




概述
MySQL的高可用架构,经历了很多年,也经历过非常多的故事。其中比较有名的有Mysql+keep alive、MHA、MGR、PXC等高可用架构。
在2018年时,闲逛GitHub时发现GitHub官方开源了一款高可用的中间件,于是,在公司后继系统上,都采用了这款中间件。
在此之前,写过一篇关于orchestrator的文章,所以此篇是对以前的深入理解与实践。放上原来写的文章:《Orchestrator浅析》
为了防止遗忘,所以,在此记录深入理解和实践经验。
介绍
orchestrator 是一个由Go语言编写的MySQL高可用管理和复制拓补显示工具,它后端使用MySQL或SQLite存储实时变化的元数据信息,这些元数据信息包括监听对外服务的MySQL,也包括它自身后端的MySQL。
它提供了一个Web界面,可以在界面上使用鼠标非常简便的更改复制拓补结构,更新部分配置等。
同时,提供了非常多的预先封装好的命令以供用户使用,我们可以在钩子函数的脚本里使用这些命令,可以非常便捷的触发失败failvoer脚本或其他failover过程脚本,这些会在文章中讲述。
Orchestrator相比MHA、MySQL+keep alive,最大的痛点就是解决了管理节点单点问题,自身可以使用reft协议来保证自身高可用性,而且单点或多点Orchestrator更是解决了脑裂的问题。
这款中间件最可靠的地方,就是它是由GitHub官方出品,其中GitHub的一部分业务也是使用Orchestrator来管理的。
这里附上Orchestrator的地址:《Orchestrator地址》
Orchestrator结构
Orchestrator本身可以单点部署和多点部署,这我们在之前有提到,生产环境建议使用多点非共享架构,开启reft保证Orchestrator自身高可用。
同时需要注意的是,Orchestrator的server端需要和对外提供服务的MySQL放在一起的,Orchestrator的专属后端可以放到远程服务器上,这点在配置文件中也有体现。
这里着重描述Orchestrator下单点和多点点架构:
注:这里的MySQL指的是Orchestrator本身的后端存储,不与提供服务的MySQL有任何联系。
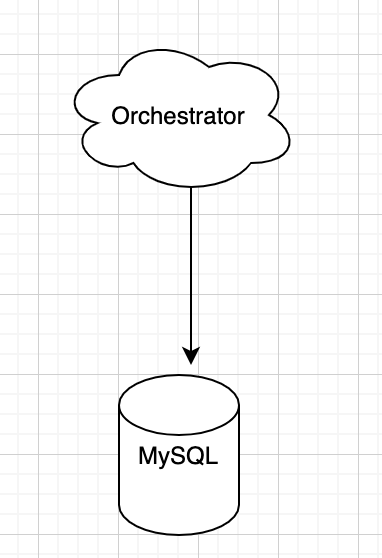
单点模式
单个Orchestrator对应单个后端MySQL
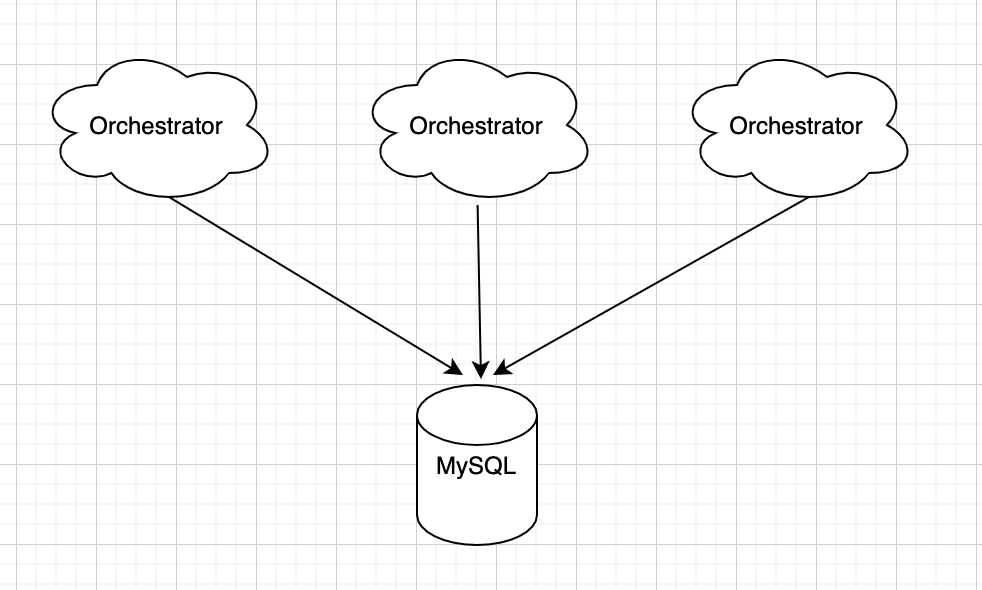
多点共享后端有两种:
1、后端可以为单点写或者主从模式,多个Orchestrator共享一个写节点后端
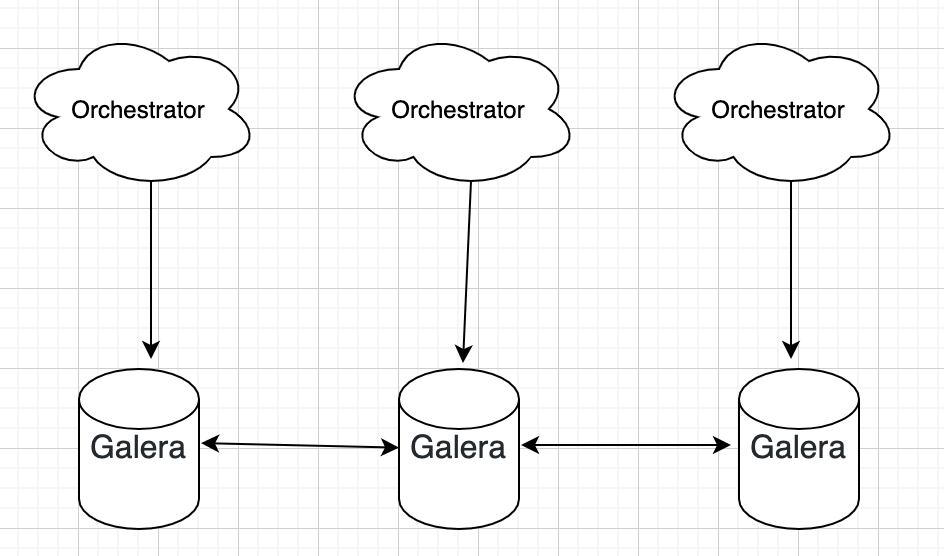
2、后端为多点写集群模式,Orchestrator之间数据相互同步
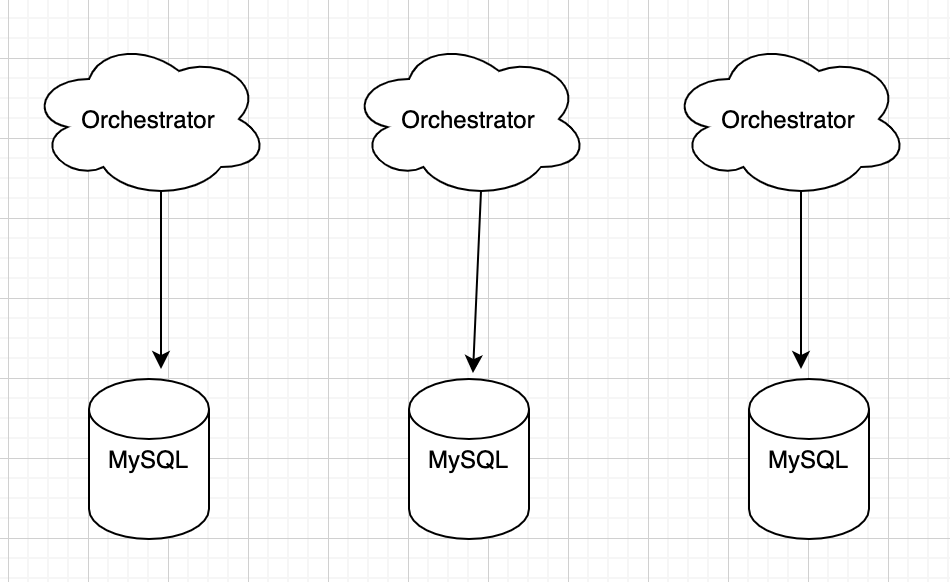
多点非共享后端
后端相互独立,每个后端为自己的Orchestrator提供服务
部署
本机环境(单节点Orchestrator+MySQL主从):
系统:CentOs
Orchestrator:172.16.150.131
master:172.16.150.133
slave:172.16.150.134
mater,slave端口:3307
Orchestrator后端MySQL端口:3306
安装
请根据合适自己的系统进行安装,这里是CentOs的系统,使用rpm包安装,默认安装目录在/usr/local/orchestrator下
--安装依赖: [root@localhost ~]# yum install -y jq [root@localhost opt]# rpm -ivh orchestrator-3.2.2-1.x86_64.rpm 准备中... ################################# [100%] 正在升级/安装... 1:orchestrator-1:3.2.2-1 ################################# [100%] [root@localhost opt]# [root@localhost opt]# cd /usr/local/orchestrator/ [root@localhost orchestrator]# ll -lih 总用量 19M 23246026 -rwxr-xr-x. 1 root root 19M 6月 21 20:32 orchestrator 23246048 -rw-rw-r--. 1 root root 5.4K 6月 16 15:54 orchestrator-sample.conf.json 23246027 -rw-rw-r--. 1 root root 5.0K 6月 4 18:38 orchestrator-sample-sqlite.conf.json 35226657 drwxr-xr-x. 7 root root 82 8月 14 08:11 resources [root@localhost orchestrator]# [root@localhost orchestrator]# root@localhost orchestrator]# cp -a orchestrator-sample.conf.json orchestrator.conf.json
文件及目录说明:
orchestrator:执行程序
*.json:配置模版
resources:存放web等相关文件
配置说明
{
"Debug": true, #debug模式,输出详细信息
"EnableSyslog": false, #是否输出到系统日志里
"ListenAddress": ":3000", #orchestrator的监听端口,web端口
"MySQLTopologyUser": "failover", #后端被管理的mysql实例中的账号,所有实例都要有,本次为3307端口
"MySQLTopologyPassword": "123456", #密码
"MySQLTopologyCredentialsConfigFile": "", #验证的配置文件,账号密码可以直接写入文件,读取
"MySQLTopologySSLPrivateKeyFile": "", #ssl验证文件
"MySQLTopologySSLCertFile": "",
"MySQLTopologySSLCAFile": "",
"MySQLTopologySSLSkipVerify": true, #跳过验证
"MySQLTopologyUseMutualTLS": false, #使用TLS验证
"MySQLOrchestratorHost": "127.0.0.1", #orchestrator的IP,也可以是本机IP
"MySQLOrchestratorPort": 3306, #orchestrator所在的端口,本次为3306端口
"MySQLOrchestratorDatabase": "orchestrator", #orchestrator元数据的数据库名称
"MySQLOrchestratorUser": "root", #管理orchestrator数据库的账户
"MySQLOrchestratorPassword": "123456", #密码
"MySQLOrchestratorCredentialsConfigFile": "",
"MySQLOrchestratorSSLPrivateKeyFile": "",
"MySQLOrchestratorSSLCertFile": "",
"MySQLOrchestratorSSLCAFile": "",
"MySQLOrchestratorSSLSkipVerify": true,
"MySQLOrchestratorUseMutualTLS": false,
"MySQLConnectTimeoutSeconds": 1, #orchestrator连接mysql超时秒数
"DefaultInstancePort": 3307, #mysql实例的端口,本次为3307,对外提供服务的实例
"DiscoverByShowSlaveHosts": true, #是否启用审查和自动发现
"InstancePollSeconds": 5, #orchestrator探测mysql间隔秒数
"SkipMaxScaleCheck": true, #没有MaxScale binlogserver设置为true
"UnseenInstanceForgetHours": 240, #忘记看不见的实例的小时数
"SnapshotTopologiesIntervalHours": 0, #快照拓扑调用之间的小时间隔。默认值:0(禁用)
"InstanceBulkOperationsWaitTimeoutSeconds": 10, #执行批量(多个实例)操作时在单个实例上等待的时间
"HostnameResolveMethod": "none", #解析主机名,默认default 不解析为none
"MySQLHostnameResolveMethod": "@@hostname", #MySQL主机名解析
"SkipBinlogServerUnresolveCheck": true, #跳过二进制服务器检测
"ExpiryHostnameResolvesMinutes": 60, #域名检测过期分钟数
"RejectHostnameResolvePattern": "", #禁止的域名正则表达式
"ReasonableReplicationLagSeconds": 10, #复制延迟高于10秒表示异常
"ProblemIgnoreHostnameFilters": [], #主机正则匹配筛选最小化
"VerifyReplicationFilters": false, #重构钱检查复制筛选器
"ReasonableMaintenanceReplicationLagSeconds": 20, #上移和下移的阈值
"CandidateInstanceExpireMinutes": 60, #实例过期分钟数
"AuditLogFile": "", #审计日志
"AuditToSyslog": false, #审计日志输出到系统日志
"RemoveTextFromHostnameDisplay": ":3306", #去除集群的文本
"ReadOnly": true, #全局只读
"AuthenticationMethod": "", #身份验证模式
"HTTPAuthUser": "", #http验证用户名
"HTTPAuthPassword": "", #http验证密码
"AuthUserHeader": "", #指示身份验证用户的HTTP标头,当AuthenticationMethod为“proxy”时
"PowerAuthUsers": [ #在AuthenticationMethod ==“proxy”上,可以进行更改的用户列表。所有其他都是只读的。
"*"
],
"ClusterNameToAlias": { #正则表达式匹配群集名称与别名之间的映射
"127.0.0.1": "test suite"
},
"SlaveLagQuery": "", #使用SHOW SLAVE STATUS进行延迟判断
"DetectClusterAliasQuery": "SELECT SUBSTRING_INDEX(@@hostname, '.', 1)", #查询集群别名
"DetectClusterDomainQuery": "", #可选查询(在拓扑实例上执行),返回此集群主服务器的VIP / CNAME /别名/任何域名。查询将仅在集群主机上执行(尽管在拓扑的主机被重新调用之前,它可以在其他/所有副本上执行)。如果提供,必须返回一行,一列
"DetectInstanceAliasQuery": "", #可选查询(在拓扑实例上执行),返回实例的别名。如果提供,必须返回一行,一列
"DetectPromotionRuleQuery": "", #可选查询(在拓扑实例上执行),返回实例的提升规则。如果提供,必须返回一行,一列。
"DataCenterPattern": "[.]([^.]+)[.][^.]+[.]mydomain[.]com", #从正则表达式中筛选数据中心名称
"PhysicalEnvironmentPattern": "[.]([^.]+[.][^.]+)[.]mydomain[.]com", #返回实例的物理环境
"PromotionIgnoreHostnameFilters": [], #Orchestrator不会使用主机名匹配模式来提升副本(通过-c recovery;例如,避免使用dev专用计算机)
"DetectSemiSyncEnforcedQuery": "", #查询以确定是否强制完全半同步写入
"ServeAgentsHttp": false, #产生一个agent的http接口
"AgentsServerPort": ":3001", #可选,对于raft设置,此节点将向其对等方通告的HTTP地址是什么(可能在NAT后面或重新路由端口时使用;例如:“http://11.22.33.44:3030”)
"AgentsUseSSL": false, #当“true”orchestrator将使用SSL侦听代理端口以及通过SSL连接到代理时
"AgentsUseMutualTLS": false,
"AgentSSLSkipVerify": false,
"AgentSSLPrivateKeyFile": "",
"AgentSSLCertFile": "",
"AgentSSLCAFile": "",
"AgentSSLValidOUs": [],
"UseSSL": false, #在服务器Web端口上使用SSL
"UseMutualTLS": false,
"SSLSkipVerify": false,
"SSLPrivateKeyFile": "",
"SSLCertFile": "",
"SSLCAFile": "",
"SSLValidOUs": [],
"URLPrefix": "", #在非根Web路径上运行orchestrator的URL前缀,例如/ orchestrator将其置于nginx之后。
"StatusEndpoint": "/api/status", #使用相互TLS时的有效组织单位
"StatusSimpleHealth": true,
"StatusOUVerify": false,
"AgentPollMinutes": 60, #代理轮询之间的分钟数
"UnseenAgentForgetHours": 6, #忘记看不见代理的小时数
"StaleSeedFailMinutes": 60, #认为陈旧(无进展)种子失败的分钟数。
"SeedAcceptableBytesDiff": 8192, #仍被视为成功复制的种子源和目标数据大小之间的字节数差异
"PseudoGTIDPattern": "", #为空禁用伪GTID
"PseudoGTIDPatternIsFixedSubstring": false, #如果为true,则PseudoGTIDPattern不被视为正则表达式而是固定子字符串,并且可以提高搜索时间
"PseudoGTIDMonotonicHint": "asc:", #Pseudo-GTID条目中的子字符串,表示Pseudo-GTID条目预计会单调递增
"DetectPseudoGTIDQuery": "", #可选查询,用于权威地决定是否在实例上启用伪gtid
"BinlogEventsChunkSize": 10000, #SHOW BINLOG的块大小(X)| RELAYLOG EVENTS LIMIT?,X语句。较小意味着更少的锁定和工作要做
"SkipBinlogEventsContaining": [], #扫描/比较Pseudo-GTID的binlog 时,跳过包含给定文本的条目。这些不是正则表达式(扫描binlog时会消耗太多的CPU),只需查找子字符串。
"ReduceReplicationAnalysisCount": true, #当为true时,复制分析将仅报告可能首先处理问题的可能性的实例(例如,不报告大多数叶子节点,这些实际上是无趣的)。如果为false,则为每个已知实例提供一个条目
"FailureDetectionPeriodBlockMinutes": 60, #该时间内发现故障,不被多次发现
"RecoveryPeriodBlockSeconds": 3600, #该时间内发现故障,不会多次转移
"RecoveryIgnoreHostnameFilters": [], #恢复会忽略的主机
"RecoverMasterClusterFilters": [ #仅在匹配这些正则表达式模式的集群上进行主恢复(当然“。*”模式匹配所有内容)
"*"
],
"RecoverIntermediateMasterClusterFilters": [ #仅在与这些正则表达式模式匹配的集群上进行IM恢复(当然“。*”模式匹配所有内容)
"*"
],
#OnFailureDetectionProcesses:检测故障转移方案时执行的进程(在决定是否进行故障转移之前)。可以并且应该使用其中一些占位符:{failureType},{failureDescription},{command},{failedHost},{failureCluster},{failureClusterAlias},{failureClusterDomain},{failedPort},{successorHost},{successorPort},{ successorAlias},{countReplicas},{replicaHosts},{isDowntimed},{autoMasterRecovery},{autoIntermediateMasterRecovery}
"OnFailureDetectionProcesses": [
"echo 'Detected {failureType} on {failureCluster}. Affected replicas: {countSlaves} autoMasterRecovery: {autoMasterRecovery} losthost: {lostSlaves} slavehost: {slaveHosts} orchestratorHost: {orchestratorHost}' >> /tmp/recovery.log"
],
#PreGracefulTakeoverProcesses:在执行故障转移之前执行的进程(中止操作应该是任何一次以非零代码退出;执行顺序未定义)。可以并且应该使用其中一些占位符:{failureType},{failureDescription},{command},{failedHost},{failureCluster},{failureClusterAlias},{failureClusterDomain},{failedPort},{countReplicas},{replicaHosts},{ isDowntimed}
"PreGracefulTakeoverProcesses": [
"echo 'Planned takeover about to take place on {failureCluster}. Master will switch to read_only autoMasterRecovery: {autoMasterRecovery} losthost: {lostSlaves} slavehost: {slaveHosts} orchestratorHost: {orchestratorHost}' >> /tmp/recovery.log"
],
#PreFailoverProcesses:在执行故障转移之前执行的进程(中止操作应该是任何一次以非零代码退出;执行顺序未定义)。可以并且应该使用其中一些占位符:{failureType},{failureDescription},{command},{failedHost},{failureCluster},{failureClusterAlias},{failureClusterDomain},{failedPort},{countReplicas},{replicaHosts},{ isDowntimed}
"PreFailoverProcesses": [ #执行恢复操作前执行
"echo 'Will recover from {failureType} on {failureCluster}' >> /tmp/recovery.log"
],
#PostFailoverProcesses:执行故障转移后执行的进程(执行顺序未定义)。可以并且应该使用其中一些占位符:{failureType},{failureDescription},{command},{failedHost},{failureCluster},{failureClusterAlias},{failureClusterDomain},{failedPort},{successorHost},{successorPort},{ successorAlias},{countReplicas},{replicaHosts},{isDowntimed},{isSuccessful},{lostReplicas},{countLostReplicas}
"PostFailoverProcesses": [
"echo '(for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
#PostUnsuccessfulFailoverProcesses:在未完全成功的故障转移后执行的进程(执行顺序未定义)。可以并且应该使用其中一些占位符:{failureType},{failureDescription},{command},{failedHost},{failureCluster},{failureClusterAlias},{failureClusterDomain},{failedPort},{successorHost},{successorPort},{ successorAlias},{countReplicas},{replicaHosts},{isDowntimed},{isSuccessful},{lostReplicas},{countLostReplicas}
"PostUnsuccessfulFailoverProcesses": [],
#PostMasterFailoverProcesses:执行主故障转移后执行的进程(执行顺序未定义)。使用与PostFailoverProcesses相同的占位符
"PostMasterFailoverProcesses": [
"echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Promoted: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
#PostIntermediateMasterFailoverProcesses:执行主故障转移后执行的进程(执行顺序未定义)。使用与PostFailoverProcesses相同的占位符
"PostIntermediateMasterFailoverProcesses": [ #成功的中间主恢复时执行
"echo 'Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
#PostGracefulTakeoverProcesses:在运行正常的主接管后执行的进程。使用与PostFailoverProcesses相同的占位符
"PostGracefulTakeoverProcesses": [ #旧主位于新主之后执行
"echo 'Planned takeover complete' >> /tmp/recovery.log"
],
"CoMasterRecoveryMustPromoteOtherCoMaster": true, #当'false'时,任何东西都可以升级(候选人优先于其他人)。当'为'时,orchestrator将促进其他共同主人或否则失败
"DetachLostSlavesAfterMasterFailover": true, #恢复可能丢失一些副本DetachLostReplicasAfterMasterFailover的同义词
"ApplyMySQLPromotionAfterMasterFailover": true, #orchestrator应该自己应用MySQL主促销:设置read_only = 0,分离复制等。
"PreventCrossDataCenterMasterFailover": false, #当为true(默认值:false)时,不允许跨DC主故障转移,orchestrator将尽其所能只在同一DC内进行故障转移,否则根本不进行故障转移。
"MasterFailoverDetachSlaveMasterHost": false, #确保新主不复制旧主的数据MasterFailoverDetachReplicaMasterHost的同义词
"MasterFailoverLostInstancesDowntimeMinutes": 0, #在主故障转移(包括失败的主副本和丢失的副本)之后丢失的任何服务器停机的分钟数。0表示禁用
"PostponeSlaveRecoveryOnLagMinutes": 0, #PostponeReplicaRecoveryOnLagMinutes的同义词
"OSCIgnoreHostnameFilters": [], #OSC副本推荐将忽略与给定模式匹配的副本主机名
"GraphiteAddr": "",
"GraphitePath": "",
"GraphiteConvertHostnameDotsToUnderscores": true,
"RaftEnabled": true, #raft模式
"BackendDB": "mysql", #后台数据库类型
"RaftBind": "172.16.150.133", #绑定之地,本机IP
"RaftDataDir": "/var/lib/orchestrator", #数据目录,如果不存在,则自动创建
"DefaultRaftPort": 10008, #raft通信端口,所有机器必须保持一致
"RaftNodes": [ #raft节点,必须包含所有节点
"172.16.150.133",
"172.16.150.134",
"172.16.150.135"
],
"ConsulAddress": "", #找到Consul HTTP api的地址。示例:127.0.0.1:8500
"ConsulAclToken": "" #用于写入Consul KV的ACL令牌
}
以上配置根据自己需要进行配置,下面来介绍一下必须要修改的配置,其他可以使用默认:
ListenAddress:web界面监控的端口,修改之后同时需要修改orchestrator的API地址 MySQLTopologyUser:后端对外提供服务的MySQL中需要的用户名 MySQLTopologyPassword:上面用户的密码 MySQLOrchestratorHost:orchestrator主机的IP,也可以是本机IP MySQLOrchestratorPort:专属orchestrator的MySQL所在的端口 MySQLOrchestratorDatabase:存放orchestrator元数据的数据库名称 MySQLOrchestratorUser:管理orchestrator数据库的账户,创建在专属orch的数据库上 MySQLOrchestratorPassword:上面用户的密码 DefaultInstancePort:mysql实例的端口,对外提供服务的实例 DiscoverByShowSlaveHosts:启用自动发现 InstancePollSeconds:orchestrator探测mysql间隔秒数 HostnameResolveMethod:解析主机名,默认default。有三种模式:default、cnanme、none。cnanme就是解析主机的cname。none就是什么也不做。 MySQLHostnameResolveMethod:有三种模式:@@hostname、@@report_host、“”(设置为空)。@@hostname就是对MySQL发出一次“SELECT @@hostname”对命令。@@report_host需要在配置文件中配置当前MySQL的IP和端口,由于这种方式不易后续维护,一般不使用。设置为空,就是什么也不做。 DetectClusterAliasQuery:使用SQL语句对MySQL进行查询,一般都是查询hostname,也可以创建一个叫做meta的库,下面放一张集群表,写入对应的信息,然后修改这里的SQL,让orchestrator把同一个集群名认为是一个集群,更好的辅助failover。 RecoverMasterClusterFilters:失败恢复的正则匹配,可以是*,也可以正则匹配到主机 RaftEnabled:reft模式,需要最少三个节点,如果开启,参考上面整个配置文件中的最后面的配置
其外,还有一些在失败恢复时的钩子函数,如果只做主从结构转移,默认足够,如果还要做其他动作,那么需要自己配置脚本,钩子函数在后面细说。
部署
那么,接下来开始真正的部署环节,首先,需要在对外提供服务的MySQL服务器上创建用户,使orchestrator可以检测到该MySQL,从而绘制拓补图。
CREATE USER 'orch_discover'@'172.16.150.%' IDENTIFIED BY '123456';
GRANT SUPER, PROCESS, REPLICATION SLAVE, REPLICATION CLIENT, RELOAD ON *.* TO 'orch_discover'@'172.16.150.%';
CREATE DATABASE meta;
GRANT SELECT ON meta.* TO 'orch_discover'@'172.16.150.%';
---创建集群别名
CREATE TABLE meta.cluster (
anchor TINYINT NOT NULL,
cluster_name VARCHAR(128) CHARSET ascii NOT NULL DEFAULT '',
cluster_domain VARCHAR(128) CHARSET ascii NOT NULL DEFAULT '',
PRIMARY KEY (anchor)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO cluster (anchor, cluster_name, cluster_domain) VALUES (1, '你的集群名称', '你的集群域');
---这里的cluster表对应DetectClusterAliasQuery这个参数,配置SQL选取这个表以查询当前集群,如:"select ifnull(max(cluster_name), '') as cluster_alias from meta.cluster where anchor=1"
在Orchestrator专属后端MySQL上创建用户:
CREATE USER 'orch_manager'@'172.16.150.%' IDENTIFIED BY '123456';
GRANT ALL ON orchestrator.* TO 'orch_manager'@'172.16.150.%';
写入/etc/hosts文件:
[root@localhost ~]# cat /etc/hosts|grep -v local 172.16.150.133 master 172.16.150.134 slave [root@localhost ~]#
为避免篇幅太长,这里只附上我修改的配置文件配置,其他都为默认参数:
[root@slave orchestrator]# cat orchestrator.conf.json { "MySQLTopologyUser": "orch_discover", "MySQLTopologyPassword": "123456", "MySQLTopologyUseMixedTLSis": false, "MySQLOrchestratorHost": "172.16.150.134", "MySQLOrchestratorPort": 13309, "MySQLOrchestratorDatabase": "orchestrator", "MySQLOrchestratorUser": "orch_manager", "MySQLOrchestratorPassword": "123456", "HostnameResolveMethod": "none", "MySQLHostnameResolveMethod": "", "DetectClusterAliasQuery": "select ifnull(max(cluster_name), '') as cluster_alias from meta.cluster where anchor=1", "RecoverMasterClusterFilters": [ "*" ] } [root@slave orchestrator]# 说明:HostnameResolveMethod和MySQLHostnameResolveMethod这两个发现参数,我都设置的手动发现(即都一个为none,一个为空),是因为我的MySQL的hostname是localhost,且主机的hostname也没修改,所以要用用IP地址。根据自己需求,修改这两个参数。
当以上配置项都配置完成之后,我们启动Orchestrator:
[root@slave orchestrator]# nohup ./orchestrator --config orchestrator.conf.json http &
在浏览器中访问:http://你的IP:3000,进入到Orchestrator的Web管理界面:
这里需要手动发现一下,可以在Web界面上操作,也可以使用命令行发现。
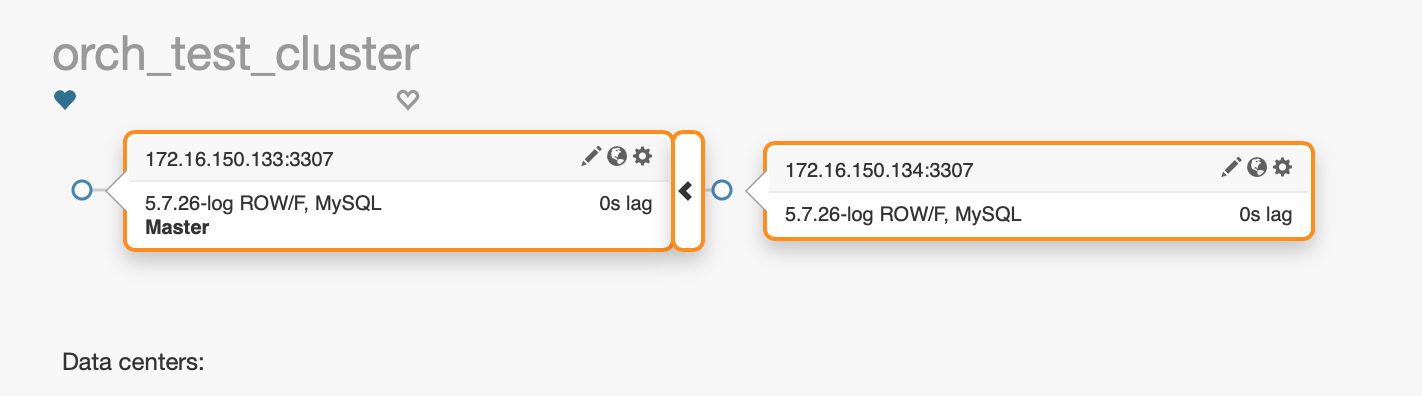
最终拓补结构:
至此,Orchestrator的基本配置讲解完毕,具体参数设置,需要自己根据实际需求配置。下篇将讲解Orchestrator的API命令,以及failover的钩子函数等。
