




1.介绍
PostgreSQL日志分析器“ pgBadger ”是一个用 Perl 编写的开源“快速 PostgreSQL 日志分析报告”程序,它从正在运行的 PostgreSQL 实例获取日志输出并将其处理成 HTML 文件。它生成的报告以漂亮且易于阅读的报告格式显示所有信息。这些报告可以帮助阐明系统中发生的错误、检查点行为、真空行为、趋势以及 PostgreSQL 系统的其他基本但至关重要的信息。
pgBadger 报告有关你的 SQL 查询的所有信息:对慢查询分析,SQL查询统计分析,会话分析, 以及我们的IO ,acuum,checkpoin 等等日常监控的一些关键点,都能很好地从日志或图表上看出关键点。而且面很全,对们数据库的日常管理,性能优化个人觉得很有帮助,由于在测试库我生的Html 文件可能数据不够丰富,但这不影响对pgBadger 的了解。
2.PG 参数设置
PostgreSQL 日志记录设置
为了有效地使用 pgBadger,应该设置登录 PostgreSQL 以提供 pgBadger 尽可能多的信息。可以调整一些选项以允许数据库系统记录有用的信息,以便 pgBadger 生成有用的报告。PostgreSQL 配置的完整文档可以在 pgBadger github 页面上找到,但下面是一些基本信息。
#慢日志时间 和日志格式
log\_min\_duration\_statement = 1000
log\_line\_prefix = '%t \[%p\]: user=%u,db=%d,app=%a,client=%h '
#支持英文
lc\_messages='en\_US.UTF-8'
lc\_messages='C'
#启用其他参数才能从日志文件中获取更多信息:
log\_checkpoints = on
log\_connections = on
log\_disconnections = on
log\_lock\_waits = on
log\_temp\_files = 0
log\_autovacuum\_min\_duration = 0
log\_error\_verbosity = default
pgBadger 默认输入不适用于 csvlog
所以如果pg参数 log\_destination 值是'csvlog' 时,需要先转换安装 Text::CSV\_XS 组件,详细见6.1
3.PGabadger 安装
下载: https://github.com/darold/pgbadger
tar xzf pgbadger-11.x.tar.gz
cd pgbadger-11.x/
perl Makefile.PL
make && sudo make install
4.PGabadger 使用示例
4.1 查看帮助
pgbadger --help #更多内容可以查看帮且文档
Usage:
pgbadger \[options\] logfile \[...\]
具有完整详细报告和图表的 PostgreSQL 日志分析器。
Arguments:
logfile 可以是单个日志文件、文件列表或 shell 命令返回文件列表。如果你想从标准输入传递日志内容使用 - 作为文件名。
注意:来自标准输入的输入不适用于 csvlog。
options:
-a | --average minutes : 构建平均图表的分钟数查询和连接。默认 5 分钟。
-A | --histo-average min:构建直方图的分钟数的查询。默认 60 分钟。
-b | --begin datetime : 在日志中解析数据的开始日期/时间(时间戳或时间)
-c | --dbclient host :仅报告给定客户端主机的条目。
-C | --nocomment :从查询中删除 /\* ... \*/ 之类的注释。
-d | --dbname 数据库:仅报告给定数据库的条目。
-D | --dns-resolv :客户端 IP 地址被其 DNS 名称替换。 请注意,这确实会降低 pgBadger 的速度。
-e | --end datetime : 要在日志中解析的数据的结束日期/时间(时间戳或时间)
-E | --explode : 通过生成一份报告来分解主报告每个数据库。与 a 无关的全局信息数据库被添加到 postgres 数据库报告中。
-f | --format logtype:可能的值:syslog、syslog2、stderr、jsonlog、 cvs、pgbouncer、logplex、rds 和 redshift。
用这个pgBadger 无法检测到日志时的选项格式。
-G | --nograph :禁用 HTML 输出的图表。默认启用。
-h | --help :显示此消息并退出。
-H | --html-outdir path:必须写入 HTML 报告的目录的路径在增量模式下,二进制文件保留在目录中使用 -O, --outdir 选项定义。
-i | --ident name : 用作 syslog ident 的程序名。默认值:postgres
-I | --incremental :使用增量模式,报告将由天在一个单独的目录中, --outdir 必须设置。
-j | --jobs number :同时运行的作业数。单人运行默认情况下或使用 csvlog 时。
-J | --Jobs number : 要并行解析的日志文件数。流程一默认情况下一次文件或使用 csvlog 时。
-l | --last-parsed file: 通过注册允许增量日志解析最后一个日期时间和行解析。
如果你愿意的话很有用观察自上次运行以来的错误,或者如果你想要一个每天报告,每周轮换日志。
-L | --logfile-list 文件:包含要解析的日志文件列表的文件。
-m | --maxlength size : 查询的最大长度,将被限制为给定的大小。默认截断大小为 100000。
-M | --no-multiline : 不收集多行语句以避免垃圾特别是在生成大量报告的错误上。
-n | --nohighlight : 禁用 SQL 代码高亮。
-N | --appname name :仅报告给定应用程序名称的条目
-o | --outfile 文件名:定义输出的文件名。默认依赖关于输出格式:out.html、out.txt、out.bin、out.json 或 out.tsung。
可以使用此选项多次输出几种格式。使用 json输出 Perl 模块 JSON::XS 必须安装,要将输出转储到标准输出,请使用 - 作为文件名。
-O | --outdir path :必须保存输出文件的目录。
-p | --prefix string :自定义 log\_line\_prefix 的值在你的 postgresql.conf 中定义。
仅当你使用它时未使用指定的标准前缀之一在 pgBadger 文档中,
例如如果你的前缀包括附加变量,如客户端 ip或应用程序名称。请参阅下面的示例。
-P | --no-prettify :禁用 SQL 查询美化格式化程序。
-q | --quiet :不打印任何内容到标准输出,甚至不打印进度条。
-Q | --query-numbering : 使用时将查询编号添加到输出中 选项 --dump-all-queries 或 --normalized-only。
-r | --remote-host ip : 设置执行cat命令的主机
-R | --retention N :保持增量模式的周数。默认为 0,禁用。用于将周数设置为保存在输出目录中。较旧的几周和几天目录被自动删除。
-s | --sample number :要存储的查询样本数。默认值:3。
-S | --select-only :仅报告 SELECT 查询。
-t | --top number :要存储/显示的查询数。默认值:20。
-T | --title string : 更改 HTML 页面报告的标题。
-u | --dbuser username:仅报告给定用户的条目。
-U | --exclude-user username : 排除指定用户的条目报告。可以多次使用。
-v | --verbose :启用详细或调试模式。默认禁用。
-V | --version : 显示 pgBadger 版本并退出。
-w | --watch-mode :只报告错误,就像 logwatch 一样。
-W | --wide-char : 将查询的 html 输出编码为 UTF8 以避免Perl 消息“打印中的宽字符”。
-x | --extension :输出格式。值:text, html, bin, json ortsung。默认值:html
-X | --extra-files : 在增量模式下允许 pgBadger 编写 CSS 和 输出目录中的 JS 文件作为单独的文件。
-z | --zcat exec\_path :设置 zcat 程序的完整路径。如果使用它zcat 或 bzcat 或 unzip 不在你的路径中。
-Z | --timezone +/-XX : 设置时区从 GMT 开始的小时数。使用它来调整 JavaScript 图表中的日期/时间。
--pie-limit num : 低于 num% 的饼图数据将显示一个总和。
--exclude-query regex : 任何匹配给定正则表达式的查询都将被排除 从报告中。例如:“^(VACUUM|COMMIT)” 你可以多次使用此选项。
--exclude-file 文件名:包含所有正则表达式的文件的路径用于从报告中排除查询。一个正则表达式每行。
--include-query regex : 任何不匹配给定正则表达式的查询将被排除在报告之外。你可以用这个多次选择。例如:“(tbl1|tbl2)”。
--include-file 文件名:包含所有正则表达式的文件的路径要从报告中包含的查询。一个正则表达式每行。
--disable-error : 不生成错误报告。
--disable-hourly :不生成每小时报告。
--disable-type : 不按类型生成查询报告,数据库或用户。
--disable-query :不生成查询报告(最慢,最频繁,用户查询,数据库查询,...)。
--disable-session :不生成会话报告。
--disable-connection :不生成连接报告。
--disable-lock :不生成锁定报告。
--disable-temporary :不生成临时报告。
--disable-checkpoint :不生成检查点/重启点报告。
--disable-autovacuum : 不生成 autovacuum 报告。
--charset :用于设置要使用的 HTML 字符集。默认值:utf-8。
--csv-separator : 用于设置 CSV 字段分隔符,默认:,
--exclude-time 正则表达式:匹配给定正则表达式的任何时间戳都将是从报告中排除。示例:“2013-04-12 .\*”你可以多次使用此选项。
--include-time 正则表达式:只有与给定正则表达式匹配的时间戳才会包含在报告中。示例:“2013-04-12 .\*”你可以多次使用此选项。
--exclude-db name : 排除指定数据库的条目报告。示例:“pg\_dump”。可多次使用时间。
--exclude-appname name : 排除指定应用程序名称的条目从报告。示例:“pg\_dump”。可以使用多次。
--exclude-line regex : pgBadger 将开始排除任何日志条目将匹配给定的正则表达式。可多次使用时间。
--exclude-client name : 排除指定客户端 IP 的日志条目。可以多次使用。
--anonymize : 隐藏查询中的所有文字,有助于隐藏机密数据。
--noreport : 防止 pgBadger 以增量方式创建报告模式。
--log-duration : 强制 pgBadger 关联生成的日志条目通过 log\_duration = on 和 log\_statement = 'all'
--enable-checksum :用于在每个查询报告下添加一个 md5 和。
--journalctl 命令:用于替换 PostgreSQL 日志文件的命令对 journalctl 的调用。基本上它可能是:journalctl -u postgresql-9.5
--pid-dir path :设置 pid 文件必须存储的路径。默认 /tmp
--pid-file file : 设置pid文件的名字来管理并发pgBadger 的执行。默认值:pgbadger.pid
--rebuild :用于以增量方式重建所有 html 报告输出有二进制数据文件的目录。
--pgbouncer-only :仅在标题中显示 PgBouncer 相关菜单。
--start-monday :在增量模式下,日历的周开始于一个星期天。使用此选项在星期一开始。
--iso-week-number :在增量模式下,日历的周数从星期一并尊重 ISO 8601 周数、范围01 到 53,其中第 1 周是具有新的一年至少有4天。
--normalized-only :仅将所有规范化查询转储到 out.txt
--log-timezone +/-XX : 设置时区从 GMT 开始的小时数必须用于调整从读取的日期/时间解析之前的日志文件。使用此选项使用日期/时间进行更困难的日志搜索。
--prettify-json :如果你希望 json 输出被美化,请使用它。
--month-report YYYY-MM : 创建一个累积的 HTML 报告超过指定月。需要增量输出目录和存在所有必要的二进制数据文件
--day-report YYYY-MM-DD:创建指定日期的 HTML 报告。需要增量输出目录和存在所有必要的二进制数据文件
--noexplain : 不处理 auto\_explain 生成的行。
--command CMD :执行以检索日志条目的命令标准输入。 pgBadger 将打开一个管道到命令并解析命令生成的日志条目。
--no-week :通知 pgbadger 不要在增量模式。如果花费太多时间很有用。
--explain-url URL : 用它来覆盖图形解释的 url工具。默认值:http://explain.depesz.com/?is\_public=0&is\_anon=0&plan=
--tempdir DIR : 设置写入临时文件的目录 默认值:File::Spec->tmpdir() || '/tmp'
--no-process-info :禁用更改进程标题以帮助识别 pgbadger 进程,有些系统不支持。
--dump-all-queries : 转储在日志文件中找到的所有查询替换 绑定参数包含在查询中他们各自的占位符位置。
--keep-comments :不要从规范化查询中删除评论。如果你想区分相同的规范化查询。
--no-progressbar : 禁用进度条。
pgBadger 能够使用无密码 ssh 连接解析远程日志文件。使用 -r 或 --remote-host 设置主机 ip 地址或主机名。还有一些额外的选项来完全控制 ssh 连接。
--ssh-program 要使用的 ssh 程序的 ssh 路径。默认值:ssh。
--ssh-port port 用于连接的 ssh 端口。默认值:22。
--ssh-user username 连接登录名。默认为运行用户。
--ssh-identity file 要使用的身份文件的路径。
--ssh-timeout ssh 连接失败的第二次超时。默认 10 秒。
--ssh-option options 用于 ssh 连接的 -o 选项列表。
总是使用的选项:
-o 连接超时=$ssh\_timeout
-o PreferredAuthentications=hostbased,publickey
也可以使用 URI 指定要解析的日志文件,支持的协议是http\[s\] 和 \[s\]ftp。 curl 命令将用于下载文件和文件将在下载过程中被解析。也支持 ssh 协议并将使用与远程主机一样的 ssh 命令。请参见下面的示例。
Examples:
pgbadger /var/log/postgresql.log
pgbadger /var/log/postgres.log.2.gz /var/log/postgres.log.1.gz /var/log/postgres.log
pgbadger /var/log/postgresql/postgresql-2012-05-\*
pgbadger --exclude-query="^(COPY|COMMIT)" /var/log/postgresql.log
pgbadger -b "2012-06-25 10:56:11" -e "2012-06-25 10:59:11" /var/log/postgresql.log
cat /var/log/postgres.log | pgbadger -
#带有 stderr 日志输出的日志前缀
pgbadger --prefix '%t \[%p\]: user=%u,db=%d,client=%h' /pglog/postgresql-2012-08-21\*
pgbadger --prefix '%m %u@%d %p %r %a : ' /pglog/postgresql.log
#带有 syslog 日志输出的日志行前缀
pgbadger --prefix 'user=%u,db=%d,client=%h,appname=%a' /pglog/postgresql-2012-08-21\*
#使用我的 8 个 CPU 更快地解析我的 10GB 文件
pgbadger -j 8 /pglog/postgresql-10.1-main.log
#对远程日志文件使用 URI 表示法
pgbadger http://172.12.110.1//var/log/postgresql/postgresql-10.1-main.log
pgbadger ftp://username@172.12.110.14/postgresql-10.1-main.log
pgbadger ssh://username@172.12.110.14:2222//var/log/postgresql/postgresql-10.1-main.log\*
#你可以同时使用本地 PostgreSQL 日志和远程 pgbouncer 日志文件来解析:
pgbadger /var/log/postgresql/postgresql-10.1-main.log ssh://username@172.12.110.14/pgbouncer.log
#仅使用选择查询生成 Tsung 会话 XML 文件:
pgbadger -S -o sessions.tsung --prefix '%t \[%p\]: user=%u,db=%d ' /pglog/postgresql-10.1.log
#每周按 cron 作业报告错误:
30 23 \* \* 1 /usr/bin/pgbadger -q -w /var/log/postgresql.log -o /var/reports/pg\_errors.html
#每周使用增量行为生成报告::
0 4 \* \* 1 /usr/bin/pgbadger -q \`find /var/log/ -mtime -7 -name "postgresql.log\*"\` -o /var/reports/pg\_errors-\`date +\\%F\`.html -l /var/reports/pgbadger\_incremental\_file.dat
#这假设你的日志文件和 HTML 报告也每周轮换一次,且使用自动生成的增量报告::
0 4 \* \* \* /usr/bin/pgbadger -I -q /var/log/postgresql/postgresql.log.1 -O /var/www/pg\_reports/
#将每天和每周生成一份报告。
#在增量模式下,你还可以指定要保留的周数报告:
/usr/bin/pgbadger --retention 2 -I -q /var/log/postgresql/postgresql.log.1 -O /var/www/pg\_reports/
#如果你在半小时内每天 23:00 和 13:00 有一个 pg\_dump,你可以使用 pgBadger 如下从报告中排除这些时期:
pgbadger --exclude-time "2013-09-.\* (23|13):.\*" postgresql.log
这将有助于避免 pg\_dump 生成的 COPY 语句位于最慢查询列表的顶部。你还可以使用 --exclude-appname "pg\_dump" 以更简单的方式解决此问题。
#你还可以解析 journalctl 输出,就像它是一个日志文件一样:
pgbadger --journalctl 'journalctl -u postgresql-9.5'
#从远程主机调用它:
pgbadger -r 192.168.1.159 --journalctl 'journalctl -u postgresql-9.5'
#你不需要在命令行中指定任何日志文件,但如果你有其他 PostgreSQL 日志文件要解析,你可以照常添加它们。
#要在之后重建所有增量 html 报告,请执行以下操作:
rm /path/to/reports/\*.js
rm /path/to/reports/\*.css
pgbadger -X -I -O /path/to/reports/ --rebuild
它还将更新所有资源文件(JS 和 CSS)。如果使用此选项构建报告,请使用 -E 或 --explode。
#pgBadger 还支持使用 logplex 格式的 Heroku PostgreSQL 日志:
heroku logs -p postgres | pgbadger -f logplex -o heroku.html -
这将通过标准输入将 Heroku PostgreSQL 日志流式传输到 pgbadger。
#pgBadger 可以使用自动检测 RDS 和 cloudwatch PostgreSQL 日志 rds 格式:
pgbadger -f rds -o rds\_out.html rds.log
#CloudSQL Postgresql 记录它是相当普通的 PostgreSQL 日志,但以 JSON 格式封装。 pgBagder 也会自动检测到它,但如果你需要强制使用日志格式,请使用 \`jsonlog\`
pgbadger -f jsonlog -o cloudsql\_out.html cloudsql.log
这与 jsonlog 扩展相同,json 格式不同,但 pgBadger 可以解析两种格式。
#要创建一个月内的累积报告,请使用命令:
pgbadger --month-report 2919-05 /path/to/incremantal/reports/
这会将月份名称的链接添加到增量报告的日历视图中,以查看 2019 年 5 月的报告。如果使用此选项构建报告,请使用 -E 或 --explode。
4.2 增量生成报告
pgBadger 包括使用选项 -I 或 --incremental 的自动增量报告模式。在这种模式下运行时,pgBadger 将每天生成一份报告,每周生成一份累积报告。首先以二进制格式输出到强制输出目录(请参阅选项 -O 或 --outdir),然后以 HTML 格式输出带有主索引文件的每日和每周报告。主索引文件将每周显示一个下拉菜单,其中包含指向每周报告的链接和指向每周每日报告的链接。
在这种模式下,pgBadger 将在输出目录中创建一个自动增量文件,因此你不必使用 -l 选项,除非你想更改该文件的路径。这意味着你可以每天在此模式下对每周轮换的日志文件运行 pgBadger,并且它不会计算日志条目两次。
为了节省磁盘空间,你可能需要使用 -X 或 --extra-files 命令行选项来强制 pgBadger 编写 JavaScript 和 CSS 来分隔输出目录中的文件。然后将使用脚本和链接标签加载资源。
例如,如果你基于每日轮换文件按如下方式运行 pgBadger:你将获得整个运行期间的所有每日和每周报告。
0 4 \* \* \* /usr/bin/pgbadger -I -q /var/log/postgresql/postgresql.log.1 -O /var/www/pg\_reports/
4.3 重建报告
增量报告可以在 pgbadger 报告修复或更新所有 HTML 报告的新功能后重建。要重建仍然存在二进制文件的所有报告,请执行以下操作:
rm /path/to/reports/\*.js
rm /path/to/reports/\*.css
pgbadger -X -I -O /path/to/reports/ --rebuild
它还将更新所有资源文件(JS 和 CSS)。如果使用此选项构建报告,请使用 -E 或 --explode。
4.4 月度报告
默认情况下,增量模式下的 pgBadger 仅计算每日和每周报告。如果你想要每月累积报告,则必须使用单独的命令来指定要构建的报告。例如,要构建 2019 年 8 月的报告:
pgbadger -X --month-report 2919-08 /var/www/pg_reports/
这会将月份名称的链接添加到增量报告的日历视图中,以查看月度报告。当前月份的报告可以每天运行,每次都完全重建。默认情况下不构建月度报告,因为它可能需要大量时间来跟踪数据量。
如果使用每个数据库选项( -E | --explode )或( -R | --rebuild )时也是如此,则在调用 pgbadger 构建月度报告时也必须使用它。
例在使用每个数据库选项( -E | --explode )构建报告,则在调用 pgbadger 构建月度报告时也必须使用它:
pgbadger -E -X --month-report 2919-08 /var/www/pg\_reports/
4.5 其它格式
pgbadger 支持多种格式 ,其中就包括二进度格式,和JSON格式。详细可以查看官方文档 或帮助文档
二进制格式
使用二进制格式可以创建自定义增量和累积报告,并可从该二进制文件生成新的 HTML
JSON格式
JSON 格式有利于与其他语言共享数据,这使得将 pgBadger 结果集成到 Cacti 或 Graphite 等其他监控工具中变得容易。
4.6 并行处理
要启用并行处理,你只需使用 -j N 选项,其中 N 是你要使用的内核数。
pgBadger 然后将按如下方式进行:
对于每个日志文件
块大小 = int(文件大小 / N)
查看这些块的开始/结束偏移量
fork N 个进程并寻找每个块的起始偏移量
当解析器到达结束偏移量时,每个进程都会终止
它的块
每个进程将统计信息写入二进制临时文件
等待所有子进程终止
所有生成的二进制临时文件都将被读取并加载到
内存来构建 html 输出。
使用该方法,在块的开始/结束时,pgBadger 可能会截断或省略每个日志文件最多 N个查询 . 如果你的日志文件中有数百万个查询,那么这是一个微不足道的差距。你正在寻找的查询丢失的可能性接近0,这就是为什么我认为这个差距是宜居的。大多数情况下,查询被计算两次但被截断。
注意: -J N 一般是对数百个小日志文件并且可以使用至少 8 个 CPU,性能会更好
-j N 常用于单个大文件,性能更好
这是在具有 8 个 CPU 和 9.5GB 单个文件的服务器上完成的基准测试,-j 性能更好(小写的的j , 同时运行的作业数)
Option | 1 CPU | 2 CPU | 4 CPU | 8 CPU
--------+---------+-------+-------+------
-j | 1h41m18 | 50m25 | 25m39 | 15m58
-J | 1h41m18 | 54m28 | 41m16 | 34m45
这是在有 200 个日志文件,每个 10MB,总共 2GB,结果略有不同。-J 性能更好(大写的的J,主要针对要并行解析的日志文件数)
Option | 1 CPU | 2 CPU | 4 CPU | 8 CPU
--------+-------+-------+-------+------
-j | 20m15 | 9m56 | 5m20 | 4m20
-J | 20m15 | 9m49 | 5m00 | 2m40
重要提示:
当你使用并行解析时,pgBadger 会在 /tmp 目录中生成大量临时文件,并在最后删除它们,因此除非 pgBadger 未运行,否则不要删除这些文件。它们都使用以下模板 tmp\_pgbadgerXXXX.bin 命名,因此可以很容易地识别它们。
5.PGabadger 使用截图
pgbadger postgresql-2022-02-14_120324.csv -o abc.html
5.1 Overivew
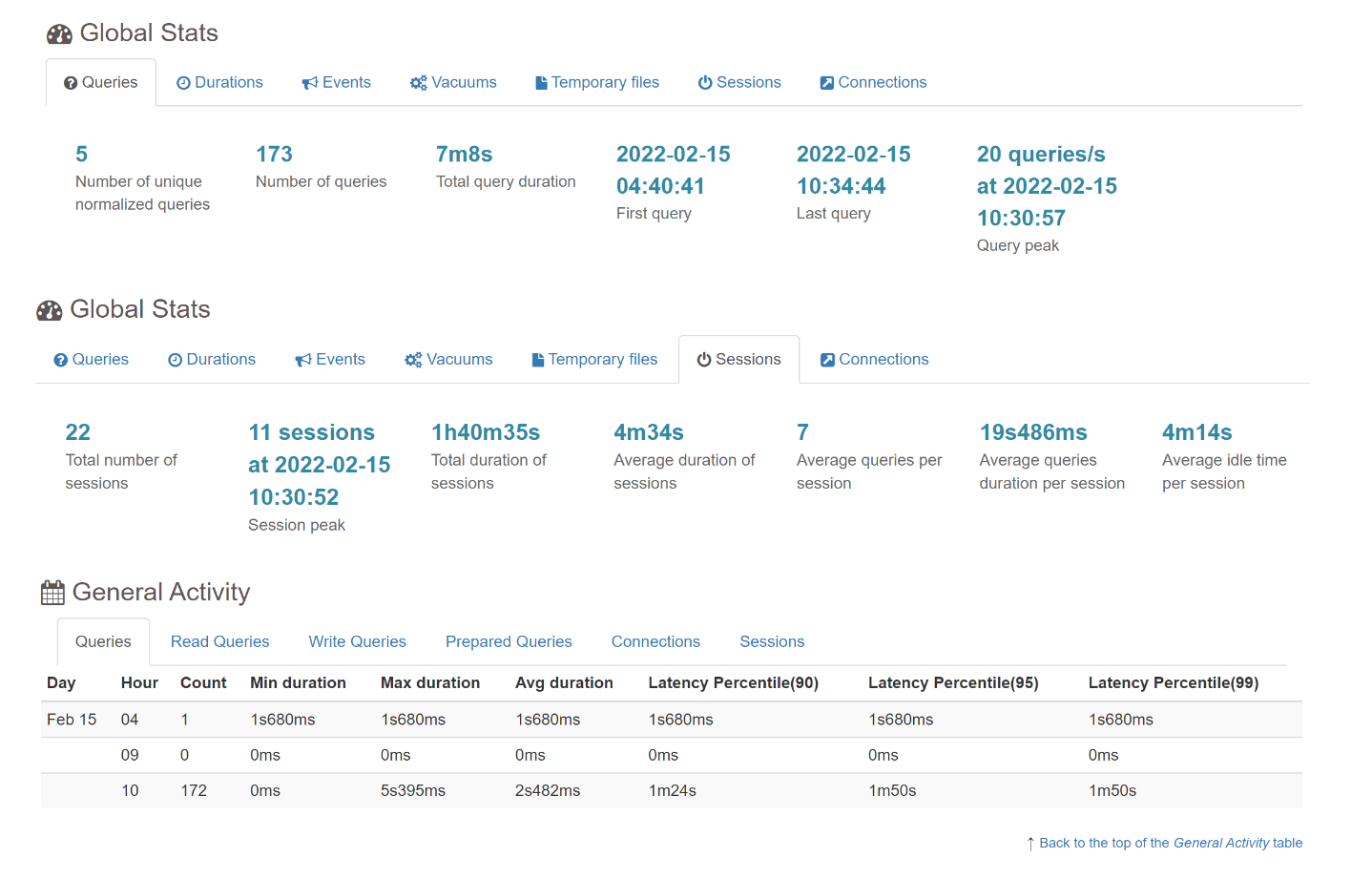
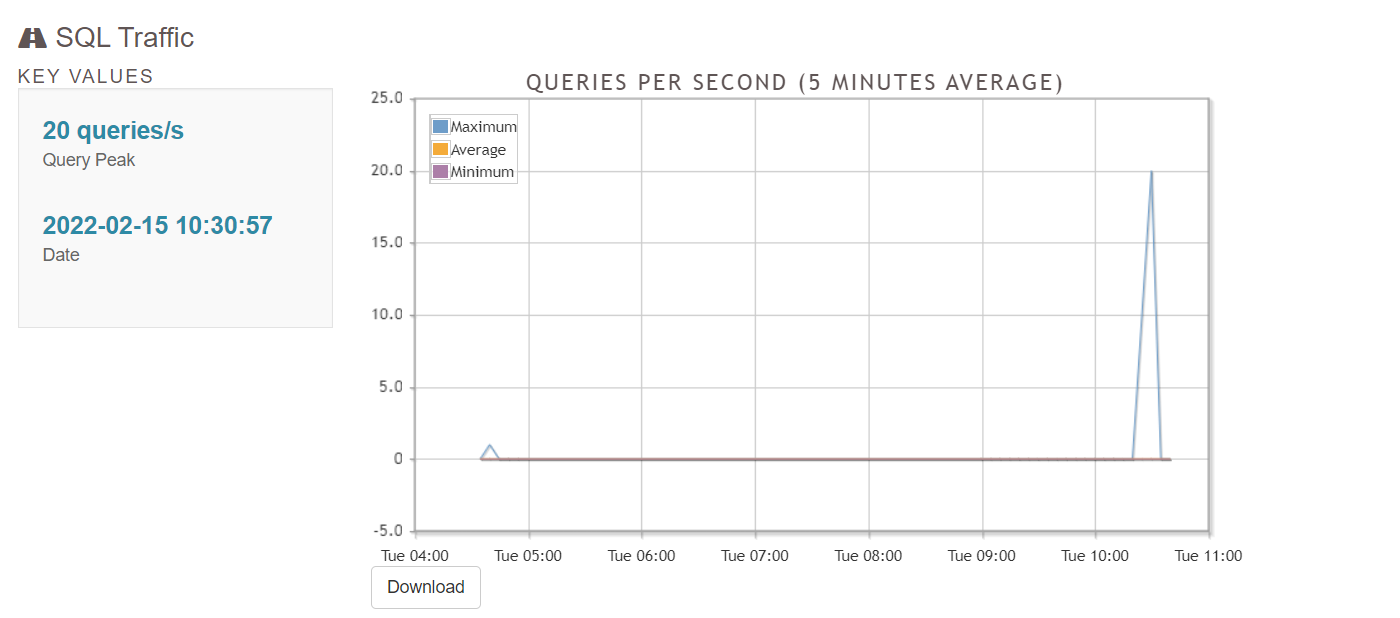
5.2 Connections

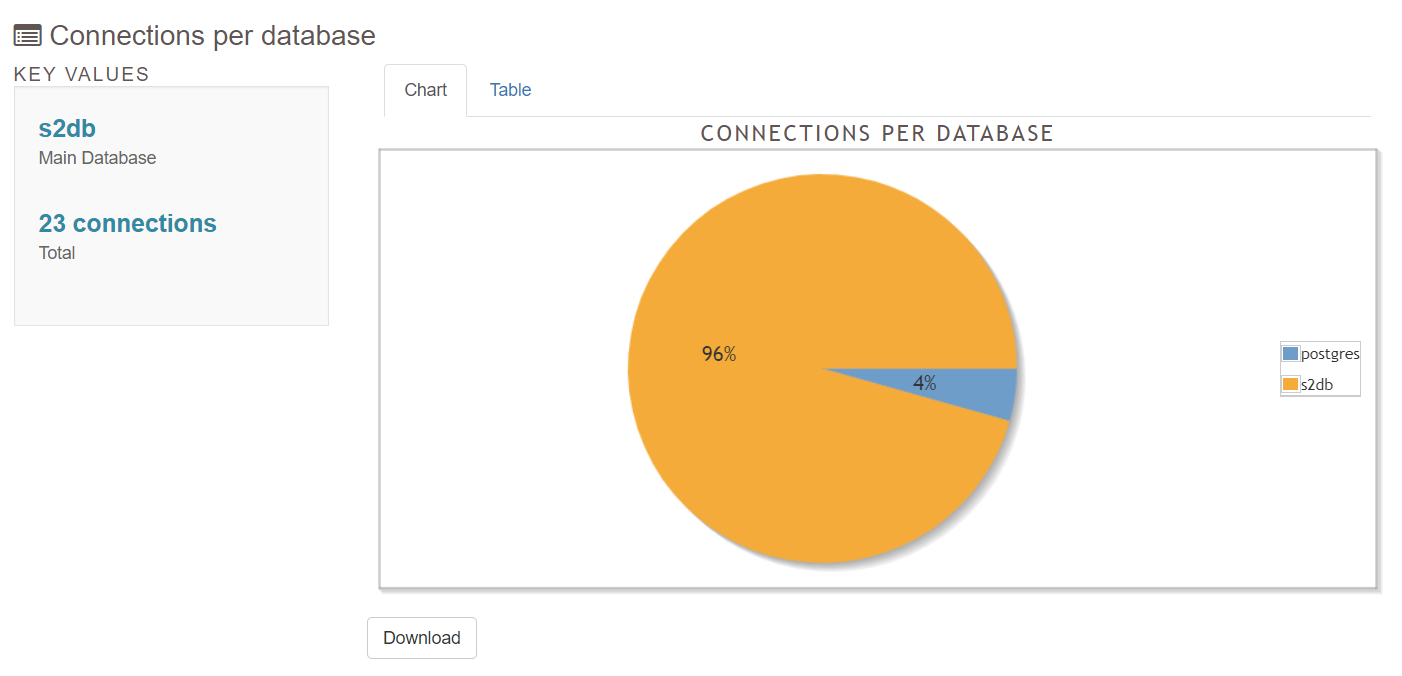
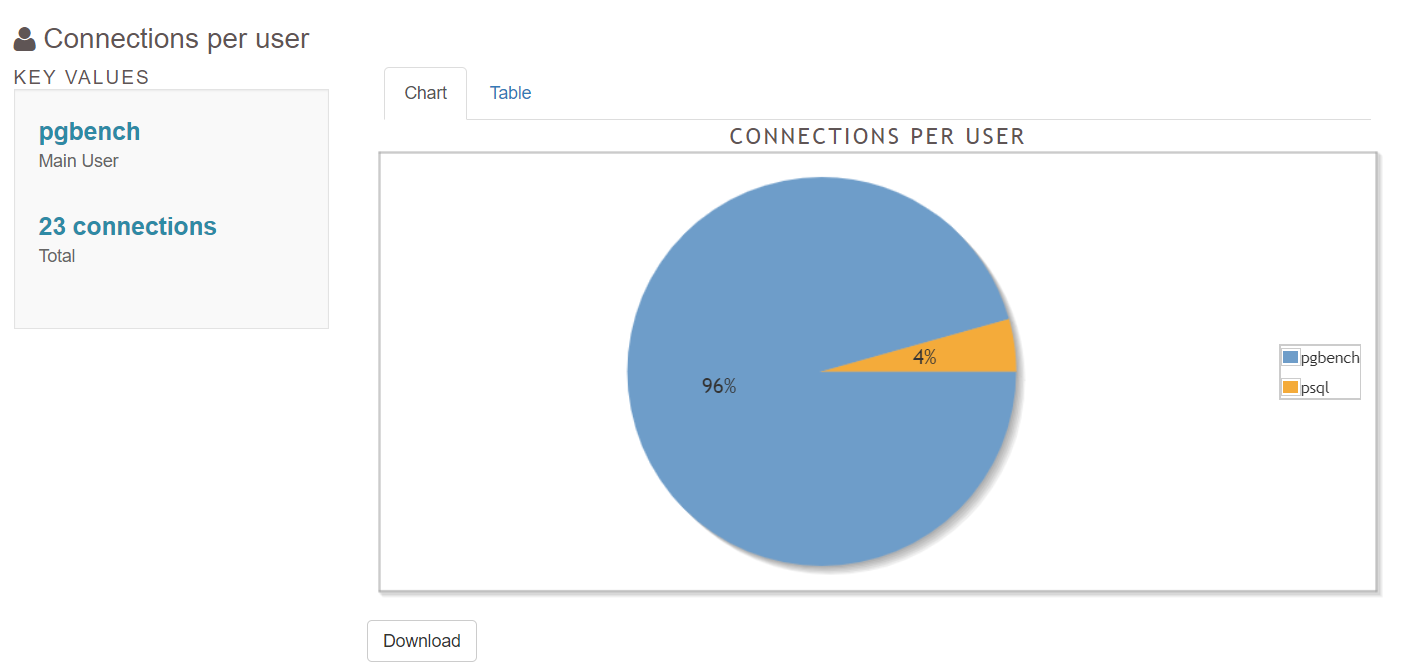
5.3 Checkpoints/Restartpoints
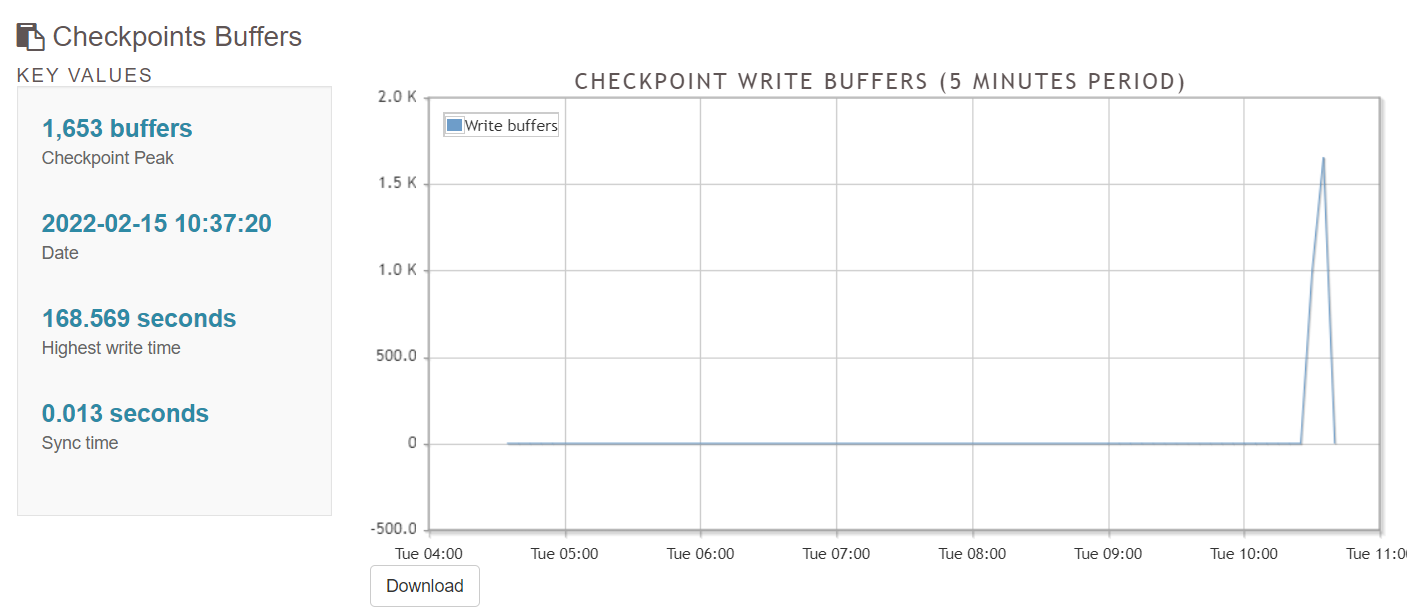

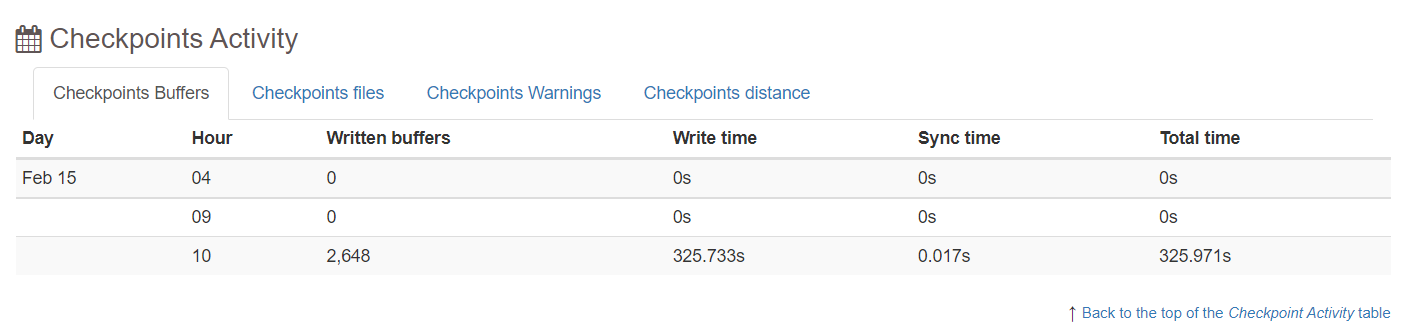
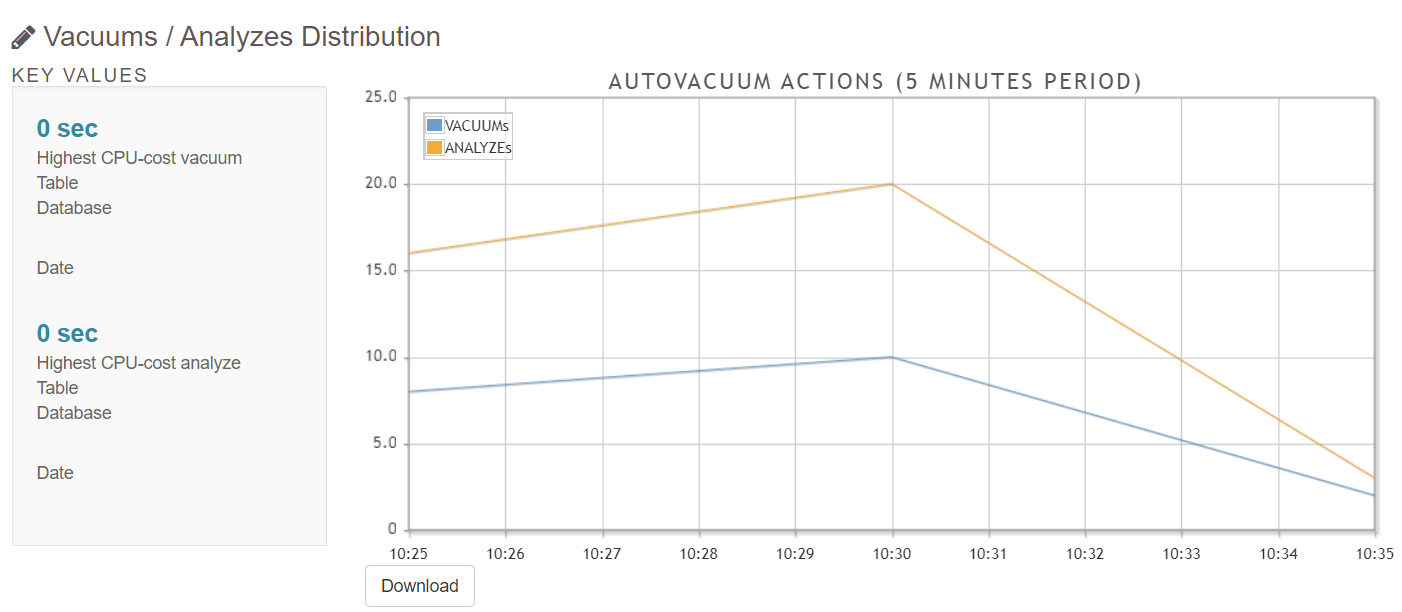
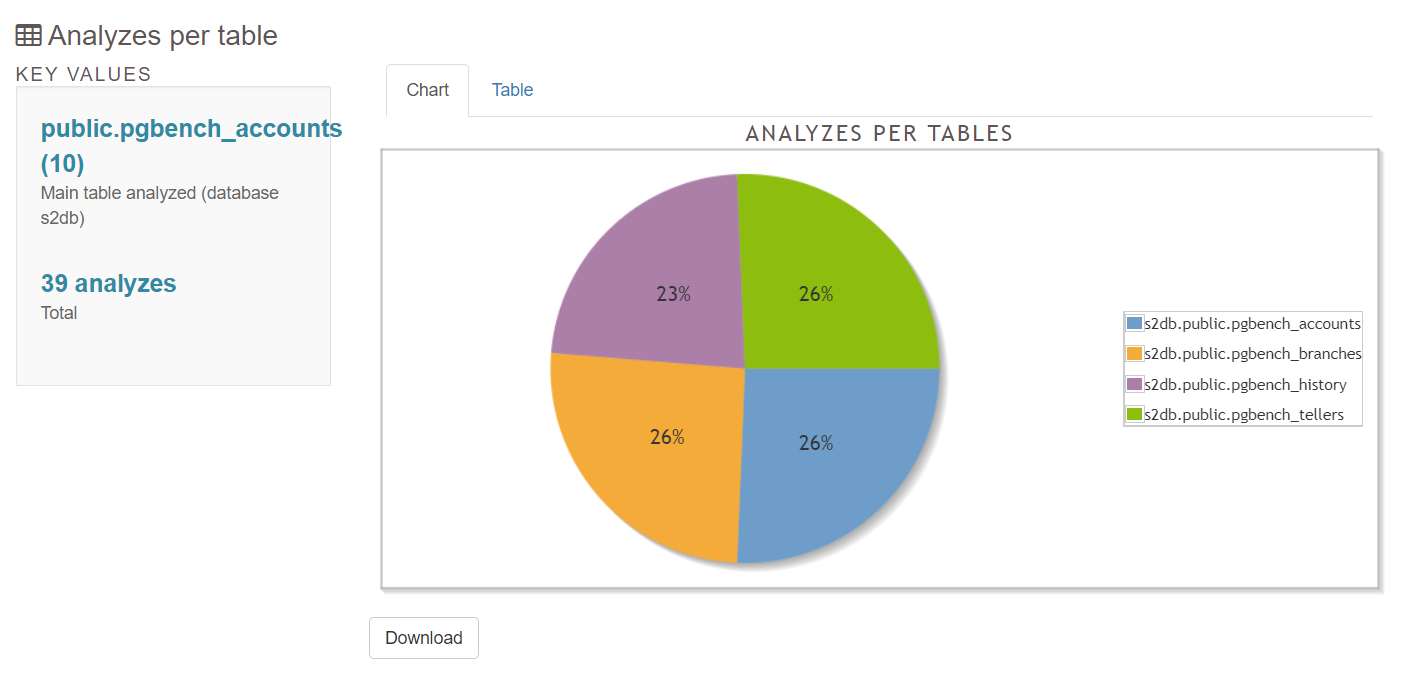
5.4 Vacuums
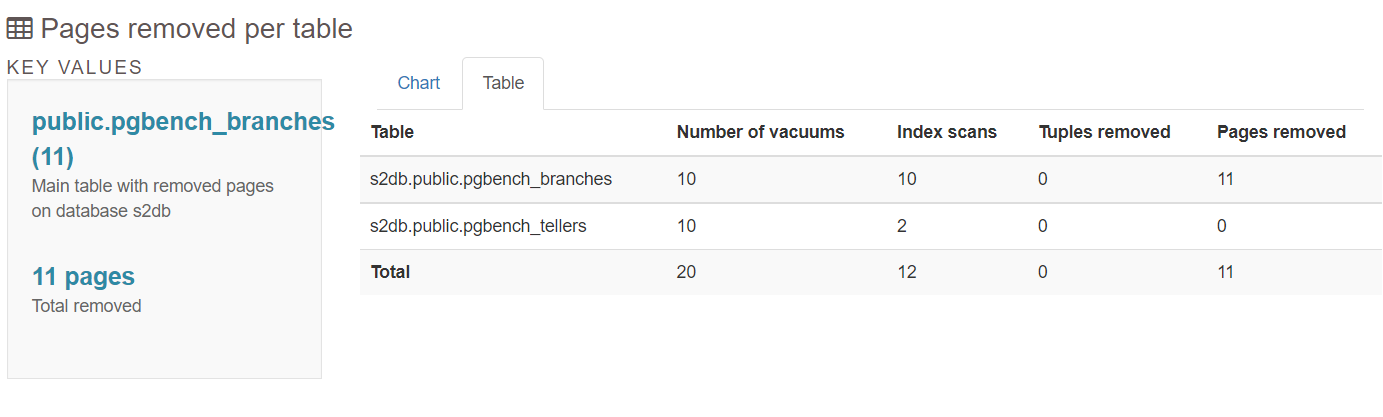
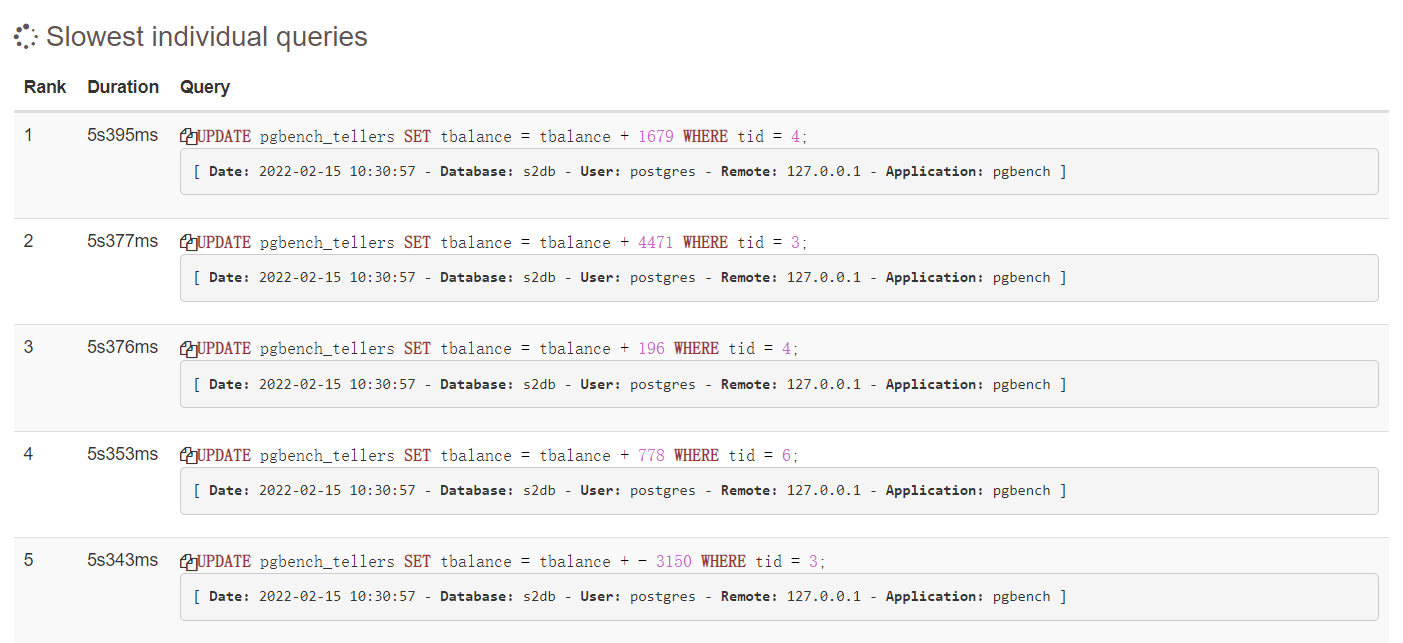
5.5 Top Queies

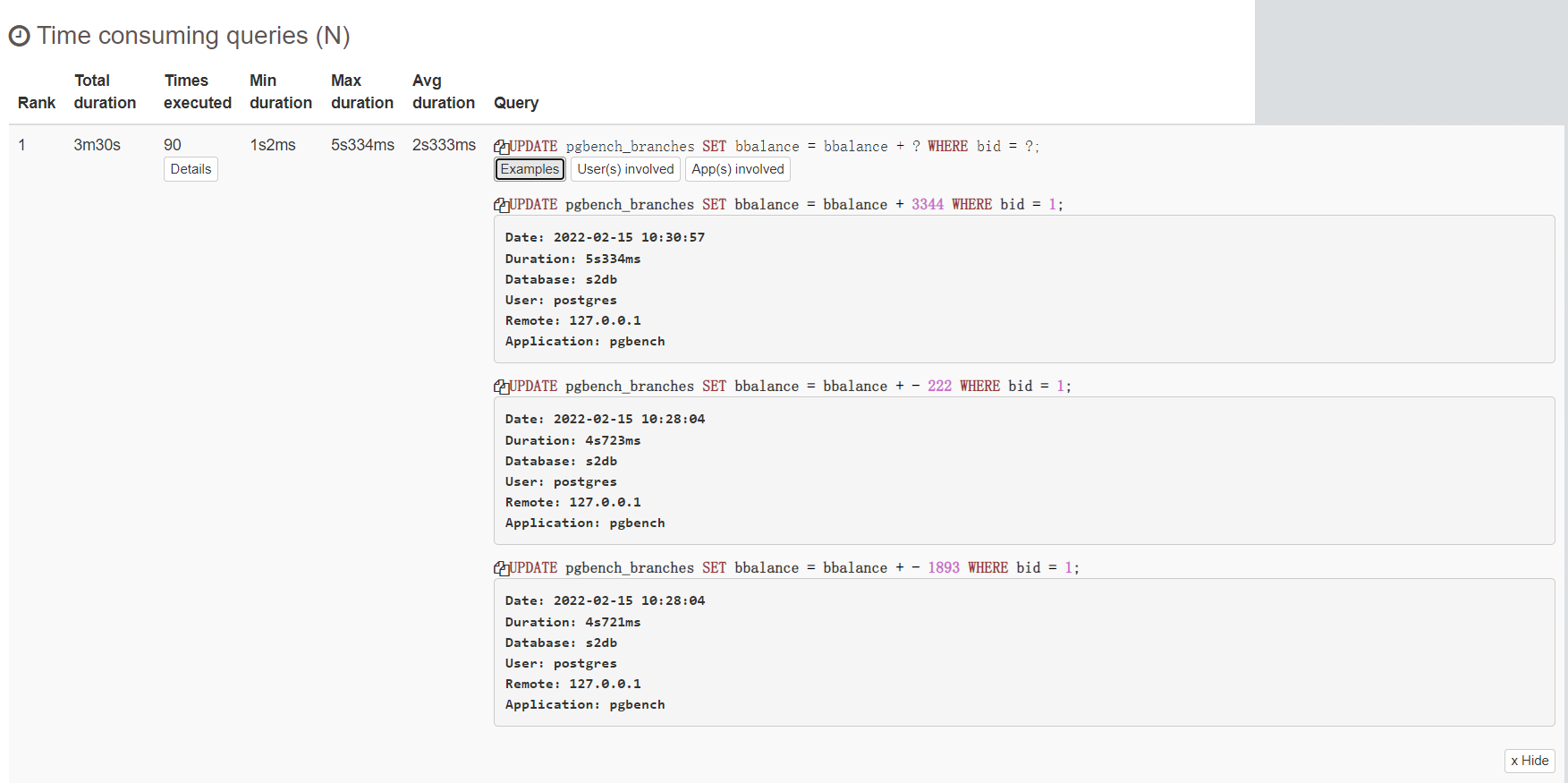
6.问题
6.1 安装支持CSV的组件
perl -MCPAN -e shell
install Text::CSV_XS
#如果没有报错Can’t locate CPAN.pm in @INC
先安装CPAN https://www.ltsplus.com/python/fix-perl-cannot-locate-cpan-pm
yum -y install perl-CPAN
[root@s2ahumysqlpg01 log]# rpm -qa | grep perl-CPAN
perl-CPAN-1.9800-299.el7_9.noarch
#成功将 csv 格式的日志 格式分析成html
\[root@s2ahumysqlpg01 log\]# pgbadger -f stderr postgresql-2022-02-14\_120324.csv -o abc.html
\[========================>\] Parsed 111864 bytes of 111864 (100.00%), queries: 0, events: 0
LOG: Ok, generating html report...
6.2 本文pdf和 html下载
下载连接 : https://www.modb.pro/download/432889
7.参考连接:
https://github.com/darold/pgbadger
https://pgbadger.darold.net/documentation.html
https://severalnines.com/database-blog/postgresql-log-analysis-pgbadger
https://www.postgresql.org/message-id/CAPgXFMRPhFF%2BRyTYsY0gbkz7Szyb18UUHmjYJN0u%3Dk3A8BxVRw%40mail.gmail.com
https://www.ltsplus.com/python/fix-perl-cannot-locate-cpan-pm
