




看到兄弟们最近分享甚是活跃,作为一个老司机那是必须要参与进来的,如果兄弟们看完觉得还有点用,那将是我莫大的荣幸。
虽然写过不少东西,但是一时半会又不知分享点啥方面内容,想来想去,觉得在SQLTuning方面,怎么分析执行计划最重要,也知道有很多人对分析执行计划有一些误区,特别是拿到超长执行计划又不知道如何入手,可能感觉到很迷茫。
其实ORACLE现在进行SQLTuning的工具太多了,常见的通过setautotrace,获取执行计划的有setstatistics_level=all或gather_plan_statisticshints,还有sqlmonitor、SQLHC、SQLT等一系列工具,做执行计划绑定有SQLPROFILE、SPM、SQLPATCH等,整个SQLTuning优化家族的工具和方法已经日趋完善和庞大。
所以该主题还是从执行计划这个最核心的开始,聊聊平时的分析误区、正确的分析方法,希望对大家有一定的帮助。该主题分两部:
上部:不正确执行计划分析方式;
下部:多维度解读执行计划及实例解析;
对于做SQLTuning的人来说,掌握正确的执行计划分析方法,可以快速帮助我们定位问题的ROOTCAUSE,从而快速解决问题,一些不正确的执行计划分析方法,可能会误导你,浪费您的宝贵时间。下面就列出典型的错误分析方式(或不完美的分析方法),希望能与大家产生一丝共鸣。
使用PL/SQLDeveloper的F5查看和分析执行计划
PL/SQLDev工具是ORACLE领域最流行的工具,开发人员大多使用它,做ORACLEDBA的很多人也喜欢用它,开发人员进行SQL优化喜欢用F5查看执行计划是很正常的,毕竟他们大多不够专业,然而很多DBA做优化的时候也喜欢用它,这是很有问题的,为什么这么说呢?
可以这么说,使用F5去查看执行计划,来进行SQLTuning的人,就是不够专业的(这句话一出,是不是得罪一大批人啊,哈哈,如果是,我对您说声抱歉了),我提一个问题,你就明白了,如果用F5得到一个几百行的执行计划,中间某一行是问题的关键,你怎么快速定位?
而且这玩意分析执行计划的问题很多,你知道它内部其实是调用EXPLAINPLAN实现的,也就是得到的执行计划不一定准确,比如有绑定变量的情况下,就是纯估算的,从而对应的指标诸如cardinality、COST等都是不准确的,你说用一个不准确的玩意去找问题,那不是扯淡吗?在实际做SQL优化过程中,我连EXPLAINPLAN FOR都很少用,更别提用这种图形化工具了。
纸上得来终觉浅,不来点实战例子怎么行呢,下面就来个实战的例子,让大家明白,少用这些图形化工具分析执行计划(当然分析点简单的执行计划还是有点用的,也不能一棒子打死啊)。
某日阳光明媚,吃完中午饭,正准备小小休息一会的时候,一哥们在微信上问我一条SQL优化问题,说的比较急,他百思不得其解,明明单独测试的时候能够走索引,为什么表一关联,打死都不走索引,就算加了HINTS也不走索引,让我帮忙看看。下面就构造一个类似的SQL,如下所示:
select *
fromt1
leftjoin t2
ont1.name = t2.name
wheret1.name = '09DZ8H3XG8ORAH0HUZQI';
在这里我要说一下,他原来发的是用PL/SQLDeveloper发的执行计划,如下所示:
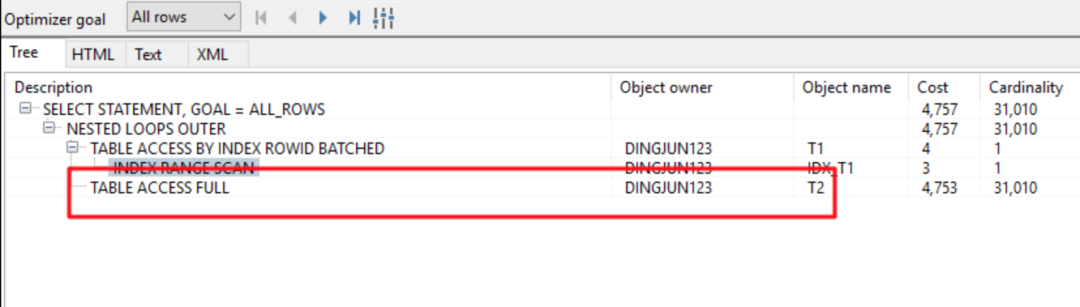
这里的t1,t2表的name都有索引,而且有很好的选择性,那按理说,根据下面关联条件:
ont1.name = t2.name
wheret1.name = '09DZ8H3XG8ORAH0HUZQI';
这里应该谓词传递给t2.name,转为t2.name=’09DZ8H3XG8ORAH0HUZQI’,那么t2表应该要走索引,然而却没有走索引,通过上面的执行计划可以看出一个问题:全表扫描那行的cardinality=31010,然而真实的结果是:
selectcount(*) from t2 where t2.name='09DZ8H3XG8ORAH0HUZQI';
COUNT(*)
----------
1
1row selected.
第一眼想到的是,这T2表统计信息不对啊,然而T2表的统计信息是刚收集过的:
selectnum_rows,sample_size,last_analyzed from dba_tab_statistics
wheretable_name='T2';
NUM_ROWSSAMPLE_SIZE LAST_ANALYZED
--------------------- -------------------
3101013 31010132020-07-12 23:32:27
而且是100%收集啊,所以统计信息没有问题。单独测试的时候正常走索引,如下所示:
回头一想,这里有个大坑啊,啥大坑呢?
像我平时做SQLTuning,我很少用PL/SQLDeveloper啊,这东西显示的执行计划,一般看的不是很直观,还有很多信息需要你自己添加,上面的执行计划就漏掉了最重要的谓词信息,而且对于超长执行计划简直是没法分析啊。
我们做SQLTuning最好使用SQL*PLUS,文本格式,便于分析(后面会说正确执行计划分析方式就明白了为什么用文本格式),我又让他把SETAUTOTRACE TRACEONLY 的执行计划弄出来给我看看,如下:
ExecutionPlan
----------------------------------------------------------
Planhash value: 2757452810
-----------------------------------------------------------------------------------------------
|Id | Operation | Name | Rows | Bytes |Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 31010 | 2180K| 4757 (3)| 00:00:01 |
| 1 | NESTED LOOPS OUTER | | 31010 | 2180K| 4757 (3)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 46 | 4 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_T1 | 1 | | 3 (0)| 00:00:01 |
|* 4 | TABLE ACCESS FULL | T2 | 31010 | 787K| 4753 (3)| 00:00:01 |
-----------------------------------------------------------------------------------------------
PredicateInformation (identified by operation id):
---------------------------------------------------
3- access("T1"."NAME"=U'09DZ8H3XG8ORAH0HUZQI')
4- filter("T1"."NAME"=SYS_OP_C2C("T2"."NAME"(+))AND
SYS_OP_C2C("T2"."NAME"(+))=U'09DZ8H3XG8ORAH0HUZQI')
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
16368 consistent gets
0 physical reads
0 redo size
831 bytes sent via SQL*Net to client
487 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
靠,瞬间发现了问题根源,还是SQL*PLUS亲切啊,明显在谓词部分(PredicateInformation)发现了一个陌生的函数:SYS_OP_C2C,这TMD明显是ORACLE内部隐式类型转换的函数嘛,然后CBO对于cardinality的计算使用函数的选择性计算,所以和真实的cardinality不一样,后面的字符串加了个U’,这明显是NVARCHAR2啊,立马让他
DESC T1和T2表:
desct1
Name Null? Type
------------------------------------------------------------- ------------------------------------
ID NUMBER
NAME NVARCHAR2(100)
desct2
Name Null? Type
------------------------------------------------------------- ------------------------------------
ID NUMBER
NAME VARCHAR2(100)
很明显这是类型不一致,当t1.name=t2.name,因为NVARCHAR2的优先级高于VARCHAR2,所以把T2.name做了隐式类型转换,所以嘛,有索引也用不上啦。以前的NVARCHAR2前面叫N’,现在改成U’,其实是一样的东西,通过dump可以看出:
selectdump('09DZ8H3XG8ORAH0HUZQI') a,
dump(n'09DZ8H3XG8ORAH0HUZQI')b,
dump(u'09DZ8H3XG8ORAH0HUZQI')c,
dump(SYS_OP_C2C('09DZ8H3XG8ORAH0HUZQI'))d
fromdual;A
---------------------------------------------------------------------------------------------------
B
---------------------------------------------------------------------------------------------------
C
---------------------------------------------------------------------------------------------------
D
---------------------------------------------------------------------------------------------------
Typ=96Len=20: 48,57,68,90,56,72,51,88,71,56,79,82,65,72,48,72,85,90,81,73
Typ=96Len=40:0,48,0,57,0,68,0,90,0,56,0,72,0,51,0,88,0,71,0,56,0,79,0,82,0,65,0,72,0,48,0,72,0,85,
0,90,0,81,0,73
Typ=96Len=40:0,48,0,57,0,68,0,90,0,56,0,72,0,51,0,88,0,71,0,56,0,79,0,82,0,65,0,72,0,48,0,72,0,85,
0,90,0,81,0,73
Typ=96Len=40:0,48,0,57,0,68,0,90,0,56,0,72,0,51,0,88,0,71,0,56,0,79,0,82,0,65,0,72,0,48,0,72,0,85,
0,90,0,81,0,73
ORACLE通过SYS_OP_C2C函数将VARCHAR2转成了NVARCHAR2,SO,找到了问题根源,那么就解决这个问题就简单了,可以使用如下方式:
1.改语句,将t1.name加上to_char,这样可以避免t2.name的类型转换,因为t1.name已经在where里有条件,这样也不影响t1.name走索引:
select *
from t1
left join t2
on to_char(t1.name)= t2.name
where t1.name ='09DZ8H3XG8ORAH0HUZQI';
执行计划如下:
ExecutionPlan
----------------------------------------------------------
Planhash value: 4205057668
---------------------------------------------------------------------------------------------
|Id | Operation | Name | Rows | Bytes |Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 72 | 8 (0)| 00:00:01 |
| 1 | NESTED LOOPS OUTER | | 1 | 72 | 8 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 46 | 4 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_T1 | 1 | | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID BATCHED| T2 | 1 | 26 | 4 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | IDX_T2 | 1 | | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
PredicateInformation (identified by operation id):
---------------------------------------------------
3- access("T1"."NAME"=U'09DZ8H3XG8ORAH0HUZQI')
5- access("T2"."NAME"(+)=SYS_OP_C2C("T1"."NAME"))
2.如果改不了语句,那么就对t2.name建立函数索引,如下所示走了函数索引:
create indexidx1_t2 on t2(SYS_OP_C2C(NAME));
执行计划如下:
ExecutionPlan
----------------------------------------------------------
Planhash value: 4208491579
---------------------------------------------------------------------------------------------
|Id | Operation | Name | Rows | Bytes| Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 31010 | 2180K| 4645 (1)| 00:00:01 |
| 1 | MERGE JOIN OUTER | | 31010 | 2180K| 4645 (1)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID BATCHED | T1 | 1 | 46| 4 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_T1 | 1 | | 3 (0)| 00:00:01 |
| 4 | BUFFER SORT | | 31010 | 787K| 4641 (1)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID BATCHED| T2 | 31010 | 787K| 4641 (1)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | IDX1_T2 | 12404 | | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
PredicateInformation (identified by operation id):
---------------------------------------------------
3- access("T1"."NAME"=U'09DZ8H3XG8ORAH0HUZQI')
6- access("T2"."SYS_NC00003$"(+)=U'09DZ8H3XG8ORAH0HUZQI')
3.改表设计,保持t1.name和t2.name的一致性,这个应该在做设计的时候就考虑,这里不做阐述。
至此,问题解决,说句题外话,我们经常会遇到类型转换问题导致索引失效,要么是写SQL时候自己加了TO_CHAR,TO_DATE,TO_NUMBER,要么因为类型不一致,ORACLE做了隐式类型转换导致索引失效。要避免这种问题,还是要在表设计的时候,使用常用类型和一致的类型,避免使用一些不常用的比如NVARCHAR2,TIMESTAMP等,写SQL时候遇到类型不一致的,要先测试好,避免上线后出现问题。
附测试语句:
droptable t1;
droptable t2;
createtable t1(id number,name nvarchar2(100));
createtable t2(id number,name varchar2(100));
createindex idx_t1 on t1(name);
createindex idx_t2 on t2(name);
begin
dbms_stats.gather_table_stats(ownname=> user,tabname => 't1',no_invalidate => false);
dbms_stats.gather_table_stats(ownname=> user,tabname => 't2',no_invalidate => false);
end;
/
insertinto t1
selectlevel,dbms_random.string(opt => 'x',len => 20)
fromdual
connectby level<100000;
insertinto t2
selectlevel,dbms_random.string(opt => 'x',len => 20)
fromdual
connectby level<1000000;
insertinto t2
select* from t1
whererownum<1000;
commit;
--问题语句
select*
fromt1
leftjoin t2
ont1.name = t2.name
wheret1.name = '09DZ8H3XG8ORAH0HUZQI';
其它不正确的执行计划分析方式还有很多,这里不再赘述,有兴趣的可以自己分析下,比如:带绑定变量的不获取实际执行的执行计划,过度关注COST等。
今天分享到此结束,我们下部见。
