




数据库性能很大一部分跟SQL写法有关, 有些SQL是必须改代码才能优化的, 如果不能改代码, 需要删历史记录,回收空间,让表始终保持相对较小,才能消耗较少的资源,得到能够接受的响应时间.如前公众号文章所述: 必须通过改写SQL才能提升性能的一些情况 (列举了10个需要改写的SQL).
出于各种原因, 需要在不改SQL代码的情况下对数据库进行优化,下面就列举了一些情况,可以在不改程序代码的情况下, 改善SQL的执行效率:
1-增加索引(没有风险)
普通索引:
这个不多解释, 大部分sql性能提升立竿见影, 几百倍,上千倍甚至上万倍的提升都是正常的.
函数索引
解决隐式类型转换:
字段类型是varchar2类型, 变量类型是number类型, 比如 phone_nbr=13812345678 , phone_nbr(varchar2类型)字段上的索引是用不上的(不要抬杠说index fast full scan还有可能), 这就需要再创建一个 to_number(phone_nbr)的函数索引来提高效率;
类似的情况还有 varchar2类型(和char类型)的字段, 变量类型是nvarchar2(和nchar),这种情况需要创建to_nchar函数索引;
注意: date类型的字段, 遇上timestamp的变量, 不能通过创建to_timestamp函数索引来解决,需要使用方法3.
解决字段上使用函数,做运算:
to_char(cdate,'yyyymmdd')=:b1
可以创建to_char(cdate,'yyyymmdd')函数索引
xxx is null的写法,可以让xxx与常量0组成联合索引
2-调整执行计划(没有风险)
sql执行计划选择错误,不需要在程序代码的sql中增加hint, 强大的oracle有办法在后台控制SQL的执行计划;
情况1:执行计划有好有差, 直接使用sql profile或sql plan baseline固定好的执行计划;
情况2:sql没有好的执行计划,需要手工加hint生成好的执行计划,然后再用sql profile或sql plan baseline固定;
上面两种情况都可以使用coe_load_sql_profile.sql脚本完成,都是简单输入几个参数即可.
对于情况2,很多书上介绍使用coe_xfr_sql_profile.sql, 这种方法比较麻烦,还容易出错,建议大家抛弃这个方法,改用简单的coe_load_sql_profile.sql
补充一个hint使用特例, /*+ bind_aware */这个hint, 需要使用sql patch进行追加.
写这篇公众号文章的起因就是源于前同事的一个问题:
一个系统工具(logminer)使用的sql, 使用了并行度为208的 parallel_index , 这么高的并行度是不可接受的,想取消sql的并行. 因为无法修改SQL,尝试使用no_parallel_index(t) 不生效,最终通过sql patch应用了一个full(T@SEL$1)的hint,避免了使用index fast full scan,也就没有了并行:

3-改字段类型 (有一定风险,建议做好充分测试)
主要针对date类型字段, 遇到timestamp类型的变量,做隐式类型转换无法使用索引的情况,如:
select count(*) from tt where created>=:b1 and created<=:b2;
如果created字段是date类型,b1和b2是timestamp类型, 会发生隐式类型转换,无法使用created字段上的索引; 而且这种情况无法创建to_timestamp函数索引来补救;
如果不改代码解决,只能修改字段类型date为timestamp(0):
alter table tt modify created timestamp(0);
这个语句只修改数据字典, 不需要修改每行记录(如果是反过来timestamp(0)改成date类型,就要逐行修改每条记录,大表时间会比较长)
timestamp(0) 与 date 类型的主要区别在于 两个timestamp类型相减得到的是interval类型; 而两个date类型相减, 得到的是number类型, 如果没有这种谓词条件或返回列, 可以尝试这个方法.
4-改表结构(没有风险)
改成分区表
适用: 统计分析类SQL,如果是对一个月的数据做统计分析, 表中有5年的数据量, 分区后, 数据访问量为原来的1/60
5-改参数(有一定风险,建议做好充分测试)
OLTP高并发环境没有使用绑定变量, 大量硬解析, 修改代码的工作量是巨大的, 简单方法就是修改数据库初始化参数 cursor_sharing=force (默认值为exact), 有一定的风险,做好测试.(有一些bug需要注意,公众号文章: 11.2.0.3版本升级到18c之前的各版本,可能遇到严重性能问题 )
6-特殊案例
原SQL:
select PM_JOB_SEQUENCE.nextval job_id
from (select 1 from all_objects where rownum <= 13);
借用数据字典视图all_objects生成一段sequence 序列, 频繁的执行,消耗系统大量的CPU,平均每次执行平均buffer gets 169~1362(6个执行计划):
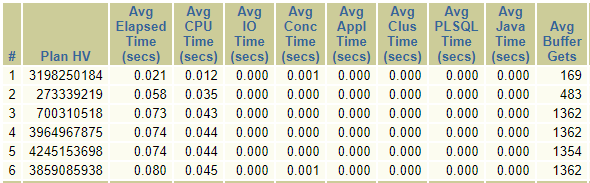
如果能改代码,可以改成:
select PM_JOB_SEQUENCE.nextval job_id from dual connect by level<=13;
这种写法不消耗buffer gets;
如果不能改代码, 可以创建一个同名表:
create table all_objects (id number not null);
insert into all_objects select 0 from dual connect by level<=100;
commit;
create index idx_all_objects on all_objects(id);
--因为同义词synonym和表同时存在时,优化访问表, 这时只需要2个buffer gets:
select PM_JOB_SEQUENCE.nextval job_id
from (select 1 from all_objects where rownum <= 13);

如果要访问真正的系统视图all_objects,则需要加上sys的schema: sys.all_objects
7- DBMS_ADVANCED_REWRITE (方法6,如果只是换表,也可以用这种方法,但是不支持sequence)
这个方法在10g版本就有了,用一段SQL代码,替换另一段SQL代码(不支持带绑定变量的SQL),功能很强大,大家有兴趣可以在网上搜索更多的案例.
对应的数据字典: DBA_REWRITE_EQUIVALENCES
下面是一个简单例子:
参数说明:
DBMS_ADVANCED_REWRITE.DECLARE_REWRITE_EQUIVALENCE (
name VARCHAR2, ---名字
source_stmt CLOB, ---原SQL代码
destination_stmt CLOB, ---替换SQL代码
validate BOOLEAN := TRUE, --默认值true, 会比较两个SQL结果集, 如果不相同, 不会创建成功
rewrite_mode VARCHAR2 := 'TEXT_MATCH' --默认值,简单转换; 还有高级的general, 更高级的recursive (disabled: 禁用)
);
如果要删除:
exec sys.DBMS_ADVANCED_REWRITE.DROP_REWRITE_EQUIVALENCE ('&equ_name');
--例子开始:
--创建REWRITE_EQUIVALENCE
begin
sys.DBMS_ADVANCED_REWRITE.DECLARE_REWRITE_EQUIVALENCE (
'tiger_test_equivalence',
'select ename from emp',
'select dname from dept'
,validate => false
);
end;
/
--修改参数才能使用:query_rewrite_integrity 默认值: enforced
SQL> alter session set query_rewrite_integrity = trusted;
--下面SQL,实际上执行的是select dname from dept:
SQL>select ename from emp;
ENAME
--------------
ACCOUNTING
RESEARCH
SALES
OPERATIONS
--把参数query_rewrite_integrity改回默认值
alter session set query_rewrite_integrity = enforced;
--再次执行,返回正常结果:
SQL> select ename from emp;
ENAME
----------
SMITH
ALLEN
......
JAMES
FORD
MILLER
实战案例模拟:
--原SQL,无法使用status字段上的索引(条件写到了having 部分):
select m.object_type, count(1) unread_count
from t1 m
group by m.object_type, m.status, m.owner
having m.status = 'INVALID' and m.owner = 'SYS';
--等价改写SQL,可以使用status字段上的索引(条件在where部分):
select m.object_type, count(1) unread_count
from t1 m where m.status = 'INVALID' and m.owner = 'SYS'
group by m.object_type, m.status, m.owner;
想用等价改写的SQL,替换原SQL,下面是简单的几个步骤:
setup case:
create table t1 as select * from dba_objects;
create index idx_t1_status on t1(status);
--创建REWRITE_EQUIVALENCE
begin
sys.DBMS_ADVANCED_REWRITE.DECLARE_REWRITE_EQUIVALENCE (
'test_rewrite2'
, q'[select m.object_type, count(1) unread_count
from t1 m
group by m.object_type, m.status, m.owner
having m.status = 'INVALID' and m.owner = 'SYS']'
, q'[select m.object_type, count(1) unread_count
from t1 m where m.status = 'INVALID' and m.owner = 'SYS'
group by m.object_type, m.status, m.owner]'
, validate => true
, rewrite_mode => 'general'
);
end;
/
--执行原SQL, 执行计划还是使用全表扫描(query_rewrite_integrity 参数没有设置)
select m.object_type, count(1) unread_count
from t1 m
group by m.object_type, m.status, m.owner
having m.status = 'INVALID' and m.owner = 'SYS';

--设置参数, 再次执行原SQL:
alter session set query_rewrite_integrity = trusted;
select m.object_type, count(1) unread_count
from t1 m
group by m.object_type, m.status, m.owner
having m.status = 'INVALID' and m.owner = 'SYS';
(相当于执行了改写后的SQL,实现了优化目的)

8- 非常规方法, 慎用!
改二进制代码里面的sql (jar,exe等文件,sql代码一般也是字符串保存) ;大部分情况,这种方法应该也没问题.但是,不到万不得已, 不要用这一招.做好测试.
举个简单例子:
sql代码有各种日期类型的格式转换,下面情况需要创建3个不同的函数索引:
to_char(created,'yyyy-mm-dd') to_char(created,'yyyy/mm/dd') to_char(created,'yyyymmdd')
这种情况,可以在二进制代码中,找到这些字符串,统一改成 to_char(created,'yyyymmdd') , 这样只需要创建一个函数索引即可.
前面两个写法, 改完后字符串长度变短, 可以在后面补两个空格.
感谢阅读
(完)
