






Spark已成为全球主要行业中功能最强大,需求量最大的主要大数据框架,由于Spark具有可访问性和强大功能,还具有处理大数据挑战的能力,它已成为Hadoop的强大补充,而后者则是大数据技术的原始选择。
现在,它拥有超过225,000名成员的良好用户基础,并且有200多个公司的对代码付出的贡献,它已成为阿里巴巴、亚马逊、eBay、雅虎、腾讯、百度等一些主流企业的首选框架。
那下面铁锤就和大家一起来聊聊Spark功能组件的主体构成。
Spark和Hadoop之间的主要区别
影响企业的最常见问题是,当Hadoop出现时,对Spark的需求是什么。这可以通过描述批处理和实时处理的概念来解决。前者基于处理已存储了一定时间的数据块的概念,后来又用于实时处理模型。在MapReduce框架Hadoop在2005年是大数据领域的一项突破性技术,但直到2014年Spark引入时才如此。Spark的主要销售主张是实时速度,因为它比Hadoop的MapReduce框架快100倍。因此,可以说Hadoop基于批量处理已存储一段时间的数据的原理。另一方面,Spark有助于实时处理并解决关键用例。此外,即使在批处理方面,也发现它快100倍。
Spark功能
Apache Spark是用于实时数据处理的开放源代码计算集群框架。它拥有一个蓬勃发展的开源社区,并且是Apache Foundation最雄心勃勃的项目。
Spark提供了一个接口,用于对具有内置并行性和容错性的整个集群进行编程。它基本上建立在Hadoop的MapReduce框架上,并将其扩展到更多计算类型。Spark的一些重要功能包括:
速度:如上所述,Spark比Hadoop MapReduce进行的批处理速度快100倍。受控分区已使之成为可能,该分区有助于通过分区模式管理数据,从而有助于以最小的网络流量并行分配数据处理。
机器学习:MLib是Spark的机器学习组件,在数据处理方面非常困难,它无需使用多种工具,即一种用于处理,一种用于机器学习。因此,它为数据工程师和其他数据科学家提供了一个强大而统一的引擎,该引擎既快速又易于使用。
Polyglot:它提供了Java,Scala,R和Python中的高级API的规定,这意味着它可以使用这四种中的任何一种进行编码。另外,它允许在Scala和Python中使用shell,前者可通过./bin/spark-shell从安装目录访问,而后者则可通过./bin/pyspark访问。
实时计算:由于其内存中计算,Spark具有低延迟的实时计算。旨在提供巨大的可扩展性。Spark团队的文档化用户拥有在具有数千个节点的系统上运行的生产集群,它支持许多计算方法。
评估缓慢:可以看出Spark会推迟评估,直到变得极为重要为止。这是影响其速度的主要因素之一。Spark通过将转换添加到DAG或计算的有向压克力图来处理转换,只有在驱动程序请求数据后,DAG才会真正执行。
与Hadoop集成:Spark 与Hadoop具有良好的兼容性,这是对所有在Hadoop中开始职业生涯的大数据工程师的一种礼物。尽管Spark被声明是Hadoop的MapReduce功能的替代品,但它也具有通过使用YARN进行资源调度而在Hadoop群集之上运行的能力。
Spark体系结构:抽象和守护程序
Spark拥有一个标记清晰的分层体系结构,所有组件和层都被广泛地结合在一起并与其他扩展和库集成在一起。该体系结构基于两个主要的抽象:
弹性分布式数据集(RDD):这些是数据项的集合,这些数据项分为多个分区,并且可以存储在Spark群集中的工作节点上的内存中。从数据集的角度来讲,Spark支持两种类型的RDD,即Hadoop数据集(从存储在HDFS上的文件创建)和并行化的集合,而并行化的集合又基于现有的Scala集合。此外,RDDS viz支持两种类型的操作。转变与行动。
有向无环图(DAG):当每个节点都是RDD且边沿对数据进行转换时,则对此类数据执行的计算序列为DAG。DAG完全消除了Hadoop MapReduce多阶段执行模型,与Hadoop相比,它还提供了增强的性能。DAG中的Direct表示以下事实:转换是一种将数据分区状态从A更改为B的操作,而Acyclic意味着转换无法返回到较早的分区。
Spark体系结构具有两个主要的守护程序以及一个集群管理器。它基本上是一个主/从体系结构。这两个守护程序是:
主守护程序:它处理主/驱动程序过程
辅助进程:处理从进程
一个Spark集群只有一个Master和许多Slave Worker。单个Java进程由驱动程序和执行程序运行,而用户可以在不同的机器(如垂直集群或混合机器配置,甚至在同一水平的Spark集群)上运行它们。
Spark体系结构:驱动程序,执行程序和集群管理器的角色
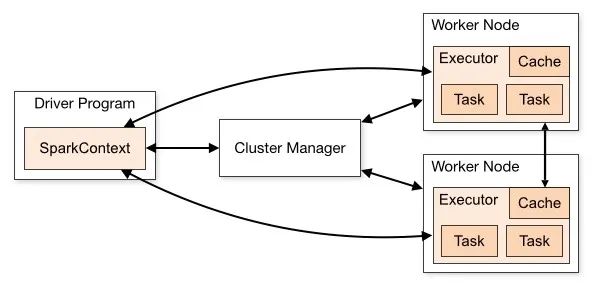
1、驱动程序:是运行应用程序的primary()函数的中心点。它也是Spark Shell(Scala,Python和R)的入口。Spark Context在这里构建。驱动程序的组件包括:
DAGS调度程序 任务计划程序 后端调度程序 块管理器 所有这些负责将spark用户代码转换为在集群上实现的实际spark作业。驱动程序的角色是: 在Spark集群的主节点上运行的驱动程序有助于计划作业的执行,并有助于与集群管理器进行协商。 它有助于将RDD转换为执行图,然后将其分为多个阶段。 有关RDD及其分区的元数据也由驱动程序存储。 驱动程序有助于将用户应用程序转换为较小的任务,这些任务又由执行者执行。后一种是处理单个任务的工作进程。 它还有助于通过端口4040上的Web UI揭示有关运行spark应用程序的信息。
数据处理 它有助于读取和写入外部数据 它有助于将计算结果数据存储在内存,HDD或缓存中。 它有助于与存储系统进行交互
政府:实时分析在政府机构中的最大用途在于国家安全领域,因为几乎所有国家都必须实时跟踪军事和警察的最新动态,以防威胁国家安全。
医疗保健:实时分析对于检查某些危重病人的病史非常有用,这有助于他们追踪血液和器官之间的移植情况。这在极端的医疗紧急情况下非常有用,因为在紧急情况下延迟几秒钟可能会导致生命损失。
银行业务:世界通过银行业务进行货币交易,因此,确保交易不存在欺诈行为至关重要。
股票交易所:股票经纪人使用实时分析来预测股票走势。许多企业通过使用实时分析来检查其品牌的市场需求来更改其业务模型。
往期推荐




