




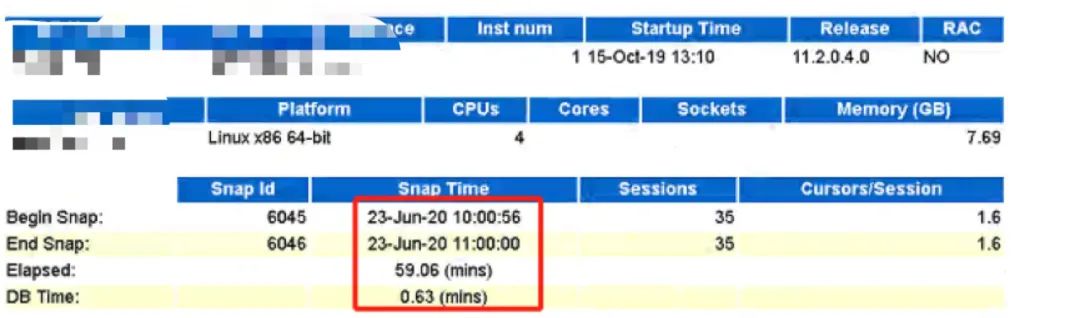
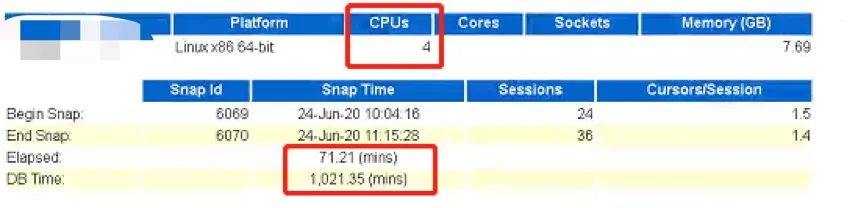
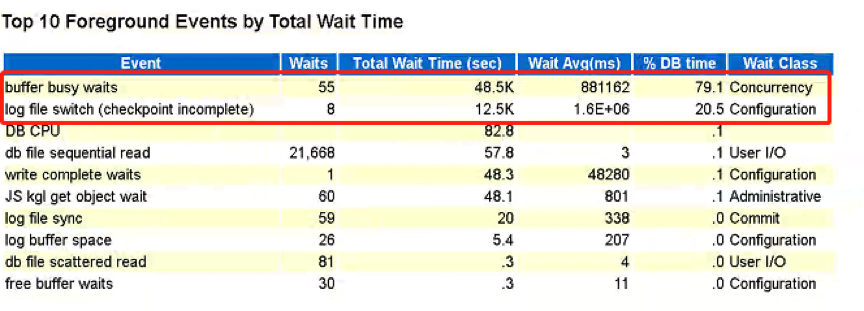
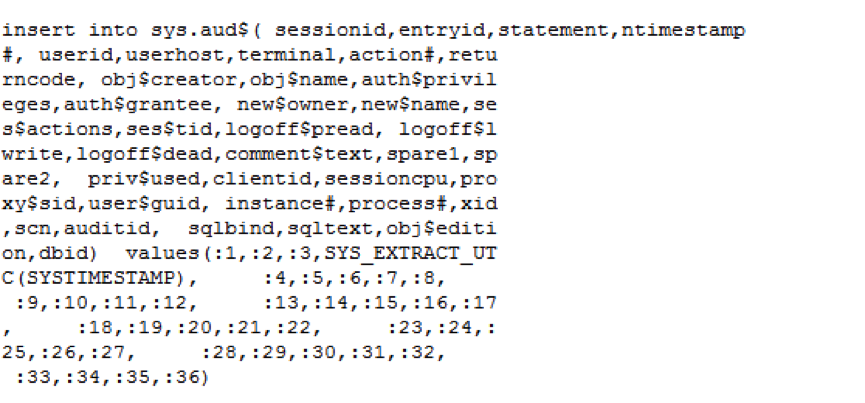
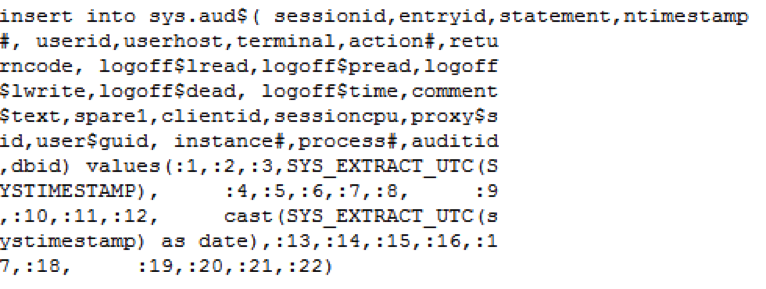
buffer busy waits:在同一时刻对同一内存块进行读写产生了争用。
log file switch (checkpoint incomplete):
当数据库中的数据发生改变时会产生redo log,一般日志组中都有多组日志文件,redo log是轮询着写的,当一组日志文件写满了,就切换到向下一组继续写,但发现其他的日志组的状态都是active(由于checkpoint未完成),日志组无法切换,这时产生的等待事件就是log file switch (checkpoint incomplete)。
一、确定buffer busy waits产生的原因
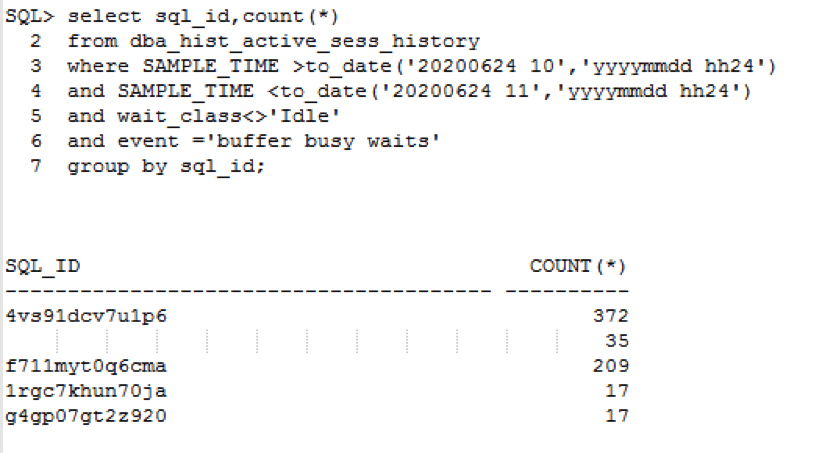
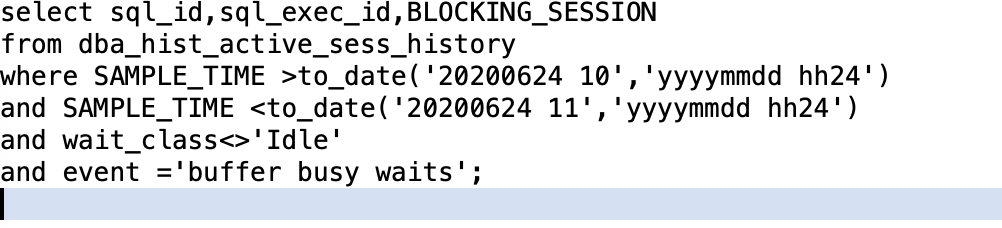
那就继续查,buffer busy waits的阻塞者。

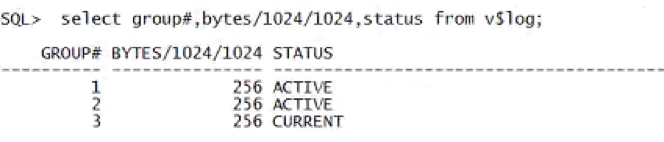
数据库3个日志组,每组大小256M,日志组数量和大小偏小,且除了一组状态是current的以外,其他的都是active状态,此时如果需要切换日志,则没有inactive的日志组可以被用来切换,必须要等待active状态的日志组对应的buffer cache 中的脏块都写入到数据文件,CKPT进程完成控制文件修改,active状态的日志组变为inactive之后才能完成日志切换。现在redo log都写不了了,那么数据库只能干等着啦。有些人查到这里,可能会告诉你,你看你日志文件太小啦,日志组又少,多加几组日志并且把日志文件的大小调大些就好啦。我觉得吧,如果直接给出这种答案的应该不是一个靠谱的dba。
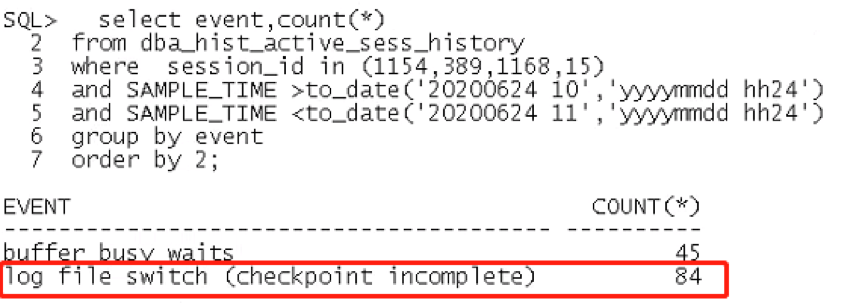
2. 继续检查redo log的切换频率
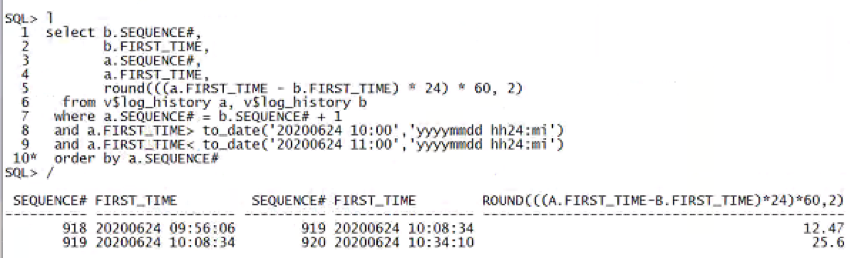
10:00 - 11:00的一个小时内,日志只切换了2次。。那么暂时就不能考虑增加日志组或者把日志组大小调大。日志切换时,如果DBWR进程还未将buffer cache 中的脏块完全写入到数据文件或者CKPT进程还未完成控制文件的修改,checkpoint 不能完成,那么就会造成log file switch (checkpoint incomplete)等待事件。CKPT进程修改控制文件是一个很快的动作,一般可以忽略,直接从DBWR进程写数据文件入手,分析需要等待的原因。
3. 查看与DBWR进程相关的等待事件
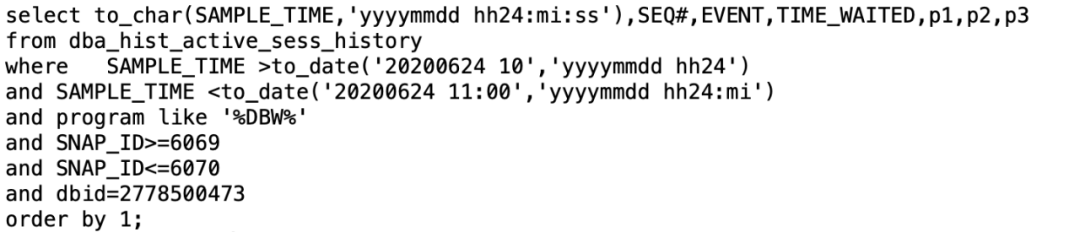
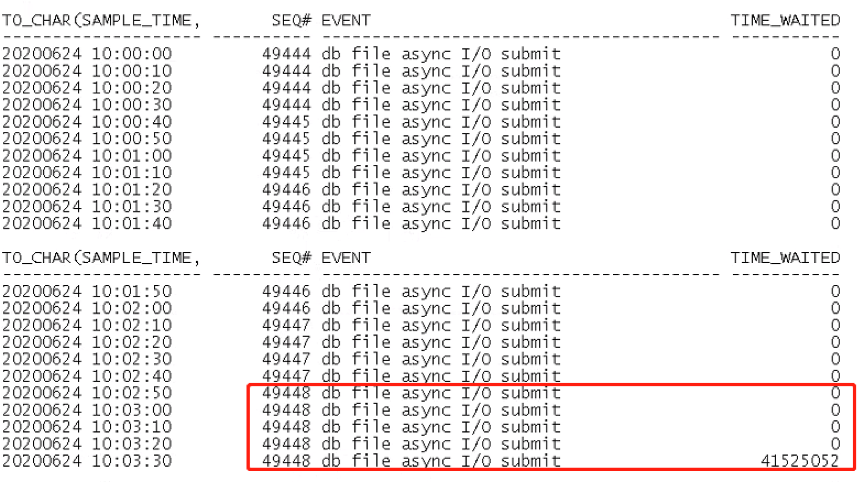
DBWR进程在进行db file async I/O submit动作,TIME_WAITED为0,表示被采样时DBWR进程还未完成写的动作,被采样到的一次完整io写入时间为40秒左右,一次io写入数据量大约为64*8k=512k,写入速度太慢,checkpoint也慢,所以造成大量的log file switch (checkpoint incomplete)等待事件。
4. 检查相关参数
确认数据库是否开始异步IO
show parameter disk_asynch_ioshow parameter filesystemio

filesystemio_options为none异步IO被禁用。(这大概是数据库安装规范没写好吧。。)
5. 继续翻AWR,查看IO性能
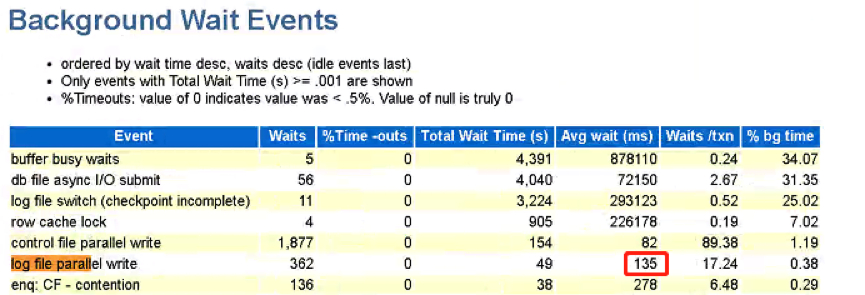
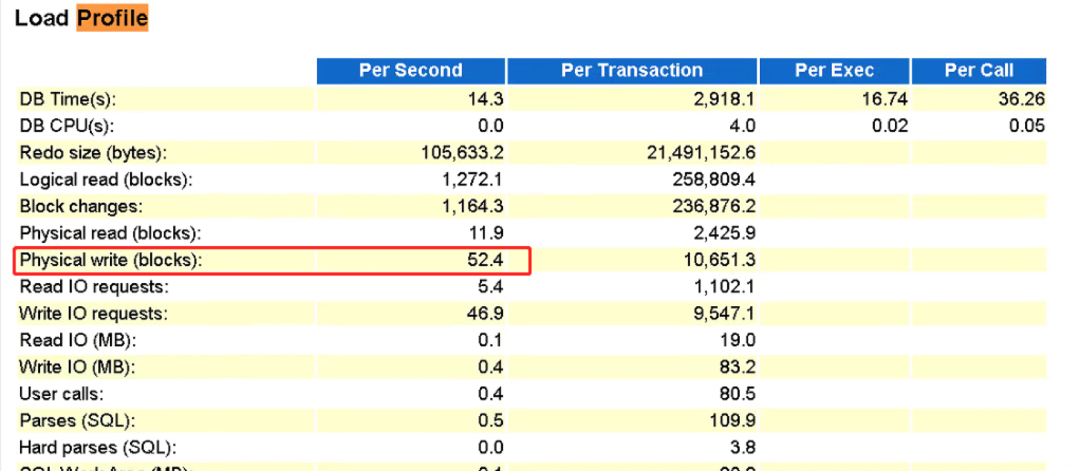
log file parallel write平均等待时间为135ms,物理读每秒52个块,可知系统io性能有问题。
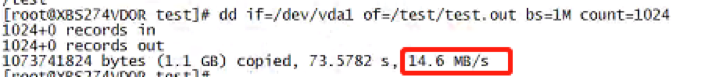
由于系统IO性能问题,导致DBWR和CKPT写入速度变慢,checkpoint迟迟不能完成,日志无法写入,事务无法完成提交,一直处于等待的状态。

你们好奇的扫地僧本尊
一个毕业于师范大学园艺专业的DBA。
从业也已经有了5年多了。。
现在没人盯着我做这个事情了,我好像也没了最初的热情。

