




经常看到有客户的系统会创建一些降序索引,如:
create index idx_xxx on tab_xxx(col_name desc);
还有多字段:
create index idx_xxx on tab_xxx(col_name1 desc,col_name2 desc);
一般情况下, 这种各字段都是desc索引是不需要的, 正常情况只需要普通索引即可(去掉desc).先看一个我遇到的案例(下面是为了方便分析进行的模拟演示):
--创建一个object_id is null 有11条记录的t1表:
create table t1 as select * from dba_objects where object_id is not null;
alter table t1 modify object_name not null;
update t1 set object_id = null where rownum<=11;
commit;
--收集一下统计信息
exec dbms_stats.gather_table_stats(user,'t1');
--当前发现的TOP SQL如下:

这是一个很简单的分页查询SQL,没有order by,执行计划使用的是全表扫描,生产系统平均buffer gets接近9万(上面用来模拟的t1表相对较小,只有741个block,索引180个左右的block).

检查t1表上的索引情况,存在一个两字段做desc的联合索引(应该是为别的业务SQL所建):
create index idx_t1_desc on t1(object_id desc,object_name desc);
加hint强制使用idx_t1_desc 索引,看一下什么情况:


使用的是index full scan , 也要把索引遍历一遍(如果object_id is null的记录数超过20个,null值所在的索引块会先扫描, 因为有rownum<=20,不会遍历整个索引,buffer gets数会大大减少).
为了优化这个SQL,我又创建了下面索引(还是两字段联合, 去掉了desc):
create index idx_t1_normal on t1(object_id,object_name);
上面SQL,不用加hint,自动使用新建索引, 执行计划使用了index range scan,效率大幅提高,buffer gets只有5:


可能有人会说, 上面的desc索引,可能是为下面的SQL所建:

那我告诉你,根本没必要. 我建的普通索引也可以被这个SQL使用. 因为oracle的优化器对这样一个全是desc的order by, 可以使用普通索引的降序扫描(descending)的方式进行优化,完全不需要创建desc降序索引:

如果上面的order by改成order by a.object_id desc,a.object_name(一个是降序,一个是默认的升序),在这种情况下, 如果为了避免排序,才需要创建(object_id desc,object_name)这样的联合索引.
而且降序索引还有一些bug,下面是MOS里面检索descending index bug的结果(截图只是一部分):
本人公众号文章<系统迁移导致SQL性能下降,神马原因?>就是一个关于desc 索引的bug.
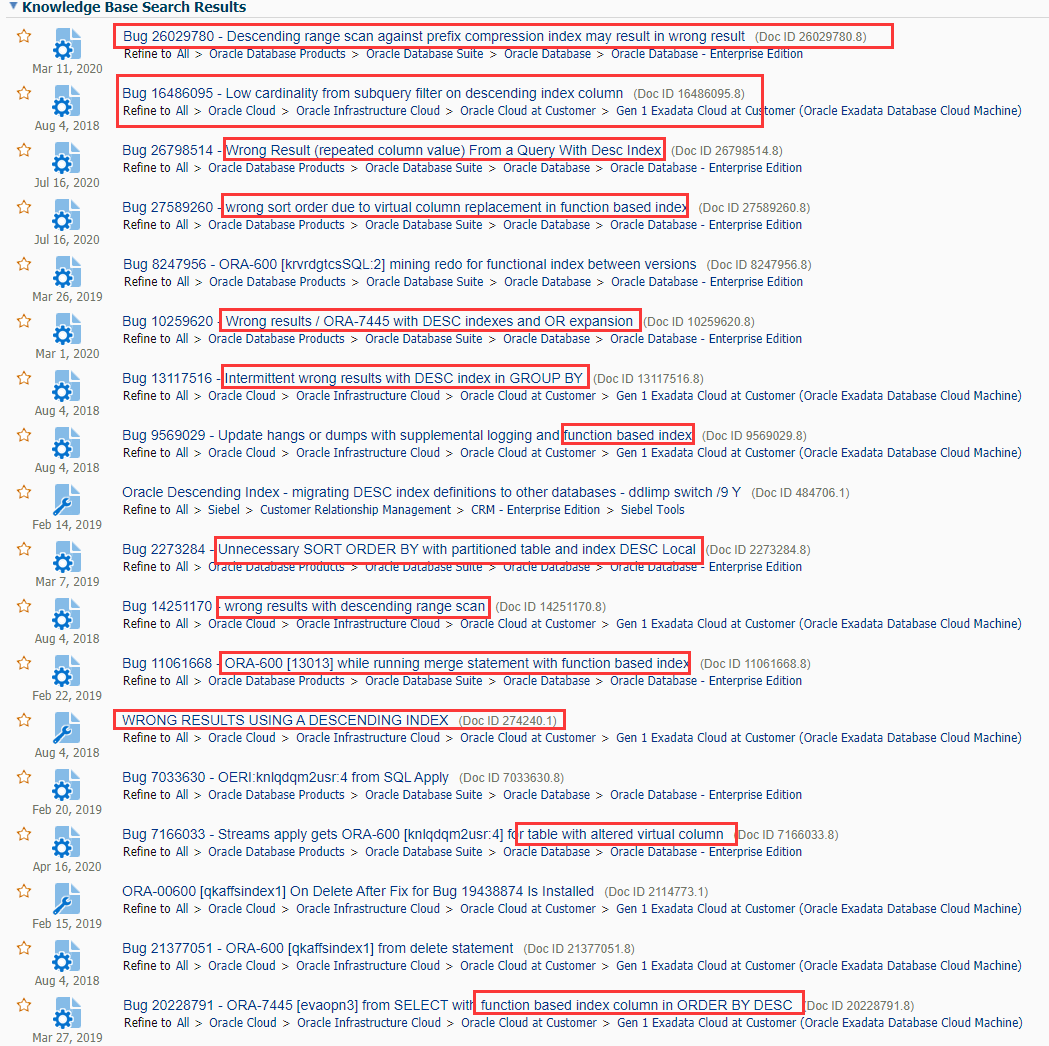
到这里, 引出我的结论:
类似上面的降序索引,可以被普通索引取代. 普通索引可能适用多个SQL,降序索引的适用范围比较窄,而且还有一些bug. 为了避免多余的索引和bug, 不建议创建全是desc 降序索引.
概括起来就是:
如果order by的一个或多个字段都是desc降序,那么是不需要创建desc 降序索引的;
如果order by的多个字段有升有降,这种情况才需要创建desc降序索引.
有时如果你需要得到索引降序扫描,而优化器没有选择,这时可以使用index_desc的hint来引导优化器,比如下面这种情况,如:

这个SQL如果不加hint, 默认使用的是全表扫描的执行计划. 使用的索引IDX_T1_OWNER_OBJECT_ID 是 owner+object_id 两字段联合索引.
下面再来分析几个书上介绍的优化案例:
我在一本书里看到有几个类似的优化案例,都是建议创建desc降序索引, 下面我们一起分析一下:
案例1:
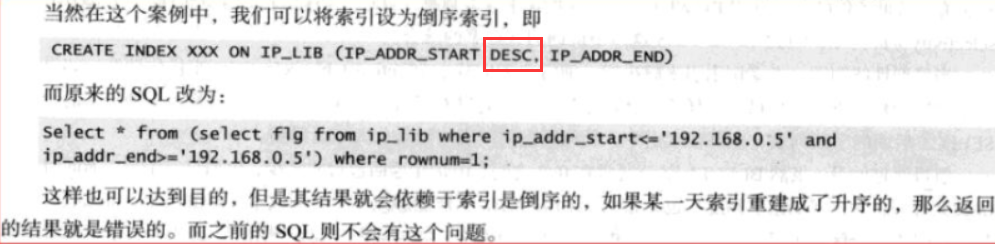
这是一个根据IP地址区间查所属地区信息的典型SQL, 这个SQL我在公众号文章<区间检索SQL优化--续>中曾有过论述,主要是写法,然后再配合合适的索引.
上面这个SQL,有几个问题:
首先,ip地址直接用字符串比较是不合适的,应该按照一定的规则,转换成number类型来比较;
其次,这样的写法如果要建索引,建议创建ip_addr_end+ip_addr_start, 即结束地址在前的普通索引,而不是建开始地址的降序索引;
再次,这种写法不存在升序降序导致结果错误的问题;
最后, 这种写法还有个比较大的缺点,就是在找不到匹配的记录时,性能会比较差.
建议大家在遇到类似区间检索的业务需求,参考我公众号文章的做法,实践证明是最佳的.
案例2:

原作者的优化建议是:

虽然也能起到优化作用,但是就像我一开始的案例分析的那样, 这个SQL创建普通的索引即可.desc 索引实际上是创建了一个函数索引,这种索引,其他SQL可能用不上.
案例3:
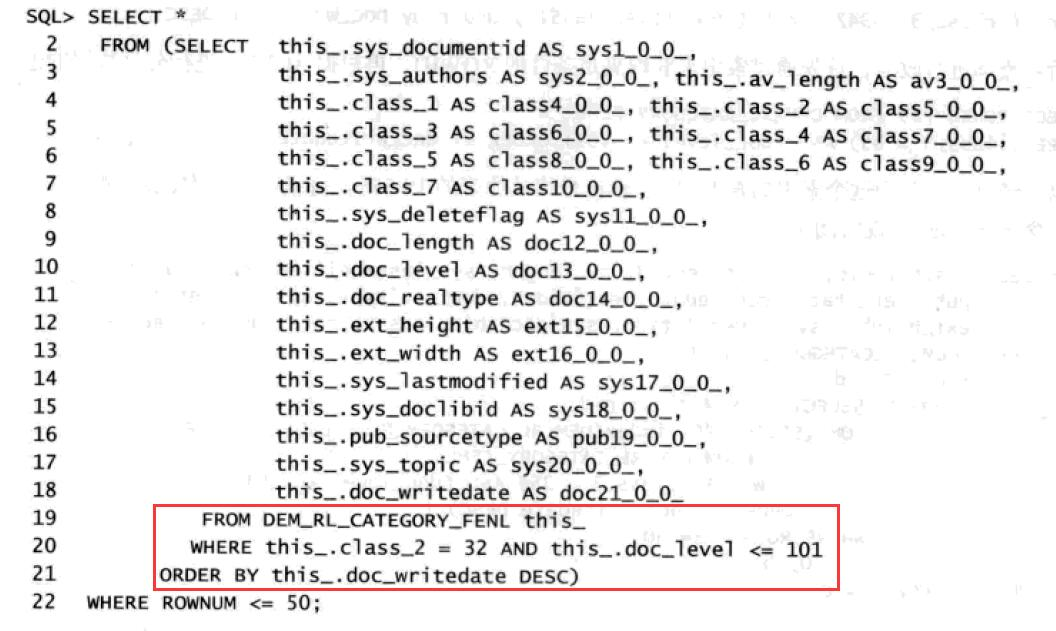
原作者对这个SQL的优化建议是:

原作者把原来的top n写法改成4层的分页查询, 我个人认为有点多余:
如果原SQL是一个分页查询多次翻页的SQL,那么这个改写完全没有问题,在页数较大时,比普通分页的3层标准分页写法会有较大的性能提升;
但是原SQL只是取top n,不存在翻页, 改写后的SQL不会因为改写发生任何性能提升,这里有点生搬硬套的感觉.
再说说组合索引的建议,最佳的索引组合我认为是这样的:
如果doc_level<=101 的选择性比较好, 那么可以创建class_3 + doc_level 两字段组合索引 ;
如果doc_level<=101 的选择性不好, 那么可以创建 class_3 + doc_writedate + doc_level 3字段组合索引(虽然sql中有order by doc_writedate desc,但是也不需要加desc);
原作者的建议是 class_3 + doc_level + doc_writedate desc 3字段组合索引, 这个组合索引,最后的doc_writedate desc是没有任何意义的, 不能起到过滤作用, 也不能去掉排序(执行计划中的sort order by还在).
如果doc_level不是<=101,而是=101 ,那么可以创建class_3 + doc_level + doc_writedate,避免执行计划中的sort order by,也是不需要加desc的.
总结:
除非必要,不要创建desc降序索引. 索引,关系型数据库的一个非常重要的理论,还需要大家深入理解.
如果有这方面的学习需求,可以购买本人的2天索引专题线上培训视频与教学材料, 培训相关的介绍请参考 < 索引专题培训 >
福利时间:
【北京大学出版社】给大家带来《Oracle高性能系统架构实战大全》技术书籍福利,助力大家更好的学习Oracle数据库技术。

本书特点:
1、 深入浅出:详解与 Oracle 数据库性能相关的方方面面,涵盖 Oracle 的体系架构及其背后的运行机制。
2、直击难点:全面解析Oracle SQL 执行计划和Oracle SQL 性能分析与优化。
3、全新实战:真实有效的实战案例再现Oracle数据库开发过程中的问题及解决思路。
4、双管齐下:先设定方案,然后从应用角度和数据库角度综合考虑,逐一分析实现环境。
送书规则:留言说说你对Oracle索引或是性能优化相关技术的看法,精选留言点赞数前4名的读者将分别获此赠书一本。
截止时间:2020年8月13日12:30,中奖的读者需于8小时内主动联系本人(微信号: ora_service)发送快递信息,逾期则视为自动放弃获赠资格。
购买链接:http://product.dangdang.com/28527631.html
(点击文末的"阅读原文"也可到达)
备注:本活动仅公众号读者参与,短时间内赞数爆增或有刷赞行为均视为无效。
本人之前购买并拜读了这本书,作者从架构师的角度,介绍了Oracle数据库性能相关的各个方面,值得广大Oracle技术爱好者一读.
在阅读过程中, 我也发现了书中的一些小瑕疵,下面列举几个(蓝色是原文):
P154: "分区键必须是本地唯一索引的前缀列",这个说法不准确,分区表的本地唯一索引,只要包含分区键即可,跟分区键位置无关.
P162: /*+ parallel(r 4) */的SQL,"oracle 会启动1个PX协调器,4个生产者,3个消费者" ,应该是4个消费者.
P440: "在外连接中,主表和驱动表并无关系,并不是主表一定就要做驱动表",这个说法不够准确,外连接的驱动表一定是主表, hash join有时你可能看到构建表不是主表,那是因为优化器又做了swap_join_inputs,执行计划outline data里面的leading一定是主表; 如果是Nested Loops, 驱动表就一定是主表了.
P505:"如果希望departments和job_history作为前两张驱动表,但是不关心具体谁先谁后,可以指定/*+ leading(e j) */" ,这个说法是对leading hint的误解,这个hint就是要让e表做第一位的驱动表.
P520:"遗憾的是,目前还无法在系统或者会话层面通过系统参数进行控制,另一种取巧的方式就是对于复杂的非OLTP类SQL使用硬编码". 这是对bind_aware hint的一个描述, 这个hint其实是可以通过sql_patch对已经上线的SQL做修正, 不论是否OLTP,都可以不用改代码.
P542:"select t.*,rownum rn from t_tasklog t where rownum<6 order by tasklog_id desc; 单纯从SQL语句来说没有问题,毕竟在进行分页查询时都是这么写的." 上面的sql写法,rownum和order在同一个select层,大部分情况在逻辑上是有问题的,这个逻辑是先随机取5条记录再排序, 而一般的业务逻辑是全部结果集排序再取前5条,需要写两层的select.
(完)
以上观点都是本人一家之言,欢迎大家留言批评指正,不胜感激!
