




-评估出业务应用的访问量上涨幅度
-根据应用的访问量上涨幅度,评估数据库性能压力上涨幅度
-根据数据库性能压力上涨幅度,评估需要扩展多少资源
-最后计算需要新采购多少服务器
-如何评估在业务高峰期,业务量会上涨多少?
-业务开发无法评估每个应用的访问量上涨幅度。
-大数据组也没有相关的历史数据。
-哪些数据库性能压力会上涨呢?
-数据库性能压力会上涨多少呢?
-数据库性能压力上涨,会消耗多大的硬件资源呢?
-计算出每个实例的最大资源使用
-最大资源使用乘以2,减去分配给该实例的资源,得到需要扩展多少资源
-sqlserver都部署在物理机上
-mysql,tidb,mongodb和redis,都部署在docker中
-qps/tps相对较大
-CPU,磁盘IO和网络IO相对较大
-其他的性能指标也相对较大。
-这些XXX的数据,具体都是多少呢?
-仅仅这些指标就够了吗?
-指标之间都是and算法吗?
-比如你把CPU,内存,IO,网络,这4维的指标数据送给PCA降到2维,PCA会吐给你2个维度的数据,但你并不知道这2维的数据代表啥含义。。。
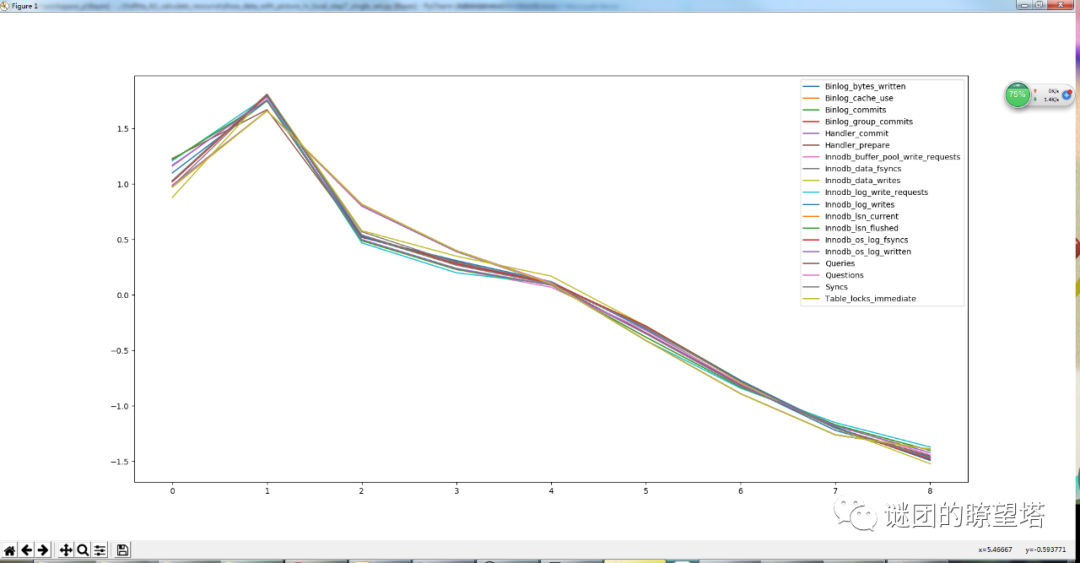
-首先获得所有实例多个时间段采样的性能指标数据。
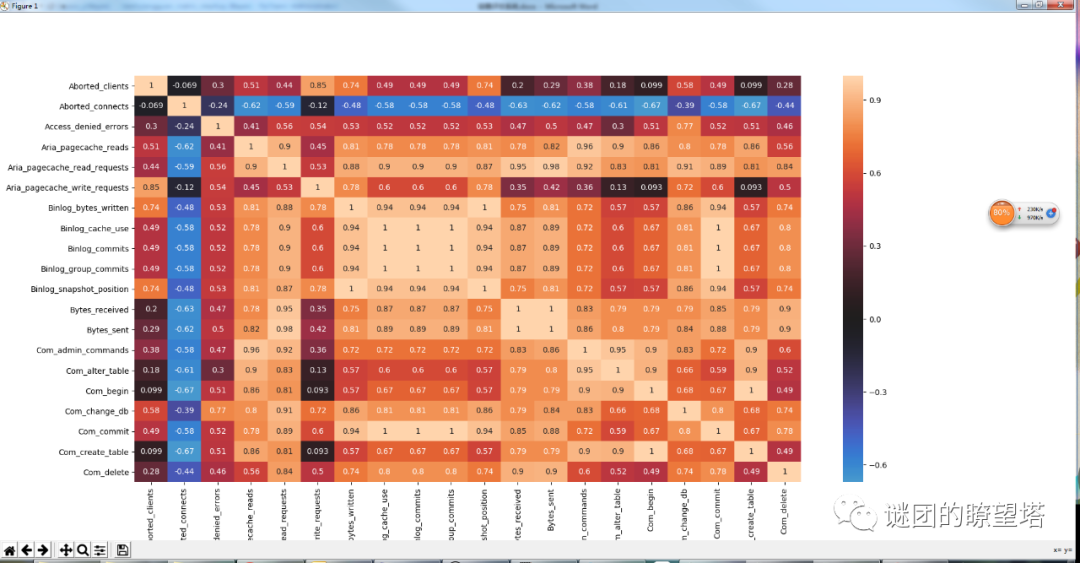
-然后计算相关系数矩阵。
-将相关系数数值很高的划成一类:
-归类好了之后,再进行类别频繁度计算,计算支持度和置信度。
-对于频繁的分类,在其中选择一个代表性的指标。
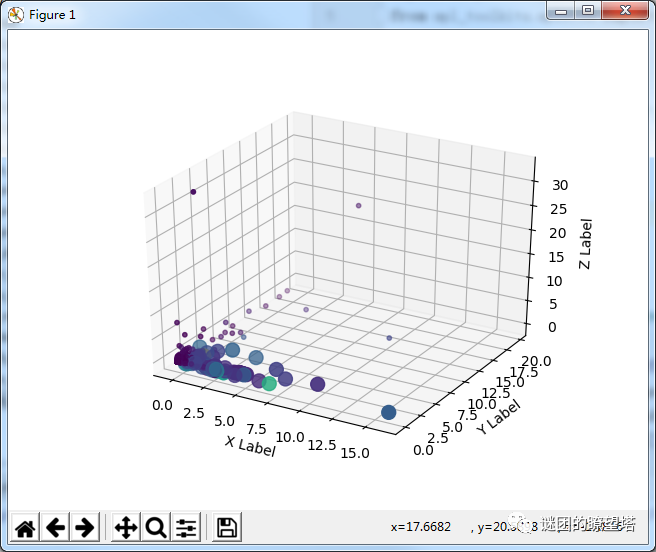
-针对某个实例,长时间采样,进行大量时间段的计算,这样就能获得该实例的特征。
-针对某个特殊事件的时间段(比如性能高峰时间段,备份时间段)进行采样,对所有实例进行计算,这样就能得到该特殊事件的特征。
-实时获得所有实例的性能指标数据
-使用分类,自动识别出符合特征的数据库实例
-将历史数据按时间排序成一维时间序列
-将时间序列分解成周期数据,趋势数据和白噪声数据
-对趋势数据进行指数平滑或者ARIMA预测
-将预测出来的数据加上周期数据,形成预测数据
-对历史指标数据进行时间序列分析,得到预测数据
-对预测数据进行分类,得到未来可能产生性能(特征)问题的实例
