




在绑定变量有数值无柱状图时的选择率计算,与绑定变量无具体数值的情况大致相同,不同之 处在于范围匹配时,会使用到字段统计数据中的最大、最小值。
表 6-2 谓词匹配选择率(考虑绑定变量值)

其中,
o BVAL 为绑定变量数值,BVAL[h]为 BETWEEN AND 中的最大值,BVAL[l]为 BETWEEN AND
中的最小值;
o HIGHVAL 为字段统计数据中的最大值,LOWVAL 为字段统计数据中的最小值;
6.4.4 使用柱状图
在使用柱状图数据时,选择率的计算更为复杂一些。使用柱状图数据时,匹配数值可以定位到 某一个分组,然后再根据其分组的数据进行计算。按照我们前面给出的结束点值(Endpoint Value) 的计算方法,可以找到数值所在的分组,例如,对于 T_OBJECTS.object_name = ‘DBA_TABLES’,
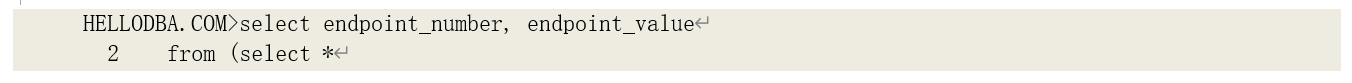

我们可以得到其所在分组的结束点数为 121。
由于结束点值(Endpoint Value)和结束点数(Endpoint Number)在不同类型柱状图中有不同含义,因此,选择率的计算也根据柱状图类型不同而不同。
频率柱状图
在频率柱状图中,结束点值为分组所对应的唯一值数,结束点数代表小于等于当期结束点值的数据记录数。
表 6-3 谓词匹配选择率(使用频率柱状图)
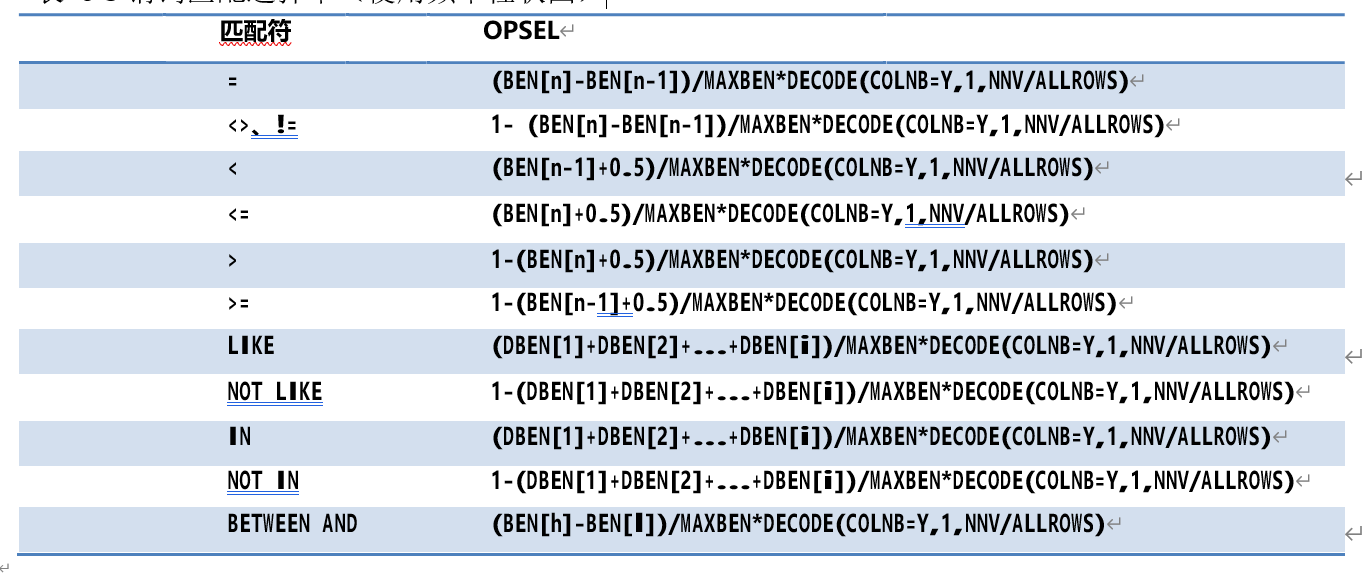
其中,
o BKTNUM 为柱状图的分组数;
o BEN[n](Bucket Endpoint Number)为数值所在分组的结束点数,BEN[n-1]为前一分组的结束点数,如果不存在,则为 0;
o 对于 IN、NOT IN,EQOPSEL[i]为 IN 中各个数值在等于(=)匹配时计算得到选择率数值;
o 对于=、<=、>=,如果匹配数值与某个分组的结束点值相同,则 BEN[n]为该分组,否则
BEN[n]为结束点值小于该值的最大分组。例如字段 A 的部分柱状图数据如下,当谓词条件为 A<=12355 时,BEN[n]为结束点数为 91 的分组;当谓词条件为 A<=12350 时,
BEN[n]为结束点数为 90 的分组。
表 6-5 高平衡柱状图示例

o LIKE 相当于一个 BETWEEN AND,BEN[h]为最大变量值落入的分组结束点数;BEN[l]为最小变量值落入的分组结束点数;
o 对于<、<=、>、>=,如果匹配变量数值落入“流行”数值分组内,则 POPADJ 为 0.5, 否则为 0;
o 对于<、>,以及<=、>=、BETWEEN AND、LIKE,如果匹配变量值没有命中结束点值时,
RANGEADJ 为(VAL-BEN[n-1])/(BEN[n]-BEN[n-1]),其中 VAL 为变量值,BEN[n]为变量值落入的分组的结束点数,BEN[n-1]为前一分组的结束点数;如果命中分组结束点,则
RANGEADJ 为 0.
o 对于 BETWEEN AND、LIKE,如果最大、最小匹配变量值都没有命中结束点值、且落入
同一个分组时时,RANGEADJ 为(HVAL-LVAL)/(BEN[h]-BEN[l]),其中 HVAL 为最大变量值、
LVAL 为最小变量值。
以 T_HISTHEADS.obj# = 69879 为例:


数值 69879 占据 3 个分组,为“流行”数值,因此 T_HISTHEADS.obj# = 69879 的选择率为
3/254=0.011811024。
提示:当谓词条件中的字段表达式(例如 TO_CHAR(ojbect_id) = ‘10001’)不存在统计数据时,则使用无统计数据时的计算公式。在 11g 中,可以为字段表达式建立扩展统计数据,从而使得优化器能考虑到字段表达式的影响,提供估算的准确性。
6.4.5 过滤条件的组合
当谓词条件中存在对多个过滤组合时,则会通过公式计算出组合选择率。以下为两个过滤条件 和单个条件取反的选择率计算公式:
表 6-6 过滤条件组合选择率

其中,OPSEL[a]为 A 过滤条件计算得出的选择率;OPSEL[b]为 B 过滤条件计算得出的选择率。
注意,对于单个字段的多过滤条件组合,则会按照兼容个过滤条件计算公式进行计算。例如, 对于 COL >= V1 AND COL < V2(V1<V2),则按照 COL BETWEEN V1 AND V2 的计算公式进行计算;对于 COL = V1 OR COL = V2(V1≠V2),则按照 COL IN (V1, V2) 的计算公式进行计算。
以两个组合条件的计算公式为基础,按照小括号强制的优先顺序以及匹配操作符的默认优先顺序,就可以得出多个组合条件的选择率计算公式。例如,对于 A OR B OR C,可以按照((A OR B) OR C) 的先后顺序进行计算:
EXPOPSEL[a or b or c] = EXPOPSEL[(a or b) or c]
= EXPOPSEL[a or b] + OPSEL[c] – EXPOPSEL[a or b]OPSEL[c]
= OPSEL[a] + OPSEL[b] – OPSEL[a]OPSEL[b] + OPSEL[c] – (OPSEL[a] + OPSEL[b] – OPSEL[a]OPSEL[b])OPSEL[c]
= OPSEL[a] + OPSEL[b] + OPSEL[c] – OPSEL[a]*OPSEL[b] – OPSEL[a]*OPSEL[c] - OPSEL[b]*OPSEL[c] + OPSEL[a]*OPSEL[b]*OPSEL[c]
值得注意的是,优化器在逻辑优化阶段会对语句进行查询转换,包括对谓词条件的转换(参见前面章节),因此,在计算选择率时所采用的谓词条件并不一定语句中的原始条件,而是转换后的条件,可以通过执行计划的谓词条件信息部分看到。
提示:在 11g 中,可以为多个字段组合创建扩展统计数据。如果谓词条件中的字段组合与扩展统计
数据中的字段组合相匹配,则会利用扩展统计数据进行计算。
