




本文是一篇译文,介绍 Percona 的工程师对 ScaleFlux 的性能压测报告。
翻译:杨奇龙
最近作者有一个针对 ScaleFlux 的产品也叫做 CSD 2000 进行压测的机会。本文中作者将介绍使用 Intel SSD 和 ScaleFlux 存储设备进行压测的对比结果。
存储设备配置:
ScaleFlux – CSD 2000 4TB
Intel – P4610 3.2TB
服务器配置:
Application server: Supermicro; SYS-6019U-TN4RT
48xIntel(R) Xeon(R) Gold 6126 CPU @ 2.60GHz
190G RAM
Database Server: Inspur; SA5212M4
32xIntel(R) Xeon(R) CPU E5-2640 v3 @ 2.60GHz
64G RAM
innodb_buffer_pool_size=8G
innodb_log_file_size = 2G
max_connections=500
slow_query_log=off
disable_log_bin
innodb_doublewrite=ON/OFF
tmpdir = var/lib/mysql/
innodb_adaptive_hash_index=off
innodb_flush_method=O_DIRECT
innodb_purge_threads=32
sync_binlog=0
max_prepared_stmt_count=4000000
CREATE TABLE `sbtest1` (
`id` int NOT NULL AUTO_INCREMENT,
`k` int NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
`data1` varchar(255) DEFAULT NULL,
`data2` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `k_1` (`k`),
KEY `idx_data1` (`data1`)
) ENGINE=InnoDB AUTO_INCREMENT=9999948 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
index_updates = {
"UPDATE %s%u SET k=?,data1=? WHERE id=?",
t.INT,{t.CHAR,255},t.INT},
non_index_updates = {
"UPDATE %s%u SET c=?,data2=? WHERE id=?",
{t.CHAR,120},{t.CHAR,255},t.INT},
inserts = {
"INSERT INTO %s%u (id, k, c, pad, data1, data2) VALUES (?, ?, ?, ?, ?, ?)",
t.INT, t.INT, {t.CHAR, 120}, {t.CHAR, 60}, {t.CHAR,255}, {t.CHAR,255}},
index_selects = {
"SELECT id,data2 FROM %s%u WHERE data1=?",
{t.CHAR,255}},
update_based_on_data1 = {
"UPDATE %s%u SET data2=? WHERE data1=?",
{t.CHAR,255},{t.CHAR,255}},
default lua scripts – 100 tables – 10ML rows each – 220G
default lua scripts – 1000 tables – 10ML rows – 2.3T
modified lua scripts – 100 tables – 10ML rows each – 440G
modified lua scripts – 540 tables – 10ML rows each – 2.5T
modified lua scripts – 540 tables – 20ML rows each – 4.7T
talk is cheap,我们来看看结果对比图吧。
Default Sysbench – Read/Write – 220G Datasize
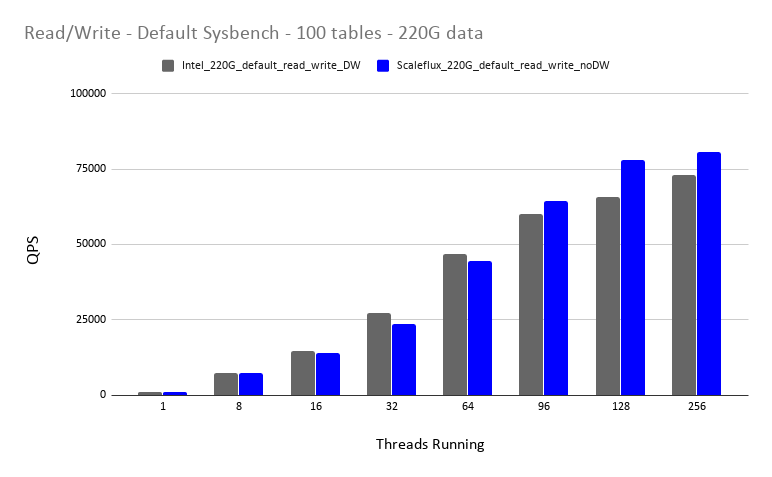
需要说明都是 ScaleFlux 支持原子写,所以作者关闭了 InnoDB Double Write Buffer。而针对 Intel SSD 不支持原子写,InnoDB Double Write Buffer 是开启的。
该场景下,作者使用了添加 2 个字段的压测模型。数据量扩大到 440G,而且使测试数据适合压缩。
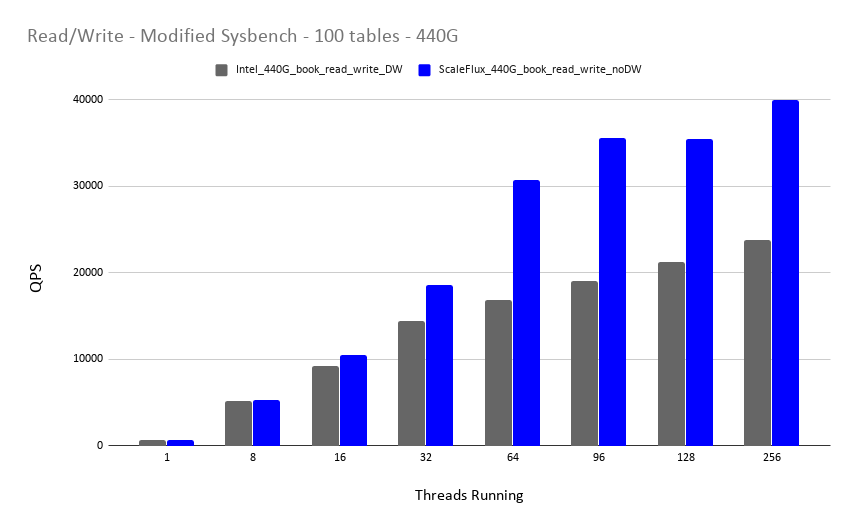
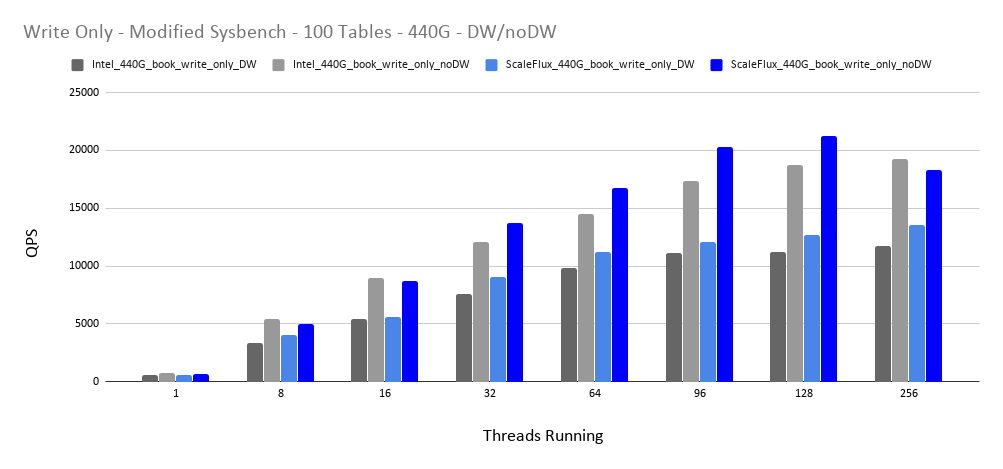
需要注意的是,我们不推荐在任何不支持原子写的设备上关闭 InnoDB Double Write。
Modified Sysbench – Read/Write – 2.5T Datasize
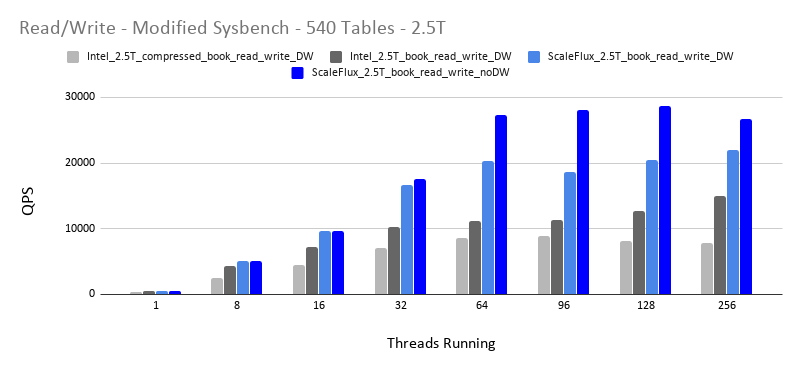
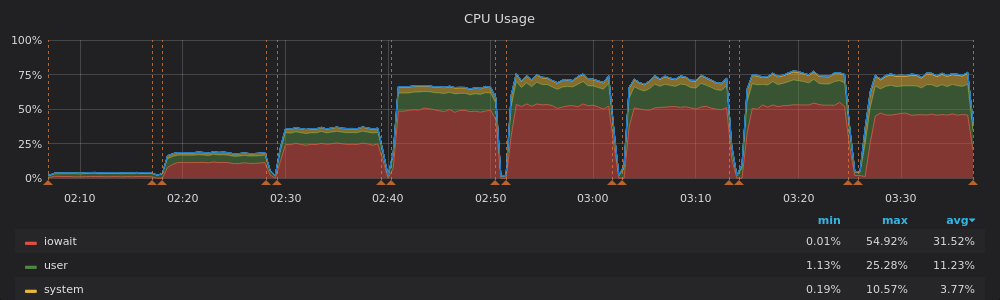
Disk Latency
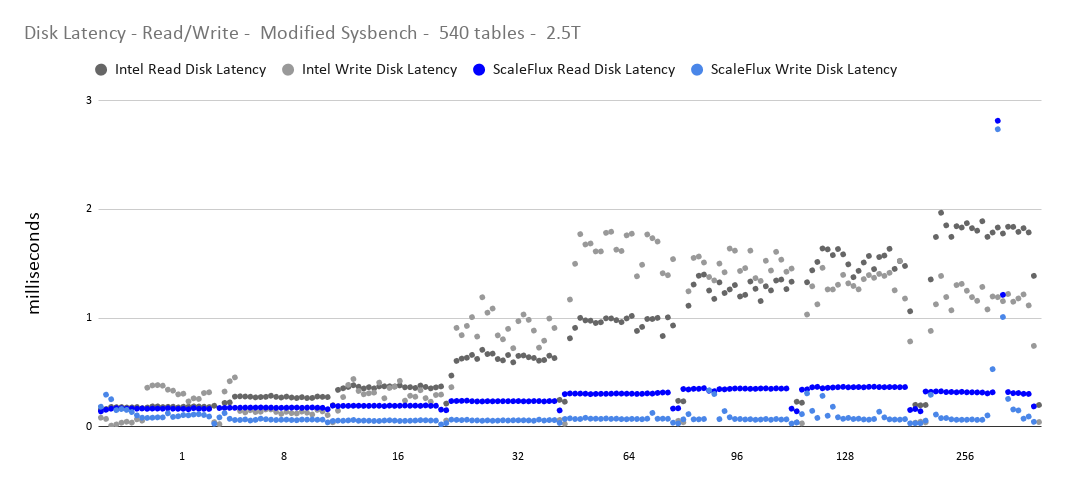
ScaleFlux – Read/Write – Modified Sysbench – 540 tables – 2.5T
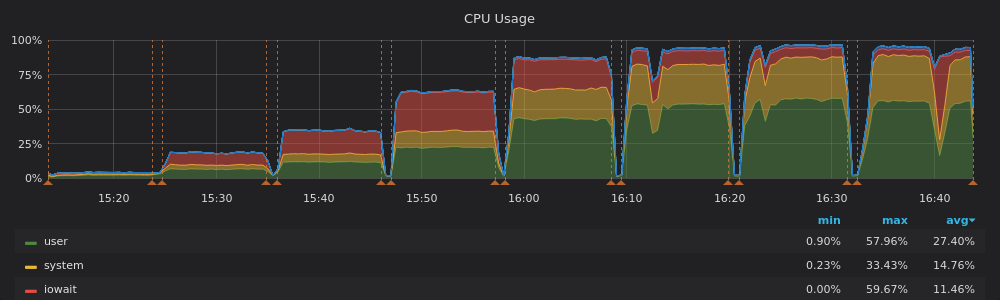
Intel – Read/Write – Modified Sysbench – 540 tables – 2.5T
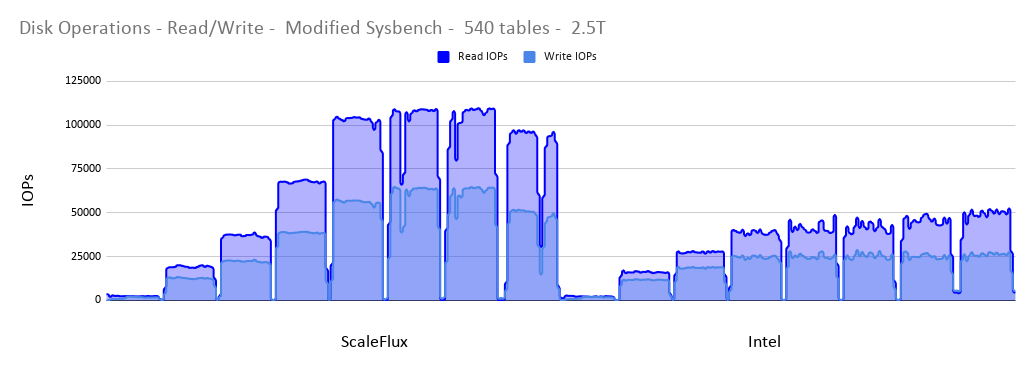
Disk Operations
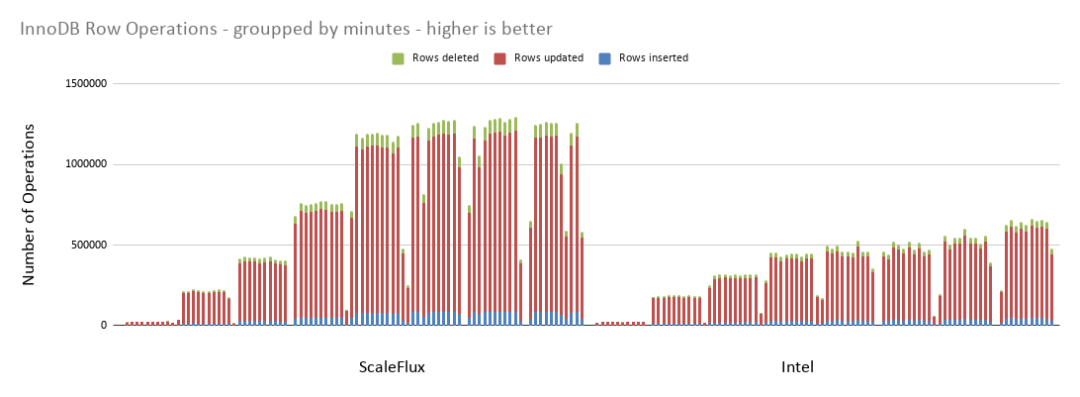
InnoDB Row Operations
关于爱可生
上海爱可生信息技术股份有限公司是国内开源数据库解决方案领导者、工业互联网高维数据应用创新者。爱可生为产业互联网创新应用提供高性价比、快速落地实现的多数据库管理平台、分布式数据库系统、数据库容器云平台、多地多中心跨云容灾等解决方案。
在工业互联网相关垂直行业,深入分析数据价值,构建数据中台和业务中台的基础软件PaaS平台,用数据技术驱动企业高质量增长。公司产品已被广泛应用于各行业,累计用户超过400家,其中包括工商银行、招商银行、中国人寿、中国太保、国家电网、上汽集团、中国移动、华为等30多家世界500强企业。



文章转载自爱可生云数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
