




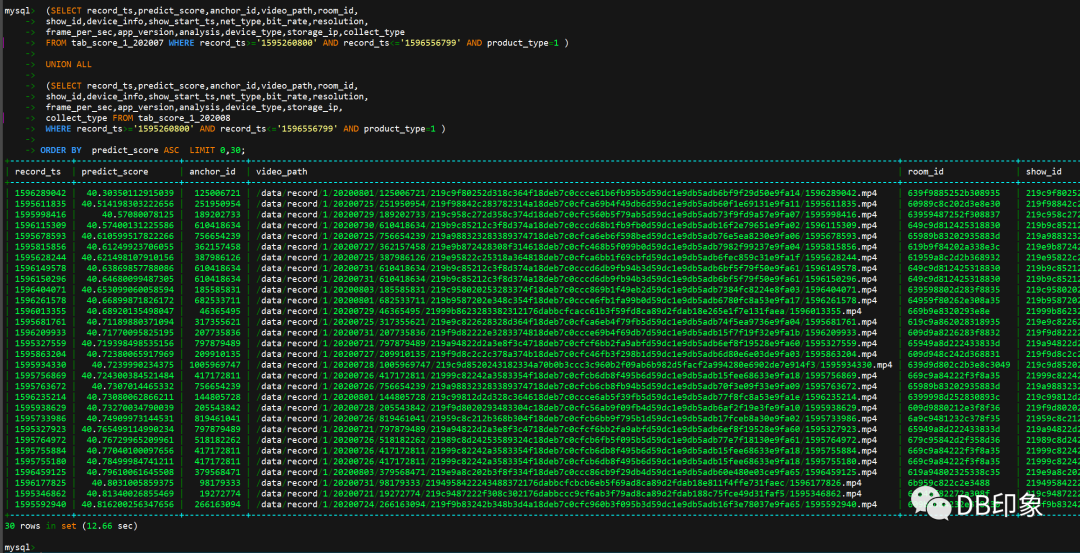
akendb=# \d+ tab01Table "public.tab01"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description-----------+---------+-----------+----------+---------+---------+--------------+-------------id | integer | | not null | 0 | plain | |num_col01 | integer | | not null | 0 | plain | |akendb=# \d+ tab02Table "public.tab02"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description-----------+---------+-----------+----------+---------+---------+--------------+-------------id | integer | | not null | 0 | plain | |num_col01 | integer | | not null | 0 | plain | |akendb=#
akendb=# select * from tab01;id | num_col01----+-----------1 | 1003 | 453 | 11(3 rows)akendb=# select * from tab02;id | num_col01----+-----------1 | 732 | 582 | 22(3 rows)akendb=#
akendb=# (select * from tab01 )akendb-# union allakendb-# (select * from tab02) ;id | num_col01----+-----------1 | 1003 | 453 | 111 | 732 | 582 | 22(6 rows)akendb=#
akendb=# (select * from tab01 )akendb-# union allakendb-# (select * from tab02)akendb-# order by id asc limit 2;id | num_col01----+-----------1 | 1001 | 73(2 rows)akendb=#
akendb=# (select * from tab02 ) 人更美akendb-# union all akendb-# (select * from tab01) akendb-# order by id asc limit 2; id | num_col01 ----+----------- 1 | 73 1 | 100(2 rows)akendb=#
akendb=# (select * from tab01 order by id limit 2)akendb-# union allakendb-# (select * from tab02 order by id limit 2)akendb-# order by id asc limit 2;id | num_col01----+-----------1 | 1001 | 73(2 rows)akendb=# (select * from tab02 order by id limit 2)akendb-# union allakendb-# (select * from tab01 order by id limit 2)akendb-# order by id asc limit 2;id | num_col01----+-----------1 | 731 | 100(2 rows)akendb=#
akendb=# update tab01 set id=1; --进行update之后id=1的行数为3,大于limit 2取数范围。UPDATE 3akendb=# update tab02 set id=1;UPDATE 3akendb=#
akendb=# (select * from tab01 )akendb-# union allakendb-# (select * from tab02)akendb-# order by id asc limit 2;id | num_col01----+-----------1 | 451 | 100(2 rows)akendb=# (select * from tab02 )akendb-# union allakendb-# (select * from tab01)akendb-# order by id asc limit 2;id | num_col01----+-----------1 | 581 | 73(2 rows)akendb=#
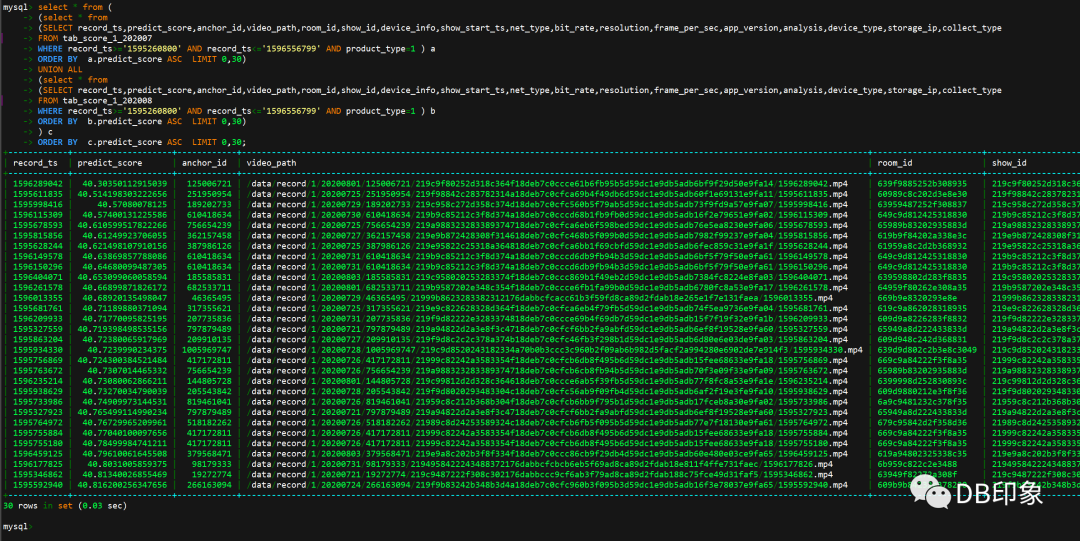
akendb=# explain analyze (select * from tab01 ) union all (select * from tab02) order by id asc limit 2;QUERY PLAN---------------------------------------------------------------------------------------------------------------------Limit (cost=110.40..110.41 rows=2 width=8) (actual time=0.031..0.033 rows=2 loops=1)-> Sort (cost=110.40..121.70 rows=4520 width=8) (actual time=0.030..0.030 rows=2 loops=1)Sort Key: tab01.idSort Method: top-N heapsort Memory: 25kB-> Append (cost=0.00..65.20 rows=4520 width=8) (actual time=0.012..0.018 rows=6 loops=1)-> Seq Scan on tab01 (cost=0.00..32.60 rows=2260 width=8) (actual time=0.012..0.013 rows=3 loops=1)-> Seq Scan on tab02 (cost=0.00..32.60 rows=2260 width=8) (actual time=0.004..0.004 rows=3 loops=1)Planning time: 0.118 msExecution time: 0.062 ms(9 rows)akendb=# explain analyze (select * from tab02 ) union all (select * from tab01) order by id asc limit 2;QUERY PLAN---------------------------------------------------------------------------------------------------------------------Limit (cost=110.40..110.41 rows=2 width=8) (actual time=0.029..0.031 rows=2 loops=1)-> Sort (cost=110.40..121.70 rows=4520 width=8) (actual time=0.028..0.028 rows=2 loops=1)Sort Key: tab02.idSort Method: top-N heapsort Memory: 25kB-> Append (cost=0.00..65.20 rows=4520 width=8) (actual time=0.010..0.016 rows=6 loops=1)-> Seq Scan on tab02 (cost=0.00..32.60 rows=2260 width=8) (actual time=0.010..0.011 rows=3 loops=1)-> Seq Scan on tab01 (cost=0.00..32.60 rows=2260 width=8) (actual time=0.003..0.004 rows=3 loops=1)Planning time: 0.110 msExecution time: 0.058 ms(9 rows)akendb=#
akendb=# (select * from tab01 order by id limit 2)akendb-# union allakendb-# (select * from tab02 order by id limit 2)akendb-# order by id asc limit 2;id | num_col01----+-----------1 | 1001 | 45(2 rows)akendb=# (select * from tab02 order by id limit 2)akendb-# union allakendb-# (select * from tab01 order by id limit 2)akendb-# order by id asc limit 2;id | num_col01----+-----------1 | 731 | 58(2 rows)akendb=#
akendb=# select * from tab01;id | num_col01----+-----------1 | 451 | 61 | 65(3 rows)akendb=# select * from tab02;id | num_col01----+-----------2 | 132 | 162 | 82(3 rows)akendb=# (select * from tab01 order by id limit 2)union all(select * from tab02 order by id limit 2)order by id asc limit 3;id | num_col01----+-----------1 | 451 | 62 | 13(3 rows)akendb=#
I Love PG
关于我们
中国开源软件推进联盟PostgreSQL分会(简称:中国PG分会)于2017年成立,由国内多家PostgreSQL生态企业所共同发起,业务上接受工信部中国电子信息产业发展研究院指导。中国PG分会是一个非盈利行业协会组织。我们致力于在中国构建PostgreSQL产业生态,推动PostgreSQL产学研用发展。
技术文章精彩回顾 PostgreSQL学习的九层宝塔 PostgreSQL职业发展与学习攻略 2019,年度数据库舍 PostgreSQL 其谁? Postgres是最好的开源软件 PostgreSQL是世界上最好的数据库 从Oracle迁移到PostgreSQL的十大理由 从“非主流”到“潮流”,开源早已值得拥有 PG活动精彩回顾 创建PG全球生态!PostgresConf.CN2019大会盛大召开 首站起航!2019“让PG‘象’前行”上海站成功举行 走进蓉城丨2019“让PG‘象’前行”成都站成功举行 中国PG象牙塔计划发布,首批合作高校授牌仪式在天津举行 群英论道聚北京,共话PostgreSQL 相聚巴厘岛| PG Conf.Asia 2019 DAY0、DAY1简报 相知巴厘岛| PG Conf.Asia 2019 DAY2简报 独家|硅谷Postgres大会简报 直播回顾 | Bruce Momjian:原生分布式将在PG 14版本发布 PG培训认证精彩回顾 中国首批PGCA认证考试圆满结束,203位考生成功获得认证! 中国第二批PGCA认证考试圆满结束,115位考生喜获认证! 重要通知:三方共建,中国PostgreSQL认证权威升级! 近500人参与!首次PGCE中级、第三批次PGCA初级认证考试落幕! 2020年首批 | 中国PostgreSQL初级认证考试圆满结束 一分耕耘一分收获,第五批次PostgreSQL认证考试成绩公布

文章转载自开源软件联盟PostgreSQL分会,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
