




1 项目背景
1.1 TendisX 现状
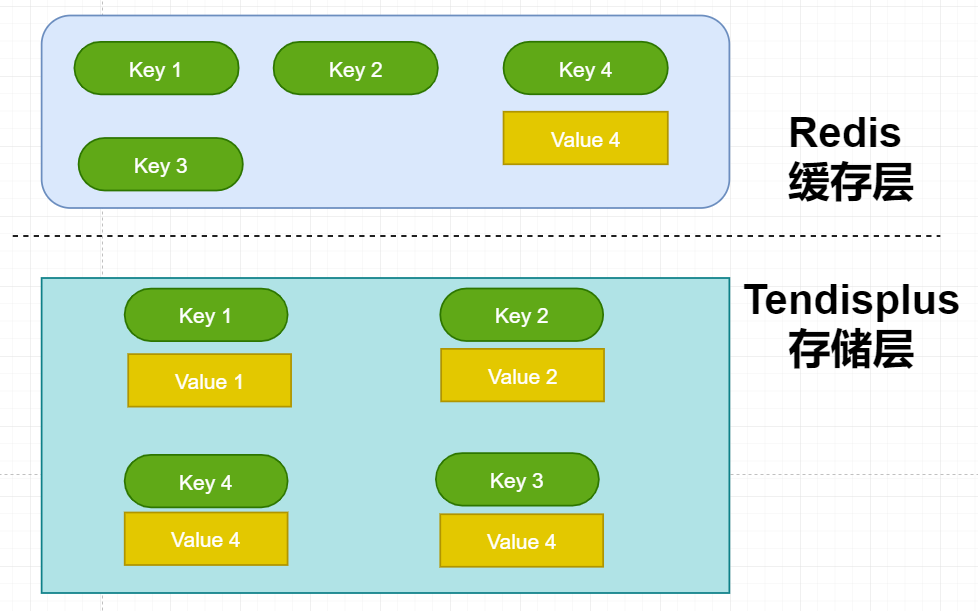
由IEG技术运营部/存储与计算资源中心 & 腾讯云数据库团队联合打造的 TendisX 冷热混合存储,缓存层使用 Redis 缓存全量的 Keys 和热 Values(All Keys + Hot values), 存储层使用 Tendisplus 存储全量的 Keys 和 Values(All Keys + All values)。TendisX 能自动将热数据加载到缓存,冷数据从缓存侧淘汰。
缓存层存储全量的 Keys 能够有效避免空查询,并且能更少的改动原生 Redis代码。随着项目上线运行,发现全量 keys 的内存开销越来越大, 因此需要将缓存层的 Key 淘汰,从而减少内存空间占用。
但是缓存层没有全量的 Keys,如何避免缓存击穿的问题?类似于 dbsize
,keys
,cluster getkeysinslot
需要 keys 的命令如何支持 ?
1.2 全量 Key 的内存开销
下图所示为单机模式下 value size : 256 字节 ;maxmemory : 4GB; 不同 key size 时,redis 和 TendisX(缓存层) 所能容纳的 set 请求数量。
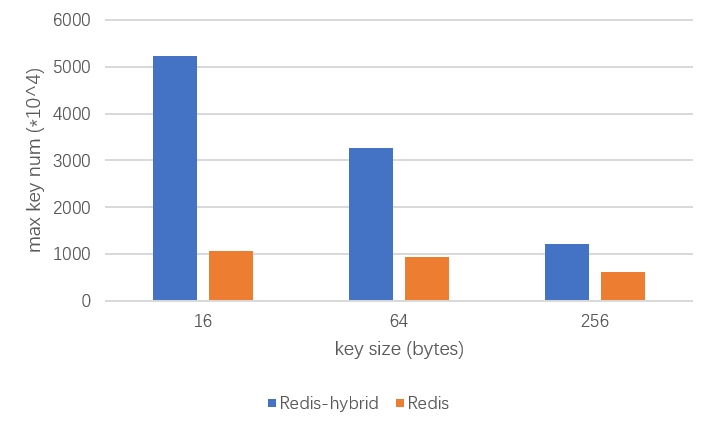
纵坐标表示在给定内存大小的情况下,写满 maxmemory 能写入的 key 的最大数目。
横坐标表示key size。
从图中可以看出 key size 为64 字节 , 对于 TendisX(缓存层),平均每个 key 占用131.3 字节。key size为256 字节,对于TendisX(缓存层) 平均每个 key 占用 352.38 字节。其中的内存开销主要来源以下部分:
全局 dict 的 dictEntry 保存 value 的 robj 全局 dictht table 的开销
另外集群模式下的 slots_to_keys (基数树保存 slot 中所有的 key)
由上的分析可以看出,在实际现网环境中平均每个 key 占用的内存大小高达几百字节,内存浪费严重。因此需要将缓存层(Redis) 的 key 淘汰到后端。
1.3 面临的挑战
Bloom filter 可以用于检索一个元素是否在一个集合中,被广泛用在存储系统中来减少不必要的访问。因此我们准备在 TendisX 中实现 Bloom filter
,用于避免不必要的后端访问。但是需要考虑以下问题:
缓存层(Redis) 如何避免缓存击穿 如果 key 不在后端存储层,访问该 key 的请求不应该转发给存储层? 元素删除 假如使用 Bloom filter
来判断 key 是否存在, 如何解决删除问题 ?空间占用与误判率间的权衡 Bloom filter
对内存空间的占用,以及分配的初始大小,误判率的大小 ?动态扩缩容 随着系统的运行,新增的 Key 不断增多, Bloom filter
能否根据当前系统的 Key 数量动态增长或者缩小 ?cluster 搬迁 缓存层(Redis) 搬迁时,如何在目标节点构造 Bloom filter
?Redis 命令兼容 缓存层没有全量的 Keys ,需要访问全部 Keys 的命令(比如 dbsize
,keys
,cluster getkeysinslot
等)如何支持?
2 Filter 调研及选型
根据前面的背景介绍我们需要一个支持删除、可扩展并且空间利用率高的 Filter。下面主要介绍我们调研的一些支持 Membership Query 的数据结构: Bloom filter, Quotient filter, Cuckoo filter 以及其变种。
2.1 Bloom Filter
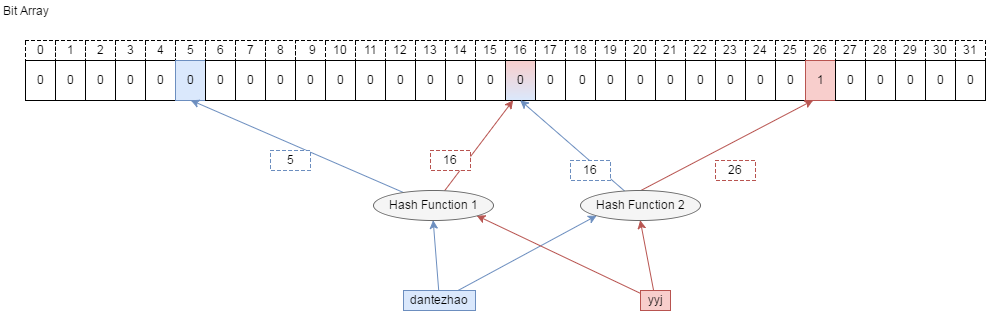
2.1.1 Standard Bloom Filter
Bloom Filter 使用 m bits 长度的位数组,并且初始化为 0。1) 当插入一个元素 x 时, 使用 k 个 hash 函数将 x 映射到位数组的 k 个位置,并且都置为 1。2) 查询元素 y 时,使用刚才的 k 个 hash 函数,如果映射的 k 个位置都为 1, 则 y 可能存在; 否则 y 一定不再。详细说明可以参考 Bloom filter wikipedia。Standard Bloom Filter
的原理如下所示:
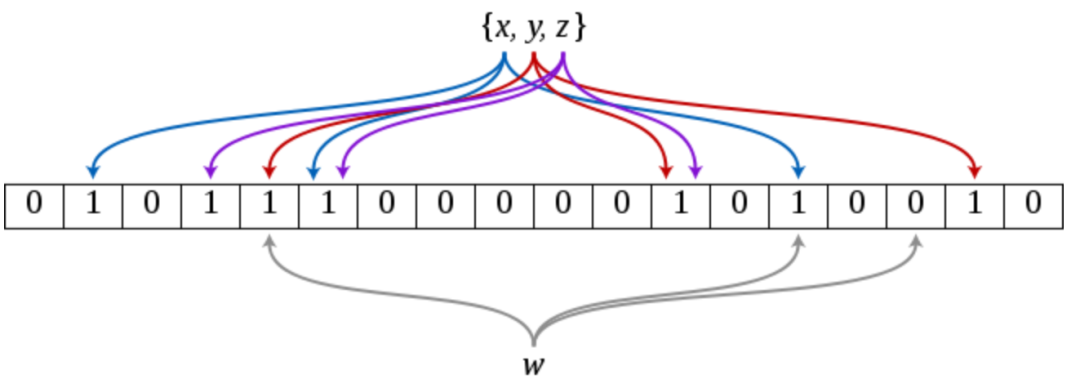
误判率(False Positives): Bloom filter 是一种概率的数据结构,当查询一个元素, filter 表示元素不在, 该元素肯定不会在集合中。如果 filter 表示存在,则该元素可能存在在集合,但是也有可能不存在,也是误判率。参考这篇文章 Bloom Filters - the math,可知误判率的大小主要与以下因素有关:1) m:位数组的总长度; 2) n:插入元素的个数; 3) k:哈希函数的个数
最优的 k 与 m 和 n 有以下关系:
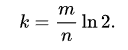
在真实应用中, 一般 n/m (即 bits per item) 为 10,平均每个 key 消耗 10 bits,误判率可以在 1% 以内。优点 :
节省空间和时间。 插入和查询是 O(k) 时间。
缺点:
不支持删除 不支持动态扩展,是静态数据结构。使用前根据插入的元素总数提前分配好空间。
2.1.2 Counting Bloom Filter
Standard Bloom filter 不支持删除元素。为了解决这个问题,Counting Bloom Filter 将 Standard Bloom Filter 位数组的每一位扩展为一个小的计数器(Counter)。在插入元素时将对应的 k (k 为哈希函数个数)个 Counter 的值分别加 1,删除元素时给对应的 k 个 Counter 的值分别减 1。这样就可以实现元素的删除,具体原理可以参考下面这篇文章 Counting Bloom Filter 的原理和实现。
优点:
Counter 计数, 解决了 Bloom Filter 不能删除的问题。
缺点:
Counter 增大了空间占用。在工程中常常将 Counter 设置为 4 bits,占用空间是 Bloom filter
的 4 倍。不支持动态扩展
2.1.3 Scalable Bloom Filter
Counting Bloom Filter
解决了 Standard Bloom Filter
不能删除元素的问题,但是仍然不能动态扩展,于是就出现了 Scalable Bloom Filter (可扩展的布隆过滤器)。Scalable Bloom Filter
支持动态扩展,用于解决插入的元素集合大规模增长问题。具体原理可以参考这篇文章 可扩展的布隆过滤器(Scalable Bloom Filter) 。
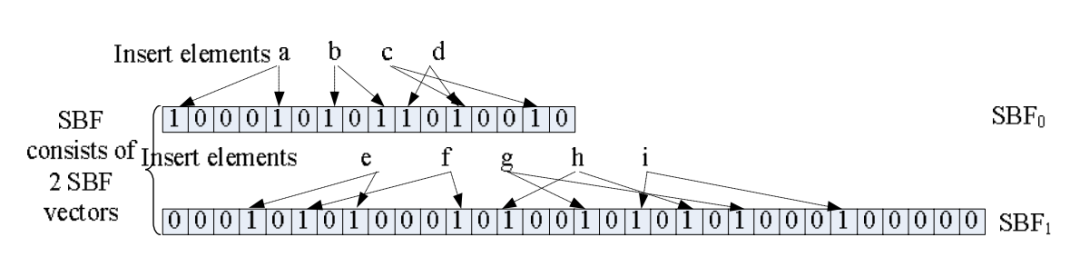
插入元素
初始化时会分配 SBF0 {n0,m,k}, 数据首先插入到 SBF0 中。 当插入的数据大于 n0 时,创建一个新的 SBF1, 并且容量是 SBF0 的两倍。 当插入的数据量大于 3*n0 时,创建一个更大的 SBF2,依次进行扩展以容纳增加的数据。 查询
查询时需要依次遍历 SBF0 ~ SBFn, 直到找到数据为止。
Scalable Bloom Filter 将多个 Bloom Filter 进行串联,来支持动态扩展。但是不能删除数据,扩展后的 SBF 不能删除旧数据。
但是依然没有解决删除的问题,可扩展的布隆过滤器(Scalable Bloom Filter) 中通过循环地清理最旧的单个布隆过滤器(Bloom Filter),即 bloomFilters 中下标最小的布隆过滤器,实现更新布隆过滤器中元素。但是这种只适合可以丢弃老数据的场景,在我们的系统中无法使用。
优点:
支持动态扩展。
缺点:
不能进行删除。如果要支持删除需要和 Counting Bloom Filter
结合一起使用, 实现复杂, 并且空间占用较大。无法进行缩容,随着数据增加, Scalable Bloom Filter
分配一个更大的 SBF,但是却不能将之前的 SBF 释放。
2.2 Quotient filter
2.2.1 Quotient filter 原理
Quotient filter (商过滤器 QF) 采用一个哈希函数,具有更高的查找效率。另外 Quotient filter 支持插入、删除和扩容,具体原理可以参考 Quotient_filter wikipedia。
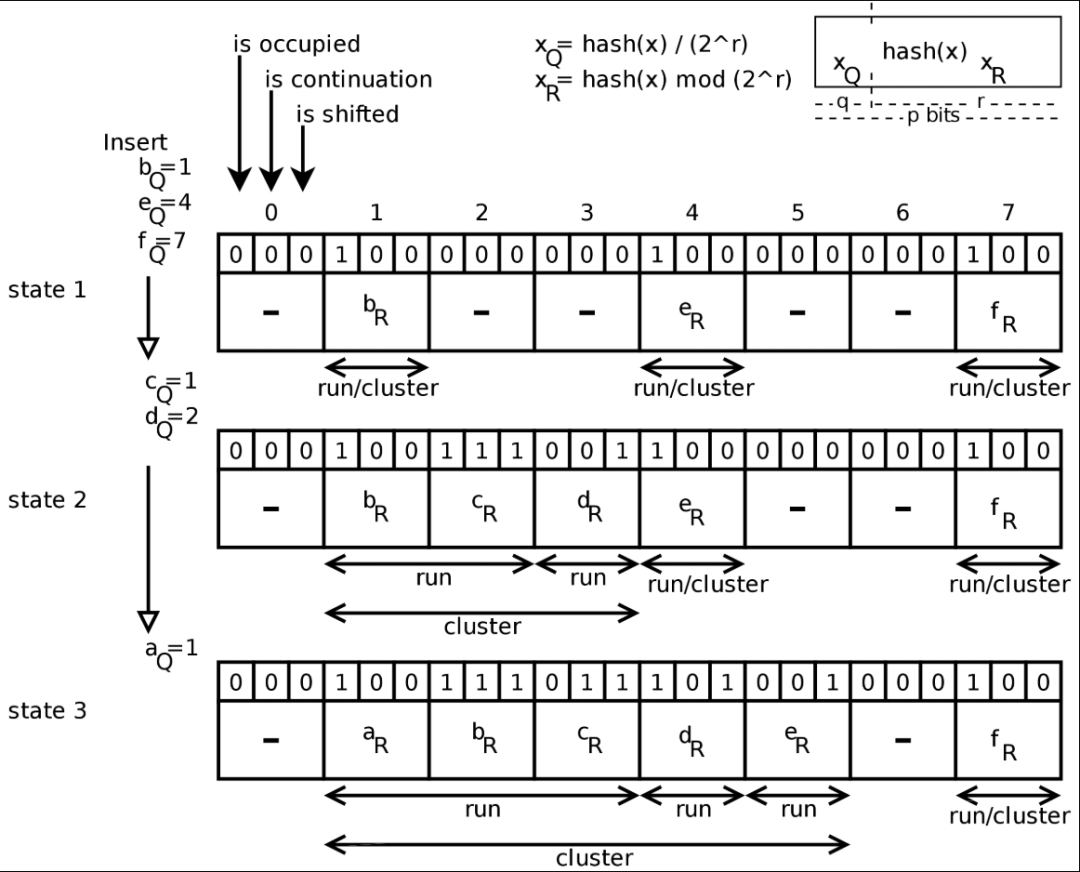
新元素插入
当插入一个键 x 时,首先经过一次哈希运算得到 hash(x),然后将 hash(x)/(2^r)作为商(XQ) ,hash(x)%(2^r) 作为余数(XR)。 商(XQ) 用来决定将元素放入到 Quotient filter 的具体的 slot 。 Quotient filter 将余数(XR) 存储到上面的 slot 。
元数据维护 随着数据的不断的插入, 有可能存在 slot 冲突 (被其他成员占用)。Quotient filter 为每个 slot 维护 3 bits 的元数据,分别表示:
is occupied : filter 中是否存在商(XQ)对应该 slot 的元素?is continuation : 不是放在自己本身的槽中,被迫后移,与前面的元素形成连续集群is shifted : 是不是放在与自己商号对应的槽中,如果不是,被迫后移动的,那么将该状态设置成1
优缺点:
空间占用 Quotient filter 空间占用略微比 Bloom Filter 多,但是比 Counting Bloom filter 少。
插入/查询效率 Quotient filter 由于一次 hash, 然后只会访问相邻的数据。所以比 Bloom Filter 更加 cache-line 友好,但是使用线性探测会降低插入性能。
合并 不同的 Quotient filter 可以像有序链表一样合并, 但是 Bloom Filter 需要相同的参数。
2.2.2 Quotient filter 变种
Rank-and-Select-based Quotient Filters
Rank-and-select based quotient filters (RSQF) 基于 Quotient filter 主要优化以下几点:
使用 2.125 bits 来维护元信息, 而不是 3 bits 在负载因子较高时,比 Quotient filter 查询效率更高。 RSQF 的元数据 将大多数的 Quotient filter 操作转换为位数组的 rank 和 select , 因此可以使用 x86 的位运算指令来进行优化。
首先与 Quotient filter 相同, RSQF 也将元素 x 进行一次 hash, 得到 hash(x), 然后定义 h0(x) 为商(与 XQ 表达意思相同), h0(x) 为余数(与XR 表达意思相同)。使用商 h0(x) 定位到具体的 slot 位置, slot 中存储余数 h1(x) 。
RSQF 将 QF 元数据中 3 bits 优化为 2bits, 如下图所示:
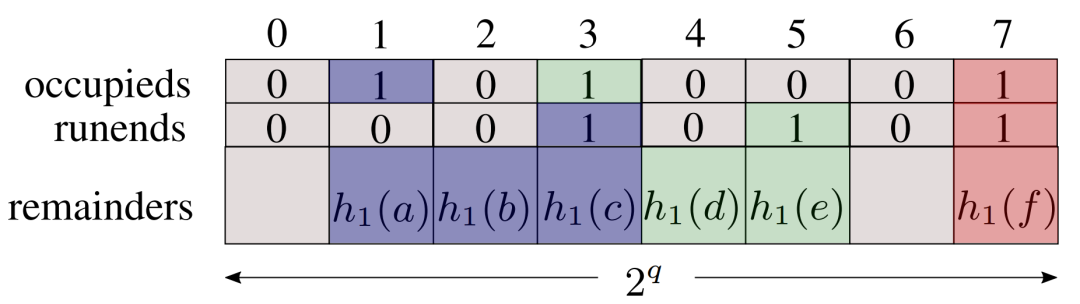
occupieds
维护一个 occupieds 位数组,来表示 filter 中是否存在元素 x 的商(h0(x)), 对应该 slot。如果 h0(x) 为 a, 则将 occupieds[a] 置为 1。 filter 中存储余数(h1(x))时,保证有序。即如果 h0(x) < h0(y) ,则 h1(x) < h1(y) 。 如果元素 x 放在了 filter[a] 中, 但是 h0(x) < a. 可以判断此时 filter 数组的 [h0(x), a] 都有元素占有。 runends上述的条件可以保证商相同的元素,都保存在连续的位置,论文中称作一个 Run。用 runends 位数组来标记是否为 一个 Run 的终止位置。
Counting Quotient Filter
在 RSQF 的基础上实现计数功能, 并且将 Counter 与余数编码到一起。
更深入的了解 Quotient filter 或者 RSQF 可以参考下面的博客或者论文:
A General-Purpose Counting Filter: Counting Quotient Filter (CQF)Counting Quotient Filter take over? A general purpose counting filter: making every bit count
2.3 Cuckoo filter
Cuckoo filter 基于 cuckoo hash 实现,不同的是 cuckoo hash 每个 bucket 存储具体的元素, Cuckoo filter 存储元素的 fingerprint 。为了介绍 Cuckoo filter,我们首先了解一下 cuckoo hash 的原理。
2.3.1 Cuckoo hash
cuckoo hash 是一种解决 hash 冲突的方法,其目的是使用简单的 hash 函数来提高 hash table 的利用率,同时保证 O(1) 的查询时间。
cuckoo hash 主要具有以下特点:
它的哈希函数是成对的(具体的实现可以根据需求设计),每一个元素都是两个哈希函数,分别映射到两个位置,一个是记录的位置,另一个是备用位置。这个备用位置是处理碰撞时用的。 cuckoo hash 处理碰撞的方法,主要把原来占用位置的这个元素踢走; 被踢出去的元素插入到它的备用位置。如果备用位置上还有人,再把它踢走,如此往复。直到被踢的次数达到一个上限,才确认哈希表已满,并执行 rehash 操作。
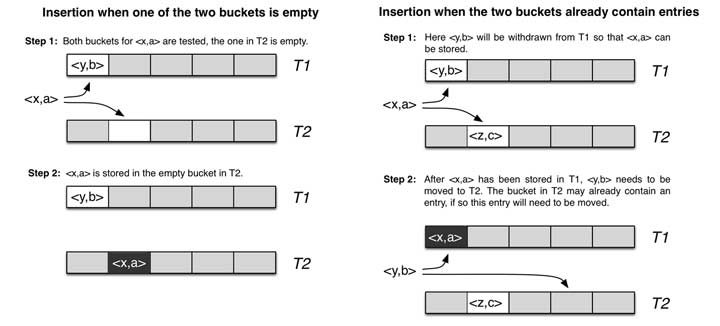
详细原理可以参考这篇博客 CUCKOO FILTER:设计与实现。
2.3.2 Cuckoo filter
Cuckoo filter 与 Cuckoo hash 主要有以下不同:
存储 fingerprint (指纹), 而不是具体的元素 Cuckoo filter 中存储元素的 fingerprint, 而不是具体的 kv,节省空间。但是这样会存在一定的误判率,后面会具体讨论。
partial-key cuckoo hashing cuckoo hash 使用 2 个 hash 函数得到 2 个 bucket 的位置,但是 cuckoo filter 中首先利用 hash 函数得到 bucket1, 然后利用下面公式得到 bucket2 的位置。
bucket2 = bucket1 ⊕ hash(fingerprint)
这样就可以利用异或 hash(fingerprint) 通过一个 bucket 的位置来获取另外一个 bucket 的位置。
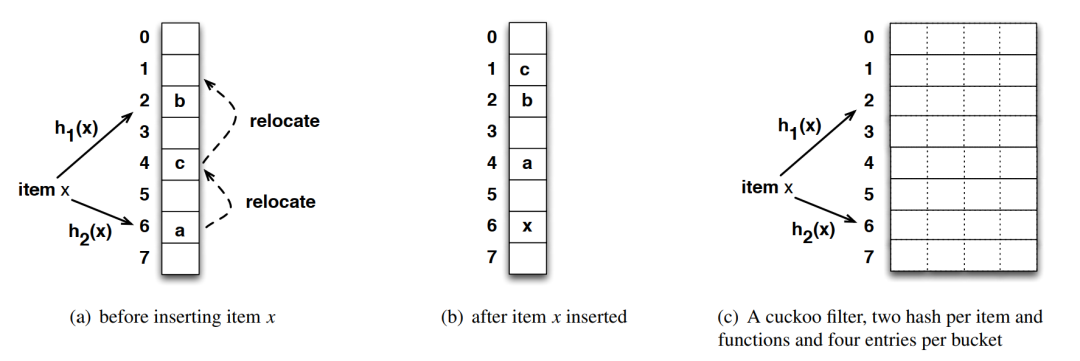
动态扩展的实现
Cuckoo filter 的扩容
每次插入先插入 cfn 。查看 bucket1 和 bucket2 是否有空余位置, 如果存在空余位置, 则插入到 cfn ; 否则插入到 cf[n-1], 依次查询直到 查询到空余位置为止。 如果从 cf[n] 到 cf[0] 的 bucket1 和 bucket2 位置都没有空余位置,则在 cf[n] 中进行踢出插入,尝试 maxIterations 次,直至插入成功。 如果插入失败,尝试扩容,生成一个更大的 cf[n+1]。 Cuckoo filter 的缩小因为 Cuckoo filter 支持删除,随着删除数据的增加, 上层 cf[0]... cf[n-1] 可能存在空余空间,因此这时候需要将下层 cf[n] 的元素插入到上层。如果 cf[n] 中没有元素,则可以将 cf[n] 的空间释放。这个过程可以称作 compact 。
compact 触发的条件:
delete 的时候触发 compact,如果 numDeletes(cuckoo filter 已删除的 key 数量) 超过 全部 key 数量的 10% , 并且系统中存在多个 filter。 显示执行 compact 命令。
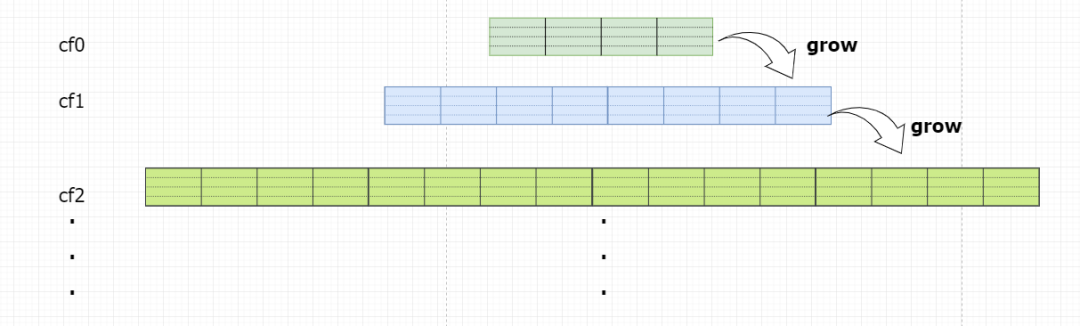
理论分析
符号说明: ε 表示目标误判率(false positive rate) f fingerprint 的长度 (bits) b 每个 bucket 可以容纳的元素数目 m 总的 bucket 的大小 n 总的插入元素数目 k hash 函数的个数
Space efficiencyC 表示 : 均摊的空间开销
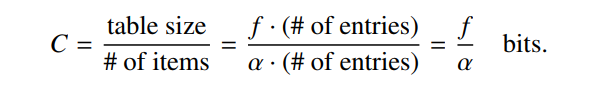
作者在最后实验中cuckoo filter 是 2^25 bucket 的成员, fingerprint 是 12 bit, bucket size
是 4, 最终空间 192 MB。插入数据将近 127.78 million。Bucket Size
增加 bucket size
可以提高空间利用率Larger buckets improve table occupancy (i.e., higher b ! higher α)
最优的 bucket size
(2,4)组合: 即 2 个hash 函数, 每个 bucket 4 个成员。论文中给出详细的图表以及实验结果, 可以参考这篇论文 Cuckoo Filter Practically Better Than Bloom 。当 ε > 0.2% 时, 每个 bucket 2 个成员比 4 个成员好(空间占用小)。当 0.001% < ε < 0.2%,bucket size
为 4 较好。false positive rate误判率与 fingerprint 大小和
bucket size
的关系如下:
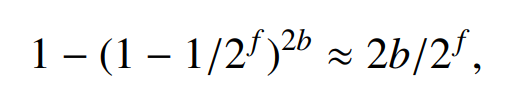
误判率越低 (即 ε 越小),要求 fingerprint 越大。
优点:
支持动态添加和删除数据。 比 Bloom filters 具有更好的查询性能。 在误判率小于 3% 的情况下,比 Bloom filters 更省空间。
约束/缺点:
同一个元素插入次数小于 kb + 1 次。如果超过 kb+1 次, cuckoo filter 会造成循环踢出相同的 key, 最后导致插入失败。 当 Cuckoo filter 层数过多时,会导致查询性能下降。
2.4 Filter 的对比总结
综合上述对 Bloom filter, Quotient filter, Cuckoo filter 以及其变种的分析,然后从中选择合适的 filter
方案。在选型的过程中主要考虑以下因素:
是否支持删除元素
是否支持
Bloom filter
动态扩展用户请求的 Key 数量是不确定的,
Bloom filter
需要根据 Key 数量进行扩大或者缩小。空间占用 && 误判率的权衡
需要权衡使用
Bloom filter
对内存空间的占用,在内存空间一定的情况下,尽可能降低误判率尽,或者支持插入更多的元素。插入/查询效率
支持记录已增加成员
支持
Bloom filter
已增加多少元素,以及对元素的计数。
最终经过分析,得到下面这张图:
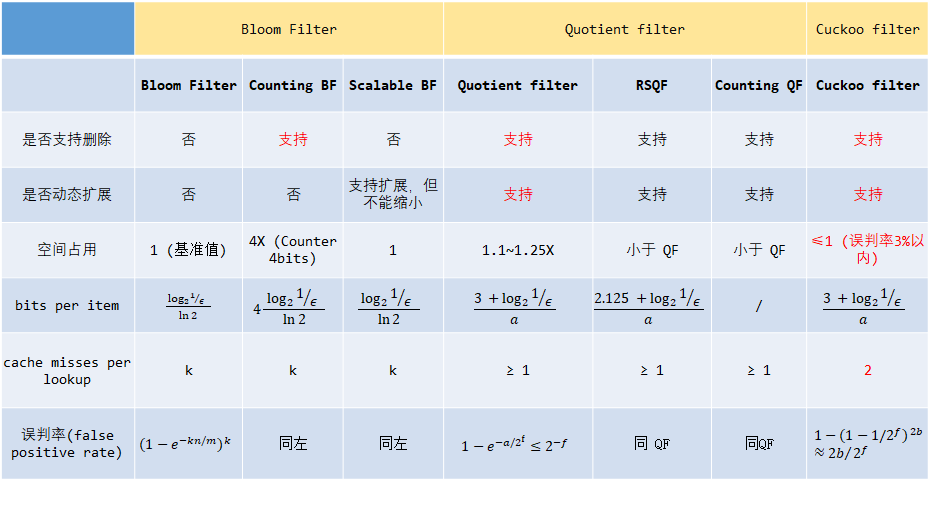
bit per item 平均每个 key 占的 bits 数据
其中 ε 表示目标误判率。α 表示 filter 的负载因子。
误判率
m:位数组的总长度; n:插入元素的个数; k:哈希函数的个数;f : fingerprint 大小。
3 系统设计
经过上面的对比, 最终选择 cuckoo filter 作为 filter 实现。另外为了解决背景中挑战如下设计:
主从复制
AOF master 将新增的 key 通过 aof 发送给 slave, slave 维护自己的 cuckoo filter。 RDB slave 第一次同步, master 将 cuckoo filter 序列化到 RDB, slave 根据接收的 RDB 更新 cuckoo filter。 Cluster 迁移
为了避免 Redis 层搬迁后目标节点重新生成 cuckoo filter, 我们的 cuckoo filter 以 slot 为单位, 每一个 slot 对应一个
cuckoo filter
。回档当缓存层(Redis) 故障, 由存储层构造
cuckoo filter
发送给缓存。命令兼容
dbsize
通过 cuckoo filter 计数, 总共 ADD 的次数。keys
,cluster getkeysinslot
,scan
等命令由后端存储层支持。
4 总结
本文主要为了解决 TendisX 冷热混合存储中, 缓存(Redis) 占用内存空间较多的问题。缓存层 All Keys + Hot values 方案更改为 Hot Keys + Hot values。为了解决缓存击穿的问题,调研并对比了常见 Filter : Bloom filter
, Quotient filter
和 Cuckoo filter
及其变种的优缺点,最后讲解 TendisX 为使用 Cuckoo filter
的将要做一些工作。
参考资料
可扩展的布隆过滤器(Scalable Bloom Filter) Information Processing Letters_2007_A Scalable Bloom Filter for Membership Queries Summary cache a scalable wide-area web cache sharing protocol -- Counting Bloom Filter Bloom Filter 知识汇总 Counting Bloom Filter 的原理和实现 Bloom Filter 系列改进之Counting Bloom Filter 这篇主要讲解了 Counting Bloom Filter, Spectral Bloom Filter 和 Dynamic Count Filter 。 Cuckoo Filter 比Bloom-filter更好的过滤器 Bloom filter or cuckoo hashing? stackoverflow 的帖子,详细对比了 cuckoo 和 bloom 的优缺点以及应用实践。 Cuckoo hash算法分析——其根本思想和bloom filter一致 增加hash函数来解决碰撞 节省了空间但代价是查找次数增加 Stream Processing and Probabilistic Methods: Data at Scale tylertreat BoomFilters GitHub Boom Filters 各种变种及其对应 go 实现
