点击上方“IT那活儿”,关注后了解更多精彩内容!!!

故障背景


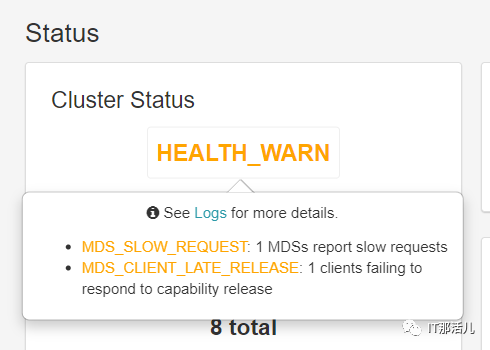
分析过程
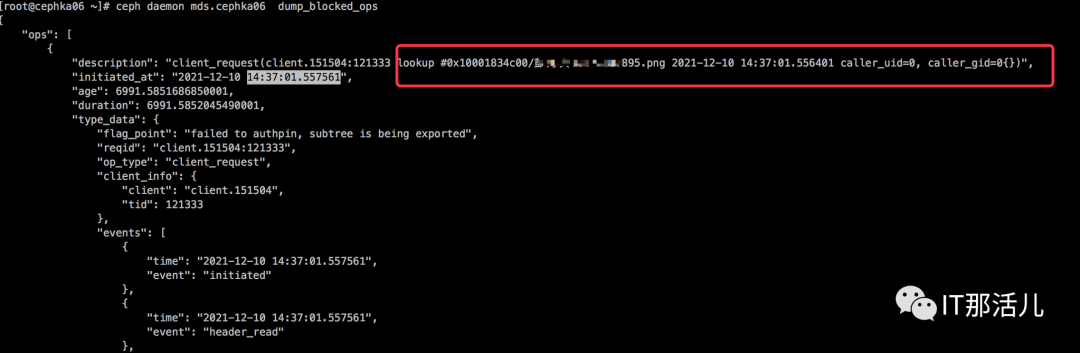
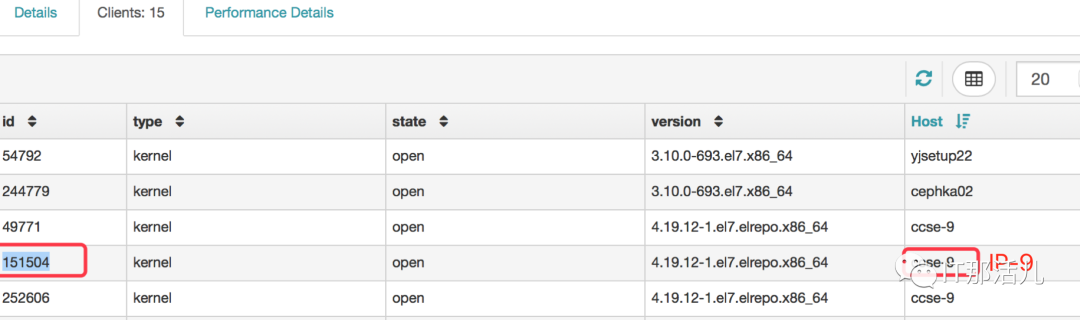
ceph tell mds.`hostname` client ls |grep -E "inst|num_caps|root”


业务恢复
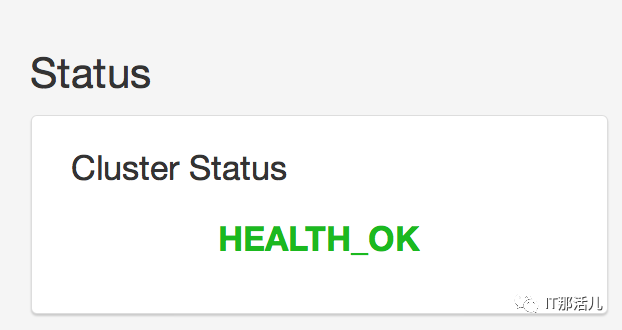
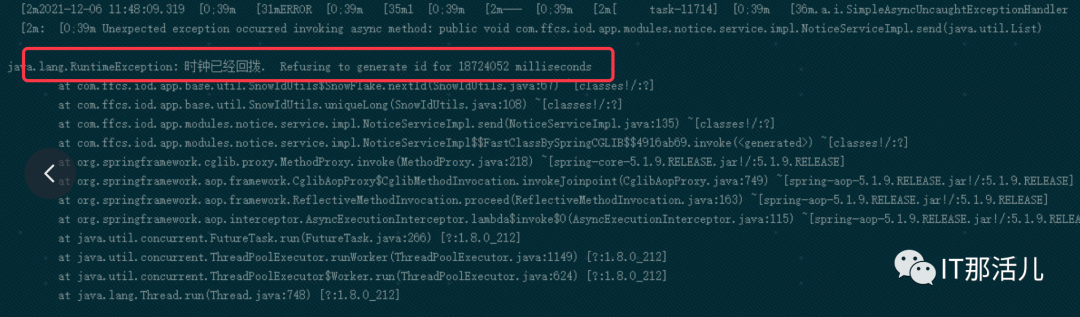
锁定“真凶”


问题复盘

本文作者:何青
本文来源:IT那活儿(上海新炬王翦团队)


分享

收藏

点赞

在看
文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





故障背景
分析过程
ceph tell mds.`hostname` client ls |grep -E "inst|num_caps|root”
业务恢复
锁定“真凶”
问题复盘
分享
收藏
点赞
在看
