在MySQL 5.7中,一个实例下,两个不同的schema,执行两条几乎相同的SQL(sql文本一致,表结构一致,表数据量相差不大),但是执行效率却有几乎100倍的差异。A schema 下,SQL的执行时间为0.12S

2个SQL的执行计划都相同: 两个sql在同一个实例下执行,并且在schema B下SQL执行缓慢不是偶发的情况,所以暂时排除受数据库服务器硬件环境影响的可能。问题可能还是在SQL语句本身?
两个sql在同一个实例下执行,并且在schema B下SQL执行缓慢不是偶发的情况,所以暂时排除受数据库服务器硬件环境影响的可能。问题可能还是在SQL语句本身?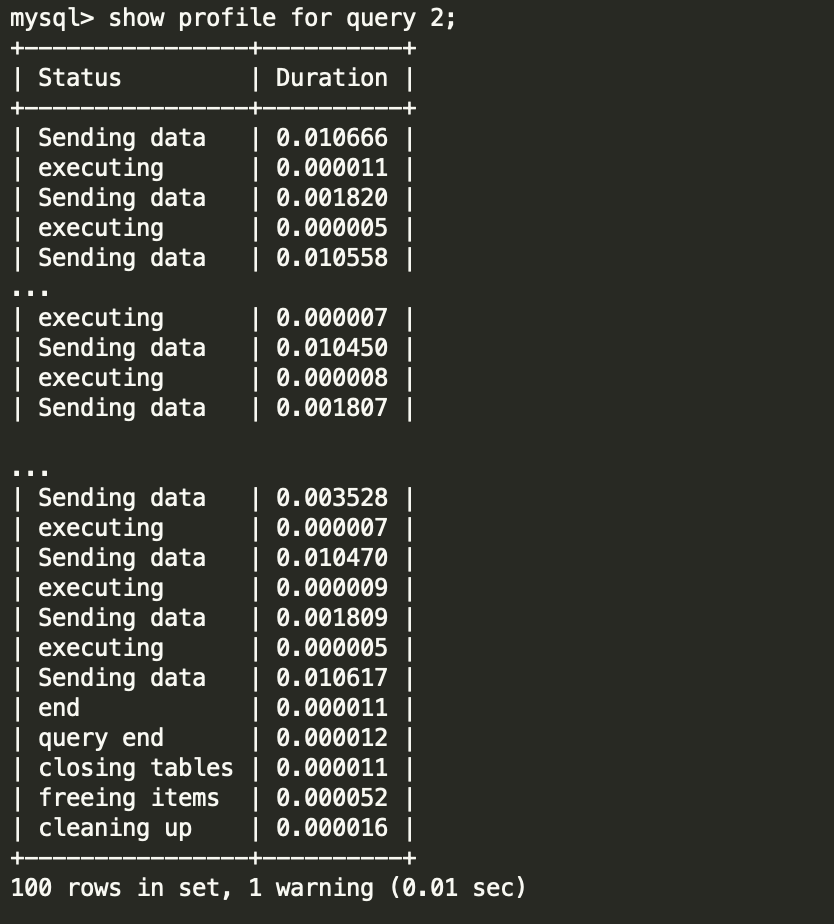
profile中所有时间基本都是0.0X秒,并且把所有时间加起来也就只有0.35秒左右,但是这个sql的执行时间怎么会需要11秒呢?到底是慢在了什么地方呢?三、通过strace跟踪,查看两条SQL的执行差异1. 先通过下面的语句,找到 os thread_id

strace -tt -o slow.txt -p 30002 -f
grep -E '^911' slow.txt > slow_911.txt


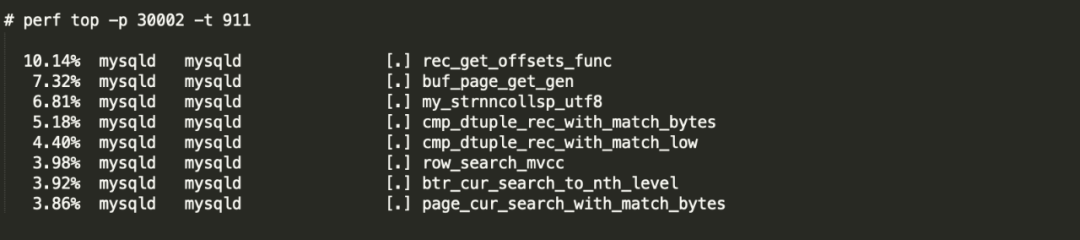
这些函数都是取数据页,并将数据页拆分为数据行的函数,并没有什么特别的函数。结合 strace 和 perf top的分析结果,慢的查询的确在MySQL服务器上花了大量的时间。那么执行计划相同,但是执行时间差异如此之大,一定是数据分布的问题了。SELECT * from B.VIEW H1
where TIME =
(select max(TIME) from B.VIEW where C = H1.C)
AND TYPE = 'TTTTT' AND H1.C <> 'XXXXX'
这个SQL的子查询中 C = H1.C 引用了外层查询的列。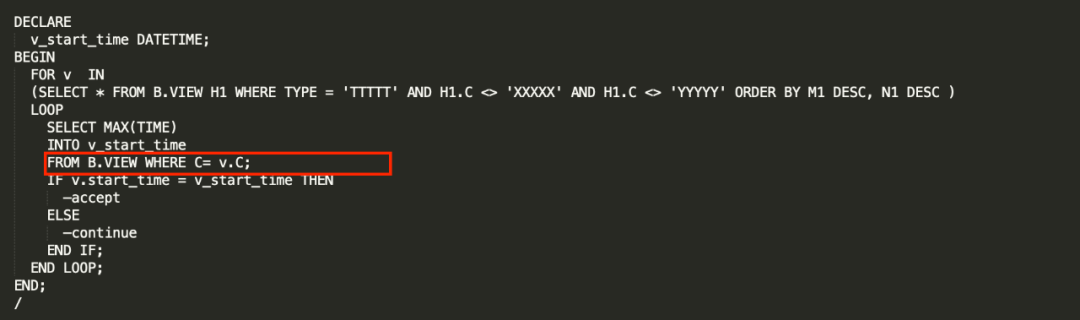
两个Schema下的查询对比,发现外层循环查出的记录数相差很小,那么性能差异肯定是取决于循环内层的子查询每次的执行所花的时间。即:select max(TIME) from B.VIEW where C = H1.C
子查询的执行效率,又取决于每个符合C= H1.C这个条件的数据量。
通过对两个结果集的比较,不难发现,数据量相差不多的情况下,SCHEMA B(慢查询),一个C记录最多对应有864条,最少的也有288条;而SCHEMA A下(快查询),最多的只有60条,基本集中在15条左右。由于VIEW还是一个视图,所以会放大执行时间。SELECT H1.* FROM B.VIEW H1,
(SELECT C,MAX(TIME) x_start_time FROM B.VIEW
WHERE H1.T = 'TTTTT'
AND H1.C <> 'XXXXX'
AND H1.C <> 'YYYYY'
GROUP BY C) b
WHERE H1.C =b.C
AND H1.TIME = b.x_start_time
ORDER BY BY M1 DESC, N1 DESC;
七、为什么慢查询的profile中的所有时间累计起来才0.35秒呢?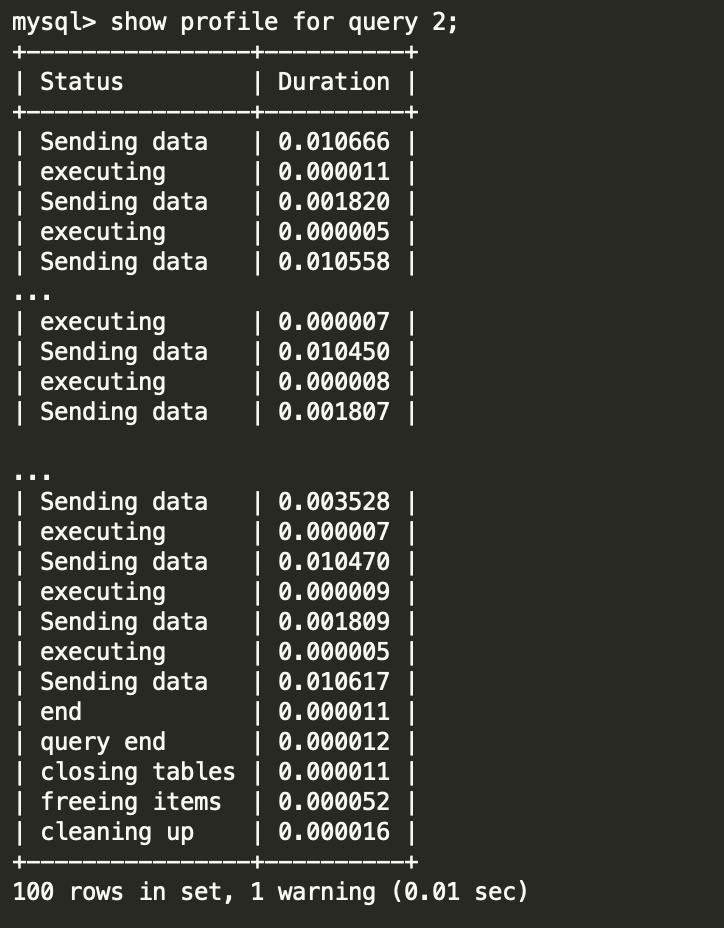

SHOW PROFILES列出了最近发送到服务端的sql语句。列表长度由变量profiling_history_size控制,默认值为15,最大值为100。官网只提了show profiles的限制,没找到show profile 相关内容,不过我测了一下,最多也只能显示100行。所以,0.35秒,只是累加了部分profile信息中的时间,并不是profile不准确。





