




柱状图数据对于优化器估算谓词对数据集的选择率有着至关重要的影响。这一节中,我们将详 细讨论这一统计数据,包括其数值如何存储、柱状图如何分类等。
是否收集柱状图数据
对于符合 METHOD_OPT 设置的字段,还要根据字段的其他属性进行进一步判决,以决定是否分析其柱状图数据。
柱状图分组数(或者称桶数,Bucket Size)
如果在 METHOD_OPT 设置指定了 FOR ALL [INDEXED/HINDEN] COLUMNS 的话,所有字段采用统
一的分组数设置;如果指定 FOR COLUMNS COL1 SIZE [COL2 …],则每个字段可以有自己的分组设置。对于不同的设置,根据设置要求为字段标记两个重要标志(等于匹配谓词和范围匹配谓词),而这 两个标识是用于判断是否收集柱状图数据的重要依据。
这两个标识位除了用于判断是否收集柱状图数据外,还在柱状图数据的收集过程中起到重要作 用,例如,判断柱状图的类型。
分组数可以指定以下几种设置,在不同设置下,谓词标识位的设置规则如下:
• AUTO:Oracle 将根据数值的分布性和字段的使用负荷决定是否收集 Histogram 数据。最近 3 分钟之内非唯一字段被用于等于匹配操作或等于关联操作,则设置“等于匹配
谓词”的标志;
最近 3 分钟之内字段被用于范围匹配操作或 LIKE 操作,则设置“范围匹配谓词”的标志。
注意,指定字段为 AUTO SIZE 时,最大分组数为通过采样数据得到的 Distinct 数,但不能大于 254;
• SKEWONLY:Oracle 将根据数值的分布性和决定是否收集 Histogram 数据。
所有非唯一字段均设置“等于匹配谓词”的标志; 所有字段均设置“范围匹配谓词”的标志;
注意,指定字段为 SKEWONLY 时,最大 Bucket 数为通过采样数据得到的 Distinct 数, 但不能大于 254;
• REPEAT:Oracle 仅收集那些已有数据字段的 Histogram 数据。
所有原有数据的字段均设置“等于匹配谓词”和“范围匹配谓词”的标志;
注意,最大 Bucket 数为原有 Bucket 数
• 数字:用户指定了 Bucket 数
所有字段均设置“等于匹配谓词”和“范围匹配谓词”的标志;
注意,最大 Bucket 数为指定数字
• 未指定任何 SIZE 参数,即 DEFAULT:Oracle 采用设置的默认 Bucket 数(75) 所有字段均设置“等于匹配谓词”和“范围匹配谓词”的标志;
注意,最大 Bucket 数为默认值 75
只有当一个字段被同时设置了“等于匹配谓词”和“范围匹配谓词”的标志,才会被设置“分 析柱状图”的标志。
关于匹配谓词判断:在默认设置下(隐含参数_column_tracking_level 为 1),SMON 进程每次苏醒时,会由当前打开的游标获取字段匹配信息,并更新到数据字典 SYS.COL_USAGE$中。每种判断谓
(如等于匹配、范围匹配、LIKE 匹配、关联匹配等)词有一个字段存储。这是影响字段统计数据收集的重要依据。

是否保存柱状图数据
对于设置了“分析柱状图”的标志的字段,会在分析过程中创建它的柱状图数据。但是,创建 了的柱状图数据是否被保存到数据字典则由以下因素决定:
• 由分组设置规则设置的匹配谓词标识;
• 柱状图类型;
其中,匹配谓词标识设置规则在上一节中做了描述。
我们前面章节提到,在 Oracle 中,柱状图数据分为两种:频率柱状图(Frequency Histogram) 和高平衡柱状图(Height Balanced Histogram)(Oracle 采用哪种方式创建柱状图数据这一问题将在下一节分析)。综合这两个因素,是否保存柱状图的规则如下:
• 字段存在“范围匹配谓词”标志,则通过内部算法判断其数据分布性是否倾斜
(Skew),如果属于分布倾斜数据,则保存柱状图数据。
• 字段存在“等于匹配谓词”标志,则根据柱状图类型决定是否存储:
对于频率柱状图,如果分组数小于采样的数据记录数时,则保存柱状图数据; 对于高平衡柱状图,如果存在“流行”(Popular)数据时,则保存柱状图数据;
所谓“流行”数据,是针对高平衡柱状图而言。我们知道,高平衡柱状图的特点是,每个分组的容量均等,字段数据的唯一值数相对较大,并且每一个唯一值的重复值很少。因此,在这种柱状 图中,通常一个分组会包含多个唯一值。但是,如果其中某个或者多个唯一值的重复值数较多,以 至于它们会占用到一整个或者一个以上的分组,这样的数据就被称为“流行”数据。
倾斜判断
倾斜判断的基本思路如下:
• 依据当前的分组数、最大值、最小值对数据等分分组;
• 分别取柱状图中落入等分范围中第一个分组与前一个被计算的分组之间的记录数做平 方和;
• 将上述平方和的数值再除以分组数,得到判断值;
• 判断值大于经验值(1.7)则认为数据倾斜;
我们举例说明一下该算法。例如当前分析某个字段的柱状图数据如下:

该柱状图分为 5 组,最大值为 80,最小值为 0,因此按照 80/5 = 16 等分
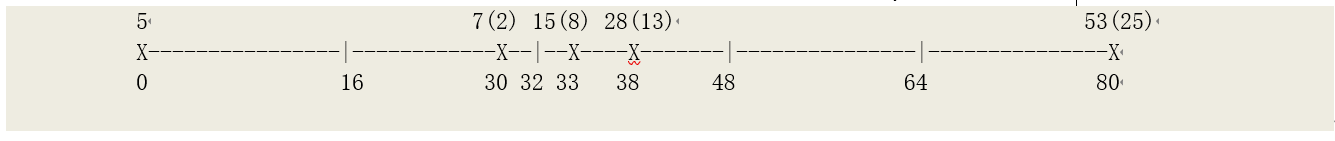
然后去每个等分范围内第一个分组的数据数做平方和:
0 至 16 内没有分组;
16 至 32 中有一个分组(第二组),取其数据数的平方:(7-5)^2 = 4;
32 至 48 中有两个分区,取第一个分组(第三组)的数据数的平方,并累加:4 + (15-7)^2 =
68;
48 至 64 内没有分组;
64 至 80 中有一个分组,取上一次被计算分组到此分组(第四、五组)之间的数据数的平方,
并累加:68+(53-15)^2 = 1512;
上述累加值除以分组数得到判断数:1512/5 = 302.4。该数值大于 1.7,因此属于倾斜数据。
柱状图数据分类:频率柱状图还是高平衡柱状图
依据字段的唯一值数、分布特性等因素,柱状图数据分为频率柱状图(Frequency Histogram) 和高度平衡柱状图(Height Balanced Histogram)。这两种柱状图不仅收集的过程不同,而且它们的分组方式、相关数据(结束点数,Endpoint Number)所代表的含义也不同,甚至影响到其它统计数据,如密度(Density)的算法不同。
在判断是否是频率柱状图还是高度平衡柱状图时,需要依据其他几个统计数据:唯一值数、数
据记录数、密度和柱状图实际的分组数。但是,唯一值数实际的分组数是需要创建了柱状图数据以 后才能知道的。因此,Oracle 采用的方法是:先按照某种方法尝试创建柱状图数据,然后检查数据
是否符合这种柱状图的要求,如果不符合,再用另外一种方法创建。其基本原则是,优先创建频率 柱状图,再考虑高平衡柱状图,如果两种柱状图都满足要求,则采用频率柱状图,大致的过程如下:
1、 估算出唯一值数(NDV);
2、 依据 BUCKET SIZE 设置,得到最大分组数(Maximum Number of Bucket,MNB),具体方法参见前面章节;
3、 由 NDV 判断是否先产生创建频率柱状图,判断规则为 NDV < 0.9*2000,判断式不成立, 则进入下一步,创建高平衡柱状图,否则创建频率柱状图、并按照以下规则判断柱状图数据是否可用:
• 获取到的分组数小于 MNB,柱状图分析完成;
• 获取到的分组数大于 MNB 且小于 2000,尝试将 Frequecy 柱状图转换为 Height
Balanced 柱状图;
• 上述两条都不满足,则丢弃该柱状图数据,进行下面步骤;
4、 尝试创建高平衡柱状图,并按照以下规则判断柱状图数据是否可用:
• 高平衡柱状图数据数据必须是能被保存的数据,保存柱状图的条件参见上节:
• 如果所有取样数据都是“流行”数据,并且每个流行数据都占用一个分组,则尝试将 高平衡柱状图转换为频率柱状图;否则,由当前高平衡柱状图来计算字段密度
(Density),
o 如果计算出的数据符合要求,则:
如果已经尝试过创建频率柱状图,说明该数据不适合创建为频率柱状图,柱 状图分析完成,采用高平衡柱状图;
如果没有尝试过创建频率柱状图,则尝试创建频率柱状图,如果频率柱状图 可用就采用频率柱状图,否则仍然采用高平衡柱状图,柱状图分析完成;
o 否则,丢弃当前柱状图数据,柱状图分析失败,需要调整取样比重新计算;
从上述柱状图创建过程可见,最大分组数对于柱状图类型有着重要的决定作用。而最大分组数的来源有两种(见上节内容):系统自动判断或者人为指定。因此,当认为指定值不合理时,可能会导致生成一个不合理的柱状图类型。我们来看以下例子:

我们指定其最大分组数为 10,导致 Oracle 为该字段创建了一个高平衡柱状图。
提示:存在一种特殊情况:当唯一值数等于最大分组时,创建的柱状图既满足频率柱状图要求又满 足高平衡柱状图要求,Oracle 依照频率柱状图的创建方式创建其柱状图,但是桶统计视图查询时, 将其归为高平衡柱状图。以下是统计数据的关于柱状图类型的定义:
如何创建频率柱状图
频率柱状图字段的唯一值数较少,柱状图的每个分组即代表了一个唯一值数,因而其创建过程比较简单:通过聚集函数对字段数据分组获取每个唯一值的重复数值数。从跟踪文件中可以找到相应的语句:

如何创建高平衡柱状图
高平衡柱状图的特点是每个分组大小相近,含有一个或多个唯一值。因此,创建高平衡柱状图的分组已经是唯一值的重复数据数,而非唯一值本身。在创建高平衡柱状图时,Oracle 利用了一个内部的窗口函数:NTILE。这个函数的作用是,根据给出的分组数和记录总数,计算出每个分组的大小(即包含的数据记录数),然后依次设置每条数据记录的分组编号:当前分组如果有空间就放 入当前桶中,否则放入下一个分组中。
在使用 NTILE 函数获取到每条记录的分组编号后,在按照分组编号分组,将每个唯一值放入一个分组中(如果 NTILE 函数为一个唯一值的多条数据记录分配到了 2 个或者 2 个以上的分组,则将其编入编号最大的一个分组内),并计算每组数据中的重复数据记录数和最大、最小数据得到高平 衡柱状图数据。其中,最大、最小数据用于判断“流行”数据的存在:如果一个分组中最小、最小 值相同,则说明其存储了一个“流行”数据。从跟踪文件中,可以得到以下查询语句用于高平衡柱状图数据的获取:
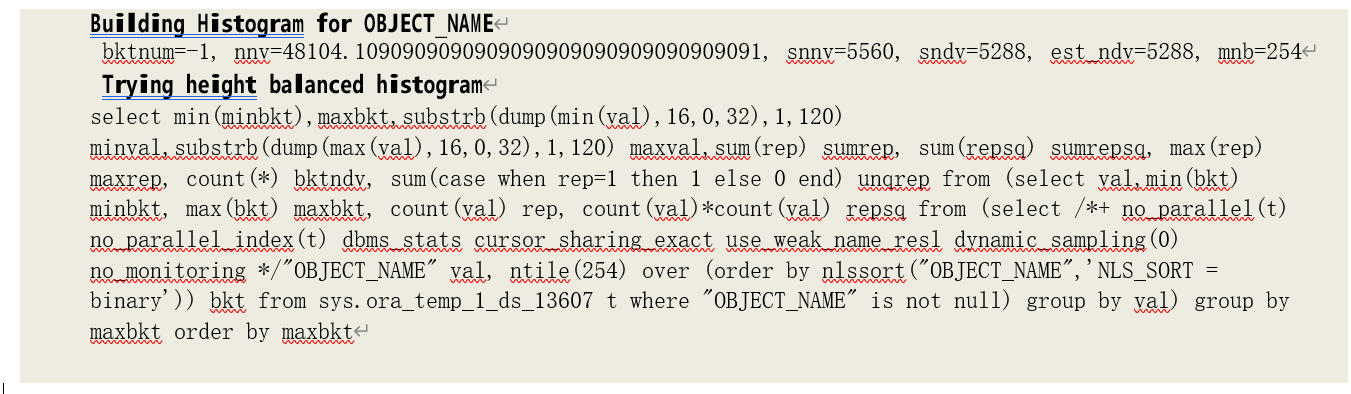
提示:由于是按照最大编号原则分配数据记录到分组,因此,为了保存字段的最小值,还需要创建
一个 0 号分组,其结束值(Endpoint Value)为字段最小数值。
如何将频率柱状图转换为高平衡柱状图
我们在上述柱状图创建过程可以看到,为了避免重新扫描表,如果尝试创建的某种类型柱状图数据不符合规则的话,会先尝试将其转换为另一种类型的柱状图数据。频率柱状图向高平衡柱状图 的转换过程实际上和查询语句的实现过程类似。
由于频率柱状图的每个分组记录了一个唯一值及其重复数据数,因此,频率柱状图向高平衡柱 状图数据转换规则如下:
• 按照当前最大分组数重新划分柱状图分组,并根据当前柱状图中唯一值数计算新的分组的 大小,保证它们相互平衡;
• 每个唯一值放入一个新的分组中,如果分组中的数据记录数达到了平均记录数的限制,则 创建新的分组,结束值为最后一个唯一值,并由当前分组编号与上一分组编号(编号相同, 则说明一个旧的分组占据了一整个新的分组,其唯一值为“流行”数据)来确认放入新分 组中的数据是否为“流行”数据;
• 以此类推,直到所有分组都被放入新的分组中。
如何将高平衡柱状图转换为频率柱状图
首先,我们回顾之前内容,尝试将高平衡柱状图转换为频率柱状图需要满足条件:所有取样数据都是“流行”数据,并且每个流行数据都占用一个分组。并且,在分析高平衡柱状图的过程中, 每个分组的数据记录数都是会被记录的。因此,对于满足这样条件的高平衡柱状图,转换为频率柱 状图的过程就比较简单,仅转换每个分组的结束点值:
• 柱状图的分组可以直接转换为频率柱状图的分组;
• 每个分组的结束点值为当前所有分组的数据记录数的累加值;
• 以此类推,直到所有分组的结束点值都被转换;
柱状图数据含义
每个字段的柱状图由多条记录组成,每条记录的关键数据有两个:结束点值(End Point Value) 和结束点数(End Point Number)。在不同类型的柱状图中,它们代表了不同的含义:
• 频率柱状图中,每个唯一值占用一个分组,因此其柱状图数据的含义为:
o 结束点值为每个分组对应的唯一值;
o 结束点数为当前所有分组的数据记录数的累加值,即当前分组的结束点数与前一分 组的结束点数的差值为当前分组中所有唯一值的重复数据数;
• 高平衡柱状图中,每个分组包含一个或多个唯一值,并含有相近的数据记录数,因此其柱 状图数据的含义为:
o 结束点值为分组最大的唯一值;
o 结束点数为分组编号;
提示:对于频率柱状图,如果数据是由样本数据分析得出的,结束点数是样本数据(而非全表数据) 中重复值数据数的累加数。
从上述柱状图数据含义描述来看,结束点数是一个数字类型的数据。但是,结束点值则与其字 段的数据类型相关,而在数据字典中,所有字段的结束点值都是存储在同一字段中,因此,Oracle 需要根据特定方法将字段的原始数据转换为统一的数据类型:数字类型。
各种数据类型的转换规则如下。并且,依据其转换规则,我们还给出其相应的不完全反向转换 方法,从而可以从已经创建的柱状图数据中获取到其对应的原始数据。
之所以称为“不完全”反向转换,是因为结束点数值存储时采用了 ROUND 方法。
数字类型(NUMBER 及其衍生类型)
数字类型字段的结束点值存储的规则很简单:原始数据 ROUND 保留左起 15 位。因此,其结束点转换和原始数据的反向转换的方法都很简单:原始数据小于等于 15 位时,结束点值即为原始数据。
数字类型转换结束点值示例:

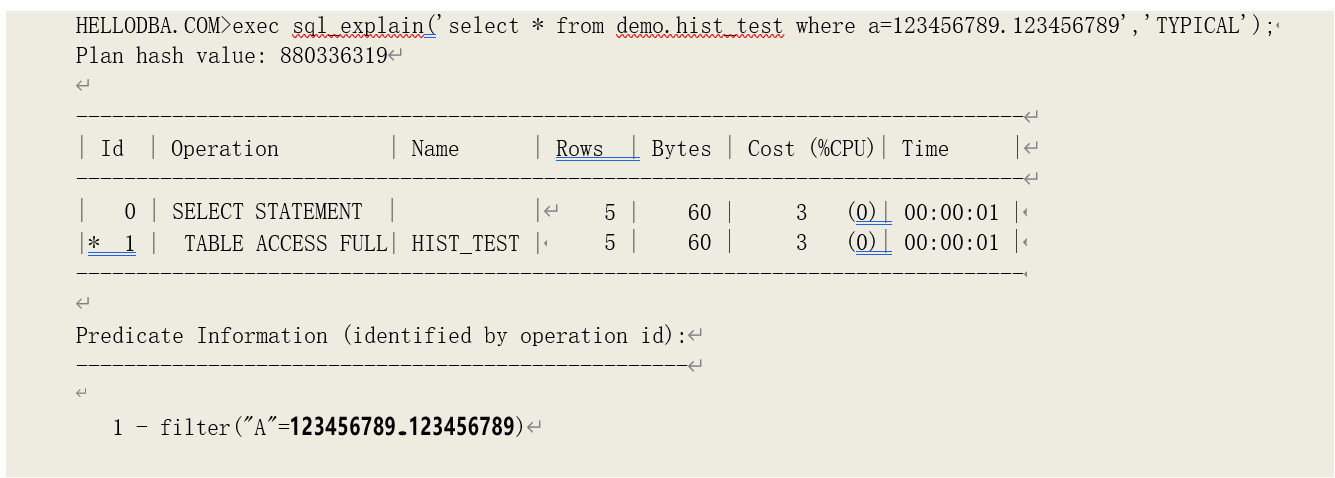
但是,由于结束点数据仅保留原始数据的左边 15 位,当原始数据长度超过 15 位,分析得出的柱状图数据就可能会导致优化器估算错误。看下例,运行脚本:

示例表中的原始数据长度超过了 15 位,并且前两个唯一值(123456789.123456789 和
123456789.123456799)的数值变化是出现在第 15 位以后。因此,分析得出的柱状图数据就会出现以下情况:

可以看到:第一、二两个分组的结束点值相同。此时,优化器由这些柱状图数据了估算数据选择率时就会出现错误:
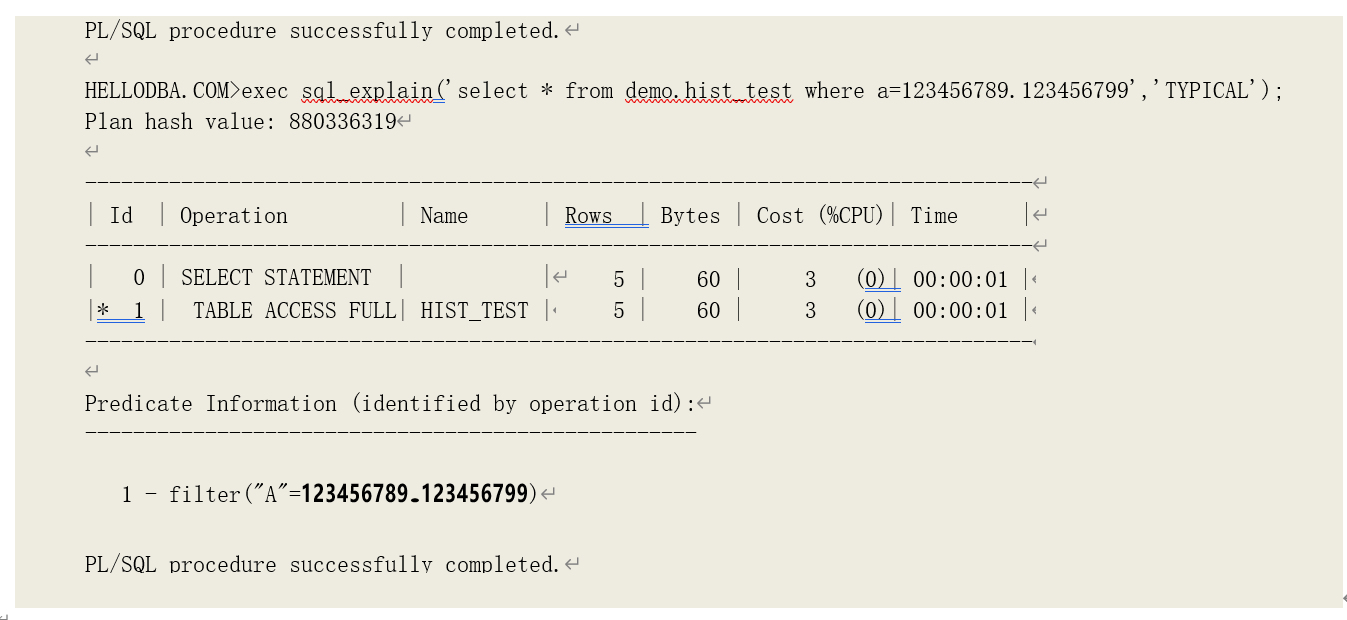
当我们分别用 123456789.123456789 和 123456789.123456799 作为绑定变量值进行执行计划分析时,优化器估算到选择的数据记录数为 5,即第二个分组的数据记录数(6-1=5)。
提示:对于其他数据类型,Oracle 也会按照特定规则转换为数字,并 ROUND 后存储,因此也可能出现上述情况。
时间日期类型(DATE 及其衍生类型)
将日期类型数值存储为结束点值时,将数据转换为以天为单位的数字,其中时间部分可以这样 转换:将时间转换为秒为单位后除以 246060(即一天的总秒数)。并将获得的数字如同数字类型一样,ROUND 到左起 15 位:
日期类型转换结束点值示例:

相应的不完整反向转换示例:
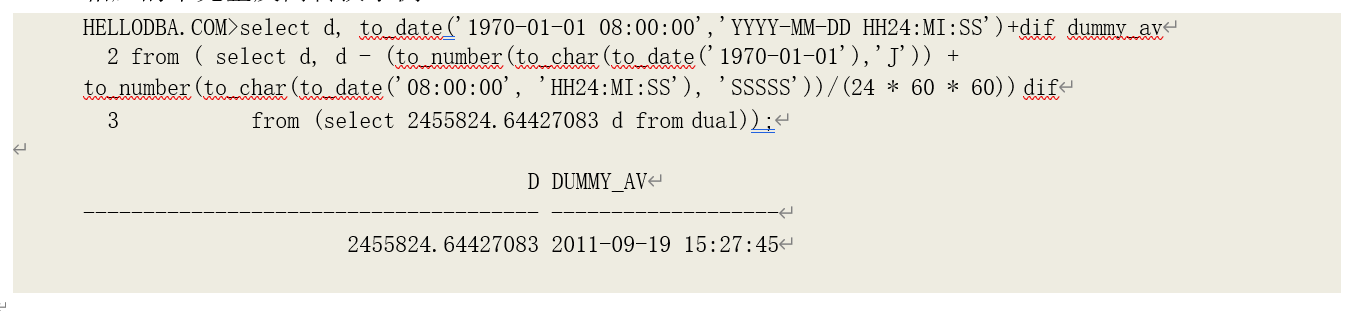
其中’08:00:00’为时区。
RAW 类型
RAW 类型数据存储为结束点值时,Oracle 将前 30 位字节由 16 进制转换为 10 进制,不足 30 位
的左边用 0 补齐,然后将该 10 进制数字 ROUND 到左起第 15 位存储。
RAW 类型转换结束点值示例:

相应的不完整反向转换示例:

字符类型(CHAR、VARCHAR2、NCHAR、NVARCHAR2)
字符类型数据存储为结束点值时,先将字符数据转换为 RAW 类型数据,然后按照 RAW 类型数据的存储方法存储:转换为 10 进制数字后 ROUND 到左起 15 位。
字符类型转换结束点值示例:

相应的不完整反向转换示例:

由于结束点值存储过程中会做 Round 截断数据,导致反向转换得到的数据会在后半部分出现乱码。通过数据比较可以发现,结束点值的数据精度通常仅相当于原数据的 6 至 7 位。这就会使得创建出来柱状图中,出现相同结束点值的分组的概率大大增加,发生查询计划估算错误的几率也增加
(如数字类型部分的例子)。为了减少这种错误,Oracle 在创建 H 柱状图时,如果发现存在结束点值相同的分组,则会将所有结束点值的实际值(Endpoint Actual Value)存储到数据字典 histgrm$的字段 EPVALUE 中(在柱状图查询视图中,其表现为字段 ENDPOINT_ACTUAL_VALUE),在做代价估算时,如果变量值通过结束点值可以匹配到多个分组时时,再用原值存储进行匹配。
提示:仅有字符类型数据才会保存实际值。
ROWID 类型
ROWID 类型数据存储为结束点值时,先将 ROWID 的各个部分转换为 16 进制数字,再转换为
10 进制数字,并按照数字类型数进行转储。注意,从 Oracle 8i 开始,标准 ROWID 构造的方法为:
• 前 4 位为(Data Object Number);
• 第 5~6.5 位(即第 6 位数字的前 4 个字节)为数据文件编号(File Id)的 64 进制数据;
• 第 6.5(第 6 位数字的后 4 个字节)~8 位为数据块编号(Block Number);
• 第 9、10 位数据记录编号(Row Number);
ROWID 类型转换结束点值示例:
由于结束点值存储过程中会做 Round 截断数据,导致反向转换得到的数据会在后半部分出现乱码。通过数据比较可以发现,结束点值的数据精度通常仅相当于原数据的 6 至 7 位。这就会使得创建出来柱状图中,出现相同结束点值的分组的概率大大增加,发生查询计划估算错误的几率也增加
(如数字类型部分的例子)。为了减少这种错误,Oracle 在创建 H 柱状图时,如果发现存在结束点值相同的分组,则会将所有结束点值的实际值(Endpoint Actual Value)存储到数据字典 histgrm$的字段 EPVALUE 中(在柱状图查询视图中,其表现为字段 ENDPOINT_ACTUAL_VALUE),在做代价估算时,如果变量值通过结束点值可以匹配到多个分组时时,再用原值存储进行匹配。
提示:仅有字符类型数据才会保存实际值。
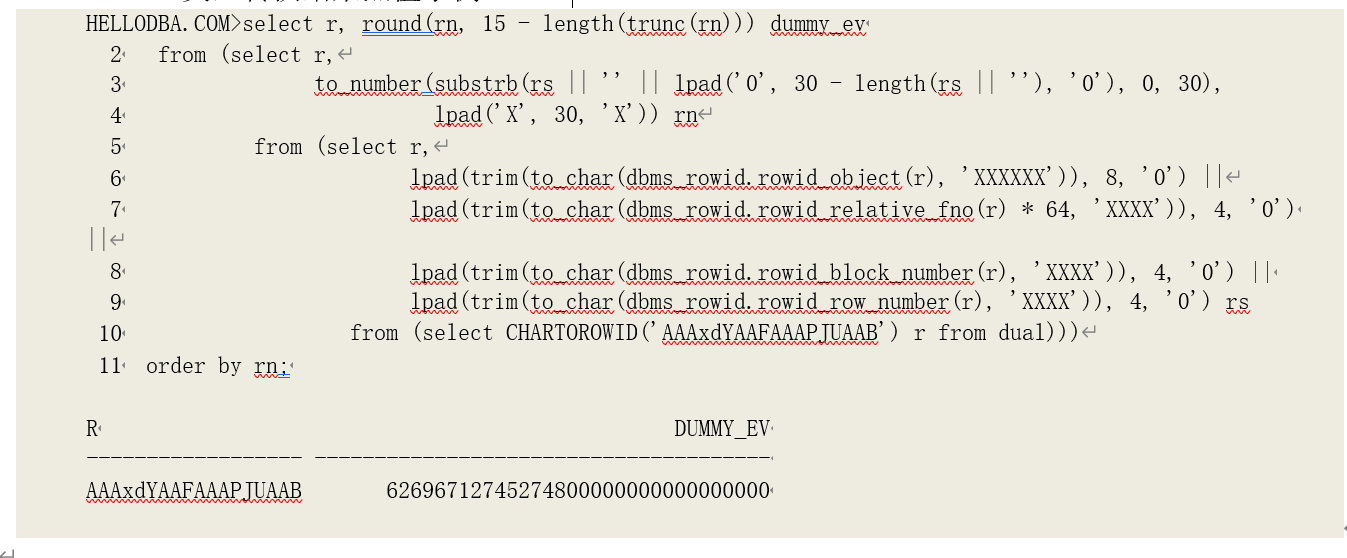
提示:由于 ROWID 数据存储为结束点值时,会将各个部分转换为 16 进制字符后进行拼接。因此,
将结束点转换回 16 进制字符串后,很难判断 ROWID 各个部分相应的字符串。下例是在我们已知原有数据位置的情况下做的方向转换。
相应的不完整反向转换示例:


密度(Density)的计算
字段的统计数据,最大的作用就是用于判断相应谓词的选择率。在已知谓词中变量值或者优化器解析时启用了绑定变量窥视时,一个精确的柱状图数据可以帮助优化器计算出精确的选择率。而 如果在优化器做解析时,不知道绑定变量值,密度就成为了选择率计算的主要依据。密度的计算依 赖于柱状图数据(在分析了柱状图数据的情况下)和唯一值数。
在各种情况下,密度的分析过程如下。
• 在分析频率柱状图时
o 当字段在分析频率柱状图数据时,密度的计算也比较简单————由记录数得来:
Density = 1/(2SIZE)
o 如果数据是由采样得来的,记录数是由样本记录数(SSIZE)计算得来的:
SIZE = SSIZE100/PCT
相应的,Density 的计算公式也变为:
DENSITY = 1/(2SIZE) = 1/(2SSIZE100/PCT) = PCT/(SSIZE200)
由于字段采样百分比不会被存储起来,我们可以从分析的跟踪输出中找到相关内容验证:

从跟踪内容可以知道字段 OWNER 采用的采样百分比为 11.55826415887,验证其数据字典中的密度数据:
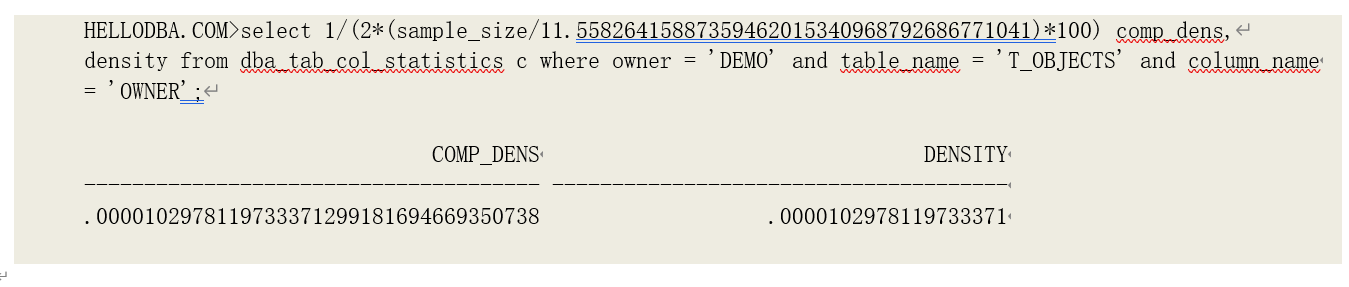
公式计算出的密度与其存储的密度是一致的。
• 在分析高平衡柱状图时
在分析高平衡柱状图时,密度数据是由分组数和柱状图中“流行”数值的数据记录数放缩得出 的,计算过程描述如下:
1、 计算出密度的倒数,即密度计算公式中的分母(INVDEN),它的计算依赖于取样数据 记录数(SSIZE)、流行数值数据记录数(POPCNT),以及它们的平方和。SSIZESQ=SSIZE12+SSIZE22…=∑SSIZEn^2
POPCNTSQ=POPCNT12+POPCNT22…=∑POPCNTn^2
其中,SSIZE1、SSIZE2…SSIZEn 为柱状图每个分组中的取样记录数,POPCNT1、
POPCNT2…POPCNTn 为各个“流行”数值的数据记录数。
INVDEN := SSIZE * ((SSIZE - POPCNT) / (SSIZESQ - POPCNTSQ));
2、 是否采用计算结果,由表达式(PCT < 100)判断,
o 如果没有采样,则直接对第一步计算得到倒数直接计算密度;
DENSITY = 1 / INVDEN
o 如果为采样数据,则需对 INVDEN 进行放缩计算,放缩方式有两种:
当取样比与样本数据中非空数据记录数(Sample Number of Not-null Value,SNNV) 与样本中唯一值数(Sample Number of Distinct Value,SNDV)比例满足特定要求时,采样内部的放缩方法:KKESDV(Kernal Kompile Engine Scale Distinct Value,
来源于 Oracle 编译器引擎的一个内部 API,在包 DBMS_STATS 中用 PLSQL 将其重写)放缩法;在 11g,如果是采用了新算法,也采用该方法对 INVDEN 进行放缩;
如果取样比、SNNV 和 SNDV 满足线性放缩条件,则直接对 INVDEN 进行线性放缩:
INVDEN := INVDEN * 100 / PCT;
如果上述两种放缩方法的条件都不满足,则需要调整取样比重新计算密度;
如果满足放缩条件,则密度由放缩后的 INVDEN 计算得出:
DENSITY = 1 / INVDEN
• 没有柱状图数据时
o 当没有柱状图数据时,密度是由 NDV 直接计算得来。
DENSITY = 1/NDV
但此时如果是通过采样获取到的统计数据(仅获取到 SNDV),那么 NDV 需要由 SNDV 放缩计算得出,分为几种情况:
如果字段是唯一字段,NDV 可以直接线性推导:
NDV = ROUND(SNDV100/PCT) => Density=1/ROUND(SNDV100/PCT)
如果为非唯一字段,则检查满足哪种放缩算法的条件,选择一种放缩(kkesdv 或线性)方法计算密度倒数。由于不存在柱状图相关数据,此时的密度导数就是
SNDV。放缩得到的密度导数也就是唯一值数 NDV
如果上述条件都不满足,则需要调整取样比重新计算密度;
如果计算得到 NDV,则密度由 NDV 计算得出:
DENSITY = 1 / NDV
• 校验与修正
Oracle 最后还会对数据做一次校验,修改不合理的数据。对于密度,会先检查 NDV 是否大于表的记录数(NROWS),如果大于的话说明 NDV 不合理,此时,如果密度是由公式 1/NDV 计算得来的话,则要将其修正为 1/NROWS。
提示:BLOB、CLOB、BFIEL、CFILE、LONG、LONG RAW 等数据类型,不会计算密度。
