




当我开始从事开发工作时,我的第一份工作是DBA。那时,在AWS RDS,Azure,Google Cloud和其余的云服务之前,有两种类型的DBA:
基础架构DBA负责建立数据库,配置存储并负责备份和复制。设置数据库之后,基础结构DBA会不时弹出并执行一些“实例调整”,例如调整缓存大小。
Application DBA从基础结构DBA获得了一个干净的数据库,并负责模式设计:创建表,索引,约束和调整SQL。应用程序DBA也是实施ETL流程和数据迁移的应用程序。在使用存储过程的团队中,应用程序DBA也将维护它们。
应用程序DBA通常是开发团队的一部分。他们将拥有深厚的领域知识,因此通常他们只从事一个或两个项目。基础结构DBA通常将是某些IT团队的一部分,并且将同时处理许多项目。
我是应用程序DBA。我从未想过要摆弄备份或调优存储。直到今天,我还是要说我是一个知道如何开发应用程序的DBA,而不是一个知道如何使用数据库的开发人员。
在本文中,我分享了我在此过程中收集的一些有关数据库开发的重要技巧。
仅更新需要更新的内容
UPDATE是一个相对昂贵的操作。为了加快UPDATE命令的执行速度,最好确保只更新需要更新的内容。
以以下查询为例,该查询规范化了电子邮件列:
db=# UPDATE users SET email = lower(email);
UPDATE 1010000
Time: 1583.935 ms (00:01.584)
看起来很清白吧?查询更新了1,010,000个用户的电子邮件。但是,是否确实需要更新所有行?
db=# UPDATE users SET email = lower(email)
db-# WHERE email != lower(email);
UPDATE 10000
Time: 299.470 ms
只需要更新10,000行。通过减少受影响的行数,执行时间从1.5秒减少到不到300ms。更新较少的行还可以节省以后的数据库维护。
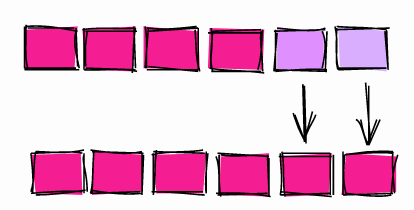
仅更新需要更新的内容
这种大型更新在数据迁移脚本中非常常见。因此,下次您编写迁移脚本时,请确保仅更新需要更新的内容。
批量加载期间禁用约束和索引
约束是关系数据库的重要组成部分:它们使数据保持一致和可靠。但是,它们的好处是要付出代价的,并且在加载或更新很多行时最明显。
为了演示,为商店设置一个小型架构:
DROP TABLE IF EXISTS product CASCADE;
CREATE TABLE product (
id serial PRIMARY KEY,
name TEXT NOT NULL,
price INT NOT NULL
);
INSERT INTO product (name, price)
SELECT random()::text, (random() * 1000)::int
FROM generate_series(0, 10000);
DROP TABLE IF EXISTS customer CASCADE;
CREATE TABLE customer (
id serial PRIMARY KEY,
name TEXT NOT NULL
);
INSERT INTO customer (name)
SELECT random()::text
FROM generate_series(0, 100000);
DROP TABLE IF EXISTS sale;
CREATE TABLE sale (
id serial PRIMARY KEY,
created timestamptz NOT NULL,
product_id int NOT NULL,
customer_id int NOT NULL
);
该模式定义了不同类型的约束,例如“ not null”和唯一约束。
要设置基线,请先在sale表中添加外键,然后将一些数据加载到表中:
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 18.413 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 5.464 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 12.605 ms
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 15410.234 ms (00:15.410)
定义约束和索引后,将一百万行加载到表中需要大约15.4s。
接下来,尝试首先将数据加载到表中,然后再添加约束和索引:
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 2277.824 ms (00:02.278)
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 169.193 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 185.633 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 484.244 ms
将数据加载到没有索引和约束的表中的速度要快得多,比之前的15.4秒缩短了2.27秒。在将数据加载到表中之后创建索引和约束花费了更长的时间,但是总的来说,整个过程要快得多,从15.4s缩短到3.1s。
不幸的是,对于索引,PostgreSQL除了删除和重新创建索引外没有提供一种简便的方法。在其他数据库(如Oracle)中,您可以禁用和启用索引,而不必重新创建它们。
使用UNLOGGED表获取中间数据
当您在PostgreSQL中修改数据时,所做的更改将写入预写日志(WAL)中。WAL用于维护完整性,在恢复过程中快速转发数据库并维护复制。
通常需要写入WAL,但是在某些情况下,您可能愿意放弃使用WAL来加快处理速度。一个示例是中间表。
中间表是一次性表,用于存储用于实施某些过程的临时数据。例如,在ETL流程中,一种非常常见的模式是将数据从CSV文件加载到中间表,清理数据,然后将其加载到目标表。在此用例中,中间表是一次性的,在备份或副本中无用。
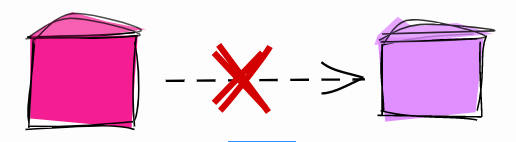
未登录表
可以将发生灾难时不需要还原的中间表以及副本中不需要的中间表设置为UNLOGGED:
CREATE UNLOGGED TABLE staging_table ( /* table definition */ );
注意:使用前,请UNLOGGED确保您了解其全部含义。
使用WITH和实施完整的流程RETURNING
假设您有一个用户表,并且发现该表中有一些重复项:
- 表格设定
db=# SELECT u.id, u.email, o.id as order_id
FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
3 | ME@hakibenita.com | 4
3 | ME@hakibenita.com | 5
用户haki benita注册了两次,一次是使用电子邮件ME@hakibenita.com,另一次是使用me@hakibenita.com。因为在将电子邮件插入表中时未对电子邮件进行规范化,所以我们现在必须处理重复项。
为了合并重复的用户,我们想要:
- 通过小写电子邮件识别重复的用户
- 更新订单以引用重复用户之一
- 从用户表中删除重复的用户
合并重复用户的一种方法是使用中间表:
db=# CREATE UNLOGGED TABLE duplicate_users AS
db-# SELECT
db-# lower(email) AS normalized_email,
db-# min(id) AS convert_to_user,
db-# array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
db-# FROM
db-# users
db-# GROUP BY
db-# normalized_email
db-# HAVING
db-# count(*) > 1;
CREATE TABLE
db=# SELECT * FROM duplicate_users;
normalized_email | convert_to_user | convert_from_users
-------------------+-----------------+--------------------
me@hakibenita.com | 2 | {3}
中间表包含重复用户的映射。对于使用相同的标准化电子邮件地址多次出现的每个用户,我们将具有最小ID的用户定义为将所有重复项都转换为该用户的用户。其他用户将保留在数组列中,并且对这些用户的所有引用都将被更新。
使用中间表,我们更新表中重复用户的引用orders:
db=# UPDATE
db-# orders o
db-# SET
db-# user_id = du.convert_to_user
db-# FROM
db-# duplicate_users du
db-# WHERE
db-# o.user_id = ANY(du.convert_from_users);
UPDATE 2
现在不再有引用,我们可以安全地从users表中删除重复的用户:
db=# DELETE FROM
db-# users
db-# WHERE
db-# id IN (
db(# SELECT unnest(convert_from_users)
db(# FROM duplicate_users
db(# );
DELETE 1
请注意,我们使用了该函数unnest来“转置”数组,即将每个数组元素变成一行。
结果如下:
db=# SELECT u.id, u.email, o.id as order_id
db-# FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
2 | me@hakibenita.com | 4
2 | me@hakibenita.com | 5
很好,所有出现的用户3(ME@hakibenita.com)都转换为用户2(me@hakibenita.com)。
我们还可以验证重复用户是否已从users表中删除:
db=# SELECT * FROM users;
id | email
----+-------------------
1 | foo@bar.baz
2 | me@hakibenita.com
现在我们可以摆脱中间表了:
db=# DROP TABLE duplicate_users;
DROP TABLE
很好,但是很长,需要清理!有没有更好的办法?
使用公用表表达式(CTE)
使用Common Table Expressions(也称为WITH子句),我们可以只用一条SQL语句执行整个过程:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
)
DELETE FROM
users
WHERE
id IN (
SELECT
unnest(convert_from_users)
FROM
duplicate_users
);
与创建中间表不同,我们创建一个公共表表达式并多次重复使用。
从CTE返回结果
在WITH子句中执行DML的一个不错的功能是,您可以使用RETURNING关键字从中返回数据。例如,让我们报告更新和删除的行数:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
RETURNING o.id
),
delete_duplicate_user AS (
DELETE FROM
users
WHERE
id IN (
SELECT unnest(convert_from_users)
FROM duplicate_users
)
RETURNING id
)
SELECT
(SELECT count(*) FROM update_orders_of_duplicate_users) AS orders_updated,
(SELECT count(*) FROM delete_duplicate_user) AS users_deleted
;
结果如下:
orders_updated | users_deleted
----------------+---------------
2 | 1
这种方法的主要吸引力在于,整个过程是在单个命令中执行的,因此无需管理事务,也不必担心在过程失败时清理中间表。
注意:Reddit上的一位读者向我指出了在公用表表达式中执行DML的可能不可预测的行为:
WITH中的子语句彼此并与主查询并发执行。因此,当在WITH中使用数据修改语句时,指定更新实际发生的顺序是不可预测的
这意味着您不能依赖于执行独立子语句的顺序。看起来像上面的示例中那样,子语句之间存在依赖关系时,可以在使用依赖项之前依赖于依赖子语句来执行。
文章来源:https://hakibenita.com/sql-tricks-application-dba
