




在收集统计数据时,可能会导致一些语句的执行计划发生重大变化。特别是当重新收集统计数据时,某些参数设定不合理,导致统计数据与实际数据有较大出入,会导致语句性能下降。在生产 环境中,这种变化可能会影响整个系统的性能、甚至宕机。在 11g 之前,我们可以通过收集统计数据副本,并在相应的测试环境中测试以后,再将副本数据导入生产环境中来避免此类问题。但是, 由于实际业务数据存在差异以及其他潜在因素,在测试环境中的测试可能并不完全可靠,这样的统 计数据迁移还是会带来一定风险。在 11g 中,Oracle 提供了另外一种方式对新收集到数据在应用到实际环境之前进行性能测试:"待定"统计数据数据。
在收集统计数据时,系统参数 PUBLISH 为 FALSE,则收集到数据就是待定统计数据。我们可以
通过在会话(或者系统)级别指定参数 optimizer_use_pending_statistics 为 TRUE(默认为 FALSE), 仅使某个会话使用新收集到待定统计数据来解析语句。当确保统计数据无误时,可以通过存储过程 将待定统计数据发布到系统中,使之生效。
管理待定统计数据的存储过程有以下几个。
导出表的待定统计数据
存储过程 DBMS_STATS.EXPORT_PENDING_STATS 用于导出表及其分区、索引和字段的待定统计数据到统计表中。
输入参数:
• OWNNAME、TABNAME、STATTAB、STATID、STATOWN:参见之前解释;
删除表的待定统计数据
存储过程 DBMS_STATS.DELETE_PENDING_STATS 用于删除表及其分区、索引和字段的待定统计数据到统计表中。
输入参数:
• OWNNAME、TABNAME:参见之前解释;
发布表的待定统计数据
存储过程 DBMS_STATS.PUBLISH_PENDING_STATS 用于发布表及其分区、索引和字段的待定统计数据到统计表中。
输入参数:
• OWNNAME、TABNAME、NO_INVALIDATE、FORCE:参见之前解释;
示例:

5.3 对象统计数据收集过程分析
本节内容将会分析 Oracle 内部在收集相关统计数据的过程及算法:例如,在自动模式,如何判断;某些特殊统计数据是如何得出的。了解这些过程,有助于我们判断当前对象的统计数据是否正 确,从而帮助我们改善优化环境,使优化器能得到最优的执行计划。
提示:通过设置 DBMS_STATS 中的隐含参数 TRACE 可以将对象分析过程及其用到的 SQL 语句输出到控制台或者文件当中。利用该参数,我们可以跟踪、分析对象统计数据的分析过程,也可以用于统计数据相关问题分析。跟踪级别分为以下多个级别,并且相互可以叠加:
跟踪级别分为以下多个级别,并且相互可以叠加:
• 1 (DSC_DBMS_OUTPUT_TRC):输出跟踪日志到屏幕,而非文件;
• 2 (DSC_SESSION_TRC):仅跟踪当前会话;
• 4 (DSC_TAB_TRC):跟踪收集表的统计数据相关日志;
• 8 (DSC_IND_TRC):跟踪收集索引的统计数据相关日志;
• 16 (DSC_COL_TRC:跟踪收集字段的统计数据相关日志;
• 32 (DSC_AUTOST_TRC):将会话跟踪日志保存到系统表 sys.stats_target$_logz 中;
• 64 (DSC_SCALING_TRC):跟踪统计数据取样调整过程日志;
• 128 (DSC_ERROR_TRC):跟踪错误和异常信息;
• 256 (DSC_DUBIOUS_TRC):跟踪可疑的统计数据;
• 512 (DSC_AUTOJOB_TRC):跟踪自动收集作业的相关事件和错误;
• 1024 (DSC_PX_TRC):跟踪并行查询相关日志;
• 2048 (DSC_Q_TRC):导出收集统计数据过程中执行的相关查询语句;
• 4096 (DSC_CCT_TRC):跟踪收集物化视图统计数据的相关日志;
• 8192 (DSC_DIFFST_TRC):跟踪统计数据收集前后的变化;
• 16384 (DSC_USTATS_TRC):11g 中新的跟踪级别,跟踪用户设置统计数据相关过程;
5.3.1 表统计数据收集与计算
表作为数据库中最基本的存储对象,其相关统计数据在 SQL 查询中起着至关重要的作用。在执行计划树中,表对象往往是底层操作的对象,上层操作的代价估算依赖于底层代价的估算,因而, 底层对象的相关统计数据的正确性与精确度就直接影响到了整个执行计划代价估算的可靠性。我们 以下分析一些直接影响表统计数据的正确性与精确度的相关收集过程。
陈旧统计数据判断
对于一些大的 OLTP 系统,往往有着表的数量多、表的数据变化快已经核心业务表、日志表数据量大的特点。因此,定期更新表的统计数据以保持与业务数据变化相一致,是这类数据库系统必须的维护过程。然而,由于系统中表的数量多且许多表的数据量大,如果定期完全更新所有表的相关统计数据,则会成为系统的巨大负担。Oracle 提供给 DBA 的一个选择就是:让系统自动找到没有统计数据或者统计数据相对陈旧的表进行更新。
要找出没有统计数据的表不难。但是,如何找出统计数据陈旧的表就涉及到一些系统的相关参 数。
首先,我们看 Oracle 是如何判断表上面的统计数据是否陈旧的。这里,有一个重要参数,即陈旧百分比:STALE_PERCENT。这是一个百分比值,即当 Oracle 发现字上一次更新表的统计数据以来, 发生变化的数据记录占总的数据记录的百分比超过该参数设置时,就认为该表的统计数据陈旧。判 断式如下:
(插入数据数 + 更新数据数 + 删除数据数) / 总的数据数 > STALE_PERCENT
这个百分比值默认是 10%。在 11g 之前,它是一个内部数值,不可修改。11g 之后,它作为一个选项(Preference),可以在系统级别修改,也可以在表级别修改。
然而,在默认情况下,表的数据变化是不会被监控的。要监控一张表的数据变化,需要满足以
下条件:
1、 系统参数 STATISTICS_LEVEL(SYSTEM 或者 SESSION 级别)为 TYPICAL(系统默认值)或者 ALL;
2、 表的监控(MONITORING)选项被开启;
要开启表的监控选项,可以在创建表(CREATE TABLE)时,指定 MONITORING 选项;也可以通过 ALTER TABLE 语句修改该选项。
示例:

启用了表监控后,系统就会监控和统计表的数据变化,并将相关数据存储在系统数据字典中。 我们可以通过视图 DBA/ALL/USER_TAB_MODIFICATIONS 查询到被监控对象的相关数据变化信息。
自动取样
为了减少分析对象导致的资源消耗,尤其是对一些大数据量的表的分析所导致的负荷,我们可以通过采样(Sampling)来分析表,而不是对整张表的所有数据进行扫描。但是,采样分析对象势必会降低统计数据的精确度。因此,一个合理的采样百分比既要保证统计数据的可靠性,又要尽量 降低分析过程导致系统负载。采样比例设置有两种:
1、 如果你已经十分清楚什么样的采样比例对于表是合理的,可以手工设置采样比例,数 值从 0.000001 到 100;
2、 设置采样比为 0 或者 DBMS_STATS.AUTO_SAMPLE_SIZE 则由 Oracle 自己来判断采样比例,这也是系统的默认选项。
下面我们将分析 Oracle 是如何自动判断采样比例的。快速取样
在获取最终取样比例之前,Oracle 会由数据块采样获取一个快速取样比。
Oracle 获取快速取样比的过程实际上是一个循环过程:当前比例获取数据 => 数据是否符合最低进度要求 => 不符合,则调整比例,继续下一轮循环;符合要求则结束循环。其中,第一次循环的比例是初始样本比例,它是由表的数据块数量估算得出的。因此,在进行样本比例循环判断之前,
Oracle 会先获取到表的数据占用的数据块数量。
提示:Oracle 有一些内部函数可以直接读取表所对应的数据段(Segment)获取其占用数据块的信息。同时也提供了包 DBMS_SPACE 调用这些函数,使用户通过包的过程、函数获取相关信息。
获取到表的数据块数(NBLKS)后,其初始比例为 100 块数据块所占比例:SPCT = 100 *
(100/NBLKS)。
提示:表的数据块数是指表的存储段(Segment)中高水位线(High Water Mark)以下的数据块数量。在 Oracle 中,逻辑存储对象(表、分区、索引)等,在物理位置上的存储都是以段
(Segment)为单位。当对象空间不足,需要扩展存储空间时,则以扩展段(Extent)为单位扩展空 间,一个扩展段则包含了多个数据块。而这些数据块在被写入数据之前需要先被格式化写如管理信息。这些扩展段和数据块都是由数据字典或者段头(Segment Header)中位图来管理的,高水位线就是这些被管理的存储空间中,最后一块被格式化的数据块位置。
提示:在每一轮调整采样比的过程中,如果采样比大于 25,则不再采样,即进行完全扫描。
获取到采样比后,则由该采样比(注意,此时是数据块采样,而非数据记录数采样,以提高效 率)读取表的采样数据记录数。获取到的采样数据记录数(N)就成为判断当前采样比是否可靠的标准。
采样比判断
Oracle 对于采样比的判断标准很简单,即如果采样数据记录数大于等于 5000,就不再调整采样比。
采样比调整
如果当前采样数据记录数小于 5000,则调整采样比,进行下一轮分析。而如何调整采样比,也是依赖于当前的采样数据记录数:
• 如果当前的采样数据记录数小于最小采样数据记录数设置(441),则将当前采样比放大
100 倍;
• 如果当前的采样数据记录数大于最小采样数据记录数设置,则将当前采样比放大 10 倍, 或者放大(7500/N)倍,两者当中取最大值;
调整采样比后,再进行下一轮判断。最终,快速获取到采样数据记录数就成为了自动采样比的 基数。
自动采样比 = 100 * ( 5500 / NROWS )
获取到自动采样比后,Oracle 按照该采样比,将样本数据存储到一张临时表中,再由临时表分析字段的统计数据。
示例:

5.1.1 字段统计数据收集与计算
我们在查询表中数据时,大多数情况下,都需要根据一个或多个字段对数据进行过滤或者由某 些字段关联多个表。此时,对相关操作的代价估算就必须使用到这些字段上的统计数据。
唯一值数估计
由快速取样得到的样本数据,用于字段的统计数据分析。而字段的统计数据可以分为两类:基本统计数据(如唯一值数 NDV、字段平均长度 ACL、最大、最小值等)和柱状图数据。对于第一类数据,实际上可以通过一次扫描表获取所有字段的统计数据。但是,由于采样具有随机性,对于一 些数据分布不均匀的字段,通过采样数据获取统计数据可能会导致获取到的数据与实际数据产生较 大差异。尤其对于一些海量数据表,通常采样比较低,因而每次分析对象获取到的数据的精度会存 在较大的不确定性。这种不确定性可能会对系统的整体性能造成重大影响。例如,对于以下一组数 据,
[0,1,1,1…(1001)…1,2,3,4,5,6,7,8,9]
其实际的 NDV 是 10,通过采样(假设采样比为 10%)获取 NDV 时,由于采样的随机性,可能就会出现以下情况:
[1…(101)…,2,6]
得到的 NDV 是 3,和实际值值存在很大的出入(如果除以采样比的话,NDV 为 3/10×100=30)。而如果优化器采样了这样数据进行执行计划代价估算的话,就很有可能获取不到最优的执行计划。
而降低这种不确定性的手段就是提高采样比例。但是,对于大型表来说,提高采样比又会带来更多的资源消耗,尤其是获取 NDV 数值时。由于获取 NDV 数值需要消除重复值(通过count(distinct col)方式获取),oracle 是通过排序的方法将已经读取的唯一值保持在 PGA 当中,以便消除后续的重复值。因此,当取样比增加时,PGA 的消耗也会线性增加。对于大型表,PGA 可能不足以容纳全部数据,从而会导致临时磁盘空间的读写,导致重大的性能问题。
在 11g 中,采用了一种新的算法,消除 NDV 计算时的数据量与 PGA 消耗之间的线性关系,从而使得通过完全扫描表获得精确统计数据成为可能。因此,在 11g,自动采样模式下不再进行快速
取样,而是直接进行全表扫描获取统计数据。这一新算法称为唯一值数估计(Approximate NDV)。默认情况下,在进行自动采样(AUTO_SAMPLE_SIZE)时,就采样该算法。也可以通过隐含参数
"APPROXIMATE_NDV"关闭该特性。
提示:11g 中,对分区表全局统计数据的增量(INCREMENTAL)计算方式,也是利用了该算法。
唯一值数估计算法分析
该算法充分利用了哈希算法的分布均衡特性。其基本算法过程如下:
• 它将每个扫描到的数值通过哈希算法转换为一个二进制数值,并放入一个数据结构中, 我们称该数据结构为一个纲要(synopsis);
• 扫描下一个数值,获取到其哈希二进制数值,将其与纲要中已有哈希值比较,如果已 经存在相同值,则丢弃该值,否则就插入纲要中;
• 纲要是有大小限制的,当新插入哈希值时,纲要已经达到大小限制,则按照一定规则 分裂改纲要、并丢弃其中一份数据(例如,将首位为 0 的数值丢弃掉),此时,纲要级别也相应增加(起始为 0,分裂一次加 1);
• 获取到新的哈希数值时,如果其符合被丢弃数据的规则,则不再插入纲要中;
• 再次分裂时,按照递进的规则(如将前 2 为都为 0 的数值分裂)丢弃数据,并以此类推,直到扫描完所有数据;
我们称纲要中最终剩下数值数成为集数(S),纲要分裂次数称为级数(I),NDV 的估算公式
为
NDV = S*2^I
在这种算法下,由于每个字段在 PGA 中仅保存一个纲要数据结构,因此,它不会随着读取的数据量的增加而导致 PGA 消耗的增加。
举例说明该算法。假设二进制位数为 4,纲要大小限制为 6:
第 1 次扫描数据 19 (哈希值为 0101) 插入纲要. ( 0101 )
第 2 次扫描数据 60 (哈希值为 1110) 插入纲要. ( 0101 1110 )
第 3 次扫描数据 36 (哈希值为 0010) 插入纲要. ( 0101 1110 0010 )
第 4 次扫描数据 90 (哈希值为 0101) 存在重复值,丢弃. ( 0101 1110 0010 )
第 5 次扫描数据 92 (哈希值为 1110) 存在重复值,丢弃. ( 0101 1110 0010 )
第 6 次扫描数据 8 (哈希值为 0100) 插入纲要. ( 0101 1110 0010 0100 )
第 7 次扫描数据 10 (哈希值为 1101) 插入纲要. ( 0101 1110 0010 0100 1101 )
第 8 次扫描数据 59 (哈希值为 0001) 插入纲要. ( 0101 1110 0010 0100 1101 0001 )
第 9 次扫描数据 86 (哈希值为 0011) 分裂纲要 (当前级别:0),丢弃其中第一位为 1 的数据
(1110, 1101),插入新数据. ( 0101 0010 0100 0001 0011 )
第 10 次扫描数据 7 (哈希值为 1111) 符合丢弃规则,数据被丢弃. ( 0101 0010 0100 0001 0011 )
最终,纲要中的元素数为 5,纲要级别为 1,估算出的 NDV = 5 * 2^1 = 10。
从上述算法描述中我们不难看出,估算 NDV 的精确度与二进制位数(位数越低,不同数据得到重复哈希值的几率越高,精度越低),以及纲要大小限制(纲要大小越小,被丢弃的数据越多,精度越低)有关。Oracle 目前采用了 64 为二进制和 16384 的纲要容量。
字段采样
实际上,对表的分析过程,也是对其字段的分析过程。因此,选择一个合理的采样大小以确保表统计数据的精度,也同时要确保字段统计数据的精度。而在分析多个字段的统计数据时,例如获 取柱状图数据,可能会导致要多次查询表。所以,无论是用户人工指定了表的采样值,还是自动采 样,Oracle 都会再计算一个采样比,对样品数据(Oracle 会创建一个临时表,将样品数据存入临时表)再次采样以减少资源消耗。
当然,初次计算出的采样比可能无法满足某些数据的精度要求。此时,Oracle 会调整采样比, 经过多轮采样以获取满足要求的统计数据。
在上一节我们提到,字段的初始采样比为 (5500/表采样记录数 * 100)。然后依据这一比例创建
一个临时表,并载入样本数据,对字段的统计数据进行分析。并且,在分析每一个数据时,会判断 该数据是否符合精度要求。在分析完所有数据后,如果还存在不满足精度要求的统计数据,则调整 采样比例,进行下一轮分析。在下一轮分析中,仅分析哪些不满足精度要求的数据。
例如,我们通过跟踪分析过程,可以看到以下信息:
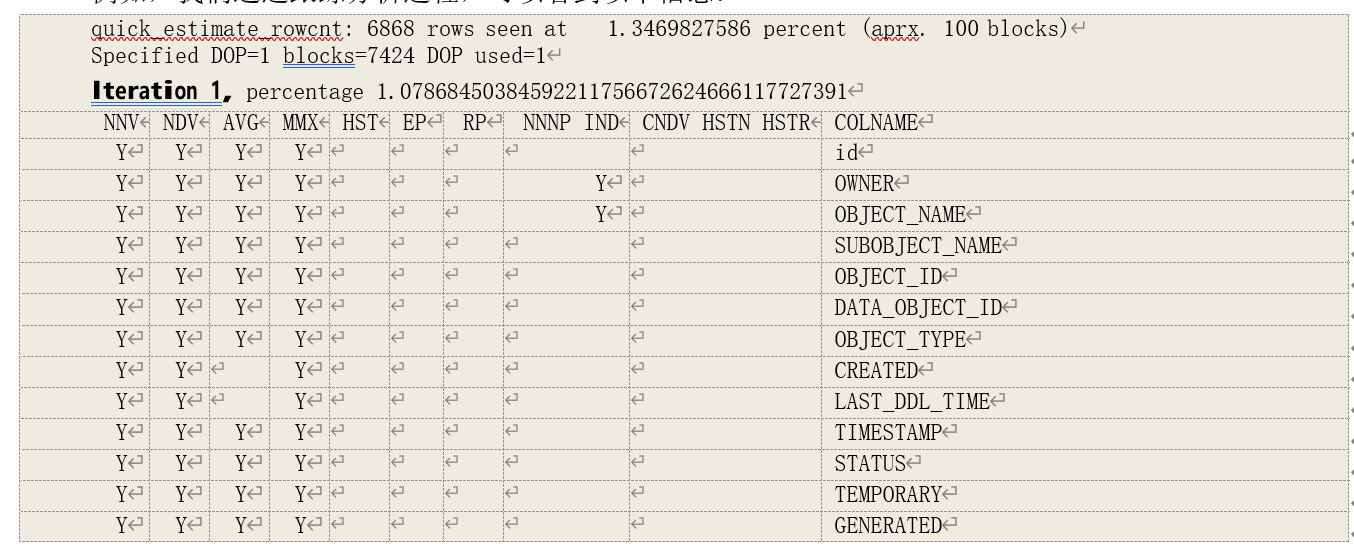
 +
+
这是初始采样比以及第一轮需要分析的统计数据。在该例中,由快速取样得到 6868 条记录, 快速采样比为 1.3469827586。因此,实际数据量为 6868/1.3469827586100 = 509880,进而得到字读初始采样比为 5500/(6868/1.3469827586100)*100 = 1.0786845038。
在随后的跟踪信息中,可以看到以下内容:

在上述信息中,我们可以看到在计算 SUBOBJECT_NAME 和 OBJECT_ID 时,提示一下消息:
Need larger sample:
这说明当前样本大小不足以获取满足精度要求的 NDV。至于如何判断精度要求,我们会在下一节内容中解释。
提示:在 11g 中,如果采样了新算法估算字段统计数据,则除了柱状图数据外,所有字段统计数据都在分析表的统计数据阶段获取。
由于有数据需要被重新分析,调整采样比后,进行了下一轮分析。
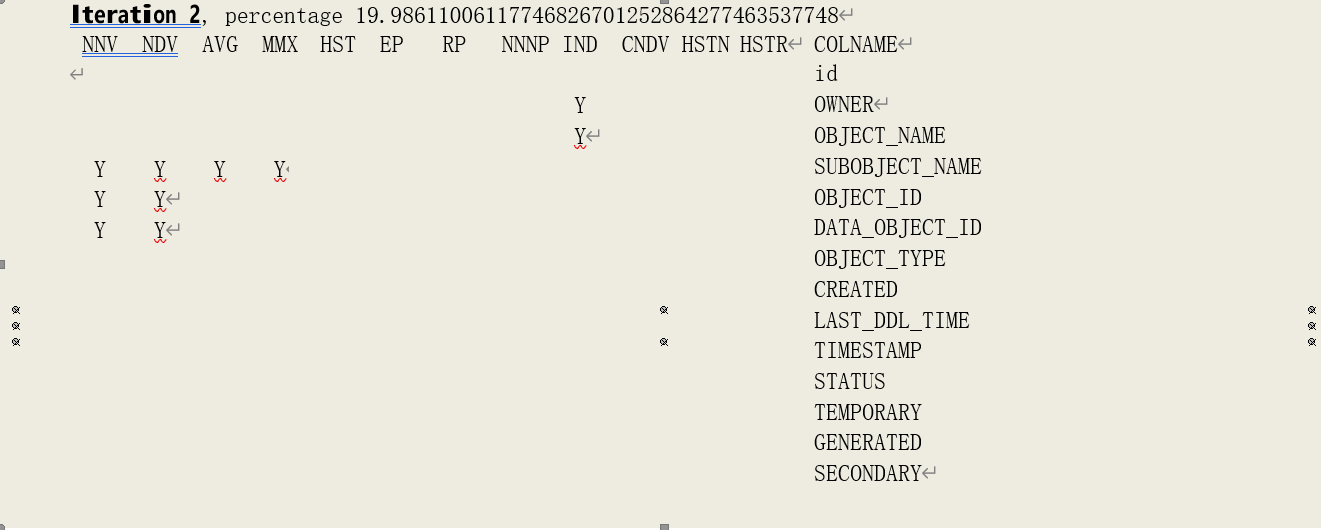
在这一轮分析中,采样比被调整为 19.986110061177。
字段采样比的调整
字段采样比的调整依赖于字段统计数据是否满足精度要求,并且在不同数据分析时会有不同的 调整公式,并最终取其中最大的一个:
• 基本调整:当前取样比的 10 倍
NEW_PCT := CURR_PCT * 10;
• 分析某个字段柱状图数据失败时的调整:
NEW_PCT := CURR_PCT * MIN_SSIZE * 1.25 / GREATEST(SNNV, 1);
• 样本数据量小于最小样本数据量设置时:
NEW_PCT := MIN_SSIZE * 2 * CURR_PCT / GREATEST(SSIZE, 1);
• 分析某个字段基本统计数据失败且为自动取样时的调整:
NEW_PCT := CURR_PCT * DSC_MIN_MINMAX_SSIZE * 1.25 / GREATEST(SNNV, 1);
• 取上面调整比例中最大的一个,其中,对于第二、四两个规则,如果多个字段导致了比例 调整,也是去其中最大的一个;
• 自动取样时,为了防止取样比跳跃过大,当前一轮取样比小于 5、调整后的采样比大于 25
且小于 50 时,调整采样比采样 25;
其中变量的含义为:
• NEW_PCT:调整后的取样比;
• CURR_PCT:当前取样比;
• MIN_SSIZE:最小样本数据量设置,默认为 441,也可以通过事件(event)38040 设置;
• SSIZE:当前采样数据记录数;
• SNNV:当前分析得到的采样数据中该字段的非空数值数(Sampling Number of Not-null Value);
• DSC_MIN_MINMAX_SSIZE:分析最大、最小值时要求的最小样本记录数,这是 Oracle
的经验数据,为 919。
在上例中,得到的最大调整取样比是分析字段 SUBOBJECT_NAME 的基本统计数据失败时得到的调整取样比,其当时的 SNNV 为 62,调整后取样比为:
NEW_PCT = 1.07868450389191.25/62 = 19.98611006
从上述分析中,我们可以知道,分析表的统计数据和分析字段的统计数据时采样取样比并不一定相同,且各个字段都可能会有自己的采样比。同样,在我们后面将介绍的索引统计数据分析也可 能会有不同的采样比。因此,在统计数据视图*_TAB/IND/TAB_COL_STATISTICS 中,都有一个字段
SAMPLE_SIZE,表示分析某个对象统计数据时采样的最终(非空)样本数据量。
需要分析的字段统计数据
从之前示例的分析过程跟踪信息中,可以看到当前分析过程中会分析字段的那些统计数据、及 其影响是否收集统计数据的相关标识:

其中,各个统计数据缩写标识符的含义为:
• NNV:非空数值数(Number of Not-null Value);
• NDV:唯一值数(Number of Distinct Value);
• AVG:字段平均大小(Average Column Length,某些地方会表示为 ACL);
• MMX:最大、最小值(Minimum and Maximum value);
• HST:柱状图数据(Histogram);
• 影响柱状图数据收集的判断标识符的含义为(提示:这些标识位只针对符合
METHOD_OPT 中设置的字段设置):
• EP:等于匹配谓词(Equal Prediction),包括表达式等式匹配和关联等式匹配;
• RP:范围匹配谓词(Range Prediction),包括表达式范围匹配和 LIKE 匹配;
• NNNP:是否为高频率匹配字段,即最近 3 分钟内是否执行了以该字段作为查询或管理谓词的语句;
• IND:是否为索引首字段;
• CNDV:收集柱状图数据时,是否考虑 NDV 因素(Combo NDV);
• HSTN:是否仅分析柱状图数据而不存储到数据字典中(Histogram Not Store);
• HSTR:柱状图是否采用固定 Bucket 数,而非自动配置;
在 11g 中,如果采用了新算法进行基本统计数据估计,上述标识也会影响全表扫描时,相关数据的获取。
提示:在采用老算法统计字段数值大小时,Oracle 利用了一个未公开函数 sys_op_opnsize。
标识初始化
在进行第一轮分析之前,会初始化标识位,同时也决定了那些数据会被统计:
• 对于允许为空(不存在非空约束)的字段,需要获取 NNV;
• 对于非定长数据类型(如 date、float 类型都为定长数据类型,它们占用的空间大小是固定的)的字段,需要获取 AVG;
• 对于非 LOB 类型(CLOB、BLOB、CFILE、BFILE)的字段,需要获取最大、最小值和
NDV;
其它一些统计数据,如字段密度(Density),则是由这些数据计算得出。
