




Postgres 13 Beta3 于2020/8/13发布。Postgres Beta 1和2分别于2020年5月和2020年6月发布。我对Postgres 13感兴趣的功能之一是B-Tree重复数据删除工作。B树索引是Postgres中的默认索引方法,并且可能是生产环境中最常用的索引。对数据库这一部分的任何改进都可能带来广泛的好处。从索引中删除重复项可以使其物理尺寸更小,减少I / O开销,并应有助于保持SELECT查询的速度!
安装Postgres 13 Beta 3
第一步是在单个Ubuntu 18主机上安装两个版本的Postgres(12和13beta3)。过去,当我测试预生产版本时,我是从源代码而不是使用构建Postgres的apt。这次,我决定使用apt install,因此包括了基本过程。
建议的安装PostgreSQL的方法是从pgdg(PostgreSQL全球开发小组)存储库中,有关更多信息,请参见Postgres Wiki。要启用测试版,所需的行/etc/apt/sources.list.d/pgdg.list是:
deb http://apt.postgresql.org/pub/repos/apt/bionic-pgdg main 13
完成后,更新源代码并安装Postgres和PostGIS。
sudo apt update
# Postgres 12
sudo apt install postgresql-12 postgresql-12-postgis-3
# Postgres 13 (Currently Beta)
sudo apt install postgresql-13 postgresql-13-postgis-3
在Ubuntu上,安装多个版本将创建在不同端口上运行的多个实例。我用于撰写本文的测试服务器当前安装了三个版本的Postgres,目前仅运行两个。首先安装了Postgres 12,因此“赢得”了默认端口5432。第二次安装了Postgres 11,并为其分配了5433,最后安装了Pg13 beta 3,并为其分配了端口5434。pg_lsclusters在Debian / Ubuntu主机上,该端口是其中可用的一部分, 包装器pg_ctl。
sudo -u postgres pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
11 main 5433 down postgres /var/lib/postgresql/11/main /var/log/postgresql/postgresql-11-main.log
12 main 5432 online postgres /var/lib/postgresql/12/main /var/log/postgresql/postgresql-12-main.log
13 main 5434 online postgres /var/lib/postgresql/13/main /var/log/postgresql/postgresql-13-main.log
This post does not use Postgres 11 beyond this example.
除此示例外,本文不使用Postgres 11。
当安装了多个版本时,确认版本与您期望的版本匹配会很有帮助。首先,Postgres 12版本的端口5432。
psql -d pgosm -p 5432 -c "select version();"
┌──────────────────────────────────────────────────────────────────────────────┐
│ version │
╞══════════════════════════════════════════════════════════════════════════════╡
│ PostgreSQL 12.4 (Ubuntu 12.4-1.pgdg18.04+1) on x86_64-pc-linux-gnu, compiled…│
│… by gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0, 64-bit │
└──────────────────────────────────────────────────────────────────────────────┘
现在,Postgres 13版本的端口5434。
psql -d pgosm -p 5434 -c "select version();"
┌──────────────────────────────────────────────────────────────────────────────┐
│ version │
╞══════════════════════════════════════════════════════════════════════════════╡
│ PostgreSQL 13beta3 (Ubuntu 13~beta3-1.pgdg18.04+1) on x86_64-pc-linux-gnu, c…│
│…ompiled by gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0, 64-bit │
└──────────────────────────────────────────────────────────────────────────────┘
创建索引
这两个版本的Postgres都使用osm2pgsql加载了相同的Colorado OpenStreetMap数据。osm2pgsql不会自行创建任何B树索引,而只会创建几何体上的GIST索引。对于这篇文章,我们研究的四列创建B树索引大小: osm_id,highway,waterway,和natural。查看public.planet_osm_line表格上的统计信息,我可以做出一些猜测,即根据,我们将会和不会看到的收益n_distinct。我猜想我们不会在中看到重大收益 osm_id,这些值中只有少量重复。其他三列(highway,natural和waterway)具有小数量的不同值的和不同量的NULL价值观。这三列都将成为部分索引的候选项,以避免对NULL值进行索引,从而减小了所创建索引的大小。我希望在这些列上看到Postgres 13的好处,可能会减少部分索引的使用频率。
SELECT attname, n_distinct, null_frac
FROM pg_catalog.pg_stats
WHERE tablename = 'planet_osm_line'
AND attname IN ('osm_id', 'highway', 'waterway', 'natural')
;
┌──────────┬────────────┬────────────┐
│ attname │ n_distinct │ null_frac │
╞══════════╪════════════╪════════════╡
│ osm_id │ -0.833553 │ 0 │
│ highway │ 26 │ 0.41616666 │
│ natural │ 4 │ 0.994 │
│ waterway │ 9 │ 0.6663 │
└──────────┴────────────┴────────────┘
索引上 osm_id
首先是该osm_id列,它是一组几乎唯一的正值和负值。在两个版本中创建的索引:
CREATE INDEX ix_osm_line_osm_id ON public.planet_osm_line (osm_id);
以下查询始终用于报告索引大小。查询本身将不会重复,因为只会更改过滤器。
SELECT ai.schemaname AS s_name, ai.relname AS t_name,
ai.indexrelname AS index_name,
pg_size_pretty(pg_relation_size(quote_ident(ai.schemaname)::text || '.' || quote_ident(ai.indexrelname)::text)) AS index_size,
pg_relation_size(quote_ident(ai.schemaname)::text || '.' || quote_ident(ai.indexrelname)::text) AS index_size_bytes
FROM pg_catalog.pg_stat_all_indexes ai
WHERE ai.indexrelname LIKE 'ix_osm_line%'
ORDER BY index_name
;
由于重复的数量少,因此该演出的尺寸只有很小的减小也就不足为奇了。仅从index_size列(以MB为单位)就无法检测到减少,这 index_size_bytes表明大小略有减少(29,515,776字节与29,384,704字节)。
第12页
┌─[ RECORD 1 ]─────┬────────────────────┐
│ s_name │ public │
│ t_name │ planet_osm_line │
│ index_name │ ix_osm_line_osm_id │
│ index_size │ 28 MB │
│ index_size_bytes │ 29515776 │
└──────────────────┴────────────────────┘
第13页
┌─[ RECORD 1 ]─────┬────────────────────┐
│ s_name │ public │
│ t_name │ planet_osm_line │
│ index_name │ ix_osm_line_osm_id │
│ index_size │ 28 MB │
│ index_size_bytes │ 29384704 │
└──────────────────┴────────────────────┘
索引上 highway
highway数据planet_osm_line的数据是当一个很好的例子 部分索引 通常可能是一个好主意,以尽量减少索引的大小。我的直觉(也是希望)是,通过减少索引大量NULL值所需的大小,重复数据删除将使此处的部分索引成为一个争论点。
创建两个索引,一个索引部分覆盖非NULL值,另一个索引全表。
CREATE INDEX ix_osm_line_highway_partial
ON public.planet_osm_line (highway)
WHERE highway IS NOT NULL;
CREATE INDEX ix_osm_line_highway_full
ON public.planet_osm_line (highway);
Postgres 12中的两个索引请注意,部分索引从完整索引中删去了大约1/3的大小。
┌────────┬─────────────────┬─────────────────────────────┬────────────┐
│ s_name │ t_name │ index_name │ index_size │
╞════════╪═════════════════╪═════════════════════════════╪════════════╡
│ public │ planet_osm_line │ ix_osm_line_highway_full │ 30 MB │
│ public │ planet_osm_line │ ix_osm_line_highway_partial │ 19 MB │
└────────┴─────────────────┴─────────────────────────────┴────────────┘
现在在Postgres 13和WOW中查看相同的两个索引!Postgres 13中的完整索引大约是Postgres 12中的部分索引的一半!有了这种节省空间的方式,我并不希望我会经常在任何地方都对分索引感到困扰。
┌────────┬─────────────────┬─────────────────────────────┬────────────┐
│ s_name │ t_name │ index_name │ index_size │
╞════════╪═════════════════╪═════════════════════════════╪════════════╡
│ public │ planet_osm_line │ ix_osm_line_highway_full │ 8944 kB │
│ public │ planet_osm_line │ ix_osm_line_highway_partial │ 5272 kB │
└────────┴─────────────────┴─────────────────────────────┴────────────┘
我不期望仅此一项改进就能消除对部分索引的需求。相反,它将减少对边缘情况的较小子集的部分索引的需求。部分索引仍将是一个有用的工具。
waterway和的索引natural
最后两列要测试的唯一和空置比率与高速公路列不同。创建索引。
CREATE INDEX ix_osm_line_waterway_partial
ON public.planet_osm_line (waterway)
WHERE waterway IS NOT NULL;
CREATE INDEX ix_osm_line_waterway_full
ON public.planet_osm_line (waterway);
CREATE INDEX ix_osm_line_natural_partial
ON public.planet_osm_line ("natural")
WHERE "natural" IS NOT NULL;
CREATE INDEX ix_osm_line_natural_full
ON public.planet_osm_line ("natural");
注意:osm2pgsql创建
natural列,这是SQL中的保留关键字。您必须使用双引号引用此列,例如SELECT "natural" ...
以下是Postgres 12中这四(4)个新索引的索引大小。natural由于99.4%的行为,因此列的部分索引在这里完全胜过完整索引NULL。水道还节省了部分索引,其中67%是行NULL。供参考,高速公路栏为42%NULL。
┌────────┬─────────────────┬──────────────────────────────┬────────────┐
│ s_name │ t_name │ index_name │ index_size │
╞════════╪═════════════════╪══════════════════════════════╪════════════╡
│ public │ planet_osm_line │ ix_osm_line_natural_full │ 28 MB │
│ public │ planet_osm_line │ ix_osm_line_natural_partial │ 264 kB │
│ public │ planet_osm_line │ ix_osm_line_waterway_full │ 28 MB │
│ public │ planet_osm_line │ ix_osm_line_waterway_partial │ 9680 kB │
└────────┴─────────────────┴──────────────────────────────┴────────────┘
同样,Postgres 13中的每个索引比其Postgres 12中的对应索引小很多。此处的胜利因NULL价值观的不同而发生了一些变化。
┌────────┬─────────────────┬──────────────────────────────┬────────────┐
│ s_name │ t_name │ index_name │ index_size │
╞════════╪═════════════════╪══════════════════════════════╪════════════╡
│ public │ planet_osm_line │ ix_osm_line_natural_full │ 8912 kB │
│ public │ planet_osm_line │ ix_osm_line_natural_partial │ 80 kB │
│ public │ planet_osm_line │ ix_osm_line_waterway_full │ 8912 kB │
│ public │ planet_osm_line │ ix_osm_line_waterway_partial │ 2968 kB │
└────────┴─────────────────┴──────────────────────────────┴────────────┘
TLDR;
对于具有大量重复值的列上的索引,Postgres 13的B-Tree重复数据删除是一个重大胜利。我通过重复和NULL值测试的列的大小减少了69-72%。下表将上述所有测试的结果汇总在一起。
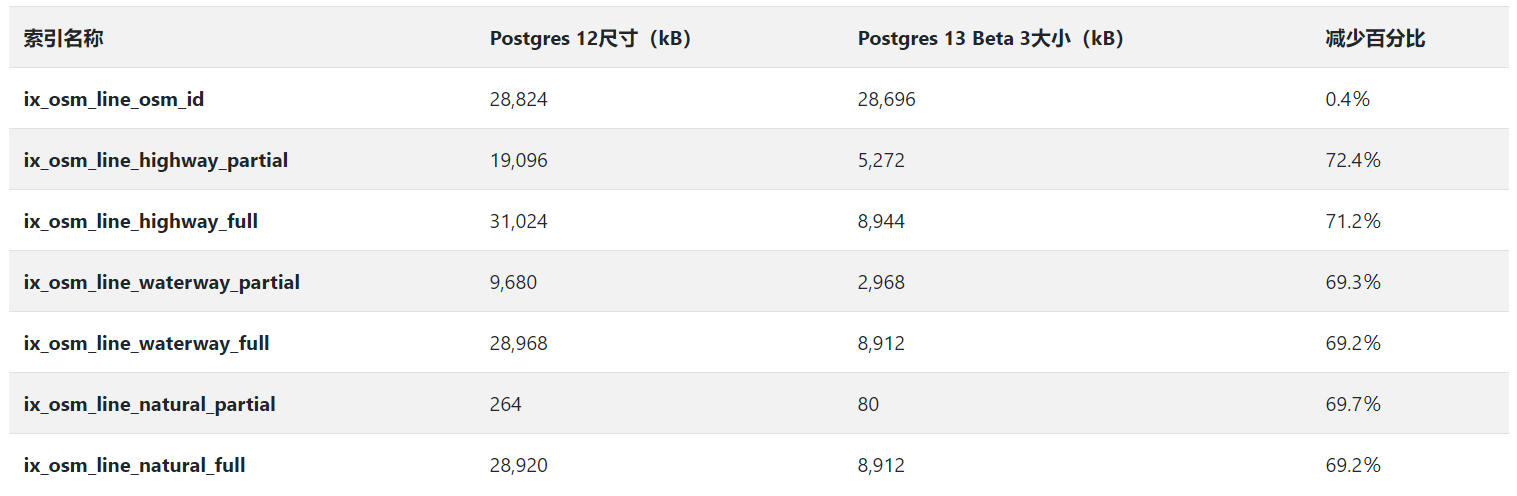
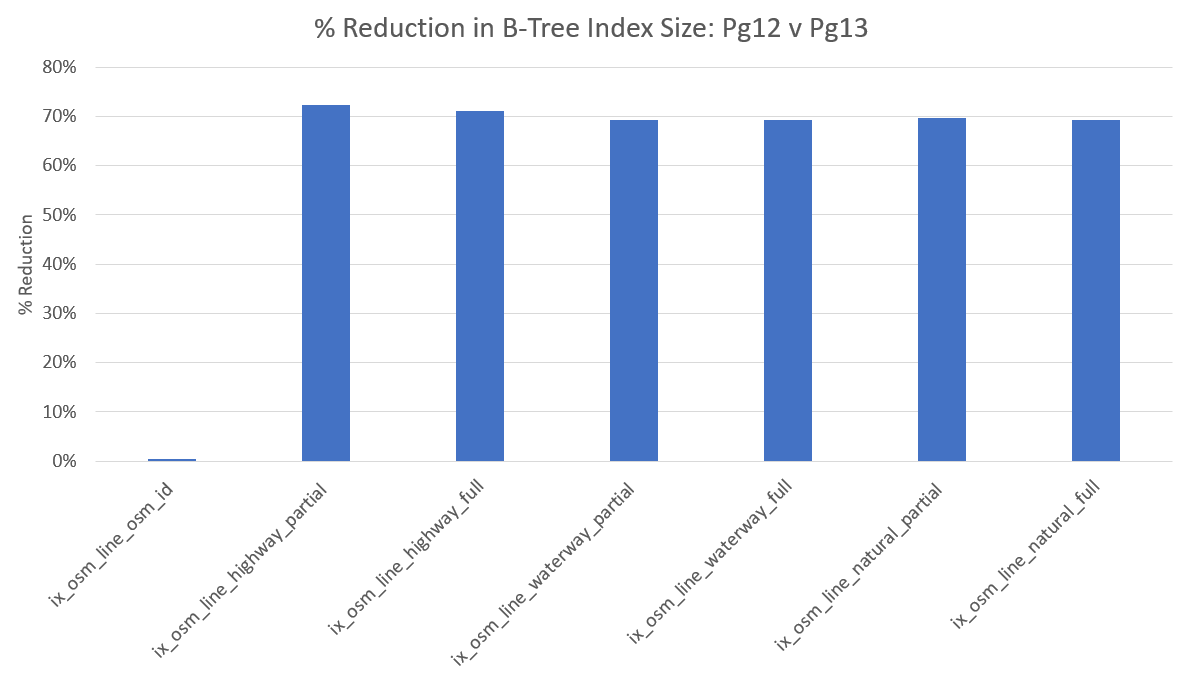
相同的数据在下面的两个图表中。首先,该图显示缩小尺寸的百分比。
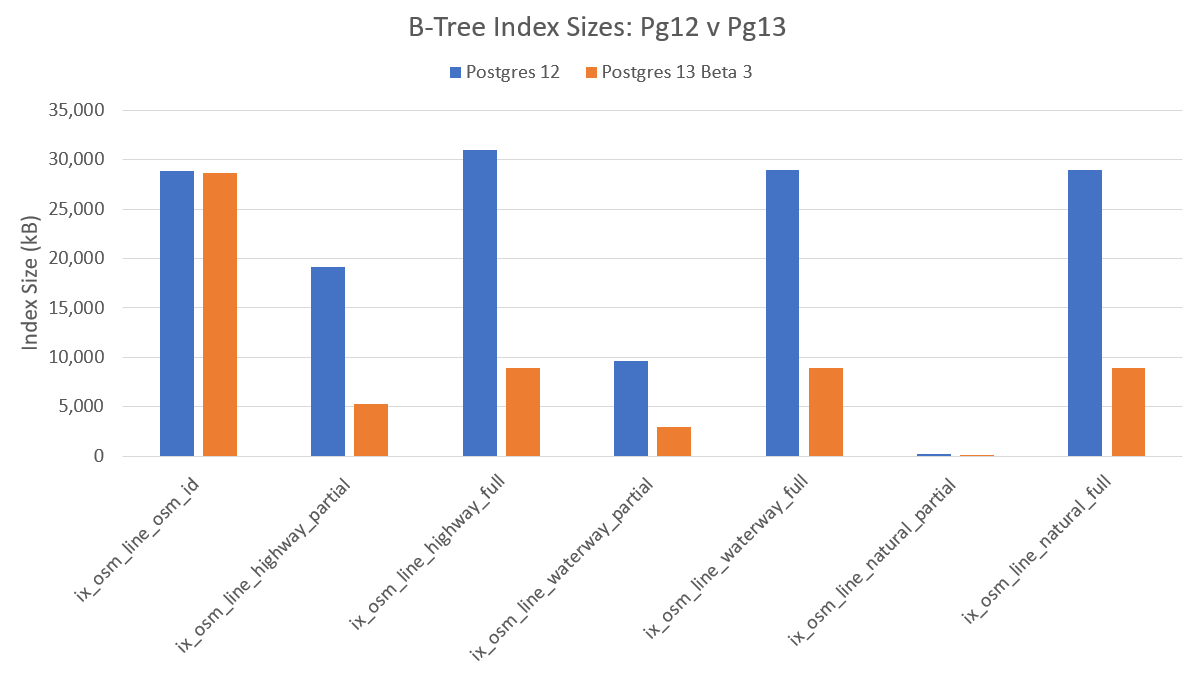
下表显示了每个测试索引的大小比较,以千字节(kB)为单位。
总结
到目前为止,关于即将发布的版本,PostgreSQL 13的B-Tree重复数据删除可能是我最喜欢的事情。这种改进在磁盘上所节省的数量给我留下了深刻的印象。尽管存在很多类似于此处显示的非唯一索引,但是它对唯一的B树索引大小没有帮助。在具有NULL值的列上创建更紧凑的索引而无需部分索引的能力是另一个好处。看起来这将更容易获得正确的索引,同时保持索引大小较小。
作者:Ryan Lambert
文章来源:https://blog.rustprooflabs.com/2020/09/postgres-beta3-btree-dedup
