




1. 前言
2. 四板斧
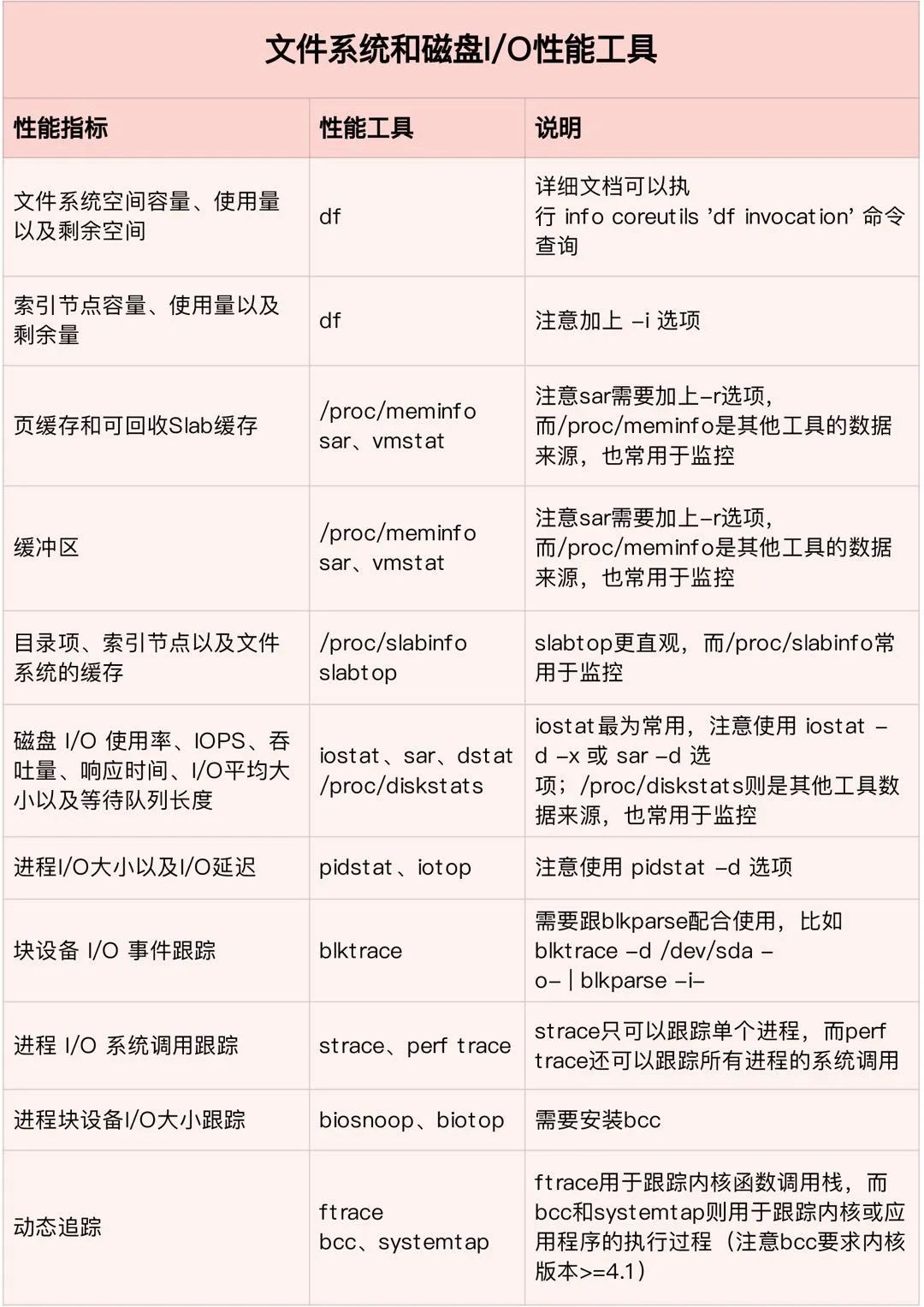
2.1. 磁盘
[root@VM-0-131-centos ~]# time dd if=/dev/zero of=test bs=8k count=5120 oflag=dsync5120+0 records in5120+0 records out41943040 bytes (42 MB) copied, 12.9928 s, 3.2 MB/sreal0m13.079suser0m0.003ssys0m0.207s
在Linux中,对于一个普通IO都会先经过page cache(o_direct除外),那么还可以这么测,写到page cache(不指定oflag=dsync)就结束,由OS去调度写。PostgreSQL也是如此,PostgreSQL对于page cache还是比较喜欢的,对于普通数据文件的写入,也是由bgwriter先写到page cache中,再由checkpointer和OS来刷写脏页,所以用dd测的这两个值有参考意义,顺序同步写入:3.2 MB/s,顺序写入:312 MB/s。
[root@VM-0-131-centos ~]# time dd if=/dev/zero of=test bs=8k count=10000001000000+0 records in1000000+0 records out8192000000 bytes (8.2 GB) copied, 26.272 s, 312 MB/sreal0m26.273suser0m0.094ssys0m6.423s
[root@VM-0-131-centos ~]# time dd if=test of=/dev/null bs=8k2000000+0 records in2000000+0 records out16384000000 bytes (16 GB) copied, 88.3873 s, 185 MB/sreal1m28.388suser0m0.125ssys0m2.675s
随机读取的能力不好测,对各种盘的随机读速度有个大概认知就行了:
1) M2 NVME SSD随机读大约40M,顺序读大约2000-4000M
2) SATA SSD 随机读大约30MB,顺序读大约550M
3) 机械硬盘随机读大约 0.5M,顺序读大约 100-200M
复合我们的预期。至此,对于磁盘的读写能力有了一个大致的认知。除了硬盘能力好坏,IO的调度策略也有影响,Linux的IO调度器称为evelator(电梯),坐过电梯都知道,电梯的算法是:电梯总是从一个方向,把人送到有需要的最高的位置,然后反过来,把人送到有需要的最低一个位置。这样效率是最高的,因为电梯不用根据先后顺序,不断调整方向,走更多的冤枉路。
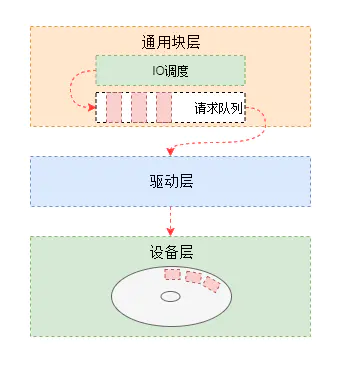
[root@VM-0-131-centos ~]# cat sys/block/sr0/queue/schedulernoop deadline [cfq]
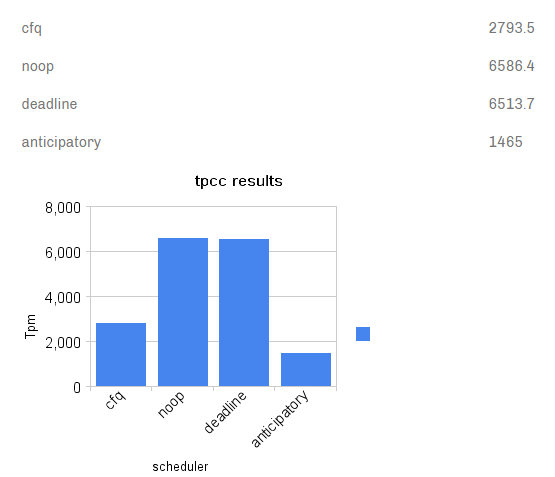
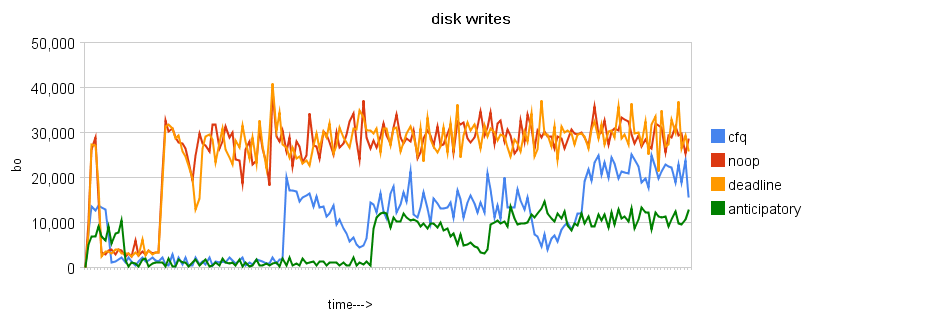
[root@VM-0-131-centos ~]# echo deadline > sys/block/sda/queue/scheduler
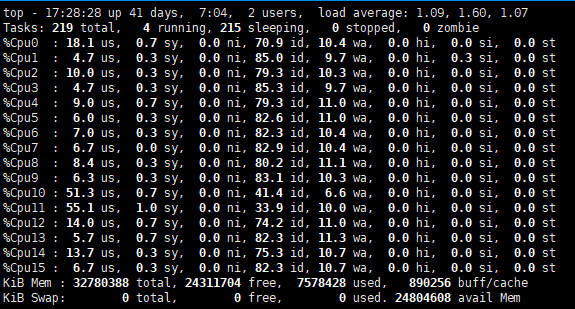
这里看到,我的磁盘比较挫,存在很多iowait。接下来再用iotop,查看是哪些进程出了状况:iotop -u postgres,看个整体,是否有哪些进程写入高,那些进程没有在做任何读取,这样就可以通过pg_stat_activity来追踪进程在执行些什么语句。给几个万金油SQL:
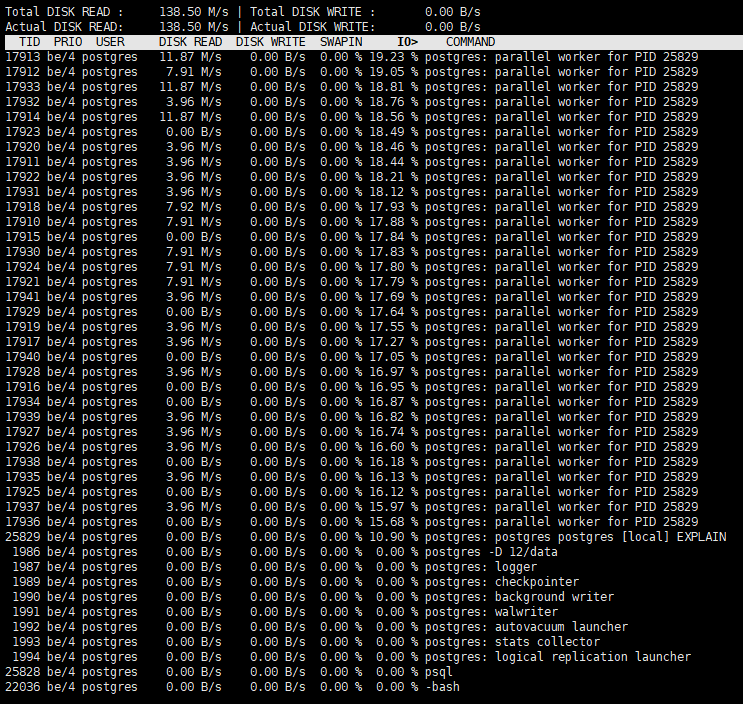
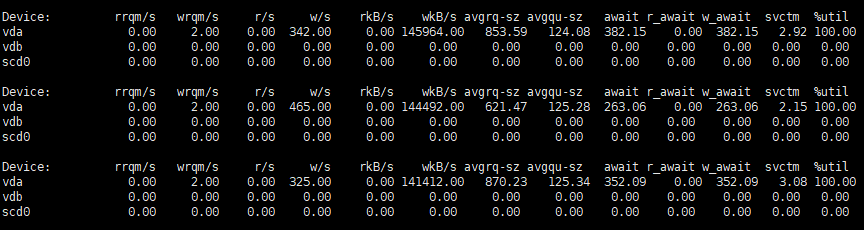
整体看完,就可以使用iostat看具体的了,iostat -x -d -k 1,注意 iostat中的 %util 基本已经没有任何作用了,svctm也没什么参考意义,磁盘是否达到真正极限瓶颈,需要参考通过fio等工具压测出的极限带宽和IOPS值。在iostat的注释中可以看到svctm:The average service time (in milliseconds) for I/O requests that were issued to the device. Warning! Do not trust this field any more. This field will be removed in a future sysstat version,而对于util来说,%util表示该设备有I/O(即非空闲)的时间比率,不考虑I/O有多少,只考虑有没有。由于现代硬盘设备都有并行处理多个I/O请求的能力,所以%util即使达到100%也不意味着设备饱和了。举个简单的例子:某硬盘处理单个I/O需要0.1秒,有能力同时处理10个I/O请求,那么当10个I/O请求依次顺序提交的时候,需要1秒才能全部完成,在1秒的采样周期里%util达到100%;而如果10个I/O请求一次性提交的话,0.1秒就全部完成,在1秒的采样周期里%util只有10%。可见,即使%util高达100%,硬盘也仍然有可能还有余力处理更多的I/O请求,即没有达到饱和状态。
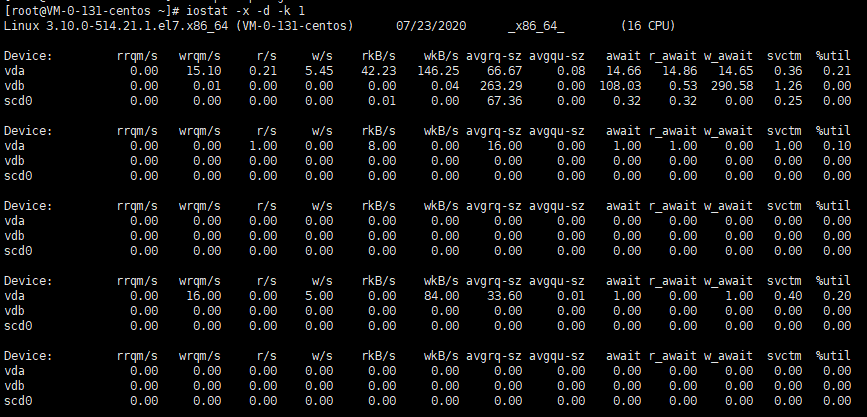
假设一个块设备一个队列,普通的物理硬盘,每秒可以响应几百个request(IOPS)
SSD1,大约是6万,SSD2,大约9万,SSD3,大约50万,SSD4,大约60万,SSD5,大约78.5万,所以只有一个队列也是不现实的。一个队列会带来如下问题:
1. 全部IO中断会集中到一个CPU上
2. 不同NUMA节点也会集中到一个CPU上
而PostgreSQL自身与IO相关的参数有很多,在此就简单介绍下,不做深入。影响较大的是fsync、full_page_write、checkpoint_timeout、checkpoint_compeletion_target等,其余的诸如commit_delay和bgwriter相关参数,也和IO有关。
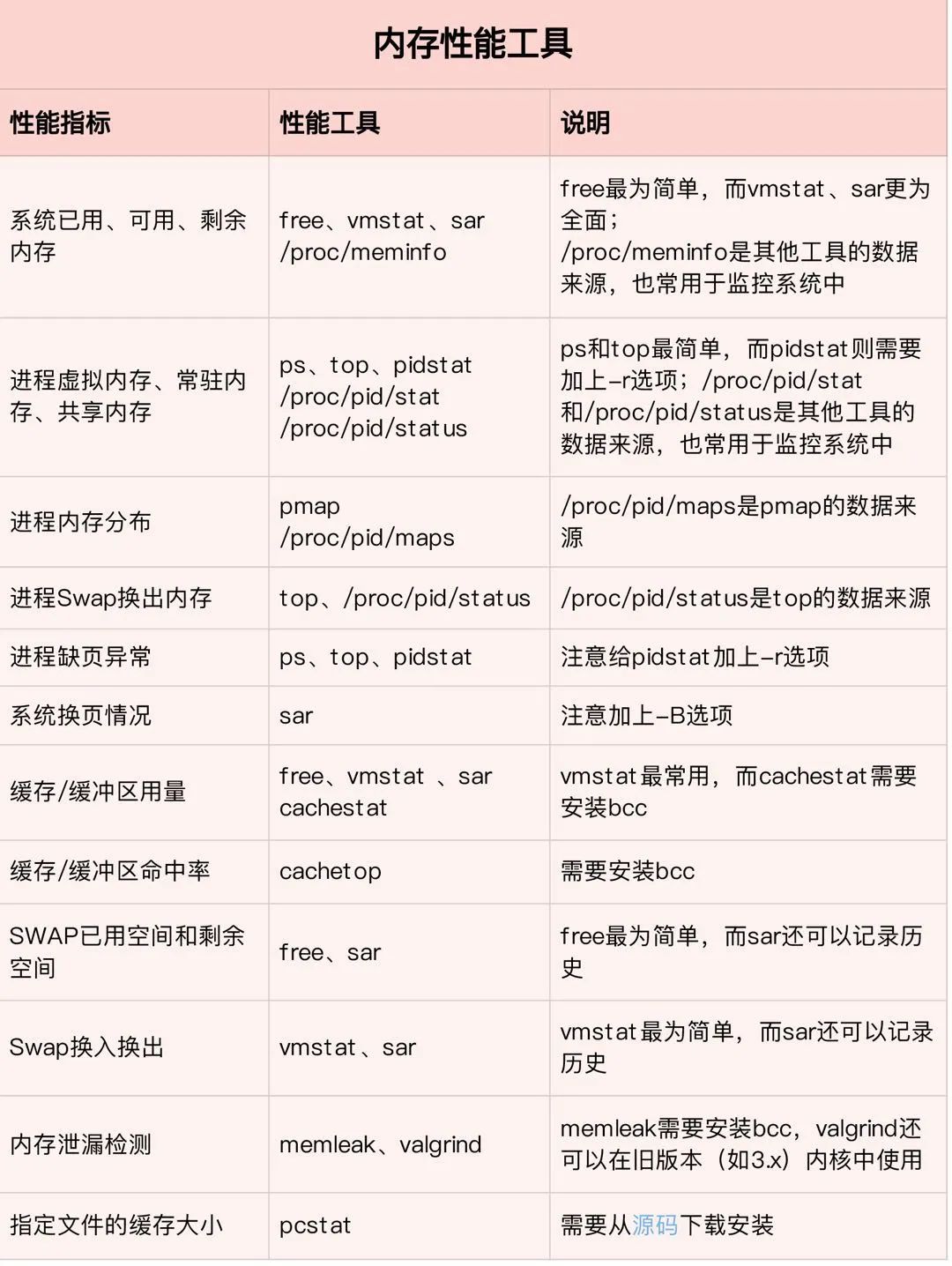
2.2. 内存
内存都很熟悉,内存越大,PostgreSQL的shared_buffer也能设置更大,但有一个合理的范围:25% ~ 40%,在某些TPCC测试的场景下,这个值还可以调大更大,比如70%的RAM,这样让warehouse的数据都能在数据库自己的内存中,减少双缓存带来的影响。在PostgreSQL中,需要特别预防OOM,还有因为work_mem不足或者有递归死循环的这种类似SQL导致临时文件的激增。
首先是OOM,即OutOfMemory,内存溢出,原因是:分配的太少,用的太多或用完没释放。Linux是允许memory overcommit的,只要你来申请内存我就给你,寄希望于进程实际上用不到那么多内存,但万一用到那么多了呢?那就会发生类似“银行挤兑”的危机,现金(内存)不足了。Linux设计了一个OOM killer机制(OOM = out-of-memory)来处理这种危机:挑选一个进程出来杀死,以腾出部分内存,如果还不够就继续杀…,所以我们可以看到类似如下,把postmaster进程给杀了:
-bash-4.2$ free -mtotal used free shared buff/cache availableMem: 32012 7359 9592 0 15060 24256Swap: 0 0 0
Linux系统默认的设置倾向于把内存尽可能的用于文件cache,所以在一台大内存机器上,往往我们可能发现没有多少剩余内存。
对于我们的操作系统,free命令显示出的空闲内存,应该更多关注-/+ buffers/cache: 这表明了你的系统可能还剩余的空闲内存。对于应用程序来说,buffers/cached占有的内存是可用的,因为buffers/cached是为了提高文件读取的性能,当应用程序需要用到内存的时候,buffers/cached会很快地被回收,以供应用程序使用。
由于PostgreSQL是多进程的架构,每个进程自己也会占一些内存:
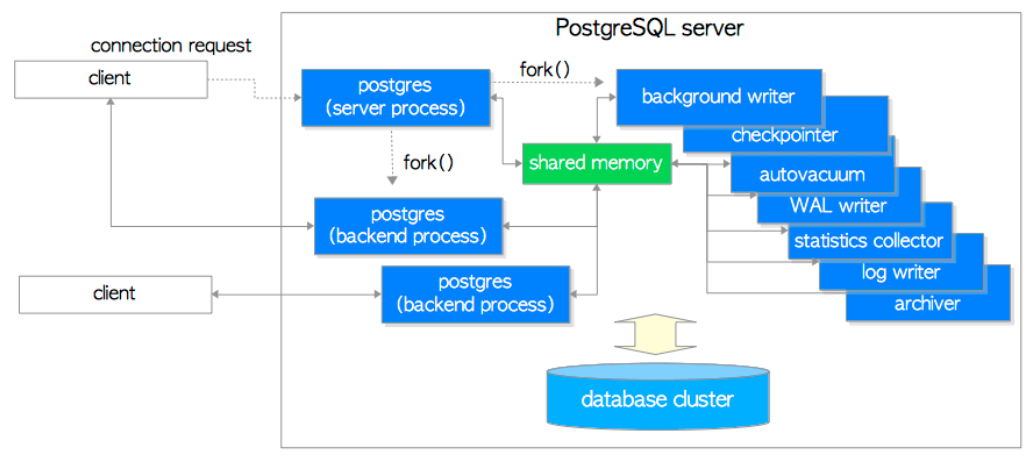
除了每个进程自己的私有内存,还有数据库中配置的work_mem、temp_buffers和maintenance_work_mem,尤其是work_mem,如果有多个用户尝试执行排序操作,则系统将为所有用户分配大小为work_mem * 总排序操作数的空间。请注意对于复杂的查询,可能会同时并发运行好几个排序或散列(hash)操作;每个排序或散列操作都会分配这个参数声明的内存来存储中间数据。同样,好几个正在运行的会话可能会同时进行排序操作,因此使用的总内存量可能是work_mem的很多倍。因此我们可以在会话级别设置该参数,而maintenance_work_mem设置较大的值对于vacuum(vacuum清理dead tuple时,扫描数据页得到的dead tuple列表是放在maintenance_work_mem里面的),RESTORE,CREATE INDEX,ADD FOREIGN KEY和ALTER TABLE等操作的性能提升效果显著,主要针对VACUUM,CREATE INDEX,REINDEX等操作。并且在一个数据库会话里,只有一个这样的操作可以执行,并且一个数据库实例通常不会有太多这样的工作并发执行。不过需要注意的是,当autovacuum运行时,可能会分配最高达这个内存的 autovacuum_max_workers倍,因此要小心不要把该默认值设置得太高。
-bash-4.2$ tree -d.|-- 1|-- 14184|-- 14185`-- pgsql_tmp4 directories-bash-4.2$ lsof | grep deletedpostgres 1987 postgres 1u CHR 136,0 0t0 3 dev/pts/0 (deleted)postgres 1987 postgres 2u CHR 136,0 0t0 3 dev/pts/0 (deleted)
内存一般用vmstat或top,主要关心swap是否用到。
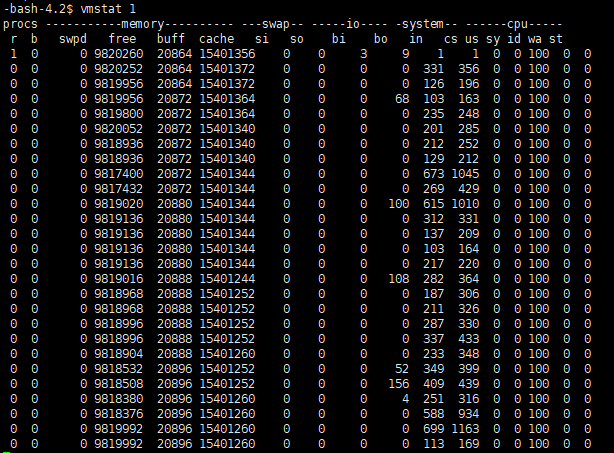
对于PostgreSQL本身,有pgfincore、pg_prewarm还有pg_buffercache这些优秀的插件等,都和内存打交道。
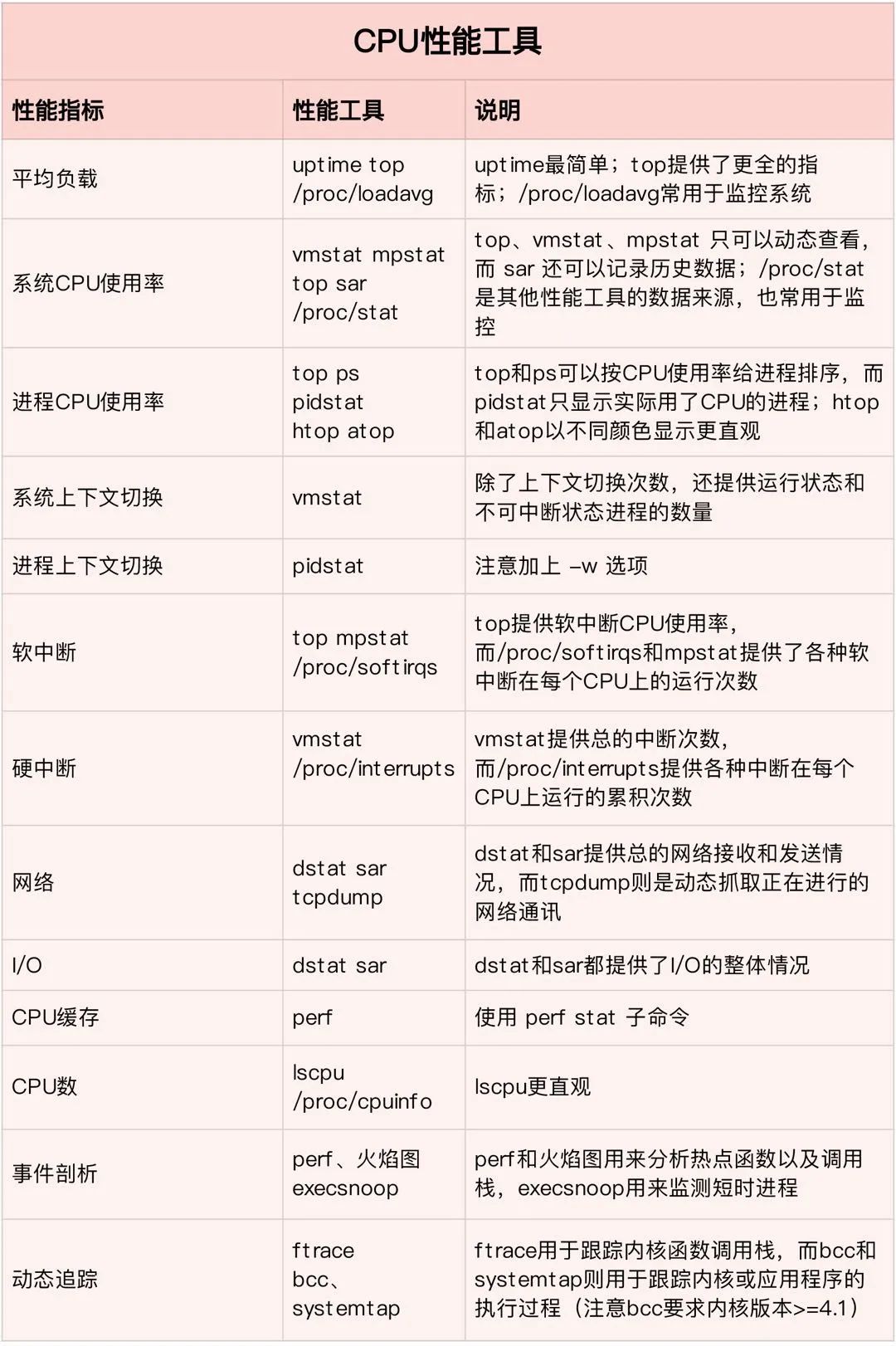
2.3. CPU
CPU就是大脑了,CPU的好坏与多少直接决定了PostgreSQL的性能好坏,主频越高越好。CPU的观察使用top和htop就可以了,个人喜欢用htop,有高亮,每个进程的使用情况也可以看的很清楚。对于现在动辄大几十个CPU的服务器,看到CPU 100%了,也不要慌,因为可能只是某一个CPU饱和了。如果服务器的CPU比较少,且大多已经饱和,那最好不要开启PostgreSQL的并行,因为并行执行会从其他查询中窃取CPU时间,并增加响应时间。
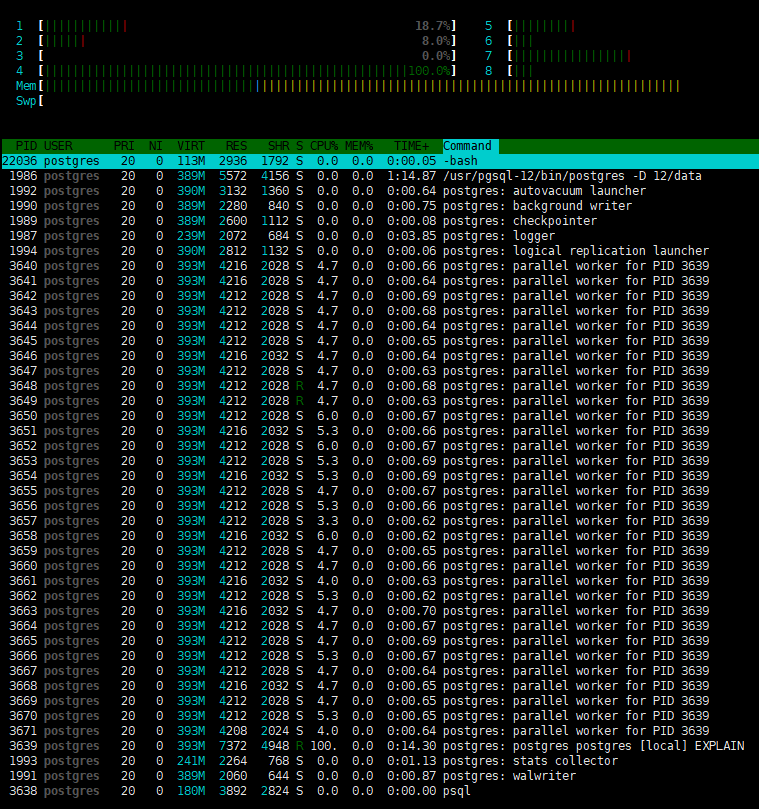
对于CPU,也有很多可以调优的地方,比如Linux 给我们提供了方便的工具用来手动分配进程到不同的CP上(CPU Affinity),这样我们可以按照服务器和应用的特性来安排特定的进程到特定的CPU上,比如要消耗大量CPU和I/O资源,如果我们能分配PostgreSQL进程到某个或多个CPU上并由这些CPU专门处理的话会毫无疑问的提高应用程序的响应和性能。还有一些特殊情况是必须绑定应用程序到某个CPU上的,比如某个软件的授权是单 CPU 的,如果想运行在多CPU机器上的话就必须限制这个软件到某一个CPU上。在此提一句,鲲鹏基于NUMA架构的服务器上,进程绑定在某个CPU上,性能提升明显。
还有网卡也可以绑定到某个CPU上,硬件中断发生频繁,是件很消耗CPU资源的事情,在多核CPU条件下如果有办法把大量硬件中断分配给不同的CPU (core) 处理显然能很好的平衡性能。现在的服务器上动不动就是多CPU多核、多网卡、多硬盘,如果能让网卡中断独占1个CPU (core)、磁盘IO 中断独占1个CPU的话将会大大减轻CPU的负担,提高整体处理效率。Linux内核从2.4以后的版本才支持把不同的硬件中断请求(IRQs)分配到特定的CPU上,这个绑定技术被称为 SMP IRQ Affinity。在网络非常繁忙的情况下,对于文件服务器、高流量Web服务器这样的应用来说,把不同的网卡IRQ均衡绑定到不同的CPU上将会减轻某个CPU的负担,提高多个CPU 整体处理中断的能力;对于数据库服务器这样的应用来说,把磁盘控制器绑到一个CPU,把网卡绑定到另一个CPU将会提高数据库的响应时间、优化性能。合理的根据自己的生产环境和应用的特点来平衡 IRQ 中断有助于提高系统的整体吞吐能力和性能。
另外比较关心的就是CPU的使用率,就是CPU非空闲态运行的时间占比,它反映了 CPU 的繁忙程度。比如,单核CPU 1s 内非空闲态运行时间为 0.8s,那么它的 CPU 使用率就是 80%;双核 CPU 1s 内非空闲态运行时间分别为 0.4s 和 0.6s,那么,总体CPU使用率就是 (0.4s + 0.6s) (1s * 2) = 50%。
在 Linux 系统下,使用 top 命令查看 CPU 使用情况,可以得到如下信息:
%CPU(s): 0.0 us, 0.0 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
us(user):表示 CPU 在用户态运行的时间百分比,通常用户态 CPU 高表示有应用程序比较繁忙。典型的用户态程序包括:数据库、Web 服务器等。
sy(sys):表示 CPU 在内核态运行的时间百分比,内核空间占用率,该字段通常是比较低的,如果该值高说明内核态代码耗时严重,或者处于内核态中的任务CPU占比高。通常,我们的用户态程序基本不会占用sys字段,但也有一种情况就是频繁进入内核态,频繁请求内核服务。比如上下文切换、大量的中断导致sys很高。
ni(nice):表示用 nice 修正进程优先级的用户态进程执行的 CPU 时间。nice 是一个进程优先级的修正值,如果进程通过它修改了优先级,则会单独统计 CPU 开销。
id(idle):表示 CPU 处于空闲态的时间占比,此时,CPU 会执行一个特定的虚拟进程,名为 system Idle Process。
wa(iowait):表示 CPU 在等待 I/O 操作完成所花费的时间,通常该指标越低越好,否则表示 I/O 存在瓶颈,可以用前文提到的iotop、iostat、sar等定位。
hi(hardirq):表示 CPU 处理硬中断所花费的时间。硬中断是由外设硬件(如键盘控制器、硬件传感器等)发出的,需要有中断控制器参与,特点是快速执行。
si(softirq):表示 CPU 处理软中断所花费的时间。软中断是由软件程序(如网络收发、定时调度等)发出的中断信号,特点是延迟执行。
st(steal):表示 CPU 被其他虚拟机占用的时间,仅出现在多虚拟机场景。如果该指标过高,可以检查下宿主机或其他虚拟机是否异常。
由于 CPU 有多种非空闲态,因此,CPU 使用率计算公式可以总结为:CPU 使用率 = (1 - 空闲态运行时间/总运行时间) * 100%。
另外负载也和CPU息息相关,平均负载(Load Average)是指单位时间内,系统处于可运行状态(Running / Runnable)和 不可中断态的平均进程数,也就是平均活跃进程数。可运行态进程包括正在使用 CPU或者等待CPU的进程;不可中断态进程是指处于内核态关键流程中的进程,并且该流程不可被打断。比如当进程向磁盘写数据时,如果被打断,就可能出现磁盘数据与进程数据不一致。不可中断态,本质上是系统对进程和硬件设备的一种保护机制。
在 Linux 系统下,使用 top 命令查看平均负载,可以得到如下信息:
top - 19:44:46 up 41 days, 9:20, 2 users, load average: 0.01, 0.35, 0.33
这 3 个数字分别表示 1分钟、5分钟、15分钟内系统的平均负载。该值越小,表示系统工作量越少,负荷越低;反之负荷越高。
当平均负载持续大于 0.7 * CPU 逻辑核数,就需要开始调查原因,防止系统恶化;
当平均负载持续大于 1.0 * CPU 逻辑核数,必须寻找解决办法,降低平均负载;
当平均负载持续大于 5.0 * CPU 逻辑核数,表明系统已出现严重问题,长时间未响应,或者接近死机。
在此要提一下chCPU这个命令,使用chCPU命令可以修改CPU的状态。可以启用或禁用CPU,扫描新的CPU等。
[root@VM-0-131-centos ~]# chCPU --helpUsage:chCPU [options]Options:-h, --help print this help-e, --enable <CPU-list> enable CPUs-d, --disable <CPU-list> disable CPUs-c, --configure <CPU-list> configure CPUs-g, --deconfigure <CPU-list> deconfigure CPUs-p, --dispatch <mode> set dispatching mode-r, --rescan trigger rescan of CPUs-V, --version output version information and exit
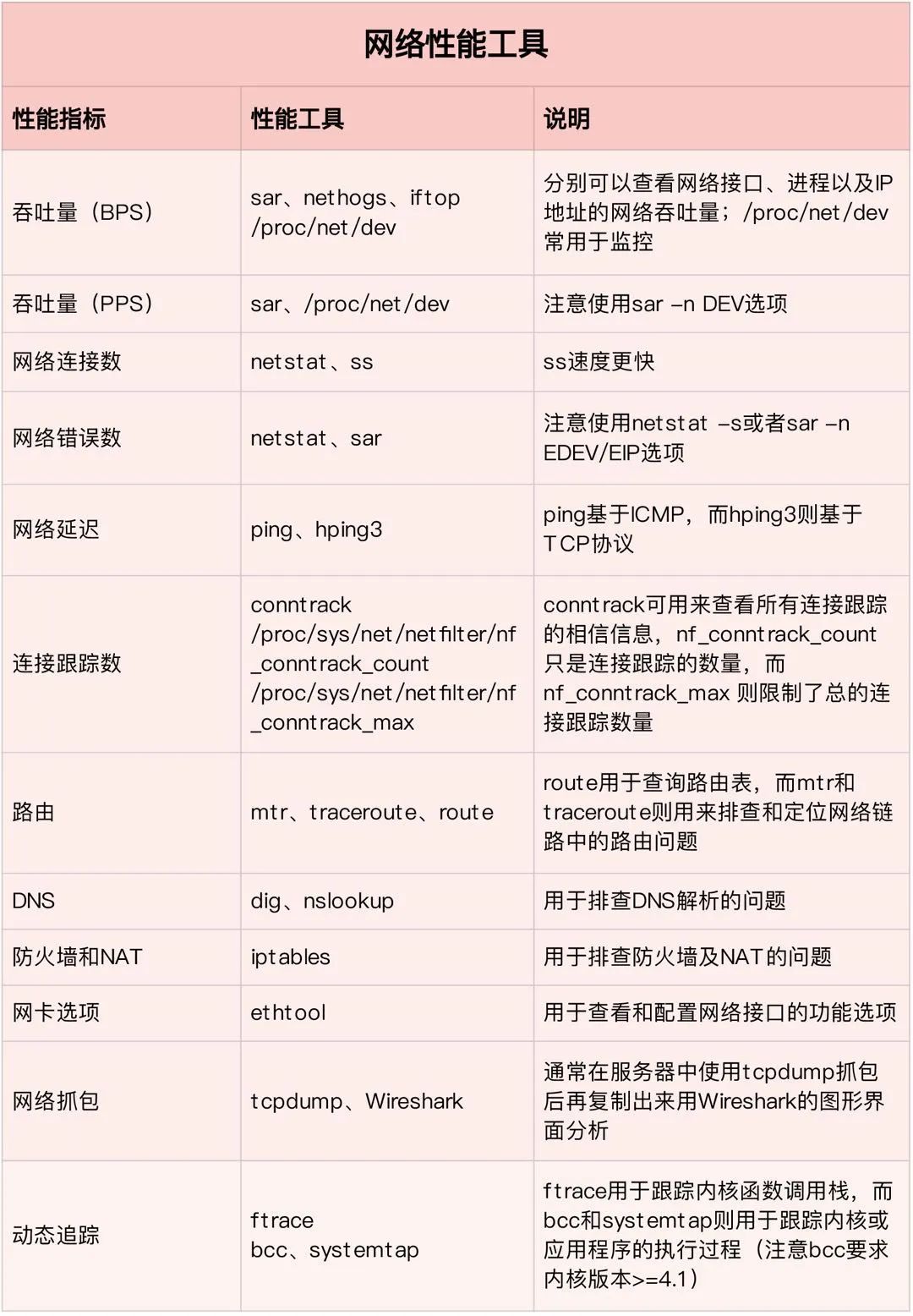
2.4. 网络
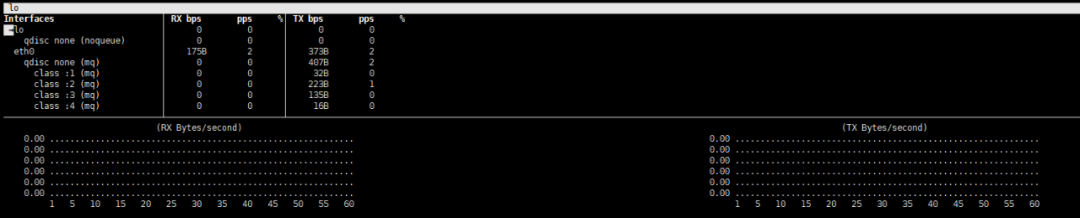
bmon也很好用,敲一下bmon即可。
既然是基于网络的,那么也不能避免某些攻击,比如我这里建立了一个连接,然后我用tcpdump来抓一下包。
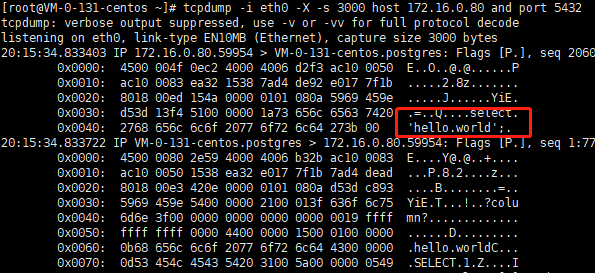
更严重一点的,可以看到你的密码,此处是为了演示将pg_hba.conf里面设置成了password(密码以明文传输):
当然PostgreSQL提供基于ssl的加密会话,unix套接字连接以及ssh隧道转发等,安全性还是很高的。PostgreSQL自身有几个和tcp相关的参数,默认都是取的linux的默认值。
postgres=# select name from pg_settings where name like 'tcp%';name-------------------------tcp_keepalives_counttcp_keepalives_idletcp_keepalives_intervaltcp_user_timeout(4 rows)
对于网络,另外关心的就是丢包率,假如链路太长,网络环境差,ARP等导致丢包严重,那也是一件很令人捉急的事情。
-bash-4.2$ ping 172.16.0.131PING 172.16.0.131 (172.16.0.131) 56(84) bytes of data.64 bytes from 172.16.0.131: icmp_seq=1 ttl=64 time=0.446 ms64 bytes from 172.16.0.131: icmp_seq=2 ttl=64 time=0.135 ms64 bytes from 172.16.0.131: icmp_seq=3 ttl=64 time=0.131 ms64 bytes from 172.16.0.131: icmp_seq=4 ttl=64 time=0.139 ms64 bytes from 172.16.0.131: icmp_seq=5 ttl=64 time=0.134 ms64 bytes from 172.16.0.131: icmp_seq=6 ttl=64 time=0.134 ms64 bytes from 172.16.0.131: icmp_seq=7 ttl=64 time=0.131 ms64 bytes from 172.16.0.131: icmp_seq=8 ttl=64 time=0.136 ms^C--- 172.16.0.131 ping statistics ---8 packets transmitted, 8 received, 0% packet loss, time 7000ms
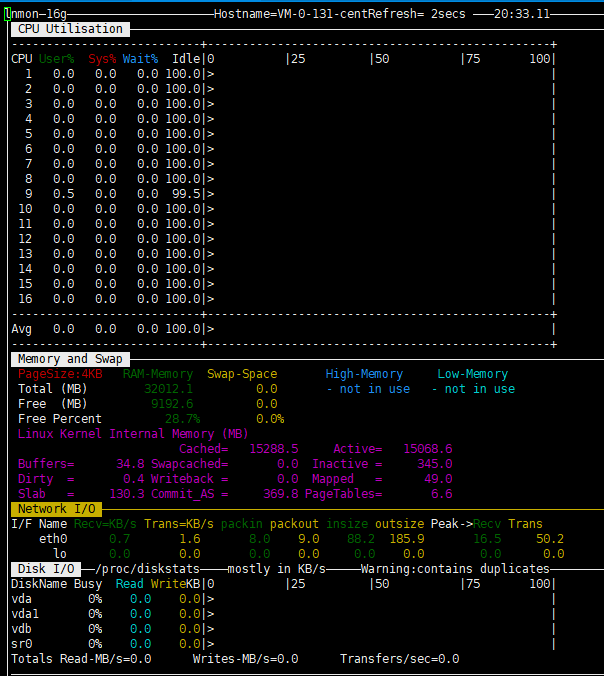
2.5. 全能工具
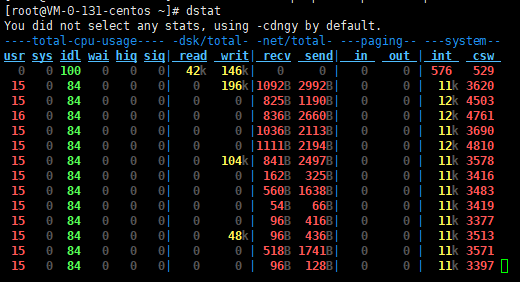
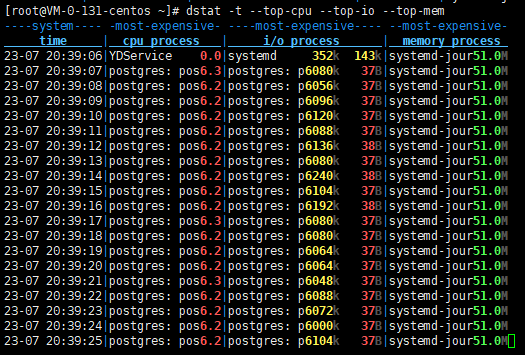
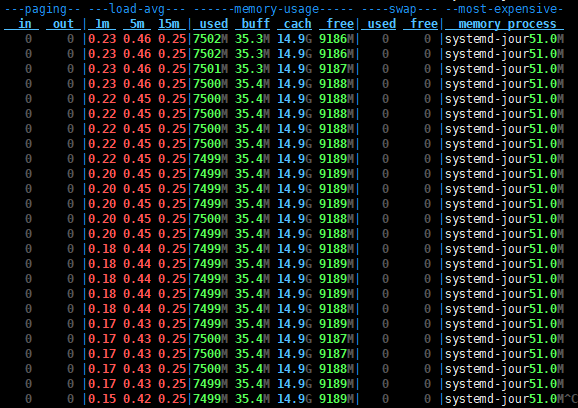
还有一个就是dstat,也很全面,界面也很友好。
I Love PG
关于我们
中国开源软件推进联盟PostgreSQL分会(简称:中国PG分会)于2017年成立,由国内多家PostgreSQL生态企业所共同发起,业务上接受工信部中国电子信息产业发展研究院指导。中国PG分会是一个非盈利行业协会组织。我们致力于在中国构建PostgreSQL产业生态,推动PostgreSQL产学研用发展。
技术文章精彩回顾 PostgreSQL学习的九层宝塔 PostgreSQL职业发展与学习攻略 2019,年度数据库舍 PostgreSQL 其谁? Postgres是最好的开源软件 PostgreSQL是世界上最好的数据库 从Oracle迁移到PostgreSQL的十大理由 从“非主流”到“潮流”,开源早已值得拥有 PG活动精彩回顾 创建PG全球生态!PostgresConf.CN2019大会盛大召开 首站起航!2019“让PG‘象’前行”上海站成功举行 走进蓉城丨2019“让PG‘象’前行”成都站成功举行 中国PG象牙塔计划发布,首批合作高校授牌仪式在天津举行 群英论道聚北京,共话PostgreSQL 相聚巴厘岛| PG Conf.Asia 2019 DAY0、DAY1简报 相知巴厘岛| PG Conf.Asia 2019 DAY2简报 独家|硅谷Postgres大会简报 直播回顾 | Bruce Momjian:原生分布式将在PG 14版本发布 PG培训认证精彩回顾 中国首批PGCA认证考试圆满结束,203位考生成功获得认证! 中国第二批PGCA认证考试圆满结束,115位考生喜获认证! 重要通知:三方共建,中国PostgreSQL认证权威升级! 近500人参与!首次PGCE中级、第三批次PGCA初级认证考试落幕! 2020年首批 | 中国PostgreSQL初级认证考试圆满结束 一分耕耘一分收获,第五批次PostgreSQL认证考试成绩公布

