




前言
之前和TiCDC初遇,感觉挺好,特别是整个CDC运行过程中的“可观测性”太棒了。
capture 和 task 和 processor
在上一期中,我们介绍了changeFeed
,通过cdc cli命令进行创建的同步任务。其中同步任务里面又包含了多个task
,这个task
是什么含义,我们来继续了解一下。
tiup ctl:v5.3.0 cdc changefeed query --pd=http://172.16.7.185:2379 --changefeed-id=replication-task-1
"task-status": [
{
"capture-id": "7717c215-ce39-4579-83ee-86737ca218f6",
"status": {
"tables": {
"71": {
"start-ts": 430820688950722570,
"mark-table-id": 0
}
},
"operation": {},
"admin-job-type": 0
}
},
{
"capture-id": "a412cdf6-a094-486d-b51d-9f2f70ddfdb6",
"status": {
"tables": {
"79": {
"start-ts": 430820688950722570,
"mark-table-id": 0
}
},
"operation": {},
"admin-job-type": 0
}
}
]
使用changeFeed query
命令输出详细信息的时候,有个task-status
,可以看到上面显示有2个不同的capture-id
。因为我们有2个cdc节点,所以这里也就有2个capture
。capture
的作用就是执行task
任务。每个task
任务下,都会执行不同的表。例如上面的capture
它的task
对应的表的id是71,而下面这个capture
的task对应的表是79。通过查询tables表可以查到table_schema和table_name。
mysql> select TABLE_SCHEMA,TABLE_NAME,TIDB_TABLE_ID from tables where TIDB_TABLE_ID=71;
+--------------+------------+---------------+
| TABLE_SCHEMA | TABLE_NAME | TIDB_TABLE_ID |
+--------------+------------+---------------+
| test1 | t1 | 71 |
+--------------+------------+---------------+
1 row in set (0.01 sec)
mysql> select TABLE_SCHEMA,TABLE_NAME,TIDB_TABLE_ID from tables where TIDB_TABLE_ID=79;
+--------------+------------+---------------+
| TABLE_SCHEMA | TABLE_NAME | TIDB_TABLE_ID |
+--------------+------------+---------------+
| test1 | t2 | 79 |
+--------------+------------+---------------+
1 row in set (0.01 sec)
上面的task处理的是test1.t1,下面的task处理的是test.t2。
我们再创建一张表t3。
mysql> create table t3(id int,name varchar(20), primary key(id));
Query OK, 0 rows affected (0.13 sec)
再次查看task
"task-status": [
{
"capture-id": "a412cdf6-a094-486d-b51d-9f2f70ddfdb6",
"status": {
"tables": {
"79": {
"start-ts": 430820688950722570,
"mark-table-id": 0
},
"81": {
"start-ts": 430823739100758026,
"mark-table-id": 0
}
},
"operation": {},
"admin-job-type": 0
}
},
{
"capture-id": "7717c215-ce39-4579-83ee-86737ca218f6",
"status": {
"tables": {
"71": {
"start-ts": 430820688950722570,
"mark-table-id": 0
}
},
"operation": {},
"admin-job-type": 0
}
}
]
此时可以看到,其中一个capture
的下面,增加了一个table为81的任务。
再说一下Processor
,在官方文档中叫做子任务处理单元,它其实是负责具体执行task
的基本单元.
所以Task
,Capture
,Processor
的三者关系如下图:
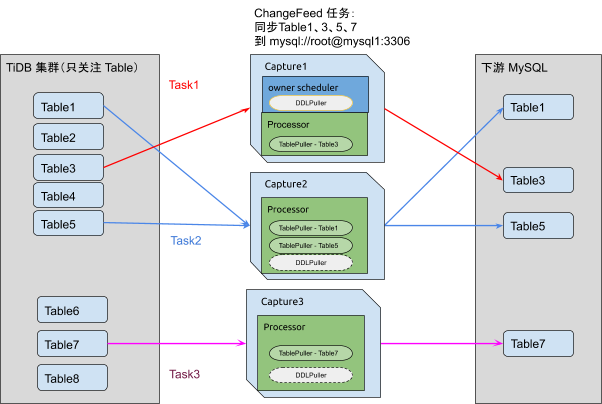
Capture
又可以划分为两种角色分别是Processor
和 Owner
。一个集群同一时刻只存在一个Owner
。一个Capture
可以同时兼具Owner
和Processor
角色。
这个架构图最上边的Capture1就是同时兼具了Owner
和Processor
的角色。cdc的ctl命令可以查看同步子任务处理单元Processor
。
查看processor列表
tiup ctl:v5.3.0 cdc processor list --pd=http://172.16.7.185:2379
Starting component `ctl`: /root/.tiup/components/ctl/v5.3.0/ctl cdc processor list --pd=http://172.16.7.185:2379
[
{
"changefeed-id": "replication-task-1",
"capture-id": "7717c215-ce39-4579-83ee-86737ca218f6"
},
{
"changefeed-id": "replication-task-1",
"capture-id": "a412cdf6-a094-486d-b51d-9f2f70ddfdb6"
}
]
我们有2个processor
,每个processor都有自己的capture-id
。
查询特定 processor
tiup ctl:v5.3.0 cdc processor query \
--pd=http://172.16.7.185:2379 \
--changefeed-id=replication-task-1 \
--capture-id=a412cdf6-a094-486d-b51d-9f2f70ddfdb6
Starting component `ctl`: /root/.tiup/components/ctl/v5.3.0/ctl cdc processor query --pd=http://172.16.7.185:2379 --changefeed-id=replication-task-1 --capture-id=a412cdf6-a094-486d-b51d-9f2f70ddfdb6
{
"status": {
"tables": {
"79": {
"start-ts": 430820688950722570,
"mark-table-id": 0
},
"81": {
"start-ts": 430823739100758026,
"mark-table-id": 0
}
},
"operation": {},
"admin-job-type": 0
},
"position": {
"checkpoint-ts": 430837431183605761,
"resolved-ts": 430837431445749762,
"count": 0,
"error": null
}
}
这里和我们上面查询的task信息基本一致。
status.tables
中每一个数字代表同步表的 id,对应 TiDB 中表的 tidb_table_id。mark-table-id
是用于环形复制时标记表的 id,对应于 TiDB 中标记表的 tidb_table_id。环形复制这个特性暂时为实验特性。resolved-ts
代表当前 processor 中已经排序数据的最大 TSO。checkpoint-ts
代表当前 processor 已经成功写入下游的事务的最大 TSO。
Owner 和 Processor
Owner
负责维护全局的同步状态,会对整个集群进行监控和适当的调度。owner 运行有以下逻辑
table
同步调度调度
table
的同步任务,分发到某个节点或从某个节点删除维护运行的
processor
状态信息,对于异常节点进行清理执行处理
DDL
,向下游同步DDL更新每一个
changefeed
的全局的CheckpointTs
和ResolvedTs
我们可以通过观察owner的cdc日志来确认它究竟做了什么?
创建一张表t5
mysql> create table t7(id int,name varchar(20), primary key(id));
Query OK, 0 rows affected (0.13 sec)
可以在owner节点的的cdc日志中看到以下信息。
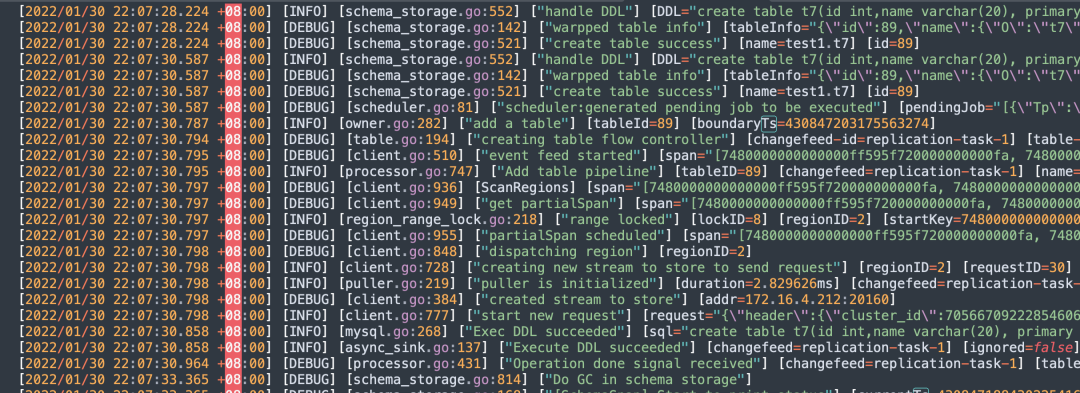
这里可以看到owner.go
,执行的动作add a table
,tableid为89。
然后scheduler.go
,会把这个表的任务调度到Capture
为4f501b0a-1d00-46e5-8fdf-aee5aa1ea9a3
上去。
[2022/01/30 22:07:30.587 +08:00] [DEBUG] [scheduler.go:81] ["scheduler:generated pending job to be executed"] [pendingJob="[{\"Tp\":\"ADD\",\"TableID\":89,\"BoundaryTs\":430847203175563274,\"TargetCapture\":\"4f501b0a-1d00-46e5-8fdf-aee5aa1ea9a3\"}]"]
而mysql.go,就是真正往下游执行语句的。可以看到它显示Exec DDL succeeded
。
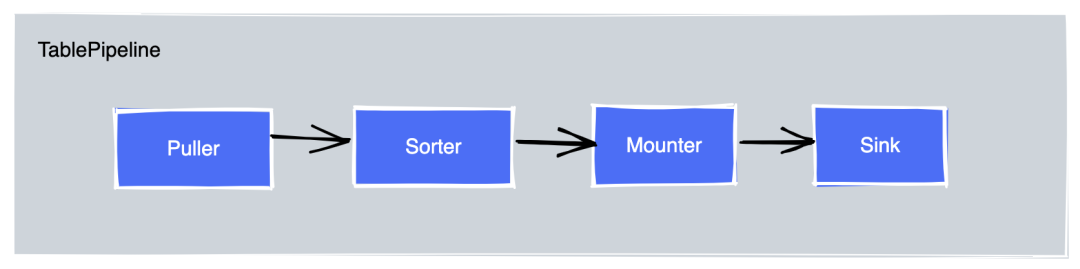
Processor
就是逻辑工作线程,一个capture
节点可以运行多个processor
。每个 processor
负责同步若干个表的数据变更。
而processor
有以下逻辑:
建立
EventFeed gRPC stream
拉取kv change eventprocessor
负责同步哪些表由owner
调度,表的调度信息储存在 etcd 中。processor
创建时会读取被分配了哪些表进行同步,将这些表的 table id 按照 TiDB 内部的 key 编码逻辑进行编码得到一些需要拉取kv change log
的key range
,processor
会综合key range
和region
分布信息创建多个EventFeed gRPC stream
。processor
运行过程中也会监控同步信息,对于增加或删除的表调整EventFeed gRPC stream
。维护本地
ResovledTs
和CheckpointTs根据全局
ResolvedTs
推进自己节点的数据向下游同步
后记
最后来看看可观测性。上次我们说了dataflow。
通过Granfra中的Dataflow可以观测到Puller、Sorter、Mounter、Sink的工作进度。
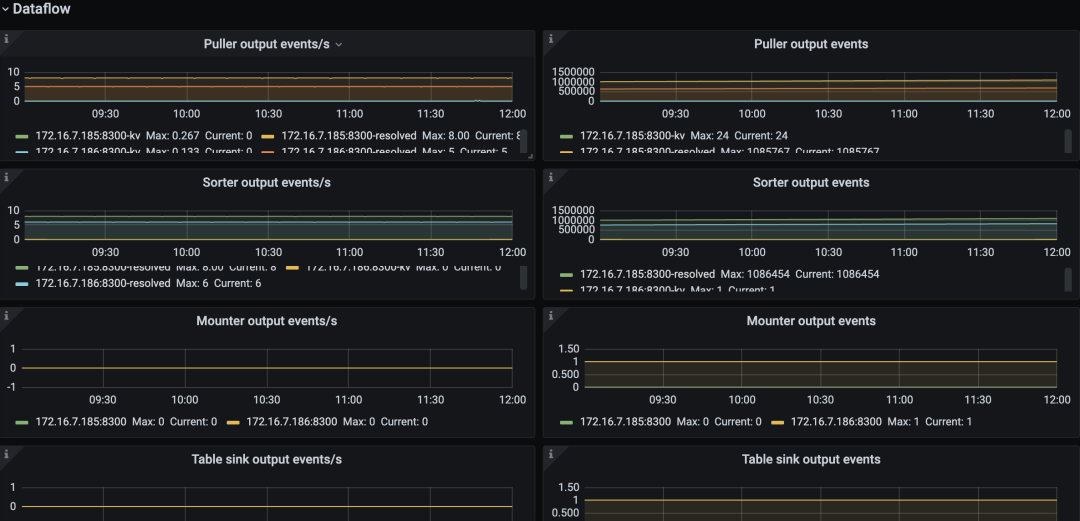
如果某个地方工作不是很理想,可以调整一些参数,比如mounter 线程数worker-num 。
reference
1.https://github.com/pingcap/tiflow/blob/master/docs/design/2020-03-04-ticdc-design-and-architecture-cn.md
