点击上方 "程序员小乐"关注, 星标或置顶一起成长
每天凌晨00点00分, 第一时间与你相约
每日英文
There are times that it is better to let things happen,rather than insisting on how you want them to be done.
有时候,最好让事情顺其自然,而不是坚持按你的想法去做。
每日掏心话
请记住,别在生气的时候做决定,别在开心的时候说承诺。
责编:乐乐
链接:jianshu.com/p/18b4bfde8c6c
往日回顾:如何让你的Nginx 提升10倍性能?
正文
什么是索引? 索引的实现方式 innodb的索引模型
什么是索引?
当我们使用汉语字典查找某个字时,我们会先通过拼音目录查到那个字所在的页码,然后直接翻到字典的那一页,找到我们要查的字,通过拼音目录查找比我们拿起字典从头一页一页翻找要快的多,数据库索引也一样,索引就像书的目录,通过索引能极大提高数据查询的效率。
索引的实现方式
在数据库中,常见的索引实现方式有哈希表、有序数组、搜索树
哈希表哈希表是通过键值对(key-value)存储数据的索引实现方式,可以将哈希表想象成是一个数组,将索引通过哈希函数计算得到该行数据在数组中的位置,然后将数据存到数组中,容易发现一个问题,如果两个索引通过哈希函数计算后得到的数组位置相同要怎么办?在这里,数组的每个value都是一个链表,链表上的每个元素都是一个数据,新数据直接添加到链表尾部。
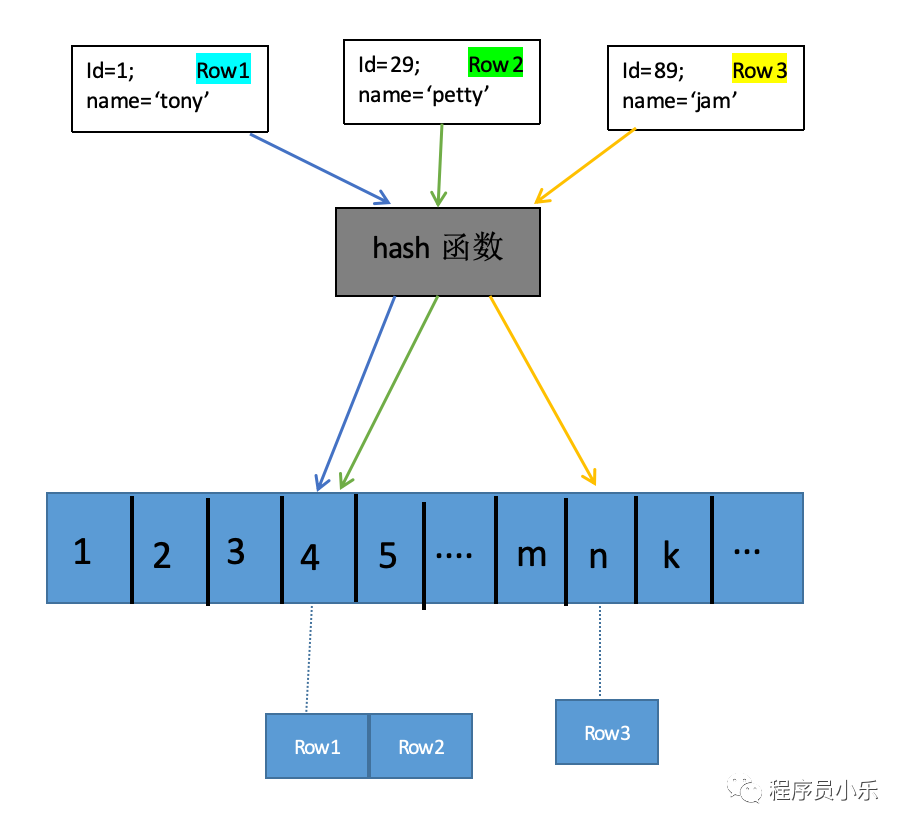
哈希表.png 所以数据库查询过程为:索引通过哈希函数计算数据所在位置--> 遍历指定位置的链表,找到满足条件的数据。
搜索公众号程序员小乐回复关键字“Java”获取Java面试题和答案。
要注意的是,链表上的数据元素不是有序的,每次有新数据加入时,新数据时直接添加到链表尾部,这样做的好处是添加数据时很方便。
哈希表不擅长进行区间查询,一般都用于等值查询
1、两个相邻索引通过hash函数后计算得到的数组位置不一定还保持相邻
2、链表上的数据是无序的
有序数组顾名思义,有序数组是按索引大小将数据保存在一个数组上,因为该数组是有序的,可以通过二分法很容易查到位置,找到第一个位置后,通过向左/向右遍历很容易得到所求区间的数据。因此,无论是等值查询还是区间查询,效率都极高。但缺陷也是显而易见的,当向数组中间n位置插入一条数据时,需将n后面的数据全部往后移动,所以,这种索引一般用于静态存储引擎。
搜索树
“二叉搜索树:一棵空树,或者是具有下列性质的二叉树:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;二叉搜索树的左、右子树也分别为二叉搜索树。平衡二叉树:平衡二叉树是在二叉搜索树的基础上引入的,指的是结点的左子树和右子树的深度差不超过1. 多叉树:每个结点可以有多个子结点,子节点的大小从左到右依次递增。
当使用平衡二叉实现索引时,结构如下图
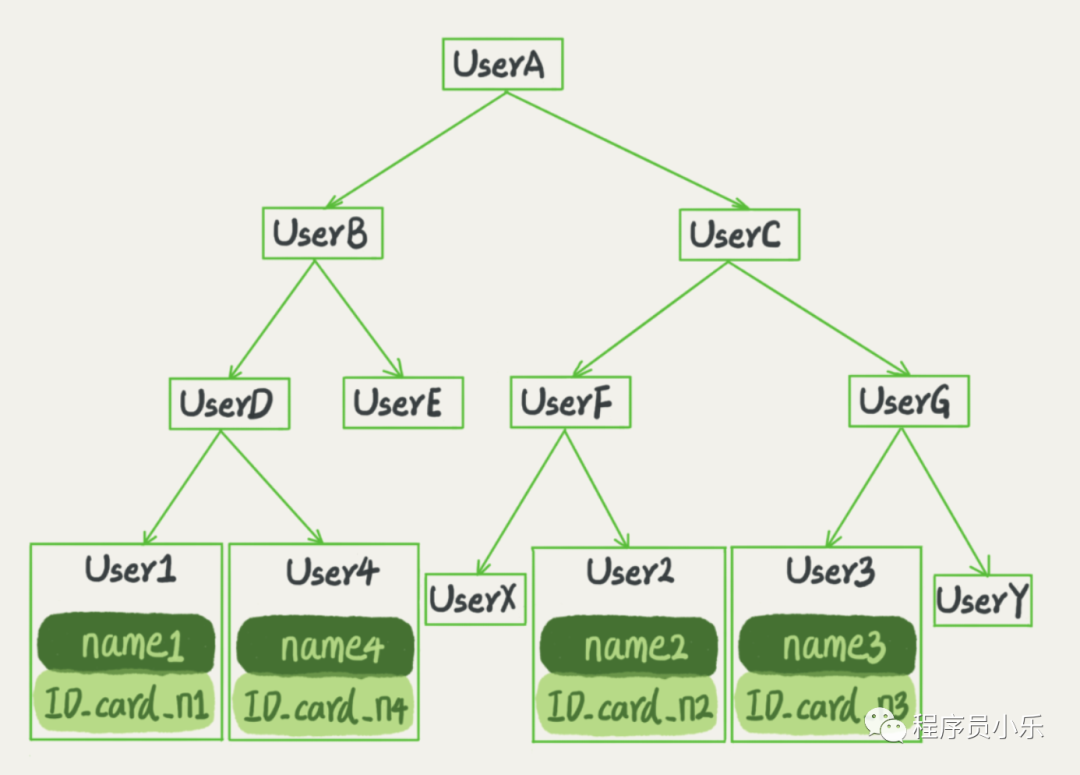
从图中可发现,每次查询最多需要访问4个节点必能得到所要数据。例如查询user2时,查询过程为:userA-->userC-->userF-->user2。所以查询速度很高,同时,因为搜索树的特性(左子树小于右子树),区间查询也很方便。
如果搜索树存于内存中,与多叉树相比,二叉树的搜索速率是最高的,但实际上数据库使用的是n叉树而不是二叉树。
“1、索引不仅存于内存,还是写到磁盘上 2、搜索树上的每个结点在磁盘上表现为一个数据块 3、多叉树每个结点下可以有多个子节点,所以存储相同数据量时多叉树的树高比二叉树小,查询一个数据需要访问的结点数更少,即查询过程访问更少的数据块。查询速度较高。
innodb的索引模型
innodb使用B+树作为索引结构。在B+树中,我们将节点分为叶子结点和非叶子结点,非叶子结点上保存的是索引,而且一个节点可以保存多个索引;数据全部存于叶子结点上,根据叶子结点的内容不同,innodb索引分为主键索引和非主键索引。非主键索引也称为二级索引。主键索引的叶子结点中保存的数据为整行数据,而非主键索引叶子节点保存的是主键的值。
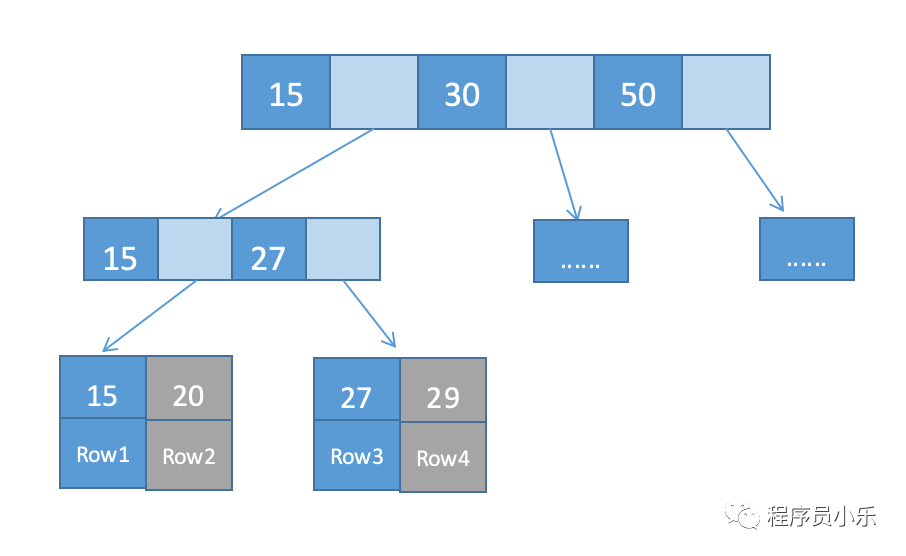
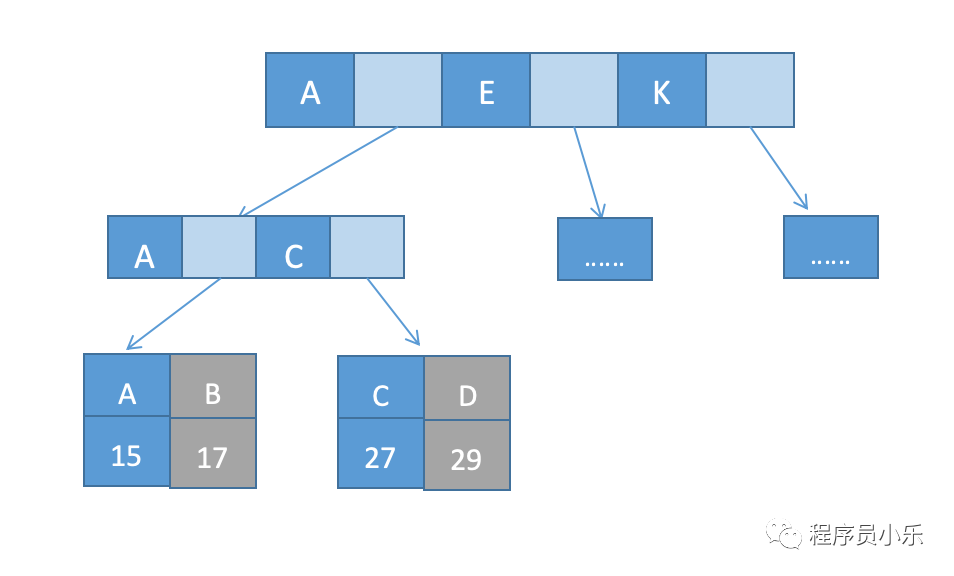
通过主键索引查询数据时,我们只需查找主键索引树便可以获取数据;通过非主键索引查询数据时,我们先通过非主键索引树查找到主键值,然后再在主键索引树搜索一次,这个过程称为回表,也就是说非主键索引查询会比主键查询多搜索一棵树。所以我们应尽可能使用主键查询。
索引维护
添加新行时,将会在索引表上添加一条记录,如果是索引递增插入时,数据都是追加在当前最大索引之后,不会对树中其他数据造成影响;如果新加入的数据的索引值位于节点的中间,需要挪动部分节点的位置,从而保持索引树的有序性。而且,相邻多个节点是存储在同一个数据页上的,此时,如果是在已经存储满状态的数据页中插入节点,会申请新的数据页,将部分数据挪动到新的数据页,这个过程称为页分裂,页分裂除了会影响性能,还会降低磁盘空间利用率。不规则数据插入时,会造成频繁的页分裂。
“当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并
所以,一般情况下会采用递增主键,使新数据递增插入。
使用业务逻辑字段做主键有什么优缺点?
“1、业务逻辑字段不容易保证索引树结点有序插入,这样写入成本较高。2、innodb默认使用整数类型作为主键,主键长度较小,二级索引的叶子结点中保存的是主键值,主键长度越小,二级索引的叶子结点占用空间也就越小。3、当然,使用业务逻辑字段做主键也有好处,可以避免回表,每次只需扫描一次主键索引树即可 综上,从性能和存储空间方面考量,自增主键往往是更合理的选择,当业务场景有且只有一个索引,而且该索引为唯一索引时,此时更适合使用业务逻辑字段作为主键。
因为数据修改/删除、页分裂等原因,会导致数据页空间利用率降低,此时,可以考虑重建索引,将数据按顺序插入,提高磁盘空间利用率。但重建主键索引和普通索引会有不同影响,重建普通索引,可以达到提高空间利用率的目的,且不会对其他索引造成影响,但如果重建主键索引就不合理了,会影响所有普通索引,性能影响较大,而且无论是新建/删除主键,都会重建整张表。这时我们可以使用alter table T engine=InnoDB这个语句代替。
查看索引利用率
“查看performance_schema.table_io_waits_summary_by_index_usage表
欢迎在留言区留下你的观点,一起讨论提高。如果今天的文章让你有新的启发,欢迎转发分享给更多人。欢迎加入程序员小乐技术交流群,在后台回复“加群”或者“学习”即可。
猜你还想看
面试官问我:介绍一下 MyBatis 事务?我竟然回答不上来...
API 接口设计之 token、timestamp、sign 具体架构与实现

关注订阅号「程序员小乐」,收看更多精彩内容