PostgreSQL数据库优化一数据库配置调优
数据库配置调优
Configuration Files
使用可配置的WAL段大小
| 列名 | 数据类型 |
|---|---|
| max_data_alignment | integer |
| database_block_size | integer |
| blocks_per_segment | integer |
| wal_block_size | integer |
| btyes_per_wal_segment | integer |
| max_identifier_length | integer |
| max_index_columns | integer |
| max_toast_chunk_size | integer |
| large_object_chunk_size | integer |
| float4_pass_by_value | boolean |
| float8_pass_by_value | boolean |
| data_page_checksum_version | integer |
/opt/pgsql13.2/bin/initdb --pgdata=/home/postgres/pgsql/data \ --waldir=/home/postgres/pgsql/wal \ --wal-segsize=64 \ --encoding=UTF8 \ --allow-group-access \ --data-checksums \ --username=postgres \ --pwprompt
当运行着一个写密集型工作负载的系统,才会看到效果,这样改变WAL段大小才有价值。
了解配置参数等级
- portgresql.conf(global)
- postgresql.auto.conf(alter system)
- command line options(-o options)
- all role(all role applicable)
- database(per-database applicable)
- role(per-role applicable)
- session(per session with set applicable)
- transaction(per function with set local)
| 参数设置级别 | 存储位置 |
|---|---|
| cluster | postgresql.conf、postgresql.auto.conf |
| db | pg_db_role_setting |
| role | pg_db_role_setting |
| db&role | pg_db_role_setting |
理解配置参数更改的上下文(Context)
| 参数context | 生效方式 |
|---|---|
| internal | 数据库内部规定参数,编译期间设置,重新编译才能生效或者通过initdb选项设置,运行期不能修改 |
| postmaster | 数据库服务端参数,数据库启动时确定,服务重启才能生效 |
| sighup | 数据库全局参数,修改无需重启服务,发送SIGHUP信号会使服务器立即重新加载生效 |
| backend | 与sighup类似,但不影响正在运行的会话,只在新会话中生效,连接建立后无法修改,内部使用,不推荐用户设置 |
| superuser-backend | 与backend类似,需要超级用户权限 |
| user | 会话级参数,单个用户可以在任意时间修改,立即生效,只影响当前会话 |
| superuser | 与user类似,需要超级用户权限 |
重新加载配置文件
-
重新加载配置参数
- pg_reload_conf函数
- pg_ctl reload命令
- kill -hup命令
-
检查配置参数
pg_settings视图
current_setting函数
show 命令
postgres=# select * from pg_settings where name='shared_buffers'; -[ RECORD 1 ]---+------------------------------------------------------------- name | shared_buffers setting | 16384 --初始启动时默认值的设置 unit | 8kB category | Resource Usage / Memory short_desc | Sets the number of shared memory buffers used by the server. extra_desc | context | postmaster vartype | integer source | configuration file min_val | 16 max_val | 1073741823 enumvals | boot_val | 1024 reset_val | 16384 --重新加载的设置 sourcefile | /home/postgres/pgsql/data/postgresql.conf sourceline | 122 pending_restart | f --t表示值的设置需要重启才能生效,f则相反 postgres=#
Configuration Tuning
Connections Related
- listen_addresses = ‘0.0.0.0’
- port = 5433
- unix_socket_directories = ‘$PGDATA’
- unix_socket_group = ‘dba’
- unix_socket_permissions = ‘0700’
- max_connections = 100
- idle_in_transaction_session_timeout = 5min
- idle_session_timeout --version 14
Memtory Related
shared_buffers
shared_buffers = 8GB ( RAM 1/4 )
共享缓存区的大小 PG:双缓冲
命中率查询:
postgres=# select blks_hit::float/(blks_read+blks_hit) as cache_hit_ratio
postgres-# from pg_stat_database
postgres-# where datname=current_database();
cache_hit_ratio
--------------------
0.9602566108590205
(1 row)
postgres=# explain (analyze ,buffers) select sum(sal) from emp;
QUERY PLAN
--------------------------------------------------------------------------------------------------------
Aggregate (cost=14.75..14.76 rows=1 width=32) (actual time=0.101..0.103 rows=1 loops=1)
Buffers: shared hit=1 --表明在共享内存中直接读到了一行
-> Seq Scan on emp (cost=0.00..13.80 rows=380 width=14) (actual time=0.014..0.018 rows=14 loops=1)
Buffers: shared hit=1
Planning:
Buffers: shared hit=8 read=1
Planning Time: 0.250 ms
Execution Time: 0.250 ms
(8 rows)
postgres=#
work_mem
work_mem=32MB ( RAM * 0.25 / max_connections )
指定在写入磁盘上的临时文件之前,ORDER BY 、DISTINCT 、JOIN和哈希表的内部操作将使用的内存量
如果有并发的M个进程,每个进程中有N个HASH操作,则需要分配的内存是 M * N * work_mem
一个连接将占用一个work_mem空间
maintenance_work_mem
maintenance_work_mem=2GB ( RAM * 0.15 / autovacuum_max_workers )
进行维护操作时需要的内存
如VACUUM 、CREATE INDEX 、ALTER TABLE ADD FOREIGN KEY 等操作需要的内存
wal_buffers
wal_buffers=16MB ( shared_buffers / 32 )
指定WAL日志缓存大小,默认值 -1
64KB <= wal_buffers <= WAL文件尺寸
Planner / Cost Related
random_page_cost
random_page_cost = 1.1 ~ 3 ( > seq_page_cost :1)
随即磁盘访问时,单个页面的读取开销,默认为 4.0
work_mem
work_mem=32MB ( RAM * 0.25 / max_connections )
effective_cache_seze
effective_cache_size = 24GB ( RAM 3/4 )
提供了可以用于磁盘缓存存储器的估计
WAL Related
wal_level
wal_level = replica ( minimal, replica, or logical )
决定多少信息写入WAL日志中。
pg 10 及以上版本默认是replica,pg 9.6及之前版本默认值是minimal;
9.6以前:
archive:增加wal归档所需的日志(最常用);
hot_standby:在备用服务器上增加了运行只读查询所需的信息(流复制使用)。
9.6以后:
minimal:值写入数据库崩溃或突然关机后,进行恢复所需要的信息; (如果使用minimal,需要把max_wal_senders设置为0)
replica:增加wal归档信息同时包括只读服务器需要的信息;
logical:支持逻辑解码,用于逻辑复制时,需要配合为logical。
archive_mode
archive_mode = on (off, on, always)
on:在主库归档
always:可以在从库归档
当wal_level设置为minimal时,无法设置改参数。
fsync
改参数直接控制WAL日志文件是否先写入硬盘。
默认值为on(先写入),表示当更新数据写入硬盘时,操作系统必须等待WAL日志文件写入完成。
当设置为off 时,表示在更新数据写入硬盘时,操作系统无须等待WAL日志文件写入完成。
synchronous_commit
synchronous_commit = on ( off, local, remote_write, remote_apply, or on )
单实例环境:
- off:当数据库提交事务时不需要等待本地wal buffer 写入wal 日志,随即向客户端返回成功。适用对数据库准确性要求不高同时追求数据库性能的场景。
- on:表示提交事务时需等待本地wal 写入wal 日志后才向客户端返回成功。on为默认设置,数据库非常安全,但性能有所损耗。
- local:含义与on类似,表示提交事务时需要等待本地wal写入后才向客户端返回成功。
流复制环境:
- off:不必等wal 日志被本地持久化,也不管是否被传到远程,事务commit都可以立即返回。
- local:wal 日志被本地持久哈后(不用管远程),事务commit就可以返回。
- remote_write:wal 日志被备库内存中,事务commit才返回。
- on:wal日志被传入备库并持久化,事务commit才返回。
- remote_apply:wal日志被传到备库并apply,事务commit才返回。
full_page_writes
在检查点之后首次修改一个页面时,PostgreSQL服务器会将该页面的全部内容刷写到WAL日志文件中。会增加WAL日志文件的写入量。
wal_compression
full_page_writes = on 、wal_compression = on 时,PostgreSQL服务器会将CheckPoint第一次修改的数据页压缩后写到WAL日志文件中
effective_io_concurrency
effective_io_concurrency = 4 ( > 100 : SSDs and Memory-backed storages )
设置同时被执行的并发磁盘I/O操作的数量。0表示禁用异步I/O请求,默认是1。对位图索引扫描有效。
checkpoint_timeout
checkpoint_timeout = 5min ~ 15min
系统自动执行checkpoint之间的最大时间间隔。系统默认值是5分钟
checkpoint_completion_target
checkpoint_completion_target = 0.7 ~ 0.9
checkpoint调度系统,它可以让检查点在我们设置的checkpoint_timeout时间周期做的更分散,从而降低IO的影响。
checkpoint_warning
如果检查点发生的时间间隔接近checkpoint_warning秒,就会在服务器日志中输出一条信息。
wal_write_delay
wal_write_delay = 10ms
指定WAL写入器刷写WAL的频繁程度,以时间为单位。
在刷新WAL之后,写入器将根据wal_write_delay所给出的实际长度进行睡眠。
commit_delay
commit_delay = 10ms
事务提交后,日志写到wal_buffer上到wal_buffer写到磁盘的时间间隔。
需要和commit_sibling配合使用。
commit_siblings
commit_siblings = 1000
触发commit_delay 等待的并发事务数
若系统中并发活跃事务达不到该值,commit_delay将不起作用,为防止在系统并发压力较小的情况下事务提交后空等其他事务,不宜设置过大。
min_wal_size(收缩WAL尺寸的最低限制值)
只要WAL磁盘使用率低于这个设置,那个发生检查点时,旧的WAL文件总是被循环复用,而不是删除。这可以用来确保预留足够的空间应对WAL使用高峰,比如当运行批处理任务时。
max_wal_size
WAL日志文件增大到该参数指定大小后,会自动进行checkpoint。
特殊情况下,如符合过高、archive_command归档失败、wal_keep_segments设置过大,WAL文件大小会超过设置的值。增加该参数的值会延长崩溃恢复所需要的时间。
wal_keep_segments
wal_keep_segments(pg13:wal_keep_size)
改参数独立于其他参数设置,保留最少wal_keep_segments个wal段文件。
archive_command
如果配置archive_mode = on,当wal段文件未及时被归档时,即使满足了其他清理条件,wal段文件也不能被清理。
archive_timeout
如果配置archive_mode=on,archive_timeout用来强制服务器周期性地切换到一个新的wal段文件。
max_slot_keep_wal_size
该值表示如果复制槽被感知到失联,保留WAL文件的最大数量。如果超过该值,PostgreSQL将开始删除最早的WAL文件。
Parallel Related
eg:Linux 64Bit x86-64 SSD CPU:16 Memory:32GB Connections:1000 OLTP
PG:13
max_worker_processes
-
max_worker_processes = 16 ( < CPU core )
数据库允许的最大后台进程数,并行进程属于后台进程的一种。
max_parallel_workers
-
max_parallel_workers = 16 ( <= max_worker_process )
数据库循序的最大并行进程数。
max_parallel_workers_per_gather
-
max_parallel_workers_per_gather = 8 ( 1/2 max_parallel_workers )
并行查询进程数。
max_parallel_maintenance_workers
-
max_parallel_maintenance_workers = 8 ( 1/2 max_parallel_workers )
维护并行进程数
max_parallel_workers_per_gather + max_parallel_maintenance_works <= max_parallel_workers
Autovacuum Related
autovacuum
autovacuum = on
autovacuum_max_workers
autovacuum_max_workers = 6 ~ 12
一次可以运行多少个autovacuum进程。
autovacuum_naptime
autovacuum_naptime = 1min (autovacuum_natime / database)
autovacuum worker进程休息间隔。
log_autovacuum_min_duration
log_autovacuum_min_duration (默认ms)
运行时间超过此值的任何autovacuum都会记录到PostgreSQL日志文件中。
autovacuum_vacuum_scale_factor * number of tuples + autovacuum_vacuum_threshold
autovacuum_analyze_scale_factor * number of tuples + autovacuum_analyze_threshold
antovacuum_vacuum_scale_factor / autovacuum_analyze_scale_factor
将添加到公式中的表记录的分数。例如,值0.2等于表记录的20%
autovacuum_vacuum_threshold / autovacuum_analyze_threshold
触发autovacuum所需的过时记录或dml的最小数量
autovacuum_vacuum_cost_limit
autovacuum可达到的总成本限制(结合所有autovacuum作业)
autovacuum_vacuum_cost_delay
autovacuum_vacuum_cost_delay = 2ms ( < 20 ms )
当一个清理工作达到autovacuum_vacuum_cost_limit 指定的成本限制时,autovacuum将休眠数毫秒。
autovacuum_vacuum_insert_threshold ( PG13 )
autovacuum_vacuum_insert_scale_factor ( PG13 )
Autovacuum最佳实践
死元组清理调优
idle_in_transaction_session_timeout
长查询:statement_timeout
加速autovacuum运行
调大autovacuum_vacuum_cost_limit参数的值,以及降低autovacuum_vacuum_cost_delay的值。
如果autovacuum_vacuum_cost_delay=0,相当于立即手动执行autovacuum。
降低死元组生成速度
多条update语句合并为一条;使用填充因子(HOT)特性;使用upsert特性(insert on conflict)
基于单表数据修改调优
autovacuum_vacuum_scale_factor
基于单表数据插入调优
13:降低autovacuum_vacuum_insert_scale_factor的值来加速autovacuum操作。
低于13:可以降低autovacuum_freeze_max_age的值,该值默认是2亿。
避免事务ID回卷
检查是否有长session手动处理事务或者使用临时表;检查是否有数据文件坏块。
表分区增大并发workers
增大autovacuum_max_workers的值。
Logging Related
-
logging_collector = on
-
log_destination = ‘csvlog’
-
log_line_prefix = ‘%m %p’
log_line_prefix需要与log_destination = ‘stderr’ 同时使用
-
log_directory = ‘log’
-
log_filename = ‘postgresql-%Y-%m-%d_%H%M%S.log’
-
log_file_mode = 0600
-
log_truncate_on_rotation = on
-
log_rotation_age = 1d
-
log_rotation_size = 0
-
log_checkpoints = on
-
log_lock_waits = on
-
log_duration = on
-
log_statement_sample_rate = 0.2
-
log_min_turation_sample = 100ms
-
log_min_turation_statement = 500ms
-
log_statement = ‘none | ddl | mod | all’
-
方案一:每天生成一个新的日志文件
log_filename = 'postgresql-%Y-%m-%d.log' log_truncate_on_rotation = off log_rotation_age = 1d log_rotation_size = 0 -
方案二:每当日志写满一定的大小(10MB),则切换一个日志
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' log_truncate_on_rotation = off log_rotation_age = 0 log_rotation_size = 10MB -
方案三
log_filename = 'postgresql-%u.log' log_truncate_on_rotation = on log_rotation_age = 1d log_rotation_size = 0
other
old_snapshot_threshold
强制删除过老的事务快照保留的死元组
temp_file_limit
限制临时文件使用量
track_io_timing
跟踪IO消耗的时间
track_activity_query_size
activity_query列存储的大小,默认是1kb。
huge_pages
改参数用于启用或禁用巨型内存页面,对于一些连接数很大或内存很大的数据库,强烈建议配置大页。
try:表示让postgresql尝试使用大页,分配大页失败后,会使用普通内存。
on:分配大页失败后,postgresql也会启动失败。
检查页表大小:
[postgres@lyp ~]$ cat /proc/meminfo |grep PageTables PageTables: 22872 kB [postgres@lyp ~]$
default_statistics_target
查看执行计划时,生成执行计划时间远大于执行时间时,可以通过调整default_statistics_target参数进行优化
default_statistics_target过大:会影响analyze操作执行的时间,扫描的数据行的个数就会更多,得到的优化器的统计数据就会越准确。
建议根据业务的情况,进行表级别的设置。
Tuning tools
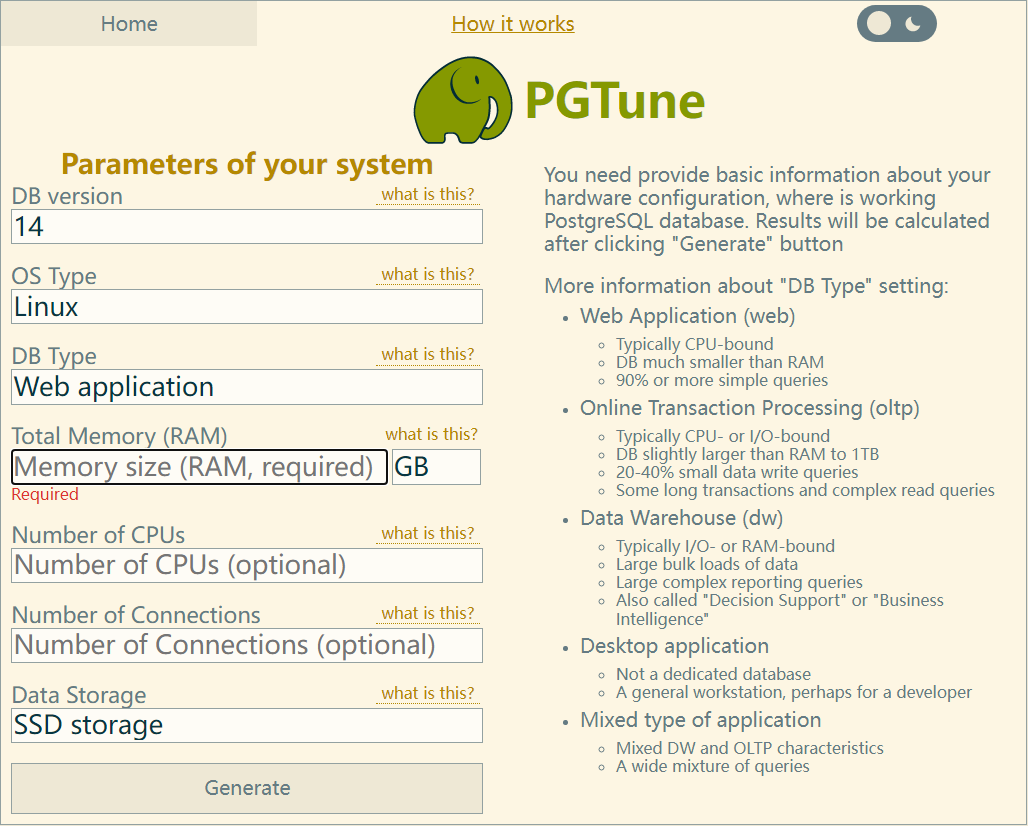
PGTune
https://pgtune.leopard.in.ua/#/
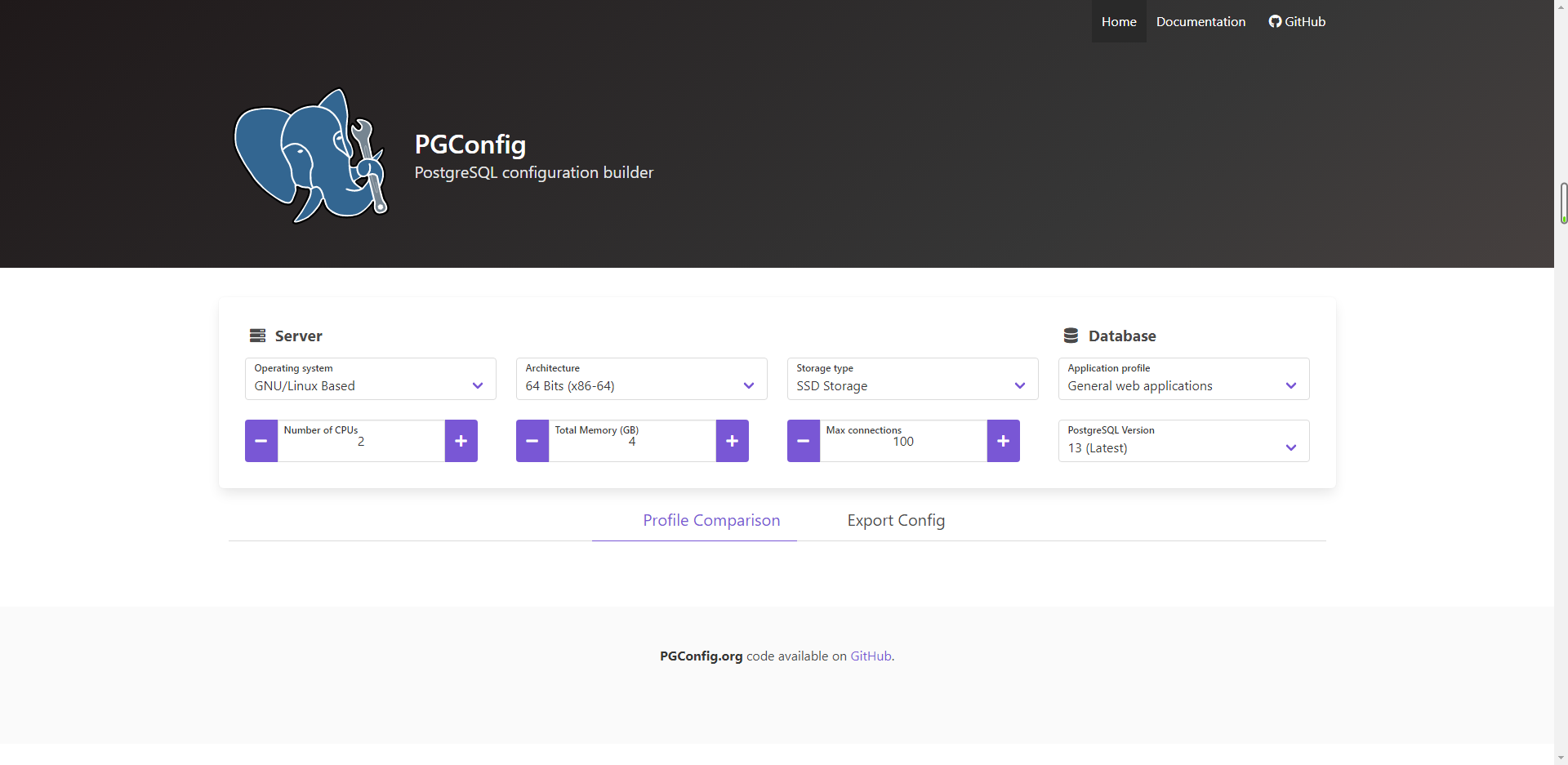
PostgreSQL Configuration Tool
https://www.pgconfig.org/#/tuning
postgresqltuner
https://github.com/jfcoz/postgresqltuner
pgBadger
https://github.com/darold/pgbadger