




前几天遇到一个分区交换导致执行计划改变的案例,写出来和大家分享一下,此次为笔者第一次分享,一为回顾case,加深印象;二为抛砖引玉,和大家一起交流,精进。本文中如有分析不当或者欠推敲的地方,可以私聊我,虚心接受,才能不断完善自己,希望大家多多点评呀!
废话不多说,直接上案例:
故障现象
某客户的账单系统每天定时进行跑批任务,跑批过程中会针对该次涉及的表进行统计信息系收集,之前测试阶段收集统计信息大约20分钟结束,而次统计信息收集持续了两个多小时,在收集统计信息期间,监控出现超时告警,并且前台页面无法查询账单,收集完统计信息后前台查询恢复正常。
操作系统:suse 11
数据库版本:11.2.0.4 两节点RAC
补丁版本:psu 190716
从现象来看,貌似是收集统计信息影响了正常的业务查询,但是不要急下结论,我们一步一步来揭开真相。
查看awr
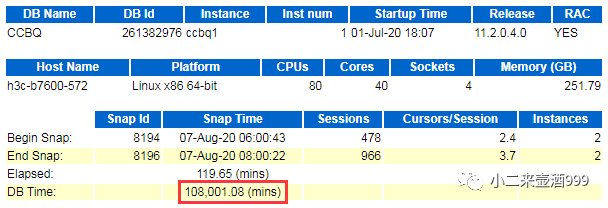
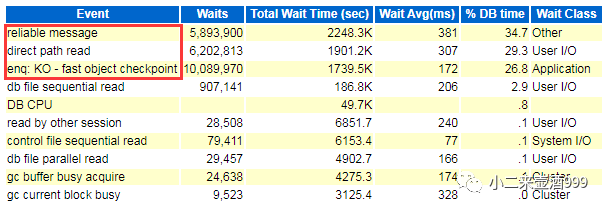
抓一份问题时间段的awr,发现在问题时间段,数据库DBtime严重,主要等待事件为reliable message、direct path read、enq: KO – fast object checkpoint。
reliable message:由文档DocID 69088.1可知,

该等待为进程通信机制的一部分,出现该等待事件,可能意味着某些进程的通道通讯受到阻塞。
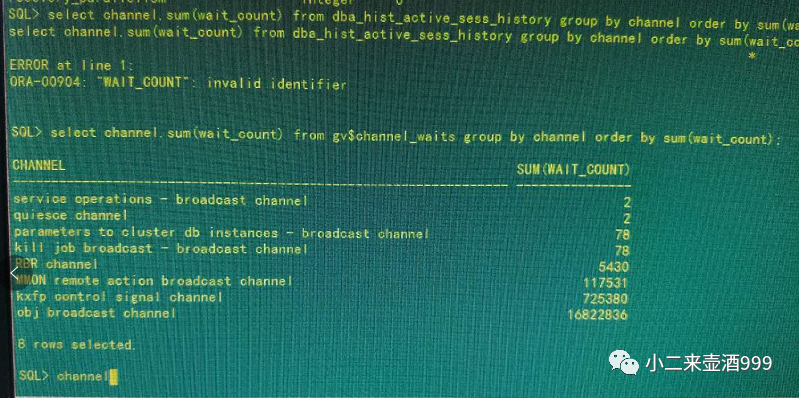
查看v$channel_waits视图,发现obj boardcast channel等待最多,结合awr中avg gloableenquence get time,avg global cache cr block receive time指标,当一个节点要读取另一个节点的内存中的块时,首先需要向redo log里面刷新日志,而这个过程较慢,导致块在实例事件传递受到阻塞,进而反应在等待事件上即为reliable message
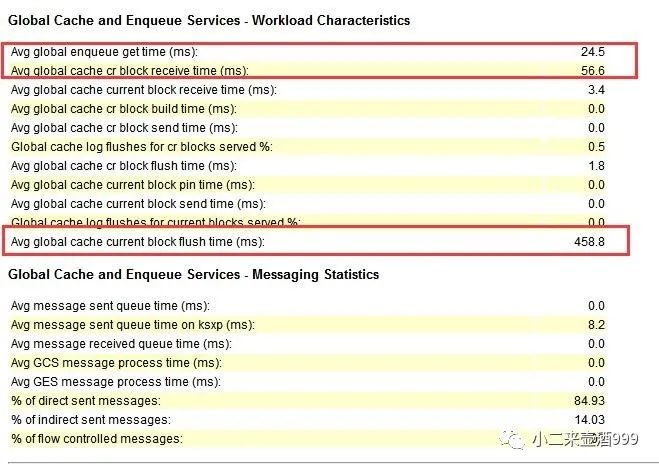
direct path read和enq: KO –fast object checkpoint:直接路径读为oracle将根据自身规则,将满足条件的表直接读入pga,不经过sga,此等待事件会增加IO消耗。而oracle在做直接路径读之前会对将要执行的对象做一次对象级别的checkpoint,因为direct path read读取的数据是直接从物理磁盘中读取的,所以需要保证物理磁盘中数据是最新的,即为enq: KO – fast object checkpoint等待。
综合以上因素,IO上是存在压力的,查看数据库负载,每秒物理读为1355MB,很大,那么看看physical reads吧。
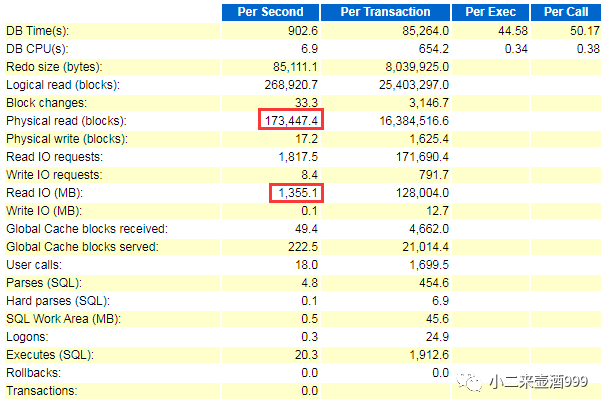
查看sql
sql id为69pnq07z712b3的该条sql所占用的物理读最高,和应用确认,该条sql即为前台登录时查询概要信息的sql,如果未及时反馈结果,则显示无法查询账单,由此可见,该条sql是关键。
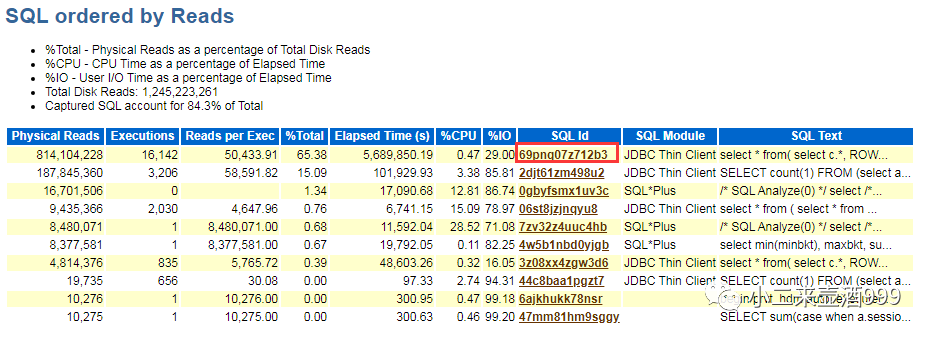
sql文本:
select * from (selectc.*, ROWNUM as rn from (select b.* from (select TO_CHAR(DUE_AMT_RMB, 'FM999999999999999990.00') as dueAmtRmb, CTASKID as ctaskid, TO_CHAR(DUE_AMT_USD, 'FM999999999999999990.00') as dueAmtUsd, DUE_DATE as dueDate, TO_CHAR(DUE_AMT_EUR, 'FM999999999999999990.00') as dueAmtEur from A_CUST_INFORMATION t WHERE t.CUSNUM = :1 and is_check = 'Y' union all selectTO_CHAR(DUE_AMT_RMB, 'FM999999999999999990.00') as dueAmtRmb, CTASKID asctaskid, TO_CHAR(DUE_AMT_USD, 'FM999999999999999990.00') as dueAmtUsd, DUE_DATE as dueDate, TO_CHAR(DUE_AMT_EUR, 'FM999999999999999990.00') as dueAmtEur from HIS.A_CUST_INFORMATION_HIS t WHERE t.CUSNUM = :2 and is_check = 'Y') b ORDER BYCTASKID desc) c) where rn between :3 and :4 |
单语句从结构上可以看出,这条sql分页写法效率不高,但这不是根源,属于存在可优化的地方,我们来看一下这条sql的执行计划。
查看执行计划
问题时间段,共产生四个执行计划,其中一个效率较高,其他的则效率不高。
plan hash value:1977483615
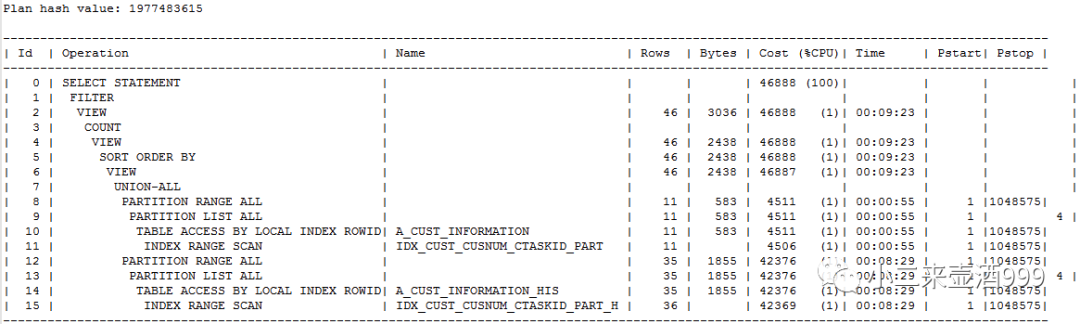

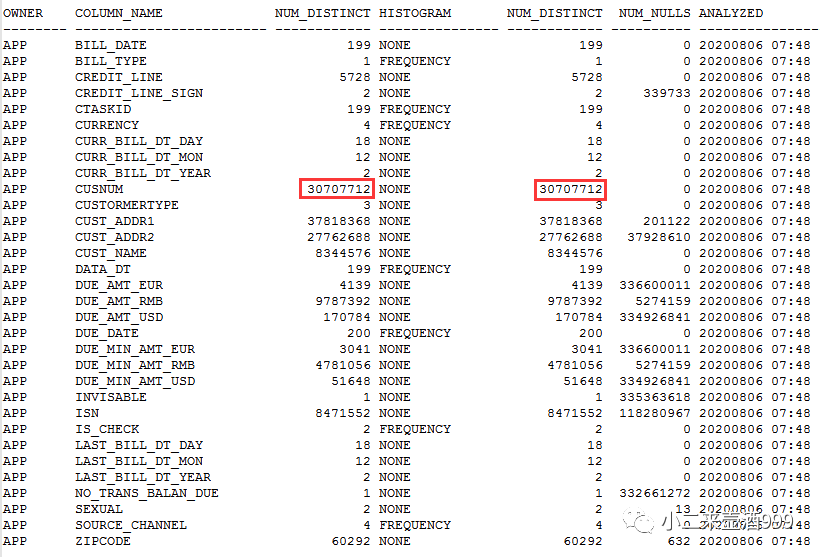
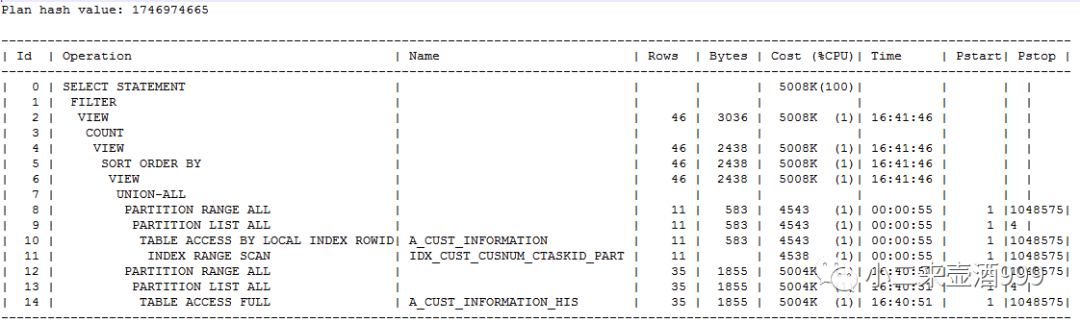
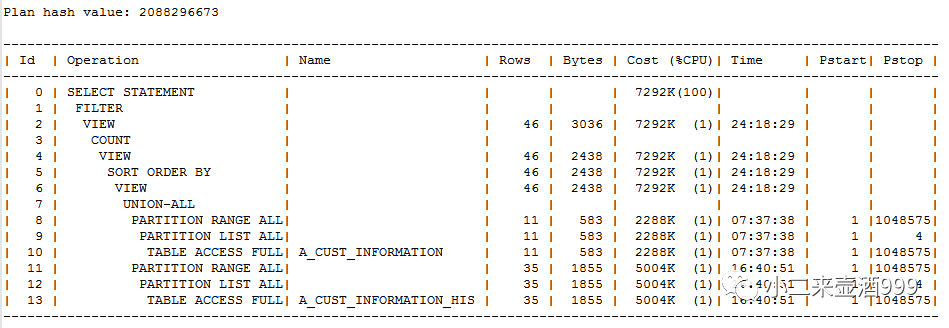
A_CUST_INFORMATION.CUSNUM字段和A_CUST_INFORMATION_HIS.CUSNUM分别存在索引,总行数3亿3千万,distinct值为3千万,选择率较好,执行计划走索引效率较高。
其余两个执行计划分别存在至少一个全表扫描,涉及的两张表,如果走全表扫描显然会拖慢sql执行,且会产生大量的物理读,增加IO压力增加。
plan hash value:1746974665
plan hash value:2088296673
但是为什么在此期间会产生多个执行计划呢?我们来查看一下v$sql_shared_cursor视图,看是否有发现,但很遗憾,该视图下针对这条sql只有一条记录。
我们再来看一下sql的历史执行情况,如下所示:
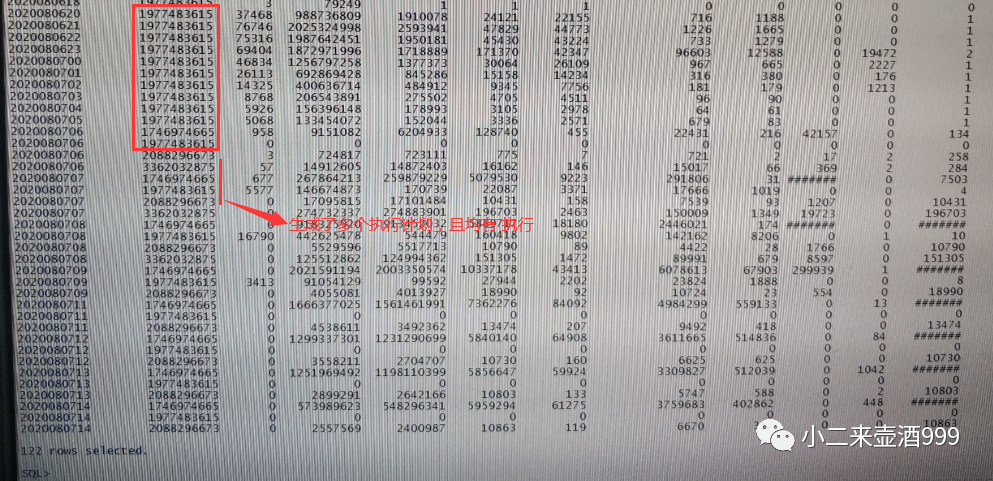
我们可以清楚的看到,在8月7日6点之前,一直稳定在plan_hash_value为1977483615的执行计划,从6点开始,执行计划开始变化,其产生的执行计划由前文信息可知,效率不高,而改变点就在于,由原来的索引范围扫描变成了全表扫描,那我们来想一想,执行计划改变都会有哪些可能的情况:
1.自适应游标共享
2.Cardinality feedback特性
3.统计信息改变
4.。。。
经查看,自适应游标共享和Cardinality feedback特性均未关闭,可能导致执行计划改变,存疑;统计信息改变,能够想到的是,有大幅度的数据改变,和开发聊一聊吧,看看是否有所发现。
经过和开发沟通,定时任务每天5点以后执行,所做的工作就是将加工好的数据,从临时表刷入A_CUST_INFORMATION表和A_CUST_INFORMATION_HIS表,而A_CUST_INFORMATION表和A_CUST_INFORMATION_HIS表每天会创建新的分区,然后采用分区交换的方式,将数据交换至新分区。那么做分区交换的临时表上,有没有索引呢,回答:“没有,在分区交换完会进行统计信息收集,然后判断索引是否失效,如果失效,会重建索引”。
至此,真相浮出水面,由于在执行分区交换的时候,中间表没有索引,分区交换之后会导致该分区索引失效,由此,在收集统计信息期间,执行计划改变为全表扫描(笔者之前不了解分区交换(exchange)相关技术,也是遇到后经过查询资料才了解,并且模拟生产环境做了相应测试,如果中间表中没有索引 ,的确会导致交换后的分区的索引失效,感兴趣的小伙伴可以自己测一下)。
总结
回顾现象,应用在跑批流程里采用分区交换的方式将数据灌入业务表,但由于此过程中的中间表没有索引,导致分区交换新的分区索引失效,致使在执行计划改变,走了效率不高的执行计划,因此,问题时间段前台查询账单业务无法正常使用,监控出现告警;而在此时正在进行收集统计信息的动作,并在收集完后重建失效索引,从表现来看,即为收集完统计信息,账单查询正常。
如何调整
对症下药即可,将中间表建立索引,并在分区交换时增加including indexes子句,同时在调整应用工作流程,在分区交换完之后,立刻判断索引是否失效。经验证,应用做此改动后,该问题不再发生。
最后感谢康哥的支持!
