“SQL跑的太慢了,40秒才能跑完,要求是在5秒内完成,怎么整?”
听起来熟不熟悉?所以要怎么整,能怎么整呢?
如果上一个层次看问题,很重要的一点是,这条SQL是否真的需要被执行?很多SQL其实是“遗产”,一些人留下了一些SQL,然后跳槽了,然后没人知道这SQL是干什么的,即使根本不再需要执行它。
上一个层次真的很重要,请勿忽略。
好了,那么层次上完啦,确定这条SQL必须跑,它还特别慢,能怎么整呢?
Oracle数据库自带SQL优化神器,SQL Monitor Report,会把SQL执行过程中的各种信息都记录下来,帮助你精准的定位问题。很多时候,答案并不难,难的是知道问题是什么。来一块看看吧。
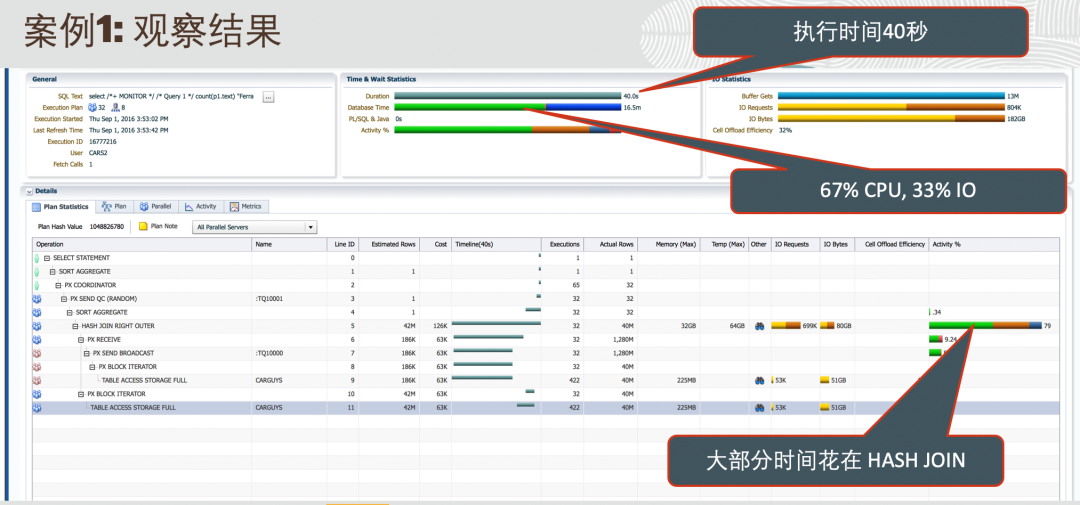
最右边,Activity%那一列,表示的是执行每一步的时候,对应的数据库里面的活动(Activity)的样本数。这样就简单了,执行哪一步的数据库活动多,肯定就表示执行那一步花的时间比较长,所以那一步就是诊断问题的入手点。因为优化么,不就是把时间变短么,那肯定是要从最花时间的执行步骤开始。
Activity%那一列里面有各种颜色,有的颜色条比较长,有的颜色条比较短,所以一眼望过去,就能看见哪一步的颜色条最长,能知道入手点在哪里。在我们上图的例子里,入手点就是HASH JOIN那个步骤。
找到入手点之后,肯定首先要看看入手点那一步的执行的相关信息。这里我们可以看到,执行这一步的HASH JOIN,使用了64GB的TEMP。TEMP通常在硬盘上,latency是毫秒(10-³)级别。如果在内存里面执行的话,内存的latency是微秒(10-⁶)级别,所以大家可能都有一个印象,用TEMP就会慢。那么是不是想办法让SQL都在内存里跑,不用TEMP它就能快呢?
就这样下结论的话,就太可惜SQL Monitor Report这个神器了。不过这里答案可以先告诉你,是能快,一丢丢~~ 这种办法就是属于用硬件来解决问题的办法,硬盘慢就换成内存。用硬件来解决问题的办法,2倍就了不得了,5倍就非常厉害了,想从40秒到5秒内,不现实。
对着SQL Monitor Report这个神器,进一步思考,为什么用了64G的TEMP?
那就得具体看看这个HASH JOIN具体都做了哪些事。这是个比较简单的例子,这里的HASH JOIN,就是是CARGUYS表和CARGUYS表的JOIN,但是这是一条并行查询,见下图,一组蓝色的并行进程和一组红色的并行进程来协同完成的HASH JOIN,两组并行进程之间采用了广播的方式(PX SEND BROADCAST)进行数据传递。
SQL Monitor Report这个神器还有两列关键的信息,Estimated Rows(估计行数),和Actual Rows(实际行数)。
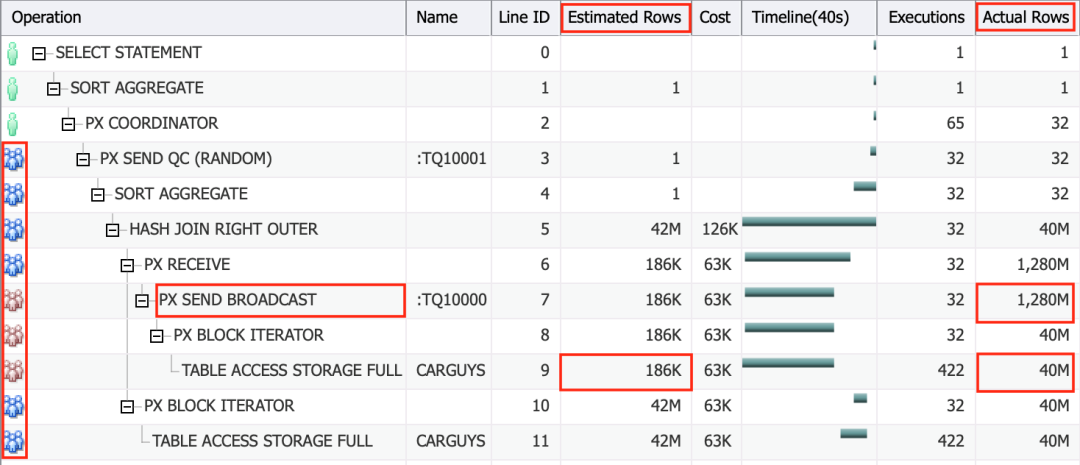
注意到,Line ID=9的那一行,Estimated Rows(估计行数)是186K,Actual Rows(实际行数)是40M,差了100倍还多。这条SQL执行的并行度是32,这样严重的偏差直接导致了Line ID=7的那一行,实际广播了40M*32=1280M数据,这些数据用来构造Hash Join中的Hash表,数据量太大在并行进程的内存空间里放不下了,就只能放到TEMP里面了。
接下来的问题是,Line ID=9的那一行为什么估计错了100多倍?SQL Monitor Report这个神器可以给到线索吗?
对哒,请看下图:
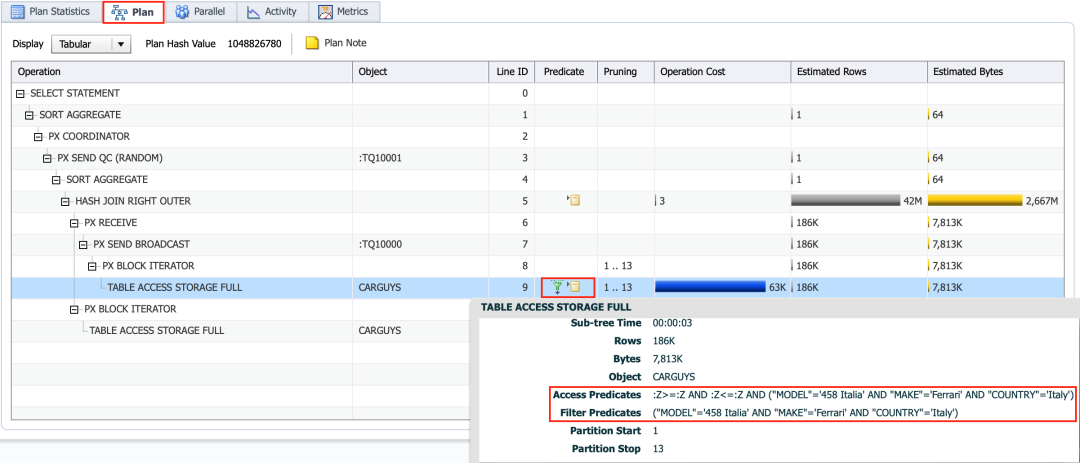
注意到SQL Monitor Report这个神器里面有好几个tab,点一下Plan那个tab,然后再点一下Line ID=9的那一行对应的Predicate列,就会出现上图右下角的小窗口,可以清楚的看到,访问Line ID=9的那一行的CARGUYS表的时候,使用的Predicate是,("MODEL"='458 Italia' AND "MAKE"='Ferrari' AND "COUNTRY"='Italy')
所以现在问题就是,为什么优化器认为应用("MODEL"='458 Italia' AND "MAKE"='Ferrari' AND "COUNTRY"='Italy')这个条件去访问CARGUYS表会返回186K数据?
想象一下,如果你是优化器的话,带着三个条件访问一个表,你怎么估计会返回多少行?
假设不考虑数据倾斜和直方图,简单估计的话,是不是分别看看每个条件对应的列的NDV(Number of Distinct Values,唯一值)有多少,假设是NDV1,NDV2,NDV3的话,那么返回的数据应该就是:
表的总行数 x(1/NDV1)x(1/NDV2)x(1/NDV3)
在这三个条件没有什么相关性,数据分布也没有特别倾斜的情况下,这样的估计一般偏差不会很大,至少不至于是100多倍的偏差。
那么我们的问题SQL里面的三个条件,有相关性吗?
Ferrari只在意大利生产
只有Ferrari才生产458 Italia这个车型
就是说有了"MODEL"='458 Italia'这个条件之后,另外的"MAKE"='Ferrari' 和"COUNTRY"='Italy'这两个条件并不会多过滤掉什么数据。这样说的话,如果估计
表的总行数 x(1/NDV1)
应该更准确~~
好了,那现在的问题是,我们做为人类,很容易就知道了三个列的相关性,可是怎样能让优化器知道呢?
Oracle数据库里面有一个叫 扩展统计信息 的东东,可以把 列相关 的信息告诉给优化器,优化器有了更全面的信息,就可以做出更准确的估计。
语法参考:
SQL> select dbms_stats.create_extended_stats(USER,'CARGUYS','(COUNTRY,MAKE,MODEL)') from dual;DBMS_STATS.CREATE_EXTENDED_STATS(USER,'CARGUYS','(COUNTRY,MAKE,MODEL)')--------------------------------------------------------------------------------SYS_STU7XNBJ5M#SUWLHOT25QW_EBHSQL> exec dbms_stats.gather_table_stats(USER,'CARGUYS')PL/SQL procedure successfully completed.
来看看在("MODEL","MAKE","COUNTRY")这三个列的组合上收集扩展统计信息之后,SQL的执行情况吧。
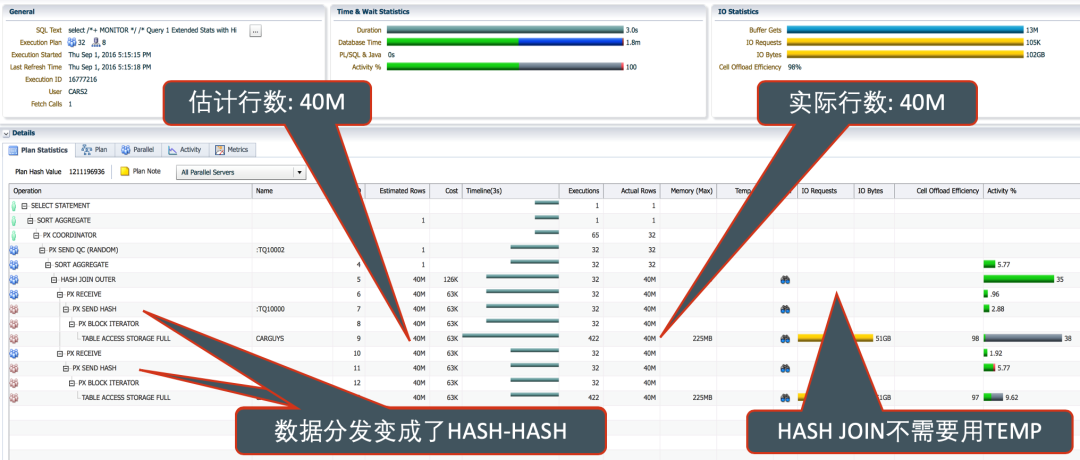
有了扩展统计信息之后,优化器的估计值比之前准确多了,估计值变好之后,优化器给两组并行进程的数据分发方式定为了HASH-HASH方式(PX SEND HASH),不再需要广播1280M的数据出去了,Hash表只需要保存40M的数据,当然也就不再需要用TEMP了。执行计划的改变,使得执行效率大幅提高。3秒完成,目标任务搞定!
总结一下
问题SQL,执行时间40秒
拿到问题SQL的SQL Monitor Report (数据库自带)
检查最右边的Activity%列,找出颜色条最长的那一行,做为入手点
检查入手点那一行的具体情况
如果入手点那一行是JOIN,通常需要进一步查看那个JOIN里面的具体情况
Estimated Rows(估计行数)和Actual Rows(实际行数)的对比是很重要的信息,如果估计有数量级级别的错误,大概率会导致不好的执行计划
SQL Monitor Report里面有好几个tab,信息很全,可以通过这些信息帮助进一步定位问题。我们这个例子里面使用了Plan tab里的Predicate信息来帮助进一步定位问题
我们定位出问题根源是查询条件涉及的三个列之间有相关性
针对问题根源,实施收集扩展统计信息这个解决方案
SQL执行时间变为3秒,目标达成
就这样一步步理清了问题,找到了问题的根源,有的放矢有针对性的去解决问题,赶脚怎么样?SQL Monitor Report,你已经拥有,值得多多使用~~
更多SQL性能优化实例解析,欢迎在哔哩哔哩(app或微信小程序)上搜索“Oracle公益课堂”,就可以看到视频啦 -“RWP大开眼界系列-SQL Monitor Report分析”
本文中的例子的SQL Monitor Report,欢迎扫描下方二维码入群索取,或通过链接https://objectstorage.ap-seoul-1.oraclecloud.com/n/ocichina001/b/wechat/o/RWP.zip下载。

扫描下方QR Code即刻预约ADW演示

编辑:萧宇