




把SQL发给BI。
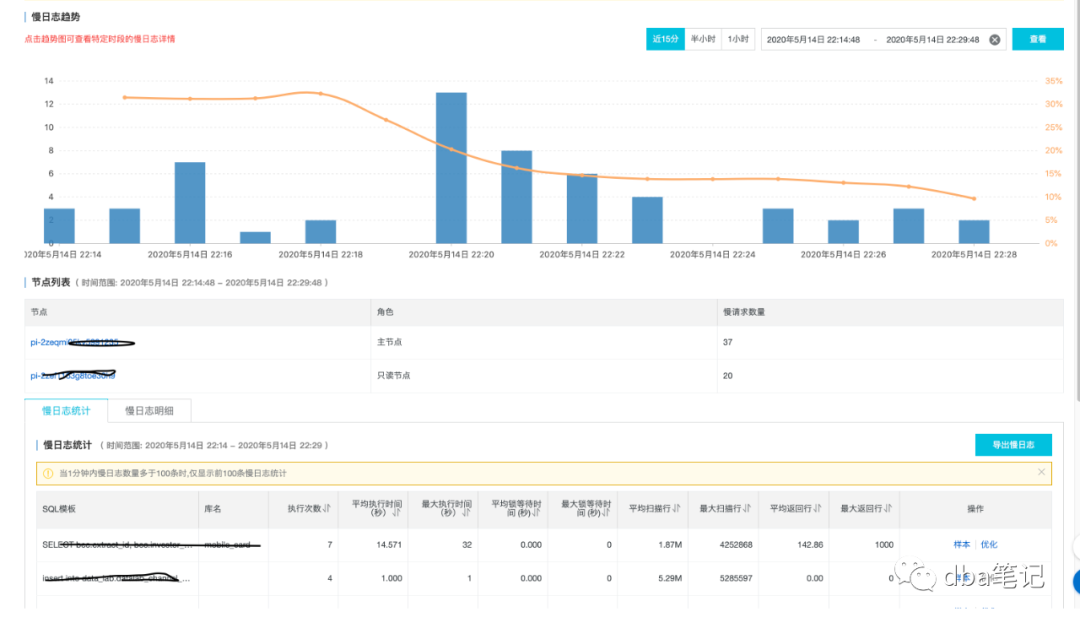
同事反馈,又没账号,又没IP,很多SQL没人认领。
优化几个Top SQL后,对整体帮助不大。
办法都是逼出来的。
阿里云接口取慢SQL数据,组装成SlowLog,pt-query-digest分析。
分析报告
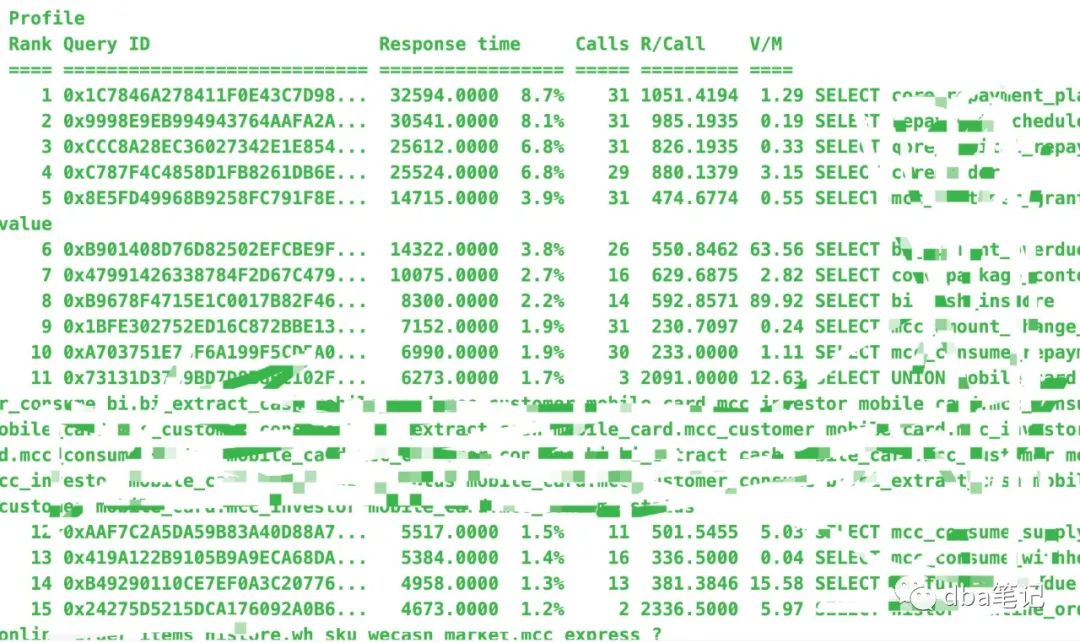
大量的SQL如下
select * from a where id > 1 and id < 10000;
根据账号和IP,定位到任务,全量同步2000+表到Hadoop。
每个表根据ID范围拆分成若干Select语句。
任务分批次在0点,1点,2点执行对应的批次。
数据分析师根据这些基础数据在大数据平台上做二次加工。
这任务没有IP账号就定位不到人,我很奇怪。
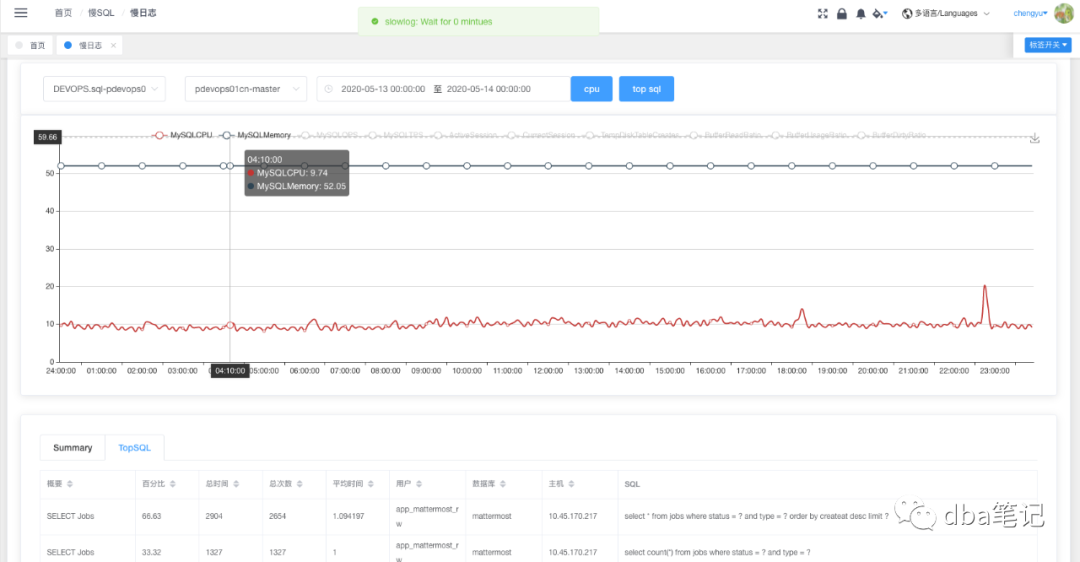
SQL优化没戏,好在从库负载高的时候,主库负载不高。
文章转载自dba笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
