分布式数据库可以从广义和狭义两个角度进行阐释,广义上,分布式的存储系统都可以称为分布式数据库。
狭义上的分布式数据库,专指无共享的、分布式的、关系型数据库,即支持SQL,分布式事务,有统一接口的分布式的数据库。
数据库当然专注于狭义的分布式范畴,以下讨论的也主要是这类系统。其代表比如,OceanBase,TiDB,Spanner这些系统。其它的,比如像一些Sharding中间件,SQL On Hadoop系统,流处理系统,共享存储的关系型数据库,不算(狭义的)分布式数据库。分布式数据库在数据库历史的早期就有了,代表例子是System R*。
分布式事务的概念也研究的很早。但分布式数据库直到最近几年才被关注,其原因是多方面的。
- 一是早期数据规模不够大,单机数据库就能搞定;
- 二是长期以来,市面上也没有较好的分布式数据库;
- 第三是分布式数据库本身不可避免的一些缺陷。
在以前人们的印象中,数据库是不讲扩展的。2000年以后,伴随着互联网行业不断增长的数据规模,NoSQL运动发展起来了。NoSQL牺牲了关系型数据库的一些限制,为数据存储带来的扩展性。这使得数据库社区开始重新思考传统关系型数据库,之后催生了NewSQL。
NewSQL 定义了一种新型的数据库,兼具扩展性与传统关系型数据库的特性。
分布式数据库的优点显尔易见,主要优势有:扩展性,分布式数据库把数据分散存储到多个节点上,以实现水平扩展。当前的许多NewSQL都能自动的扩容,这相对于传统方式(MySQL分表分库)来说拥有很大的优势。效率,把数据分到多个节点上,多个节点可以并行地执行,提高了整体的吞吐。
分布式数据库的缺点也很明显:分布式事务的代价较高。这种代价主要来源于:两阶段的提交造成过多的消息传输;可能的锁争用变大;复制多副本和高可用。在应用开发者抛弃交互式事务(接受使用存储过程)之前,分布式事务在未来将还是个很难消除的瓶颈管理复杂,相比单机的数据库,分布式数据库会有更多的节点和组件,更难于管理。
幸运的是,现在主流的分布式数据库多数使用共识协议实现自动容错,许多时候不需要用户介入。
随着摩尔定律的失效,以前靠升级硬件实现Scale Up的方式已经不行了。让数据库Scale Out变成新的考虑目标。
分布式数据库在以后将会有更大的应用空间。对于当下,一般的共识是,数据量不上一定规模,不要用分布式数据库,因为很可能获得不到什么明显的优势。
严格的讲,分布式数据库要能够做到:
- 避免单点失效。
- 横向扩展。
不能满足这两点的数据库都不能算是分布式。
实现1的方式是replication,实现2的方式是sharding。
replication分3种:主从复制(master-slave),多主复制(multi-master),无主复制(leaderless)
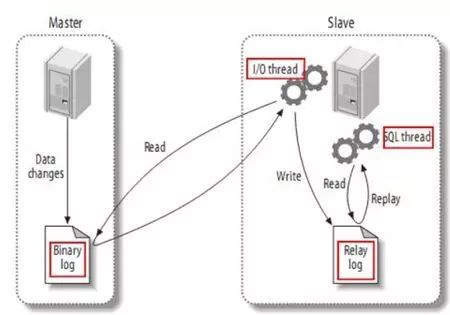
绝大多数的数据库,都是采用主从复制。当主节点失效时,选举出一个从节点提升为主节点。这种方式最好理解。平时从节点为只读。基本上绝大部分NoSQL数据库都是这种多主复制一般用在多个数据中心(不同城市)之间的复制,这种方式不同区域的客户,体验会更好,数据的操作只需要连接本区域的数据中心即可。但是,这涉及到一些实际的问题,比如数据冲突,如何路由用户的请求等问题。代表数据库是CouchDB无主比多主更激进,不像有上面只有主节点可以写,它的每一个节点都可以接受写请求,可用性最好。但需要用机制去解决数据冲突(version vector,vector clock),一般在数据库驱动里实现,实在解决不了的就需要让用户(你的代码)在读取数据的时候解决。代表数据库Riak,亚马逊自己的dynamodb(不是云服务里对外卖的那个)复制方式又分同步和异步。异步复制性能好,但是当出现主节点切换时,数据会丢。带P的数据库,基本上,每一个写请求都可以设置是同步还是异步,甚至可以控制具体复制到几个从节点才返回,也就是说C的粒度可以很细,这一点是SQL不具备的(通过CDC复制,要么是同步要么是异步,先配置好)。
很多SQL数据库也能通过主从复制避免单点失效,比如Mysql集群,但是为什么他们不算分布式呢?
就在于他们没有原生内置的sharding机制sharding就是分片,SQL里叫分库分表。但这个分是数据库提供的基本功能,拿来就用,也不会因为这个影响其他的操作比如查询,其他的操作该怎么用还是怎么用,对程序员是完全封装的。
做的好的,还会自动再平衡。你需要考虑的就是数据库提供的几种数据路由机制哪种合适你的需求。实际应用,据我所知,不多。国内老牌的厂,因为历史原因,都是用MySQL加一些中间层自己搓。好像只有58同城用的mongodb,但有没有用到sharding不清楚。
带P的数据库,缺点主要是:
- 不支持可以和传统SQL数据库媲美的事务(mongodb 4.0虽然支持了事务,但是有很多限制)。NoSQL只保证单个文档(document, value whatever)的事务(原子性),这需要程序员转换思维,设计denormalized schema。
- 对运维的要求高。
分布式数据库的好处,就是通过水平扩展的方式,以较低的成本地突破磁盘、CPU和内存等单机瓶颈,满足海量数据存储的需求,劣势当然就是技术复杂度更高了,需要团队有比较强的实力。分布式数据库是整个分布式计算体系的必然选择。在互联网领域,规模越大,任务越要分散化,随着业务的成长,架构从最原始的 PHP/Tomcat+MySQL,走到前后端分离,实质是规避服务器的CPU、磁盘I/O、带宽因请求众多而竞争激烈带来的相互影响(导致大量的Web并发请求被堵塞或者变慢,极度影响用户体验),当然体量越来越大,后端的数据库依然需要与性能瓶颈做斗争,数据库本身也逐步走向读写分离,再发展到分布式数据库。
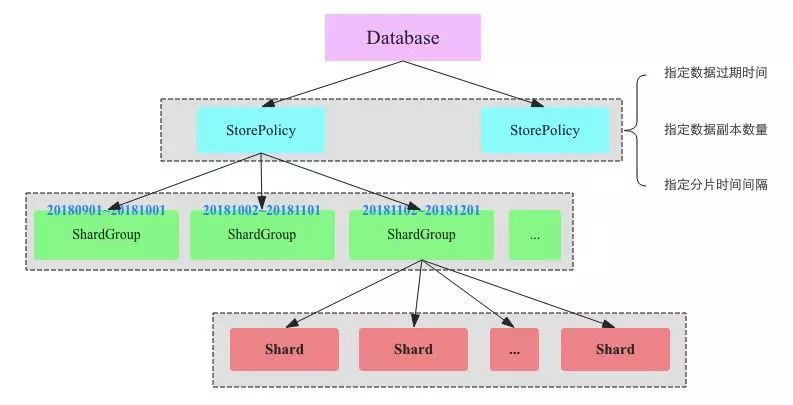
分库分表的方案首先应运而生。分库分表的原理是将数据按照一定的分区规则 Sharding 到不同的关系型数据库中,应用再通过中间件的方式访问各个 Shard 中的数据。分库分表的中间件,隐藏了数据 Sharding 和路由访问的各项细节,使应用大多数场景下可以像使用单机数据库一样使用分库分表后的分布式数据库。分库分表数据库中间件确实不是 Spanner 那样先进的分布式数据库,但从运维和使用成本的角度而言,这对很多企业是非常现实的选择。
例如,网易杭州研究院从 2006 年就开始开发分库分表数据库 DDB,该系统现在应用在网易的 100 多个产品,管理成千上万个数据节点,并且可以支持 PB 级结构化数据存储,其核心特性包括:分布式执行计划、分布式事务(2PC经典方案)、弹性扩缩容和全局表等。
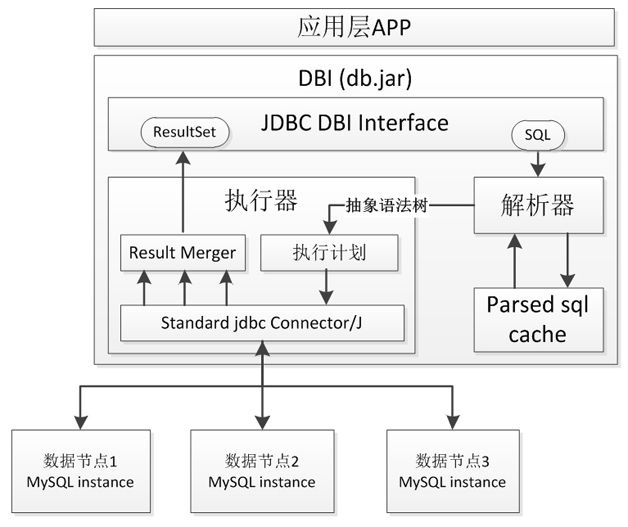
十多年来,DDB 经历了三次服务模式的重大更迭,从最早的 Driver 模式,到 Proxy 模式,再到后来的云模式。Driver 模式:应用通过 DDB 提供的 JDBC Driver 来访问 DDB,类似于通过 MySQL 的 JDBC 驱动访问 MySQL。
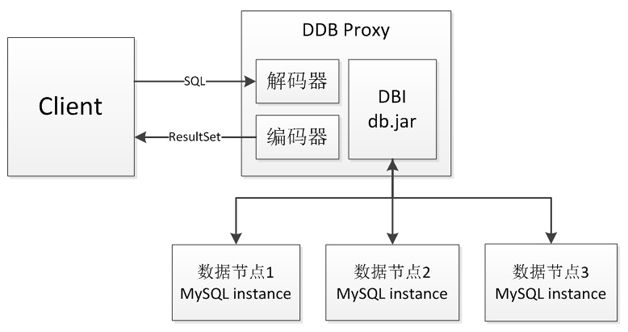
Proxy 模式:DDB Proxy 作为一组独立服务,实现了 MySQL 标准通信协议,任何语言的 MySQL 驱动都可以访问,而在 Proxy 内部,依赖 DBI 组件实现分库分表。
云计算模式:开发一套平台化的管理工具 Cloudadmin,将 DDB 中原先 Master 的功能打散,一部分分库相关功能集成到 Proxy 中,如分库管理、表管理、用户管理等,一部分中心化功能集成到 Cloudadmin 中,如报警监控。
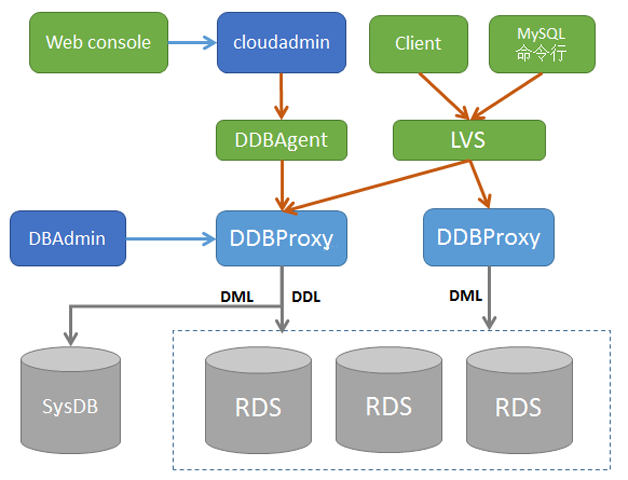
另外,考虑到 DDB 实时写入性能不足,而 HBase / Elasticsearch 等开源 NoSQL 平台多维查询以及聚合计算等功能不够,网易大数据团队还针对海量时序数据这类应用场景,研发了专门的分布式时序数据库 NTSDB。
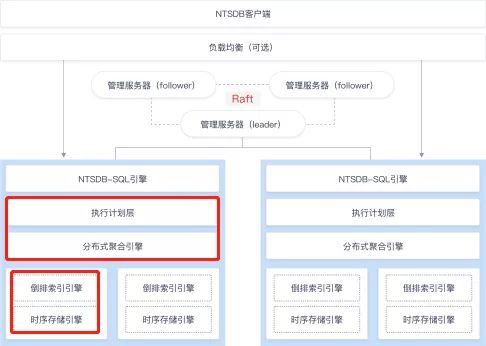
NTSDB 的分布式集群结构与 Hadoop / Hbase / Kudu 等架构非常相似:多台服务器用来存储数据,并通过Raft保证数据的一致性。数据的分布式计算是在分布式节点(node)上完成的,每个node 上的数据存储计算系统称之为 shard server。在 Shard Server 的底层数据存储中,原始数据存一份,再按照索引的方式再存一份。