




这一节我们讲一下MySQL锁的知识点,了解一下锁的分类及原理以及一些锁相关的最佳实践。
MySQL为什么需要锁
锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一 个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。本文将探讨MySQL中的常见的锁,以及背后的加锁原理,以及结合实际的开发用例,提出的一些优化建议。
相对其他数据库而言,MySQL的锁机制显著的特点是不同的存储引擎支持不同的锁机制。比如,MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking);InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。由于日常生产中主要是使用InnoDB引擎,本文也主要围绕MySQL的InnoDB引擎进行展开,如无特别声明,下文所指的均是InnoDB引擎。
MySQL中主要锁的种类和原理
锁基本原理
MySQL是如何实现加锁的呢?当我们说的MySQL锁住了这一行,其实并不会真正的锁住对应记录,而是锁住相应的索引,具体的锁哪些索引是根据查询条件来决定的。为什么通过索引,可以实现对表数据的并发控制呢?
因为MySQL的表的数据,本身通过1个或多个B+树索引来组织的。其中主键索引包含了完整的每一行的数据,非主键索引记录的是到行记录对应的主键索引的位置。所以,通过在索引记录上进行加锁操作,可以有效的读取、插入、修改、删除进行冲突判断。
如果这个表没有索引,是不是就加不了锁?这是不可能的,因为MySQL的每一个表至少有一个隐藏的聚簇索引,即主键索引。
锁的种类
在这个章节,会对MySQL InnoDB引擎中常见的7种锁进行介绍和原理分析。通过此章节,我们对MySQL的锁机制,已经就比较清楚了。
行锁
行锁即只会锁住一行,它的原理即是在对应的索引记录上加锁;
具有并发度高、锁冲突的概率低的优势,相对而言,由于粒度小,行锁成本高;
举例来说,当一行记录加了排它行锁的时候,其它事务是不能对这行记录进行修改的,但其他的行则不受此锁的影响。
但需要注意的是,在RR模型下进行更新一行记录时,如查询条件所在的列并无索引时,会退化成在主键索引对应的记录上全部加锁,即锁表。
表锁
InnoDB同时支持表锁。表锁又分为表级读锁和表级写锁,具体语法是
LOCKTABLES XXX READ|WRITE
如表加了读锁时,这个表进入了只读模式,其它会话不能对此表进行修改;
如表加了写锁,则此表进入独占模式,其它表的读和写都会被阻塞,一般用于特殊的场景,如drop table或者truncate table的场景
表锁实现原理,不是由InnoDB存储引擎层管理的,而是由其上一层MySQL Server负责的。需要注意以下两点:
(1)需要设置autocommit=0,innodb_table_lock=1(也是默认设置),InnoDB层才能知道MySQL加的表锁
(2)在事务结束前,不要用UNLOCAK TABLES释放表锁,因为UNLOCK TABLES会隐含地提交事务;同时,COMMIT或ROLLBACK不能释放由LOCAK TABLES加的表级锁,必须用UNLOCK TABLES释放表锁。
意向锁
意向锁,又分为意向共享锁IS和:意向排它锁IX, 表明一个事务想对数据库的某些行加共享/排他锁;它的原理是是记录在表级别,记录这个锁,而不是在索引上。
比如, SELECT ... LOCK IN SHARE MODE 会加一个IS锁, SELECT ... FOR UPDATE 会加一个 IX 锁.
即IS和IX锁,是当一个事务想在表中的某些行加S锁和X锁的时候,它会在表上登记一个IS和IX锁。那这个意向锁到底有什么作用呢?
意向锁被设计出来,只有1个目的,即当一个事务想申请表级别的共享或者排他锁时,会检查这个表上已经有的意向锁,来快速知道能否加锁成功。意向锁和表级锁的兼容关系如下:
X | IX | S | IS | |
X | 冲突 | 冲突 | 冲突 | 冲突 |
IX | 冲突 | 兼容 | 冲突 | 兼容 |
S | 冲突 | 冲突 | 兼容 | 兼容 |
IS | 冲突 | 兼容 | 兼容 | 兼容 |
可以看出意向锁之间是彼此兼容的,它只和表级锁之间有兼容关系。
所以,意向锁引入的主要目的也是为了提高获取表锁时的效率。
间隙锁
间隙锁(gap lock)是RR模式下,为了防止幻读而设计出来的。它锁住的是一个区间(开区间),当一个区间被加了间隙锁时,是无法执行插入的。
它的实现原理是,在对应的索引记录范围进行加锁,是一个左右均是开区间。
举例如下,有一个表,
TABLE `test` (
`id` bigint(20) unsigned NOT NULL COMMENT '主键',
`key` bigint(20) DEFAULT NULL COMMENT 'k',
PRIMARY KEY (`id`),
KEY `k` (`k`)
)
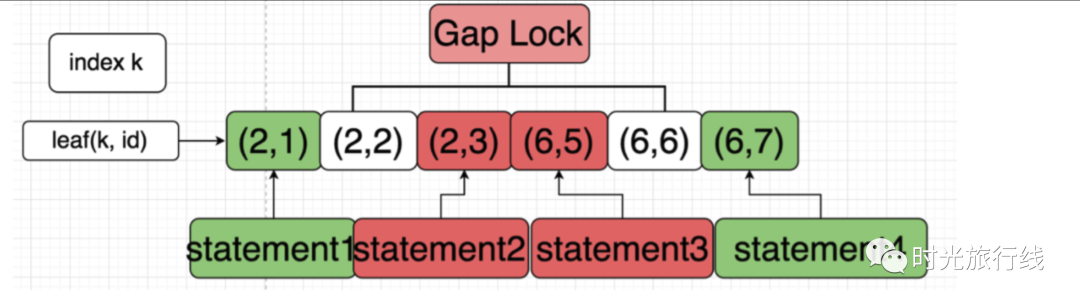
如果(2,2)和(6,6)之间被加了间隙锁,则事物2和事物3的插入,将会被阻塞,而事物1和事物4,则不会被阻塞。
需要注意的是,间隙锁本身之间是不会相互冲突的,它的唯一作用就是阻止在间隙内插入新的行。
临键锁
临键锁即next-key lock,是行锁和它之前的间隙共同构成的锁,即一个前开后闭的加锁区间。从原理上来说,它就是一个行锁叠加了一个间隙锁,它是RR模式下基本的加锁粒度。
由于间隙锁和临键锁的加锁规则比较复杂,这里引用林晓斌的总结为2个原则,2个优化,1个bug:
原则1:RR模式加锁的基本单位是next-key lock,即前开后闭的区间
原则2:查找过程中访问到的对象才会加锁
优化1:唯一索引上的等值查询,next-key lock会退化为行锁
优化2:索引上的等值查询,向右遍历的时候,最后一个值不满足等值条件的时候会退化为间隙锁。
一个bug:唯一索引上的范围查询,会访问到不满足条件的第一个值为止。
这里举例来说明
TABLE `test` (
`id` int(11) unsigned NOT NULL COMMENT '主键',
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `k` (`c`)
)
insert into t values (0,0,0),(5,5,5), (10,10,10),(15,15,15), (20,20,20),(25,25,25)
例子一:唯一索引查询间隙锁。sql如下:
update t set d=d+1 where id=7;
根据加锁规则1,加锁范围是(5,10]
同时由于优化2,最终的加锁范围是(5,10).
例子二:非唯一索引等值锁
select id from t where c=5 lock in share mode;
1)根据加锁原则1,加锁区间是(0,5]。
2)但由于c是普通索引,需要继续向右遍历,直到查询到c=10才会放弃
3)根据由于2,由于10不满足等值判断,因此会退化成间隙锁(5,10)
4)根据原则2,只有访问到的对象才会加锁,这个查询本身是有覆盖索引,并不需要访问主键,因此id主键上并没有锁。因此不会阻塞如下sql
update t set d=d+1 where id=5
例子三:主键索引范围锁
考虑如下两个SQL,语义上等同的,但是对加锁的效果确是不一样的。
select * from t where id=10 for update;
select * from t where id>=10 and id < 11 for update;
我们都知道第一条语句,会退化成id=10的行锁。
第二条语句,其实是id=10和 10<id<11的两个查找联合加锁结果。对于id=10,会加一个行锁,对于10<id<11会加一个(10,15]的临键锁
插入意向锁
插入意向锁,本质原理也是一个间隙锁,是在执行Insert语句前,获取的对应间隙的锁,同时获取对应行的锁。为什么还需要额外的引入插入意向锁呢?答案是MySQL为了提高效率。
举例如下:
TABLE `test` (
`id` int(11) unsigned NOT NULL COMMENT '主键',
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `k` (`c`)
)
insert into t values (0,0,0),(5,5,5), (10,10,10),(15,15,15), (20,20,20),(25,25,25)
有如下两个session同时执行插入操作
begin;
insert into t values (1,1,1);
begin;
insert into t values (2,2,2);
由于需要申请间隙锁,这会导致后面的插入被阻塞。但是实际上这两个插入并不会相互干扰,为什么不能同时执行呢。
索引插入意向锁,是为了解决同一个间隙内,并发插入不同位置的锁竞争。
需要注意的是,由于插入意向锁和其它的临建锁/间隙锁本身会相互冲突的,如下面的两个session会冲突的
begin;
SELECT * FROM t WHERE id > 1 FOR UPDATE;
begin;
insert into t values (2,2,2);
自增锁
自增锁是一个特殊的表级别的锁。当执行插入时,主键是AUTO_INCREMENT的列的时候,会触发自增锁。
它的原理是,它是表级别的锁,意味着,当一个事务执行插入的时候,其它的事务可能需要等待,以便获取唯一主键值,虽然等待的时间是极短的。
自增锁,为了考虑效率和一致性,有3种模式,包括:传统(默认)、连续、插入。对比如下:
模式 | 效果 | 优点 | 缺点 |
传统模式 | 任何insert预计都将导致table-level lock直到语句结束 | id递增不会重复 | 批量插入时,性能差 |
连续模式 (默认) | 当发生bulk inserts的时候,会产生一个特殊的AUTO-INC table-level lock直到语句结束, 对于Simple inserts,则使用的是一种轻量级锁,只要获取了相应的auto increment就释放锁,并不会等到语句结束。 | id递增不会重复 | 性能比传统模式好 |
插入模式 | 当进行bulk insert的时候,不会产生table级别的自增锁,因为它是允许其他insert插入的。 来一个记录,插入分配一个auto 值,不会预分配 | 性能极好 | SBR模式会有问题 |
一般来说,建议设置连续模式,即保持默认值即可,兼顾了性能和准确性。因为插入模式下,当主从采用SBR(statement-basedreplication,sbr)进行复制时,有可能会导致主从id不一致。
MySQL中锁的优化最佳实践
依据2PL的性能优化
两阶段加锁,即2PL。只加锁,不放锁;只放锁,不加锁。如下图所示:
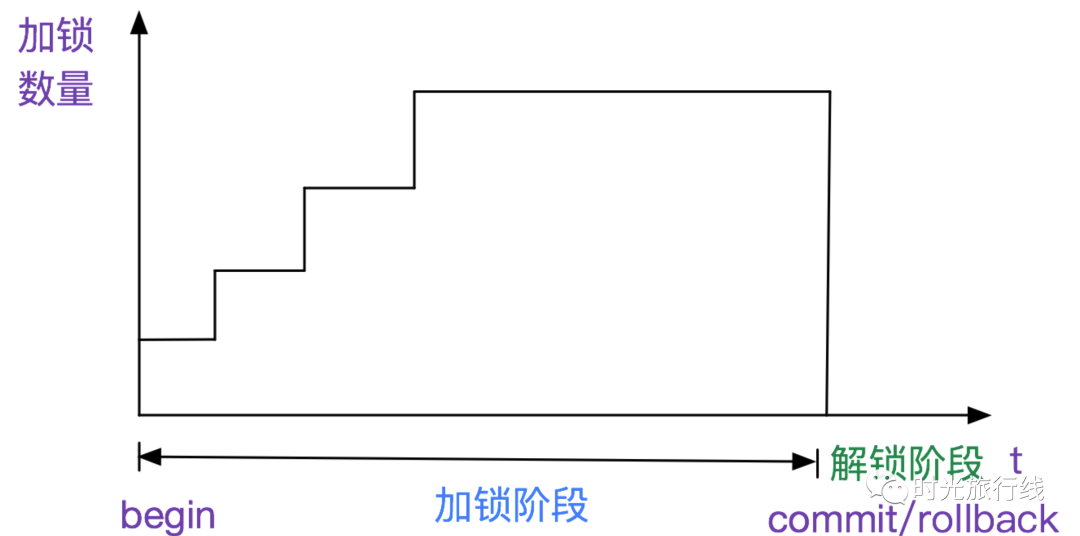
引入2PL是为了保证事务的隔离性,即多个事务在并发的情况下等同于串行的执行。
通过此项原理,我们需要把最热点的记录,即锁的冲突可能性最高的记录, 放到事务最后,这样可以显著的提高吞吐量。
避开死锁的哪些坑
唯一索引导致的死锁
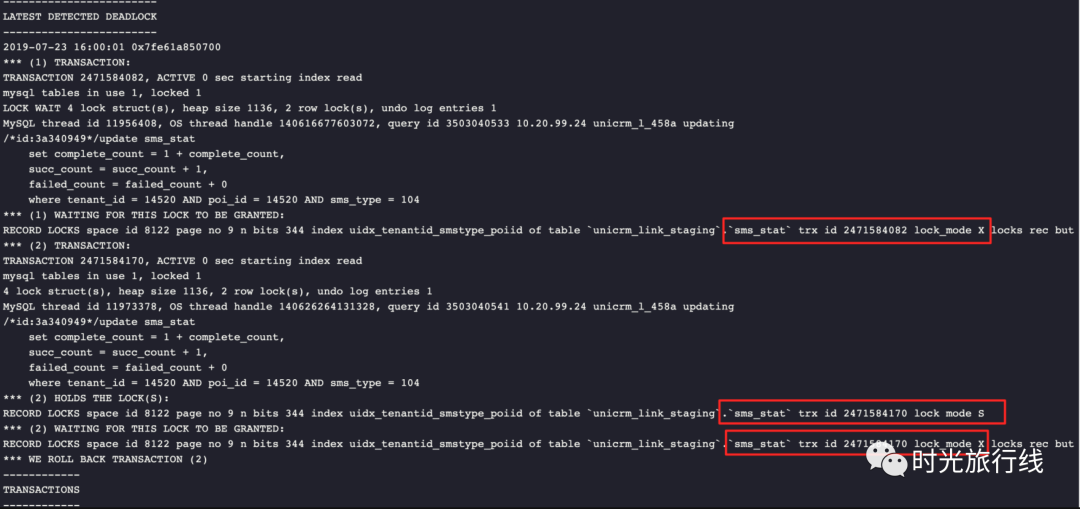
在MySQL中有一处比较特殊的实现,即当并发插入同一行,因为唯一索引导致”duplicate key error“时,会获得一把共享锁。此时,将有可能导致死锁。
比如,当有3个线程同时并发插入同一行时,只有1个线程能够成功,剩下的两个线程都将获得"duplicate key error",同时获得共享锁。如果两个线程后面继续执行更新语句时,将导致死锁。
查看死锁日志,将会获得如下类似的现场:
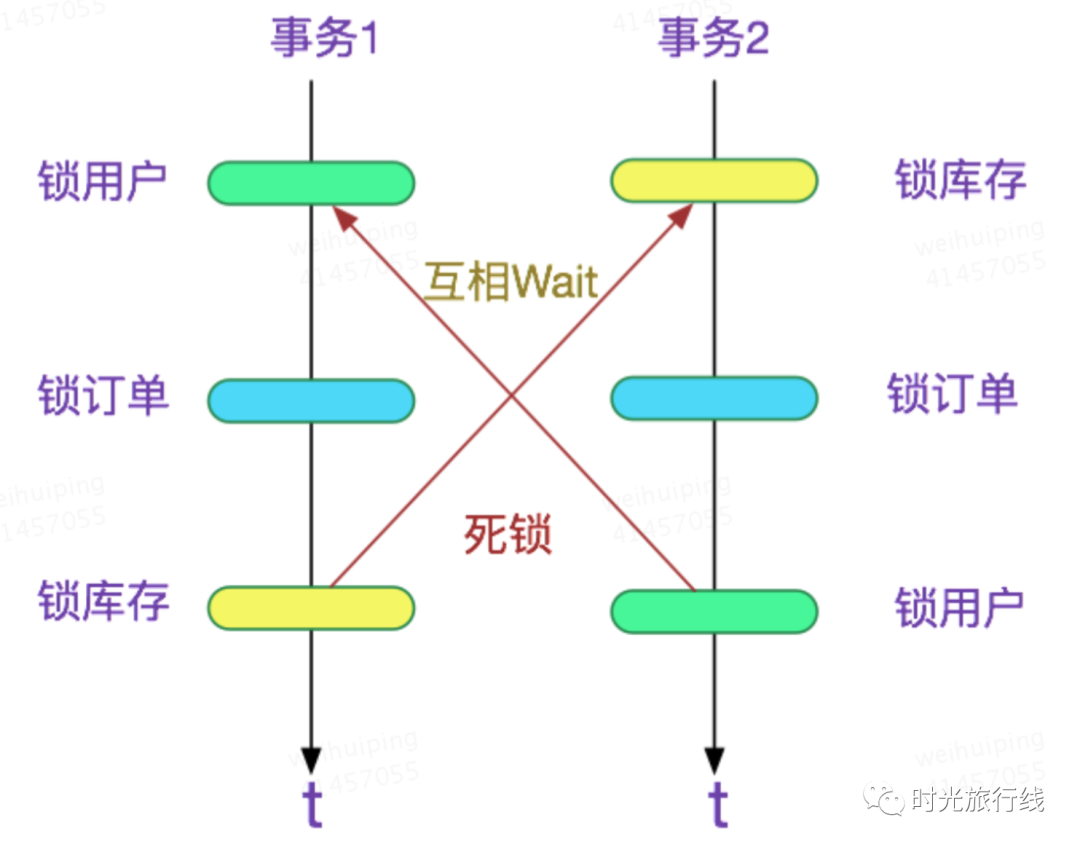
加锁顺序不一致导致的死锁
如果有多个功能,都需要操作用户表、订单表、库存表。建议在实现的时候,采用一致的加锁顺序,否则极有可能导致如下图示意的死锁。
是否真的需要RR模式
RR模式是用于解决幻读和不可重复读的,并且是MySQL的默认隔离级别。
RR模式和RC模式的一个最重要的区别是引入了间隙锁和临键锁,这将降低事务的并发性,同时增加了死锁的概率。
RR模式的好处是,在一个事务内,执行得到的统计和查询结果是一致的,但是坏处就是降低了数据库的吞吐量,同时增加了死锁的概率。
所以,我们在使用MySQL的时候,需要问一下自己,是我们真的需要RR模式吗?
高并发的表,业务生成主键
如上面自增锁的分析,mysql在默认模式下,性能不能保证,特别是当并发插入量较大的时候。
建议业务方使用独立的id生成器生成主键,避免性能和不一致的问题。
参考
1.https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-next-key-locks
2.https://dev.mysql.com/doc/refman/5.7/en/metadata-locking.html
3.https://my.oschina.net/Tright/blog/1579739

