




要估算查询计划的代价,就必须建立一个分析模型。在这个模型中,所有操作的代价都能被量 化,并且各种代价都能统一成相同的单位。这一模型也就是查询优化器代价模型。
我们知道,执行计划由一个操作树构成。同样,对执行计划的代价估算,就是对每个操作的代价估算,最终计算出总的代价。在查询优化模型中,每个操作都会有不同的资源消耗,而这些消耗 在优化模型中就被量化,用于其代价的估算,并且,父操作的代价依赖于子操作的代价。例如下面
执行计划:

其相应的代价估算方法为:

在 Oracle 中,基本上每一个操作都有其对应的代价估算公式和方法。其中,子操作估算出来的代价值都是其父操作代价估算的构成部分。
6.1 代价模型
我们前面提到过,SQL 执行所消耗的主要是 CPU 和 IO,这也就是运行 SQL 所需要付出的代价。因此,对语句执行计划的代价估算,实际上就是对该语句对 CPU 和 IO 的消耗的估算。
在 Oracle 中,存在两种代价模型:一种是 IO 代价模型;一种是 CPU 代价模型。优化器具体采用哪种模型进行代价估算通过参数_optimizer_cost_model 控制。
• IO:IO 代价模型,仅计算 IO 代价,值得注意的是,在这种模式下估算的 IO 次数而不考虑时间因素(例如,完成一次单数据块读和完成一次多数据块读所需要的时间是不同的,但 这种模式下两者是等价的);
• CPU:CPU 代价模型,计算 IO 代价的同时,计算 CPU 代价,并使用系统统计数据(System
Statistics)计算出 CPU 代价向 IO 代价转换的计算因子(CPU_TO_IO),将 CPU 转换为 IO
代价;
o 如果系统统计数据不可用,则采用统计数据默认值计算 CPU_TO_IO;
• FIXED:CPU 代价模型,计算 IO 代价的同时,计算 CPU 代价,并使用系统内部固定值将
CPU 转换为 IO 代价;
o 如果存在系统统计数据,则 CPUSPEED 采用固定值 100000,IOSEEKTIM 和 IOTFRSPEED
采用系统值,用于 CPU_TO_IO 计算;
o 如果系统统计数据不可用,则 CPUSPEED 采用固定值 100000,IOSEEKTIM 和
IOTFRSPEED 采用默认值,用于 CPU_TO_IO 计算;
• CHOOSE(默认值):如果存在可用的系统统计数据,则采用 CPU 代价模型,否则采用 IO
代价模型;
提示:在 SQL 语句中加入 SQL 提示 no_cpu_costing 也会使优化器估算代价时忽略 CPU 代价。
由于系统在启动时,就会以 NOWORKLOAD 模式初始化系统统计数据,因此,在默认情况下, 优化器都会采用 CPU 代价模型。
6.2 优化器跟踪
我们可以通过设置事件来跟踪优化器生成执行计划的过程:
ALTER SESSION SET “_OPTIMIZER_TRACE”=HINT|ENVIRONMENT|PHYSICAL|LOGICAL|MEDIUM|HIGH|ALL|LOW|NONE;
或者
ALTER SESSION|SYSTEM SET EVENTS ‘10053 TRACE NAME CONTEXT FOREVER, LEVEL n’;
通过设置不同的跟踪参数(ALL 为最详细、NONE 关闭)或者事件级别(1 为最详细、0 关闭) 可以在 UDUMP 目录下生成详细程度不同的跟踪文件。
在 11g 中,还可以通过以下方式跟踪特定语句或者优化器的特定组件:
ALTER SESSION|SYSTEM SET EVENTS ‘TRACE[RDBMS.SQL_Optimizer.][SQL:<SQL_ID>]’;
以下语句关闭跟踪:
ALTER SESSION|SYSTEM SET EVENTS 'TRACE[RDBMS.SQL_Optimizer.]OFF’;
此外,11g 中还可以用 DBMS_SQLDIAG 提供的方法跟踪特定语句:
PROCEDURE dump_trace(
p_sql_id IN varchar2, p_child_number IN number DEFAULT 0,
p_component IN varchar2 DEFAULT ‘Optimizer’, p_file_id IN varchar2 DEFAULT null);
6.3 基本代价计算公式
IO 代价模型中,仅计算 IO 代价,基本的代价计算公式为:
COST = IOCOST
CPU 代价模型中,语句查询的代价包括了 CPU 和 IO,因此基本的代价计算公式为:
COST = IOCOST + CPUCOST
为了得到所有的代价总量,就必须将所有代价转换为一个统一的代价单位。在代价模型中,所 有代价都转换为单数据块读的单次代价。
而在查询过程,会存在四种类型的 IO:单数据块读(Single Read Data-block,SRD)、多数据块读(Multiple Read Data-block,MRD)、直接数据块读(Direct Read Data-block,DRD)和直接数据块写(Direct Write Temp-data,DWT)。因此,IO 代价则由这四个部分组成:
IOCOST = SRDCOST + MRDCOST + DRDCOST + DWTCOST
• 单数据块读是指将一个数据块从磁盘读入共享缓存(Buffer Cache)中,再交给请求该数据块的进程;
• 多数据块读是指将多个数据块从磁盘读入共享缓存(Buffer Cache)中,再交给请求该数据块的进程;
• 直接数据块读是指将一个数据块从磁盘读入直接交给请求该数据块的进程;
• 直接数据块写是指进程将一个数据块直接写入磁盘;
因为在代价计算模型中,所有代价都会被统一成单数据块读的单次代价,因此,单数据块的代 价即为单数据块读的次数(#SRDS):
SRDCOST = #SRDS
完成一次数据块读请求,都要进行两个步骤:查找数据块在磁盘上的地址(即寻址过程)和从 磁盘读取数据块内容交给请求进程(即数据传输过程)。而在单数据块读时间(SREADTIM)和多数据块读时间(MREADTIM),它们的寻址时间是相同的,不同之处就在于数据传输时间。因此, 在 CPU 代价模型中,多数据块读的代价向单数据块读的代价就是通过两者之间的时间消耗比实现的,即多数据块读向单数据块读的转换因子就是 MREADTIM/SREADTIM。由此我们可以得到多数据块读的代价计算:
MRDCOST = #MRDS*MREADTIM/SREADTIM
而在 IO 代价模型中,则仅考虑读的次数:
MRDCOST = #MRDS
其中,#MRDS(Multiple Read Data blocks)为发生多数据块读的次数。
直接数据块读和直接数据块写也包含了寻址过程和数据传输过程,与单数据块读不同的是,直接 IO 不需要将数据拷贝到共享内存中,而直接将数据交给请求进程。但是,我们知道,磁盘数据传输效率和内存数据传输效率相差非常大,以至于如果存在磁盘数据传输的话,内存传输时间在总 的传输时间中当中可以被忽略。因此,直接 IO 的代价与单数据块读或者多数据块读的代价相当。
因此在估算含有直接 IO 的操作代价时,只需要计算出其相应的单数据块读代价或多数据块读代价。因此在 IO 代价模型中,代价计算公式为:
COST = IOCOST = #SRDS + #MRDS
而在 CPU 代价模型中,需要计算 CPU 代价。语句在读取和过滤数据的过程中,还会有其他一些处理,例如对字段的选取、字段数据与谓词条件的比较等,会导致 CPU 的消耗。而每一种处理都会根据其处理量不同请求 CPU 执行不同的指令次数,我们称之为 CPU 转数(#CPUCYCLES)。为了将这些 CPU 的消耗统一成 IO 的消耗代价,我们需要有一个 CPU 向 IO 代价转换的系数
(CPU_TO_IO),即多少个 CPU 指令次数消耗与一次单数据块读的消耗相当,从而得到基本代价公式中的 CPU 代价:
CPUCOST = #CPUCYCLES / CPU_TO_IO
而不同型号、不同数量的 CPU,处理指令的能力也不同,这种处理能力就是 CPU 的速度
(CPUSPEED,每秒钟可以完成的机器指令数,我们收集系统统计数据之一)。有了 CPU 处理能力这一统计数据,我们就可以估算出完成这些处理所需要的时间,从而也可以由单数据块读时间
(SREADTIM)得到 CPU 代价向 IO 代价的转换系数(CPU_TO_IO)。
CPU_TO_IO = CPUSPEED*SREADTIM
有了 CPU 向 IO 代价转换系统,我们就可以得到 CPU 的代价公式:
CPUCOST = #CPUCYCLES / (CPUSPEED*SREADTIM)
提示:CPUSPEED 的含义为每秒钟可以完成的机器指令数,因此#CPUCYCLES/CPUSPEED 的含义就是完成这些 CPU 指令所需要的时间。由这个时间除以单次单数据块读的时间(SREADTIM)就可以得到 CPU 代价相当于多少单次数据块读的代价:
CPUCOST = (#CPUCYCLES /CPUSPEED) / SREADTIM = #CPUCYCLES / (CPUSPEED*SREADTIM)
由上述 IO 代价与 CPU 代价的公式,进一步得到 CPU 代价模型中的基本计算公式:
COST = #SRDS + #MRDSMREADTIM/SREADTIM + #CPUCYCLES / (CPUSPEEDSREADTIM)
= (#SRDSSREADTIM + #MRDSMREADTIM + #CPUCYCLES/CPUSPEED) / SREADTIM
有了这个基本公式,在估算各个执行计划操作时,估算出操作所需要完成的 IO 次数以及 CPU
指令数,就可以计算出它的估算代价值。
注意,具体的代价估算方法和选择率的计算在 Oracle 各个版本(包括子版本)中都可能会由于优化器算法的改进而略有不同,我们以下计算及推导是以 10.2.0.4 为基础的。其他版本的算法推导也可以使用以下方法。
提示:估算出的最终代价都为整数。在代价估算的计算过程中,需要将过程数据中的小数去掉。通 过参数“_optimizer_ceil_cost”控制是否采用 CEIL 函数约除小数,默认值为 TRUE。
6.4 选择率计算
选择率(SELECTIVITY)的计算与字段统计数据中的密度(Density)、空值数(NULLS)、唯一值数(NDV)以及其柱状图(Histogram)数据有关。总的来说,如果字段存在柱状图数据,并且优 化器分析语句时,获取或者窥视到了与字段进行匹配的绑定变量的数值的话,则会利用柱状图数据 计算字段过滤的选择率;否则,则会利用密度或者内部公式计算选择率。
6.4.1 单过滤条件
我们首先考虑单个过滤条件的选择率计算。
在优化器跟踪文件中,我们可以找到依照字段匹配过滤性计算出的数据记录数。
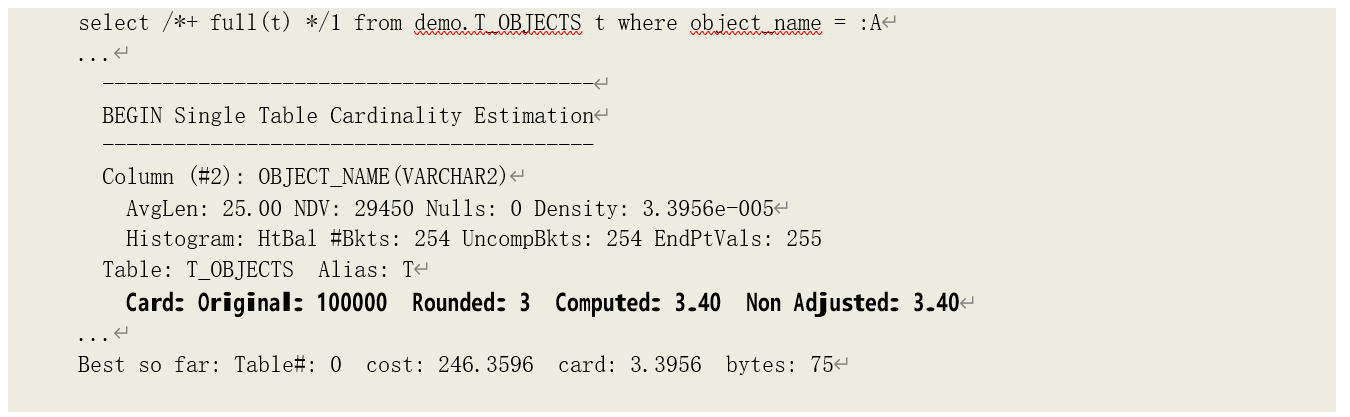
其中会显示过滤字段的统计数据,以及依据其选择率计算得出记录数(Cardinality)。通过这些 数据,我们同样可以推导出选择率的计算公式,这里不再累述。
6.4.2 绑定变量无具体数值
在绑定变量无具体数值(未做绑定变量窥视或解析时绑定变量未赋值)的情况下,选择率计算 与密度(Density)、空值数(NULLS)及唯一值数(NDV)相关。对于不同的匹配操作符,有不同的计算公式。
表 6-1 谓词匹配选择率
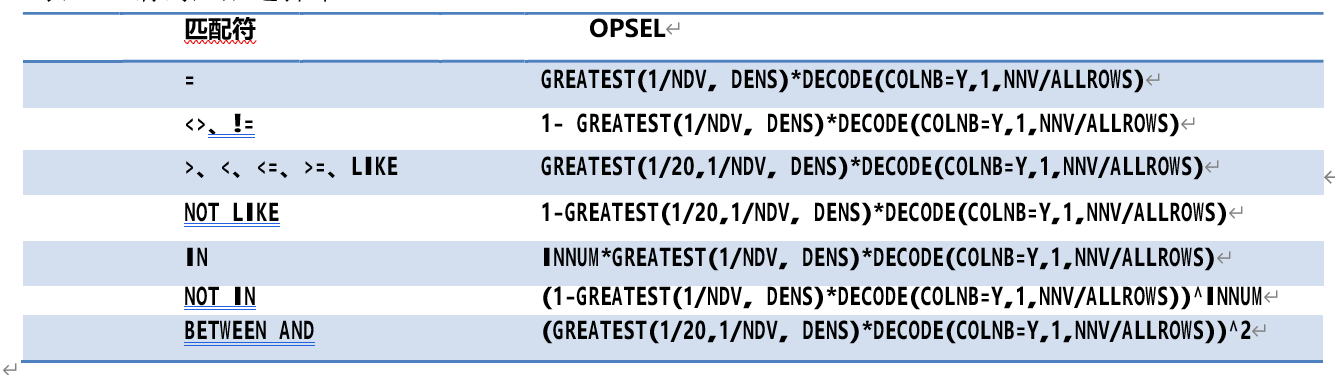
其中,
o NDV 为唯一值数、DENS 为密度、ALLROWS 为表的数据记录数,都可以从数据字典中获得;
o COLNB 表示字段是否允许为空,即是否存在非空约束,可以从字段的数据字典中获得, 这里 Y 表示允许为空、N 表示不允许为空;
o NNV 为字段的非空数值数,NNV = sample_size*ALLROWS/(sample_size+row_null),其中
row_nulls 为样本数据中的空值数,sample_size 为字段的样本记录数;
o NOTINNUM 为 IN、NOT IN 中的数值数。
