




分区概述
分区引入分区键 Partition Key,根据此键使数据规则的分布在不同的分区中。
分区优点:
1、 和单个磁盘或者文件系统分区相比,能存储更多数据
2、 优化查询,在where子句中包含分区条件条件时,可以只扫描特定的分区提高查询效率。如果遇到SUM()和COUNT()这类聚合函数的查询时,可以容易地在各个分区上并行处理
3、 对于需要删除的数据,可以通过删除分区快速删除
4、 跨磁盘分散数据查询,获得更大的查询吞吐量
在Mysql 5.7以后,同一个分区表的所有分区必须同一个存储引擎。分区数量不能超过8192,NDB除外。
create table emp(empid int,salary decimal(7,2),birth_date date)
engine=innodb
partition by hash(month(birth_date))
partitions 6;
MySQL的分区适用一个表中的所有数据和索引,不能只对表数据或者索引进行分区。也不能只对一部分数据进行分区。分区表上的索引一定是本地LOCAL索引。
分区分类
RANG分区:给定连续范围,分区键必须INT类型。
LIST分区:给定枚举值,分区键必须INT类型。
COLUMNS分区:分区键可以多列,也可以非整数。
HASH分区:给定分区数,基于HASH算法分配。分区键必须INT类型。
KEY分区:给定分区数,基于MySql的的HASH算法分配。
子分区:复合或者组合分区,主分区下再进行分区。
所有分区类型,分区表上没有主键或者唯一键,否则必须作为分区键。
大小写敏感
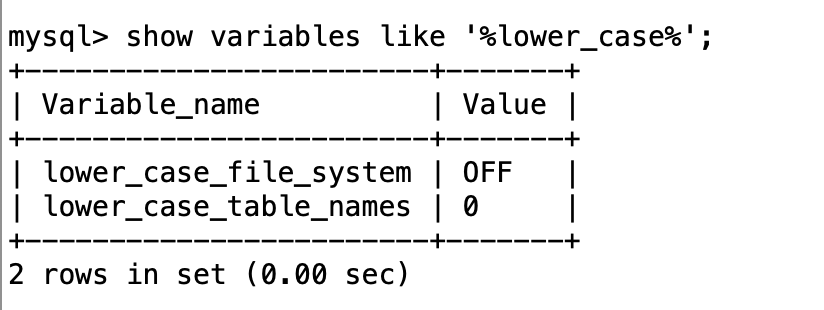
关于库名和表名大小写敏感。
lower_case_file_system不可修改的变量,表示操作系统是否大小写敏感,OFF代表敏感,ON代表不敏感。
lower_case_table_names代表数据库的库名和表名是否大小写敏感,1表示敏感,0表示不敏感。
如果操作系统敏感,那么数据库表名和库名是否敏感由lower_case_table_names决定。
如果操作系统不敏感,那么lower_case_table_names应该设置为1,即不敏感。
但是无论以上参数如何设置,列名,别名,分区名这些是不区分大小写的。
RANGE分区
create table zwy_test(
id int not null,
ename varchar(30),
hired DATE not null default ‘1970-01-01’,
separated DATE not null default ‘9999-12-31’,
job varchar(30) not null,
store_id int not null
)
partition by range(store_id)
(
partition p0 values less than(10),
partition p1 values less than(20),
partition p2 values less than(30)
);

这种情况就是超过该range范围包含的区域,可以通过加入VALUES LESS THAN MAXVALUE。
alter table zwy_test add partition (partition p3 values less than maxvalue);
适用场景:
1、 删除数据时,删除一个分区比delete更有效率。
2、 可以根据包含分区键的查询语句,仅查询一个或者部分分区,提高查询效率。

LIST分区
每个分区对应一个枚举的集合,只能输入这些指定的值。
create table list_test(
id int not null,
name varchar(30),
store_id int not null default 0
)
partition by list(store_id)(
partition p1 values in (3,5,6,9,17),
partition p2 values in (1,2,10,11,19,20),
partition p3 values in (4,12,13,14,18),
partition p4 values in (7,8,15,16)
);

插入未指定的值报错。
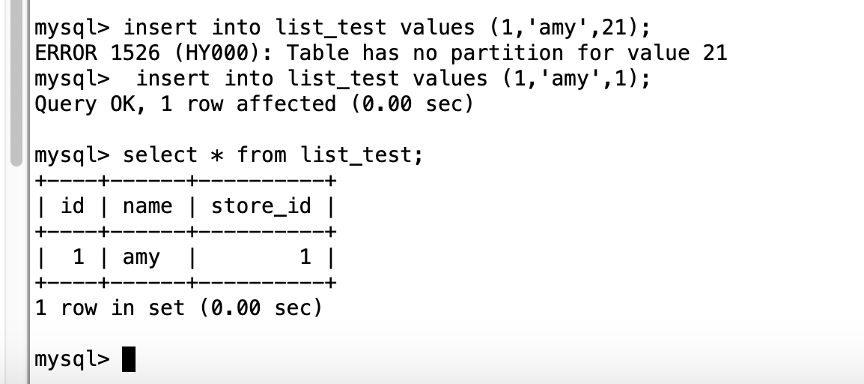

通过information_schema的PARTITIONS可以查看数据库中分区表的信息,以上插入的一行在指定的分区内。
PS:以上均为个人学习之后的理解,如有错误,恳请指正。
学习来源:《深入浅出MySQL第三版》
