




点击关注上方“SQL数据库开发”,
设为“置顶或星标”,第一时间送达干货
大家好,今天分享一个实用的办公脚本:将多个PDF合并为一个PDF,例如我手上现在有如下3个PDF分册,需要整合成一个完整的PDF

如果换成你操作的话,是不是打开百度搜索:PDF合并,然后去第三方网站操作,可能会收费不说还担心文件泄漏,现在有请Python出场,简单快速,光速合并,拿走就用!
首先导入需要的库和路径设置
import osfrom PyPDF2 import PdfFileReader, PdfFileWriterif __name__ == '__main__': # 设置存放多个pdf文件的文件夹 dir_path = r'C:\Scientific Research\Knowladge\Ophthalmology\Chinese Ophthalmology' # 目标文件的名字 file_name = "中华眼科学(第3版)合并版.pdf"
接着获取所有pdf文件的绝对路径,这里需要利用os
库中的os.walk
遍历文件和os.path.join
拼接路径
for dirpath, dirs, files in os.walk(dir_path): print(dirpath) print(files)# 结果返回当前路径、当前路径下文件夹,并以列表返回所有文件
 建议直接将需要合并的pdf放在一个文件夹,这样就无需再对文件后缀进行判断,包装成函数后如下:
建议直接将需要合并的pdf放在一个文件夹,这样就无需再对文件后缀进行判断,包装成函数后如下:
def GetFileName(dir_path): file_list = [os.path.join(dirpath, filesname) \ for dirpath, dirs, files in os.walk(dir_path) \ for filesname in files] return file_list


现在建立合并PDF的函数
def MergePDF(dir_path, file_name): # 实例化写入对象 output = PdfFileWriter() outputPages = 0 # 调用上一个函数获取全部文件的绝对路径 file_list = GetFileName(dir_path) for pdf_file in file_list: print("文件:%s" % pdf_file.split('\\')[-1], end=' ') # 读取PDF文件 input = PdfFileReader(open(pdf_file, "rb")) # 获得源PDF文件中页面总数 pageCount = input.getNumPages() outputPages += pageCount print("页数:%d" % pageCount) # 分别将page添加到输出output中 for iPage in range(pageCount): output.addPage(input.getPage(iPage)) print("\n合并后的总页数:%d" % outputPages) # 写入到目标PDF文件 print("PDF文件正在合并,请稍等......") with open(os.path.join(dir_path, file_name), "wb") as outputfile: # 注意这里的写法和正常的上下文文件写入是相反的 output.write(outputfile) print("PDF文件合并完成")
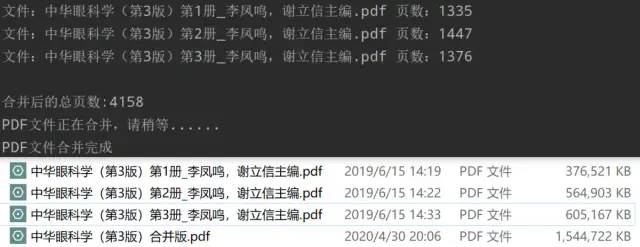
可以看到虽然待合并的PDF文件比较大,但是依旧快速的合并成功!
最后附上完整代码,只需将代码中PDF的路径和文件名修改即可使用!
import osfrom PyPDF2 import PdfFileReader, PdfFileWriterdef GetFileName(dir_path): file_list = [os.path.join(dirpath, filesname) \ for dirpath, dirs, files in os.walk(dir_path) \ for filesname in files] return file_listdef MergePDF(dir_path, file_name): output = PdfFileWriter() outputPages = 0 file_list = GetFileName(dir_path) for pdf_file in file_list: print("文件:%s" % pdf_file.split('\\')[-1], end=' ') # 读取PDF文件 input = PdfFileReader(open(pdf_file, "rb")) # 获得源PDF文件中页面总数 pageCount = input.getNumPages() outputPages += pageCount print("页数:%d" % pageCount) # 分别将page添加到输出output中 for iPage in range(pageCount): output.addPage(input.getPage(iPage)) print("\n合并后的总页数:%d" % outputPages) # 写入到目标PDF文件 print("PDF文件正在合并,请稍等......") with open(os.path.join(dir_path, file_name), "wb") as outputfile: # 注意这里的写法和正常的上下文文件写入是相反的 output.write(outputfile) print("PDF文件合并完成")if __name__ == '__main__': # 设置存放多个pdf文件的文件夹 dir_path = r'C:\Scientific Research\Knowladge\Ophthalmology\Chinese Ophthalmology' # 目标文件的名字 file_name = "中华眼科学(第3版)合并版.pdf" MergePDF(dir_path, file_name)
——End——
后台回复关键字:1024,获取一份精心整理的技术干货 后台回复关键字:进群,带你进入高手如云的交流群。 推荐阅读 这是一个能学到技术的公众号,欢迎关注
 点击「阅读原文」了解SQL训练营
点击「阅读原文」了解SQL训练营文章转载自SQL数据库开发,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
