





Kibana是一个开源的分析和可视化平台,是专门设计用来为ES工作。可以使用Kibana搜索、查看,并与存储在ES的数据进行交互。同时Kibana可以轻松地做出数据分析,并且能将数据可视化,做成多种图表和地图。
Kibana使得分析理解大量数据变得更为容易。它是基于浏览器的界面,可以快速创建和共享一个实时显示ES查询数据的动态仪表板。
Kibana 4正式版2015年发布。从新特性来说,Kibana4 全面支持 Aggregation 接口,还有更多的可视化选择,以及对页面请求的内部排队机制。
从页面设计来说,Kibana4 参考了 Splunk 的产品形态,将功能拆分成了搜索(discover),可视化(visualize)和仪表板(dashboard)三个标签页。可视化和搜索,是一一绑定的,无法跨多个 index pattern 做搜索。而且可视化标签页中,用 d3.js 实现的可视化构建器,与请求 ES 数据的聚合选择器,又是各自独立的插件。也就是说,Kibana4 在使用Aggregation 接口提供更复杂功能和更高性能的同时,彻底改变了用户的使用形式。
用户必须明确了解 ES 各个 aggs 接口的意义,请求和响应体的数据情况;还要想清楚可视化的展现形式,充分理解数据字段的作用;然后才能实现想要的结果。
在界面美观方面,Kibana4 至今未提供类似 Kibana3 中的 Query 设置功能,包括 Query 别名和颜色选择器这两个常用功能都没有。直接导致目前 Kibana4 的图例几乎毫无作用。在 filter 方面,Kibana4 用 filter agg 替代了 Kibana3 使用的 facet_filter。
页面表现形式上,Kibana3 是在页面顶部添加 Query 输入框,全局生效;Kibana4 是在 Visualize 页添加 aggs,单个面板生效。依然需要多查询条件对比的用户,需要一个个面板创建。此外,Kibana4.x版本没有自己的web接口,其使用elasticsearch的REST API。
Kibana的安装配置
从官网上下载适用于自己平台的kibana安装包,这里以kibana-4.5.0-linux-x64.tar.gz为例。(注意:其应与elasticsearch的版本匹配,在官网下载页面有说明, Kibana 4.5.x 匹配 Elasticsearch 2.3.x版本)。
将其安装在/usr/local目录下:
tar zxvf kibana-4.5.0-linux-x64.tar.gz –C /usr/local
默认情况下,Kibana 会连接运行在localhost的 Elasticsearch。要通过ip连接 Elasticsearch或者要从外部浏览器访问kibana,修改kibana.yml里的 Elasticsearch URL,然后重启 Kibana。
进入安装目录下:
vim config/kibana.yml
找到elasticsearch.url: localhost:9200,将#号去掉并修改为自己ip:
elasticsearch.url: "ip:9200"
这样在浏览器上输入ip:5601就可以访问kibana。需注意:先把elasticsearch启动起来再启动kibana。
Setting介绍及基本操作
在setting中有几个标签: Indices、Advanced、Objects、Status、About。其中About显示kibana的版本,其他标签在下面一一介绍。
Indices介绍
创建一个索引模式,默认索引包含基本的时间事件,指定输入一个能匹配Elasticsearch 索引名的索引模式。Kibana 会默认假设是要处理 Logstash 导入的数据。在Time-field name一栏中默认选择@timestamp。点击create,就完成创建。
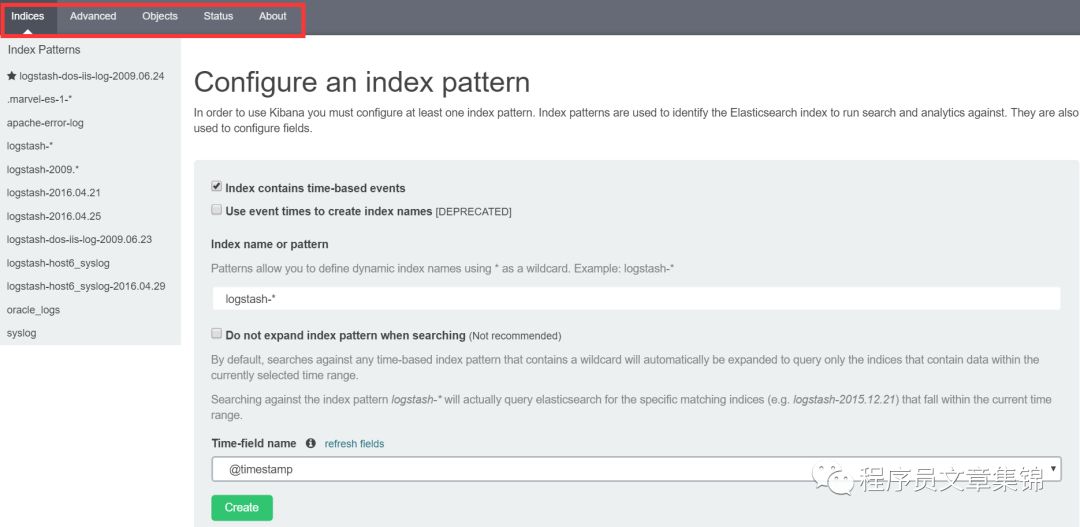
setting的indices标签
页面会弹出一个新的界面,显示索引数据的字段。点击星号,可将其设为默认的索引;点击刷新符号,将索引数据的字段刷新重新载入kibana。需注意:一般创建好索引之后都需刷新一下字段,防止在discover页面不能识别字段名。
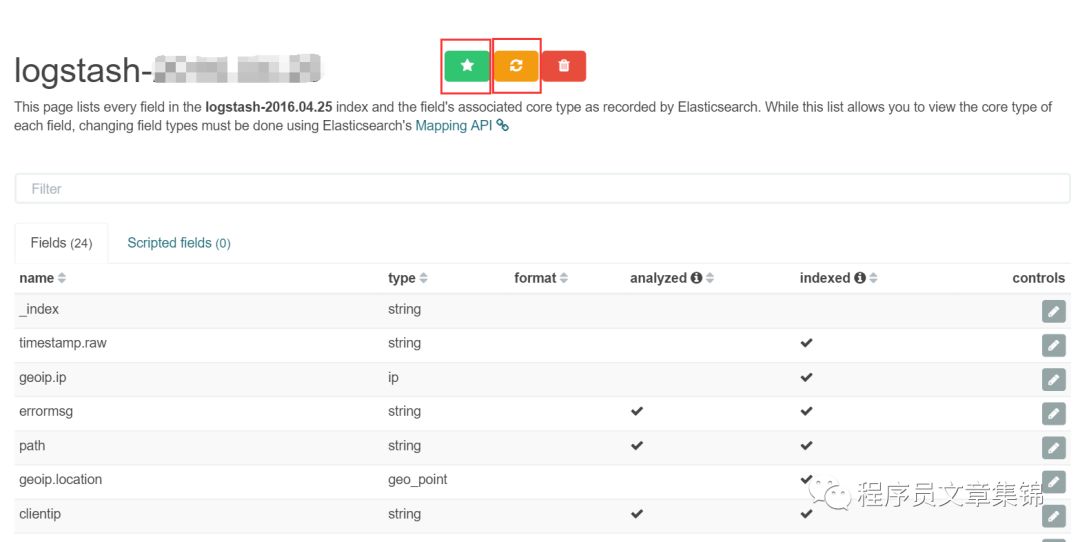
索引数据的字段显示
其中,Fields中显示的是elasticsearch已聚合好的字段,即默认的字段。在Scripted fields中可自定义添加字段,该字段仅仅用作可视化作图的辅助功能,实际上不对数据进行修改。例如,在visualize图中设置一条静态的阈值线,可点击Scripted fields下的add添加一个字段,会弹出一个配置界面,自定义name、Format、Script值,
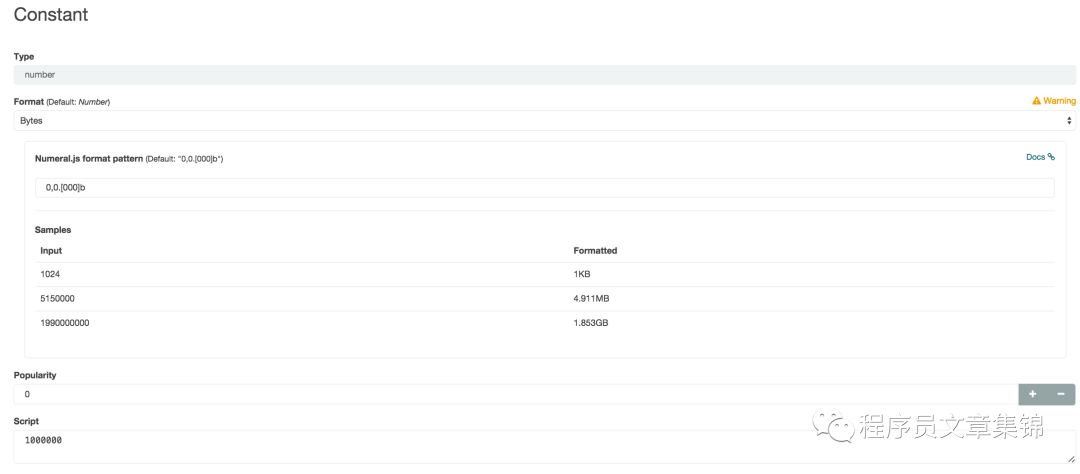
Scripted fields添加字段界面
点击create field可完成创建。在visualize中可添加字段name显示,阈值线效果如图所示。
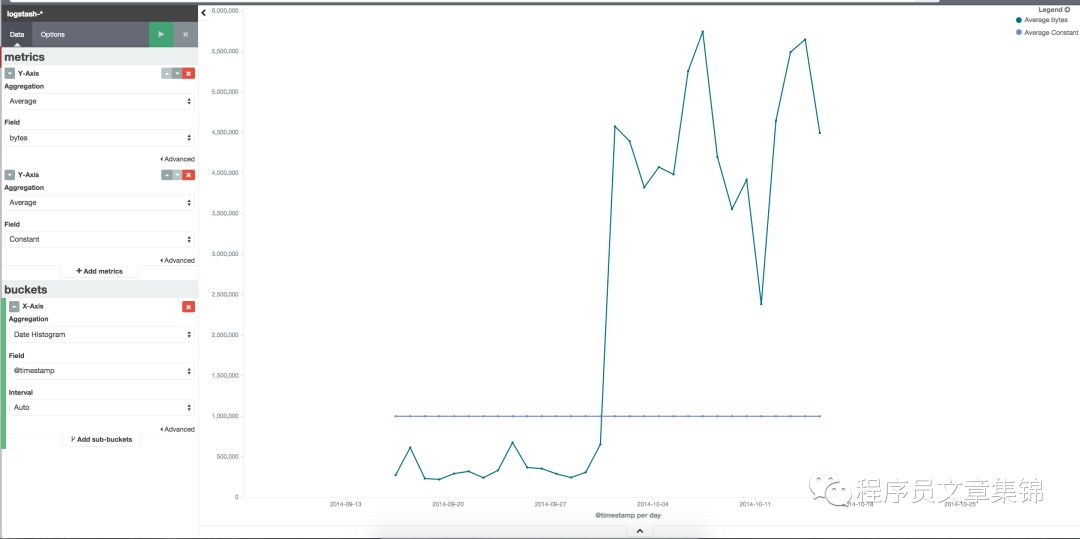
阈值线效果图
Status介绍
status中显示kibana所有状态信息,也包括插件信息。Green表示健康,Yellow和Red分别表示警告和不良,需要通过显示的信息查找问题。例如,elasticsearch未开启,就会Yellow报警。
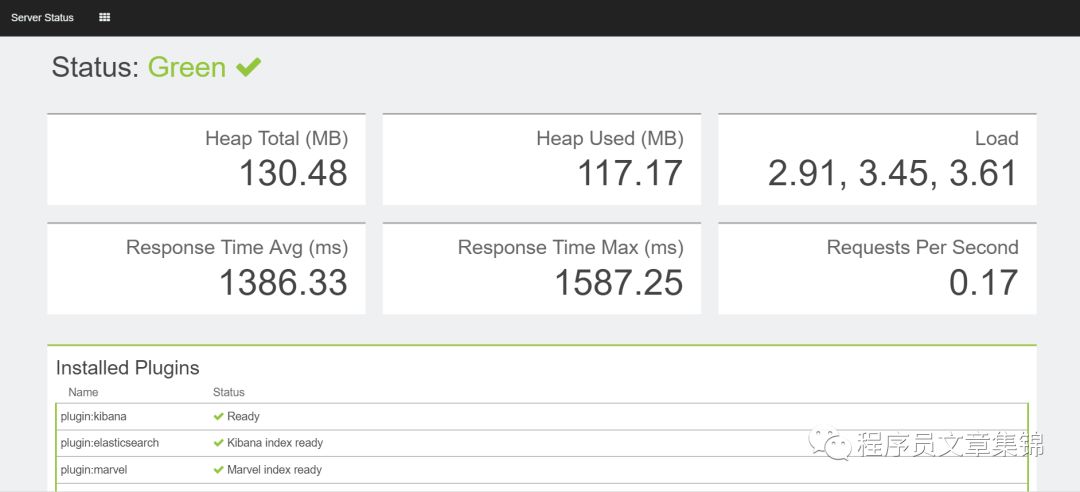
kibana的status界面
Objects介绍
Objects 标签可以查看,编辑,和删除已保存的搜索,可视化和仪表板。点击查看按钮,可查看一个已保存的对象,并会显示在 Discover, Visualize 或 Dashboard页里已选择的项目。
当编辑一个已保存的对象时,进入 Objects,选择编辑已保存的对象,点击 Edit 按钮,修改对象定义。在这个标签中还能修改对象的名字,添加一段说明,以及修改定义这个对象的属性的 JSON。如果要访问一个对象,而它关联的索引已经被删除了,Kibana 会显示这个对象的编辑(Edit Object)页。可以操作:
1重建索引这样就可以继续用这个对象。
2删除对象,然后用另一个索引重建对象。
在对象的 kibanaSavedObjectMeta.searchSourceJSON 里修改引用的索引名,指向一个还存在的索引模式。这个在索引被重命名了的情况下非常有用。对象属性没有验证机制,提交一个无效的变更会导致对象不可用。通常来说,还是应该用 Discover, Visualize 或 Dashboard 页面来创建新对象而不是直接编辑已存在的对象。
当删除一个已保存的对象时,点击 Delete 按钮,选择要删除的对象。
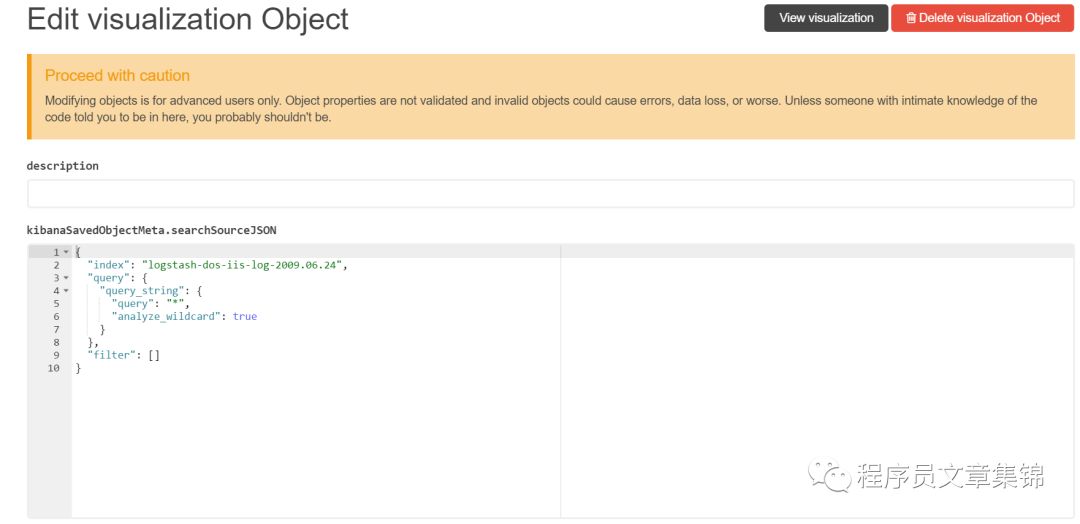
编辑Object界面
Advanced介绍
advanced页(高级参数页)允许直接编辑那些控制着 Kibana 应用行为的设置。比如,可以修改显示日期的格式,修改默认的索引模式,设置十进制数值的显示精度。
修改高级参数可能带来意想不到的后果。如果你不确定自己在做什么,最好离开这个设置页面。要设置高级参数:点击要修改的选项的 Edit 按钮,给这个选项输入一个新的值,点击 Save 按钮。
Discover介绍及操作
Discover 标签页用于交互式探索你的数据。在setting中配置索引模式后,打开 Kibana4 会出现在一个叫做 Discover 的标签页,可以提交搜索请求,过滤结果,然后检查返回的文档里的数据。
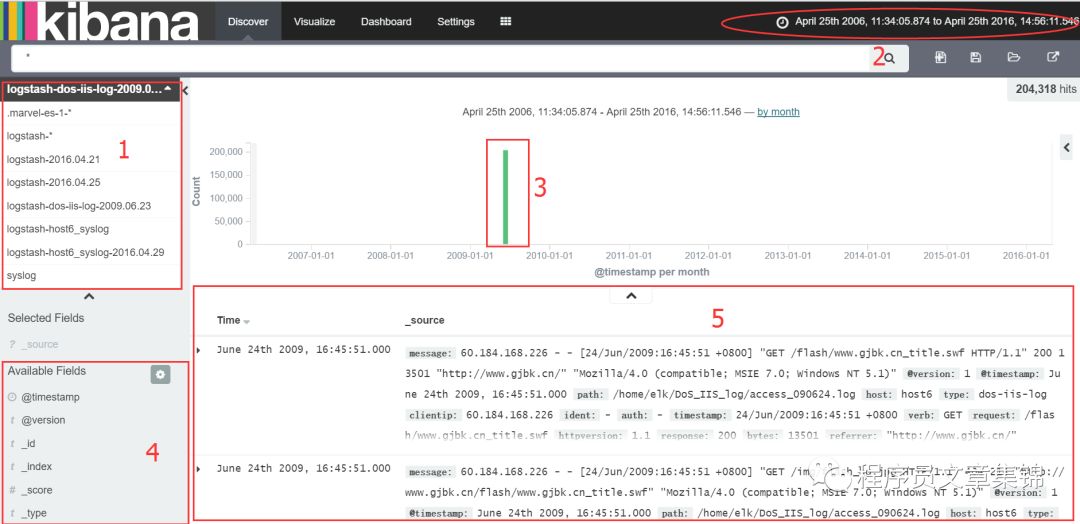
discover界面
第1部分为选择已创建好的索引名,所有在setting中创建的索引模式在该部分都能查询,选择目标索引名。
第2部分为时间过滤器(Time Filter):可限制搜索结果在一个特定的时间周期内。如果索引包含的是时序语句,而且已经为所选的索引模式配置了时间字段,那么就可以设置时间过滤器。默认的时间过滤器设置为最近 15 分钟。可以用页面顶部的时间选择器(Time Picker)来修改时间过滤器,或者选择一个特定的时间间隔,或者直方图的时间范围。要用时间选择器来修改时间过滤器:
1若要指定相对时间过滤,点击 Relative 然后输入一个相对的开始时间。可以是任意数字的秒、分、小时、天、月甚至年之前。
2若要指定绝对时间过滤,点击 Absolute 然后在 From 框内输入开始日期,To 框内输入结束日期。
3点击Go执行,点击时间选择器底部的箭头隐藏选择器。
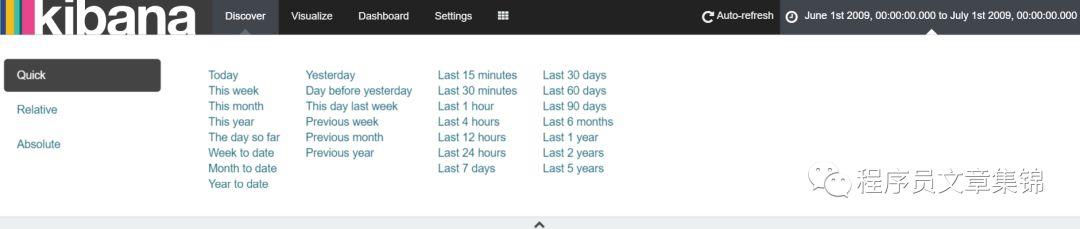
时间过滤器
同时会发现在此处有个标签。它可以配置一个刷新间隔来自动刷新 Discover 页面的最新索引数据。若要想自动刷新数据,点击Auto-refresh按钮然后选择一个自动刷新间隔,自动刷新会在后面章节做详细介绍

自动刷新设置
第3部分为目标索引的数据,可用合适的时间度量显示。若要从图上设置时间过滤器,有以下两种方式:
1若想要放大那个时间间隔,点击对应的柱体。
2单击并拖拽一个时间区域。注意需要等到光标变成加号,才意味着这是一个有效的起始点。
第4部分为目标索引数据的字段列表。可以从字段列表或者文档表格里添加过滤器。
若要从字段列表添加过滤器,可通过以下步骤:
1点击要过滤的字段名。会显示这个字段的前 5 名数据。每个数据的右侧,有两个小按钮一个用来添加常规(正向)过滤器,一个用来添加反向过滤器。
2若要添加正向过滤器,点击 Positive Filter 按钮 。这个会过滤掉在本字段不包含这个数据的文档。
3若要添加反向过滤器,点击 Negative Filter 按钮 。这个会过滤掉在本字段包含这个数据的文档。
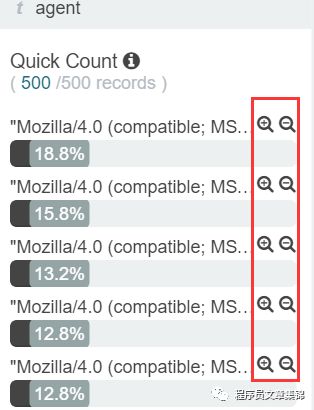
字段列表添加过滤器
若要从文档表格添加过滤器,可通过以下步骤:
1点击表格第一列(通常都是时间)文档内容左侧的 Expand 按钮 , 展开文档表格中的文档。每个字段名的右侧,有两个小按钮,一个用来添加常规(正向)过滤器,一个用来添加反向过滤器。
2若要添加正向过滤器,点击 Positive Filter 按钮 。这个会过滤掉在本字段不包含这个数据的文档。
3若要添加反向过滤器,点击 Negative Filter 按钮 。这个会过滤掉在本字段包含这个数据的文档。
文档数据表格
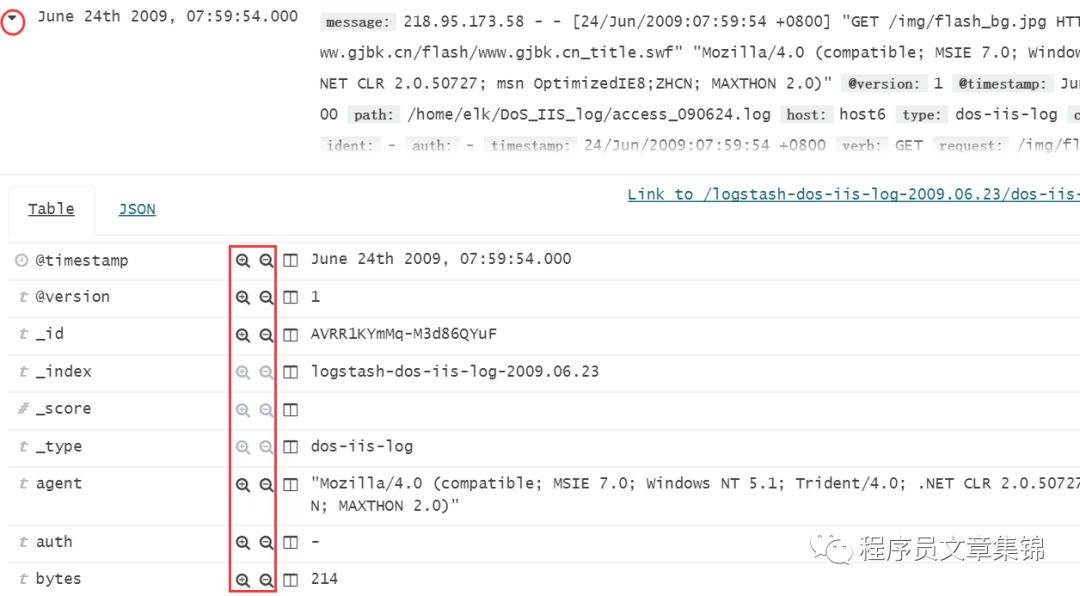
第5部分为目标索引数据的详细信息。可以在上方的搜索栏里输入要搜索的目标信息。当提交一个搜索请求后,最近的 500 个搜索结果会显示在文档表格里。可以在 Advanced Settings 里通过 discover:sampleSize 属性配置表格里具体的文档数量。表格会默认显示当前选择的索引模式中定义的时间字段内容(转换成本地时区)以及 _source 文档。可以从字段列表添加字段到文档表格。还可以用表格里包含的任意已建索引的字段来排序列出的文档。
要查看一个文档的字段数据,点击表格第一列(通常都是时间)文档内容左侧的 Expand 按钮 。Kibana 从 Elasticsearch 读取数据然后在表格中显示文档字段。
文档表格会默认显示当前选择的索引模式中定义的时间字段内容(转换成本地时区)以及_source文档。可以从字段列表添加字段到文档表格。
要添加字段列到文档表格,具体操作:
1移动鼠标到字段列表的字段上,点击它的add按钮。
2重复操作直到你添加完所有你想移除的字段。
添加的字段会替换掉文档表格里的 _source 列。同时还会显示在字段列表顶部的 Selected Fields 区域里。
如果要重新对表格中的字段列进行左右排序,则需要移动鼠标到目标字段列的顶部,点击移动按钮或。

添加字段到文档表格
Visualize介绍及操作
Visualize 标签页用来对索引数据设计可视化的图表。在此标签中,可保存可视化图表,方便加载合并到dashboard面板里。点击visualize标签创建一个新的可视化标签,可选的有Area chart(区块图)、Data table(数据表)、Line chart(折线图)、Metric(计算器)、Pie chart(饼图)、Tile map(地理位置)、Vertical bar chart(直方图)。
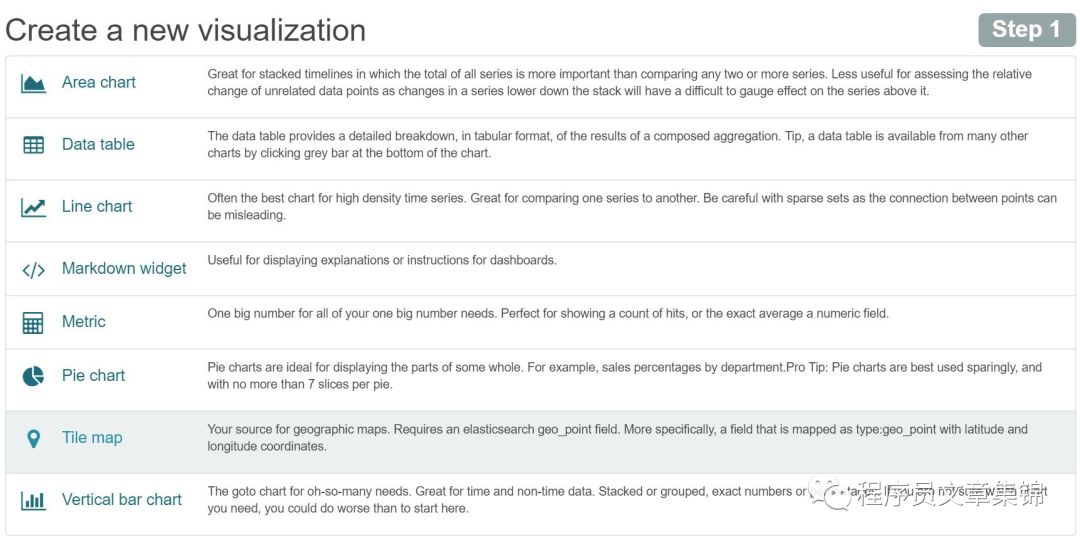
创建可视化标签step1

创建可视化标签step2
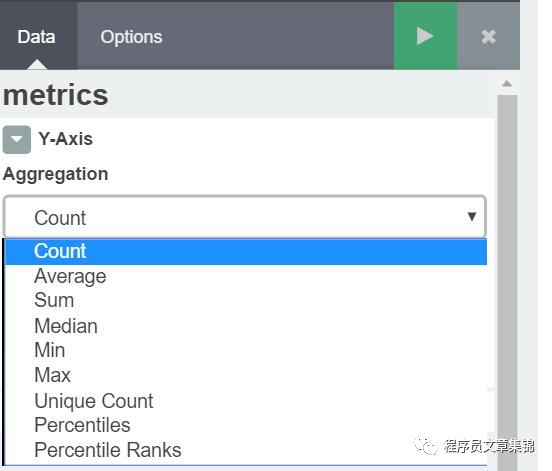
Y轴:数值维度
Y 轴是数值维度。该维度有以下聚合可用:
l Count count聚合返回选中索引模式中元素的原始计数。
l Average 这个聚合返回一个数值字段的average。从下拉菜单选择一个字段。
l Sum sum聚合返回一个数值字段的总和。从下拉菜单选择一个字段。
l Min min聚合返回一个数值字段的最小值。从下拉菜单选择一个字段。
l Max max聚合返回一个数值字段的最大值。从下拉菜单选择一个字段。
l Unique Count cardinality聚合返回一个字段的去重数据值。从下拉菜单选择一个字段。
l Standard Deviation extended stats聚合返回一个数值字段数据的标准差。从下拉菜单选择一个字段。
l Percentile percentile聚合返回一个数值字段中值的百分比分布。从下拉菜单选择一个字段,然后在Percentiles框内指定范围。点击X移除一个百分比框,点击+Add添加一个百分比框。
l Percentile Rank percentile ranks聚合返回一个数值字段中指定值的百分位排名。从下拉菜单选择一个字段,然后在Values框内指定一到多个百分位排名值。点击X移除一个百分比框,点击+Add添加一个数值框。
可以点击+ Add Aggregation按键添加一个聚合。
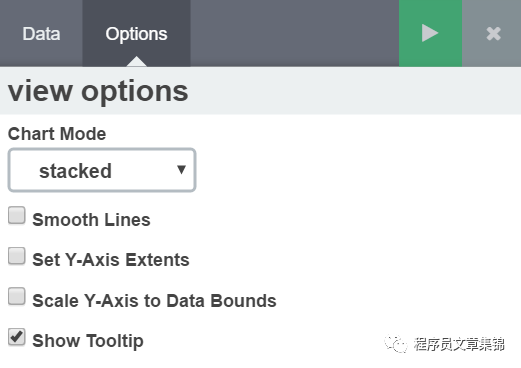
view options图
选择 options 更改其中的配置信息。
Chart Mode 是指当图形定义了多个 Y 轴时,可以用该下拉菜单定义聚合如何显示在图形上:
l stacked 聚合结果依次叠加在顶部。
l overlap 聚合结果重叠的地方采用半透明效果。
l wiggle 聚合结果显示成 streamgraph 效果。
l percentage 显示每个聚合在总数中的百分值。
l silhouette 显示每个聚合距离中间线的方差。
多选框可以用来控制以下行为:
l Smooth Lines 勾选该项平滑数据点之间的折线成曲线。
l Set Y-Axis Extents 勾选该项,然后在 y-max 和 y-min 框里输入数值限定 Y 轴为指定数值。
l Scale Y-Axis to Data Bounds 默认的 Y 轴长度为 0 到数据集的最大值。勾选该项改变 Y 轴的最大和最小值为数据集的返回值。
l Show Tooltip 勾选该项显示工具栏。
l Show Legend 勾选该项在图形右侧显示图例。
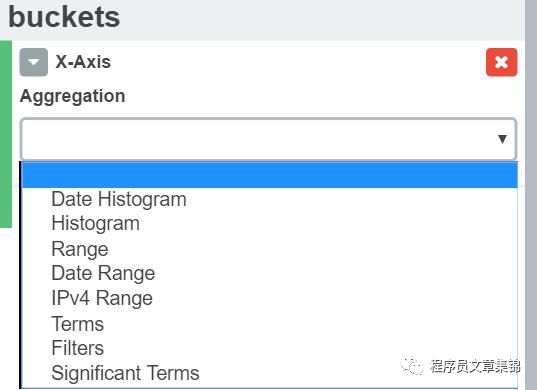
X轴:buckets维度
buckets聚合指明从你的数据集中将要检索什么信息。图形的X 轴表示buckets维度。图形的X 轴支持以下聚合:
l Date Histogram date histogram基于数值字段创建,由时间组织起来。可以指定时间片的间隔,单位包括秒,分,小时,天,星期,月,年。
l Histogram 标准histogram基于数值字段创建。为这个字段指定一个整数间隔。勾选Show empty buckets让直方图中包含空的间隔。
l Range 通过range聚合。可以为一个数值字段指定一系列区间。点击Add Range添加一对区间端点。点击红色 (x)符号移除一个区间。
l Date Range date range聚合计算你指定的时间区间内的值。你可以使用date math表达式指定区间。点击Add Range添加新的区间端点。点击红色(/)符号移除区间。
l IPv4 Range IPv4 range聚合用来指定 IPv4 地址的区间。点击Add Range添加新的区间端点。点击红色(/)符号移除区间。
l Terms terms聚合允许你指定展示一个字段的首尾几个元素,排序方式可以是计数或者其他自定义的metric。
l Filters 你可以为数据指定一组filters。可以用 query string,也可以用 JSON 格式来指定过滤器,就像在 Discover 页的搜索栏里一样。点击Add Filter添加下一个过滤器。
l Significant Terms 展示实验性的significant terms聚合的结果。
必须深入理解以上介绍,根据数据类型,去自定义可视化形。需注意,作图是在setting创建索引模式和discover搜索数据并用合适的时间过滤完成之后,才可以进行的。下面以图解方式来演示各个图表如何去制作,每种类型图都以一种例子来解释。
Area chart(区块图)
目标:作图查看元数据中所有返回状态码。
操作:Y轴一般选择计数;X轴可用时间间隔Data Histogram。然后查看状态码的字段是什么,根据之前的介绍可用terms过滤。在这里选择response.raw字段,可查看排名靠前前5位(可选升序、降序排列)。
需注意:一般我们选择*.raw,这是导入数据时的索引名以logstash开头(logstash-*),才会生成raw字段。若没有这个,会对Visualize造成影响,甚至无法成功得到所需的图表。
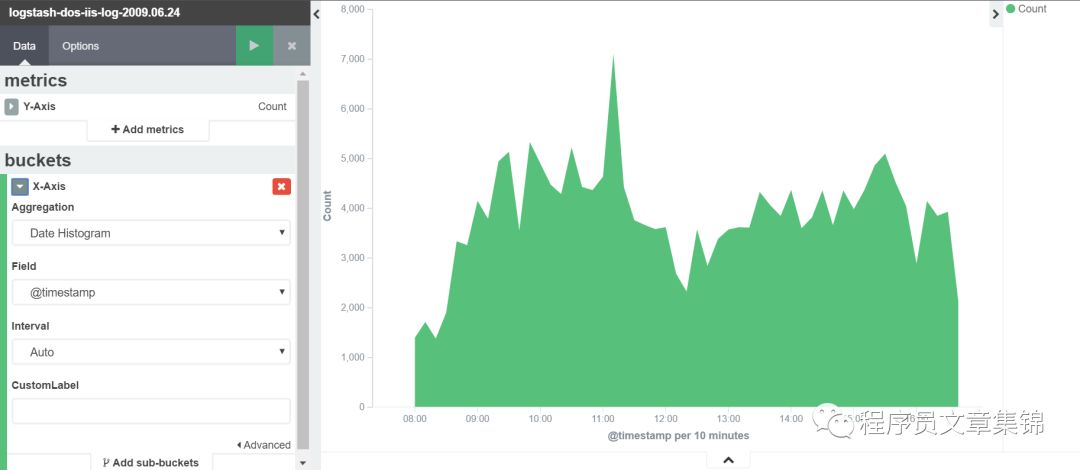
Area chart图解(一)
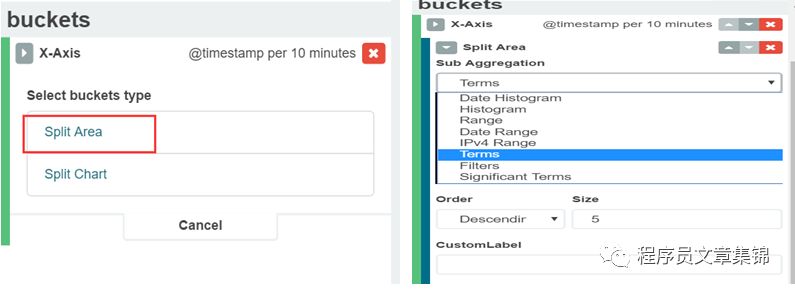
Area chart图解(二)
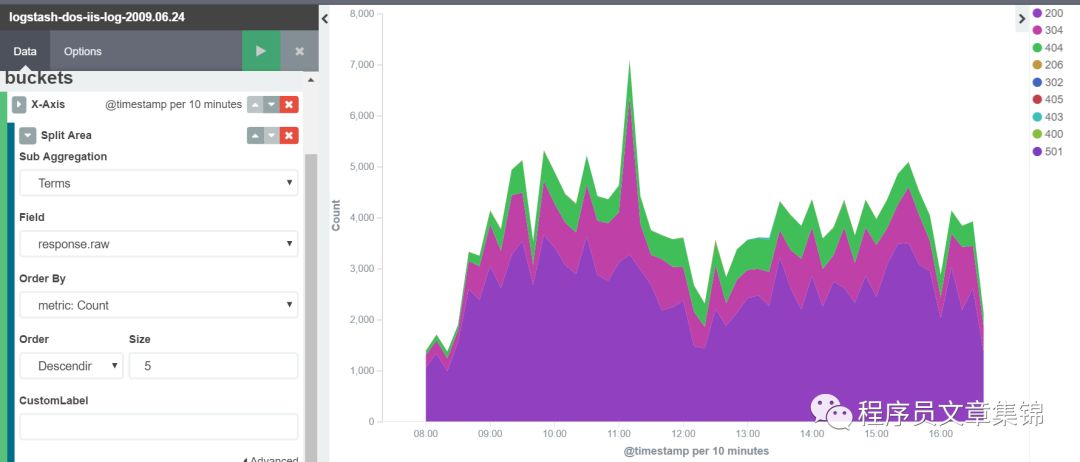
Area chart图解(三)
到此,就得到我们所要的图,点击将定制的可视化标签保存,可以自定义名称(支持汉字)。
Data table(数据表)
目标:作表格筛选元数据中的信息。
操作:metrics显示计数;buckets 可分切割表格成行,点击Add sub-buckets,选择Split Rows可切割行,选择Split Table可切割表。然后筛选所需信息。也可点击Raw和Formatted导出表格。
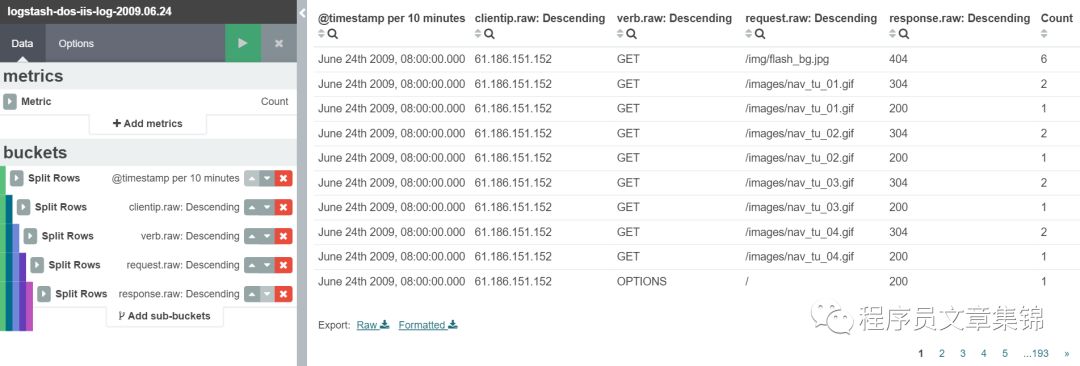
Data table图解(一)
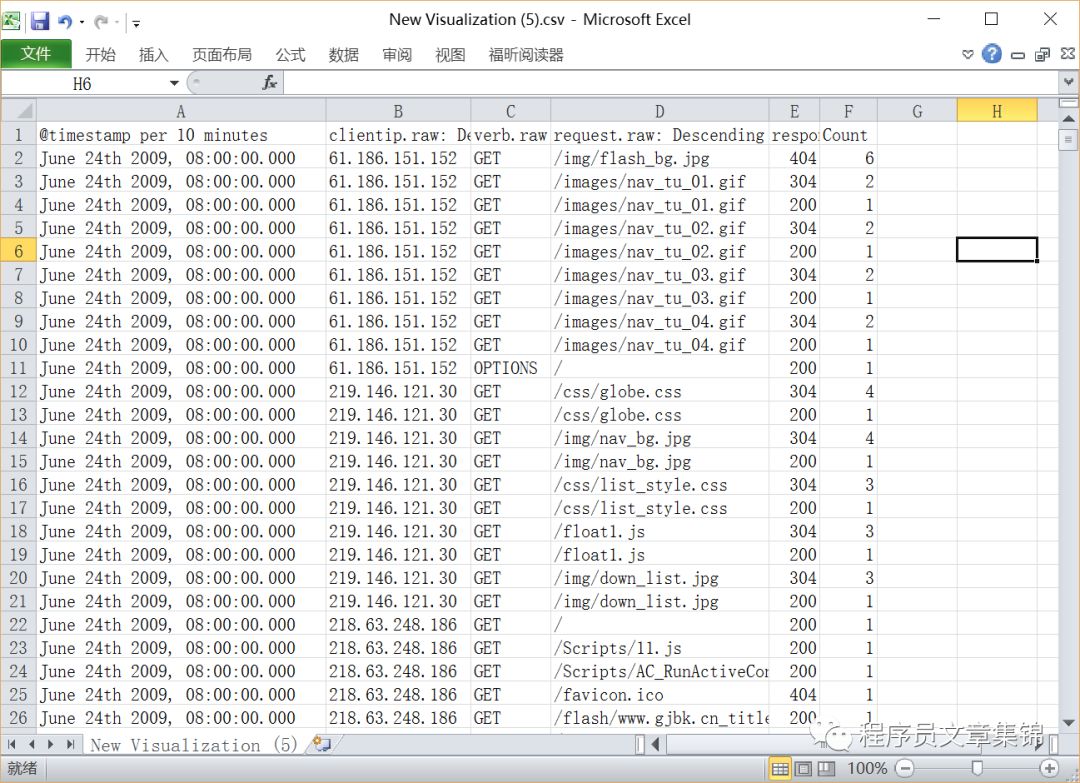
Data table图解(二)
Line chart(折线图)
这个图的Y 轴是数值维度。图形的 X 轴是buckets 维度,可以为 X 轴定义buckets。折线图对各个时间点数据计数;可以用terms筛选所需字段;用filters自定义查看所要信息。
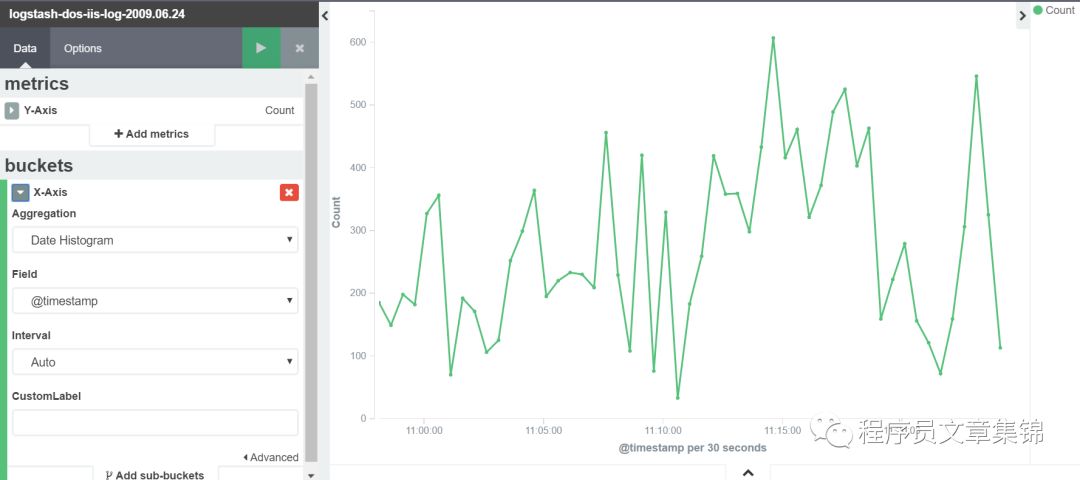
Line chart图解(一)
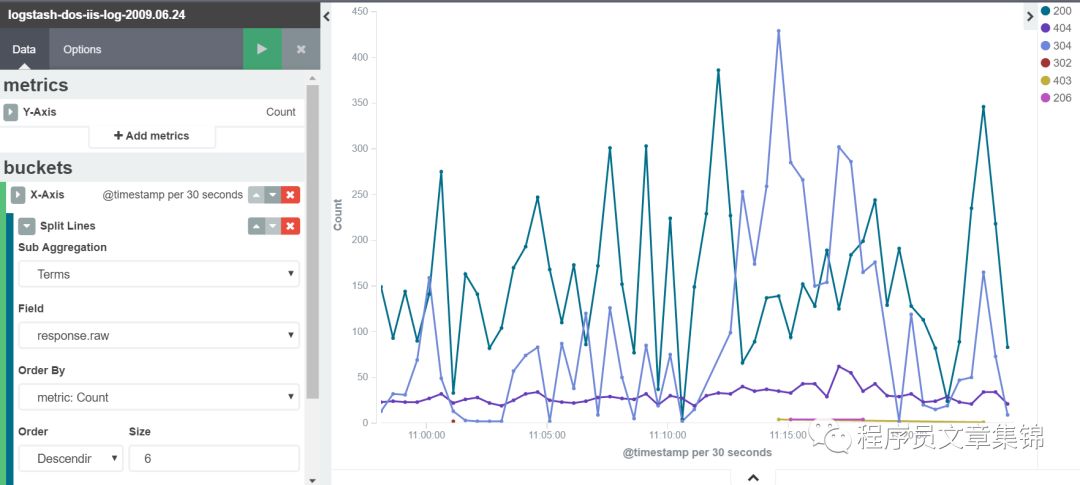
Line chart图解(二)
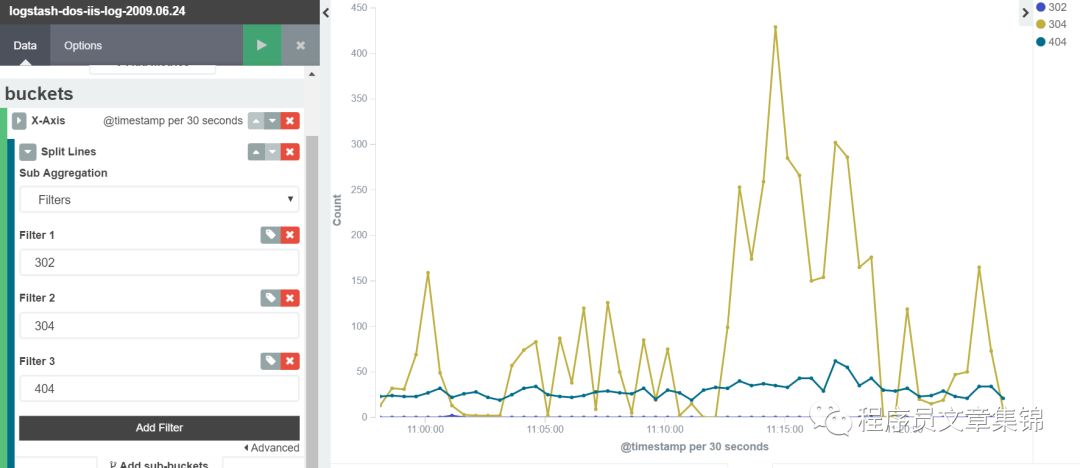
Line chart图解(三)
Metric(计算器)
Metric是对数据做Count、Average、Sum、Min、Max、Unique Count、Standard Deviation 、Percentile计数。
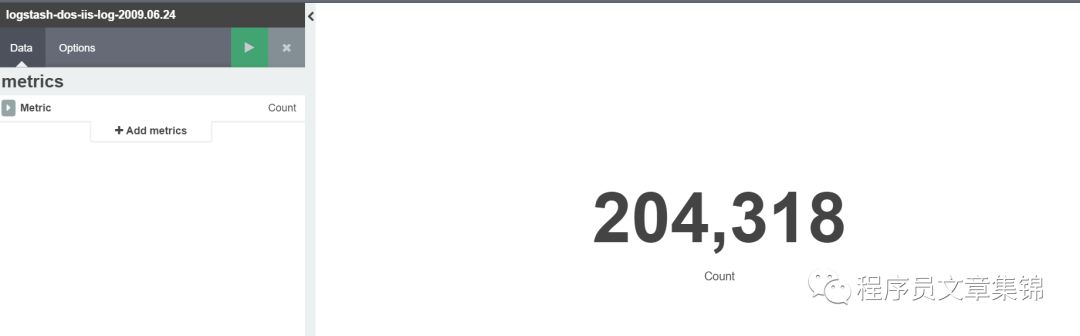
Metric图
Pie chart(饼图)
饼图的分片大小通过 metrics 聚合定义。这个维度可以支持聚合:Count 、Sum 、Unique Count。 buckets 聚合指明从你的数据集中将要检索什么信息。在你选定一个 buckets 聚合之前,先指定你是要切割单个图的分片,还是切割成多个图形。多图切分必须在其他任何聚合之前要运行。如果要切分图形,可以选择切分结果是展示成行还是列的形式,点击 Rows | Columns 选择器即可。
与折线图类似,选择所需的字段进行terms过滤。我们查看clientip中排名靠前的10位。也可以在此基础上继续筛选字段或过滤信息。
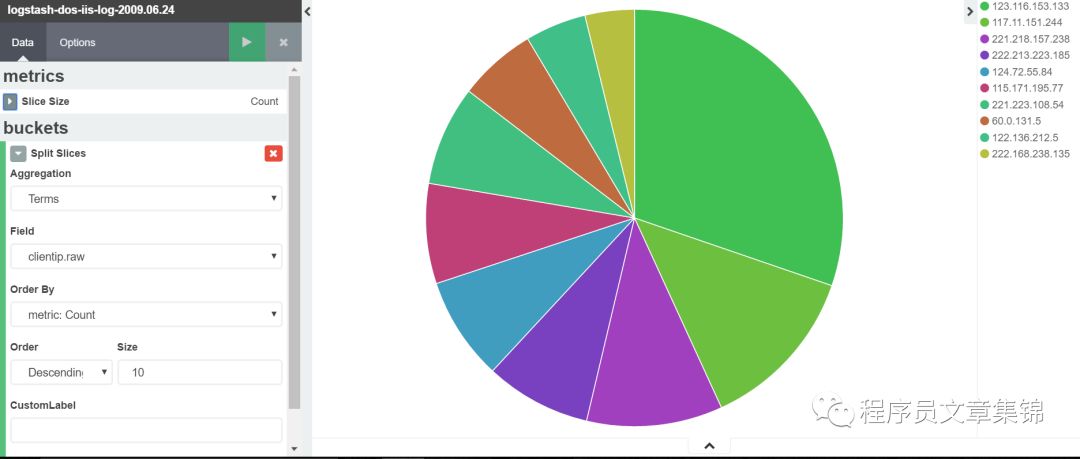
Pie chart图解(一)
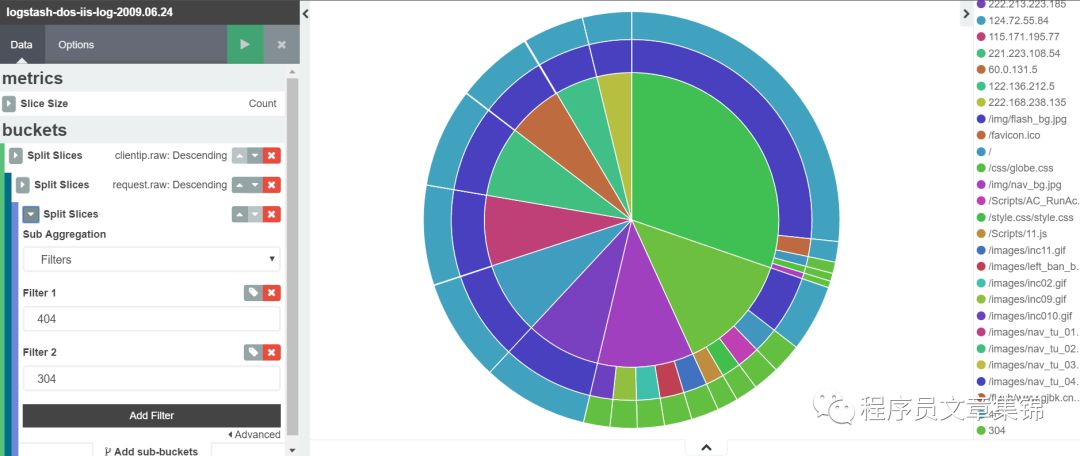
Pie chart图解(二)
Tile map(地理位置)
只有在数据里面有位置信息时,才能用tile map作图。默认 metrics 聚合是 Count 聚合。地图使用 Geohash 聚合作为初始化聚合。从下拉菜单中选择一个坐标字段。Precision 滑动条设置圆圈标记在地图上的显示大小。
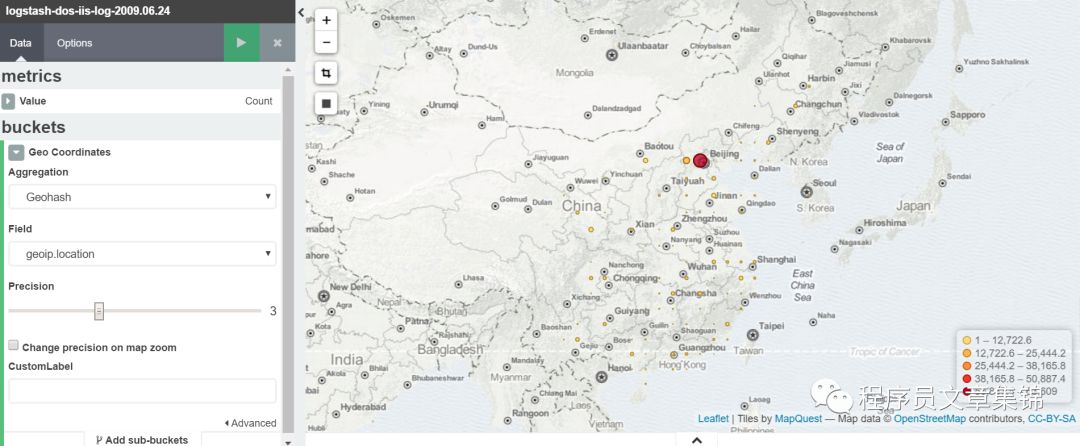
Tile map图
在options中从下拉框选择下面一个选项:
l Shaded Circle Markers 根据 metric 聚合的值显示不同的颜色。
l Scaled Circle Markers 根据 metric 聚合的值显示不同的大小。
l Shaded Geohash Grid 用矩形替换默认的圆形显示 geohash,根据 metric 聚合的值显示不同的颜色。
l Heatmap 热力图可以模糊化圆标而且层叠显示颜色。热力图本身还有如下选项可用:
1Radius: 设置单个热力图点的大小。
2Blur: 设置热力图点的模糊度。
3Maximum zoom: Kibana 的 Tilemap 支持 18 级缩放。该选项设置热力图最大强度下的最高缩放级别。
4Minimum opacity: 设置数据点的不透明截止位置。
5Show Tooltip: 勾选该项,让鼠标放在数据点上时显示该点的数据。
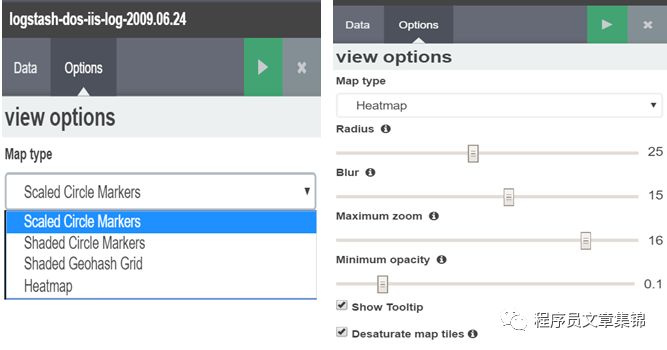
Tile map图
Vertical bar chart(直方图)
1直方图的 Y 轴是数值维度,图形的 X 轴是buckets 维度。类似折线图,可以选择字段用terms、filters等过滤。
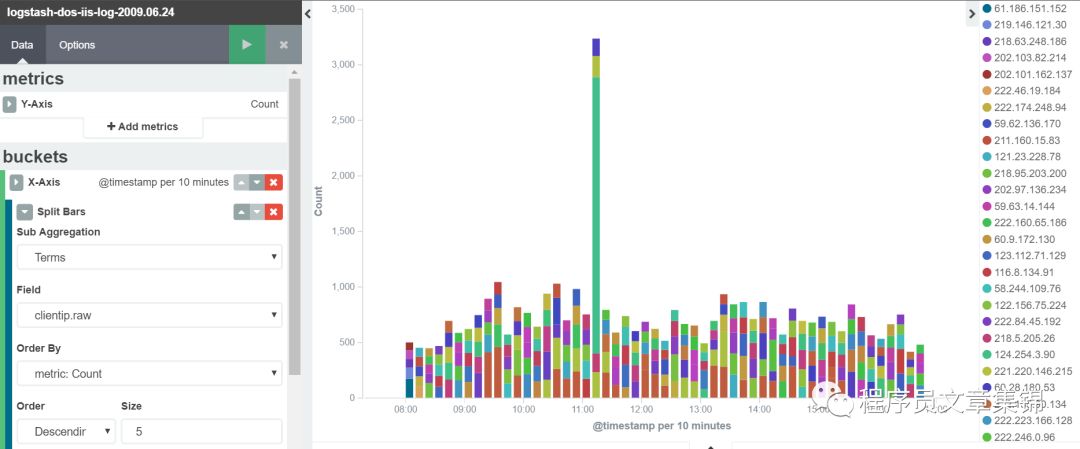
Vertical bar chart图
Dashboard介绍及操作
一个 Kibana的dashboard 能够自由排列一组已保存的可视化图表。然后可以保存这个仪表板,用来分享或者重载。下面开始使用仪表板,需要至少有一个已保存的可视化图表。
创建一个新的仪表板
第一次使用 Dashboard 标签的时候,Kibana 会显示一个空白的仪表板。通过添加可视化的方式来构建你的仪表板。默认情况下,Kibana 仪表板使用明亮风格。如果你想切换成黑色风格点击 Settings 按钮,然后勾选 Use dark theme。
ashboard图
自动刷新页面
设置页面自动刷新的间隔以查看最新索引进来的数据。这个设置会定期提交搜索请求。设置刷新间隔后,它会出现在菜单栏的时间过滤器左侧。
要自动刷新数据,点击 Auto-Refresh 按钮选择自动刷新间隔:

自动刷新
开启自动刷新后,Kibana 顶部菜单栏会显示一个暂停按钮和自动刷新间隔:。点击这个暂停按钮可以暂停自动刷新。
添加可视化到仪表板上
要添加可视化图表到仪表板上,点击工具栏面板上的按钮。从列表中选择一个已保存的可视化。可以在Visualization Filter里输入字符串来过滤想要找的可视化。
选择添加已保存的可视化图表后,它会出现在你仪表板上的一个容器(container)里。如果觉得容器的高度和宽度不合适,可以调整容器大小。
保存仪表板
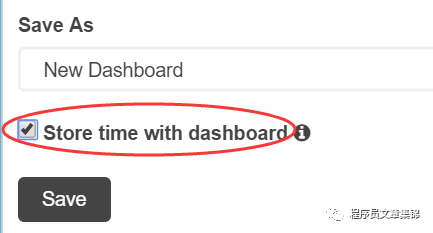
在Dashboard标签页上,将多张保存好的可视化图表的添加在一页上,点击保存,可以自定义一个Dashboard name,同时可选择Store time with dashboard,即将设置好的time filter同图表一起保存,下次打开时无需再手动设置时间过滤,就可以加载上次保存时的图表的时间设置。
保存Dashboard
加载已保存仪表板
点击 Load Saved Dashboard 按钮显示已存在的仪表板列表。已保存仪表板选择器包括了一个文本栏可以通过仪表板的名字做过滤,还有一个链接到 Object Editor 从而管理已保存仪表板。同时也可以直接点击Settings > Edit Saved Objects 来访问 Object Editor。点击容器右上角的Edit按钮在Visualize页打开可视化编辑。
分享仪表板
分享仪表板的功能是将可视化图表分享给其他用户。可以直接分享 Kibana 的仪表板链接,也可以嵌入到你的网页里。点击share按钮,可以看到Embed this dashboard。

Dashboard的share功能
用户必须有 Kibana 的访问权限才能看到嵌入的仪表板。点击 Share 按钮显示 HTML 代码,就可以嵌入仪表板到其他网页里。还带有一个指向仪表板的链接。点击复制按钮可以复制代码,或者链接到你的黏贴板。
查看详细信息
要显示可视化背后的原始数据,点击容器底部的。可视化会被有关原始数据详细信息的几个标签替换掉。底层数据的分页展示。可以通过点击每列顶部的方式给该列数据排序。
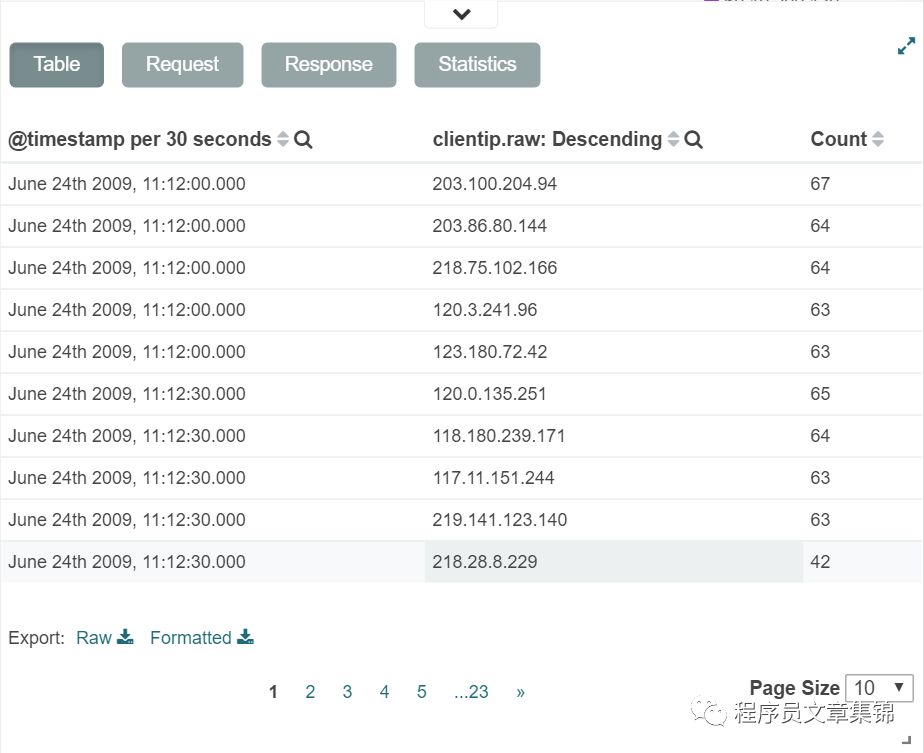
Dashboard面板查看详细信息
现有威胁模型生成
Apache日志记录服务器活动的功能,包括访问日志、错误日志。常用的Apache日志返回码含义有:200(OK,交易成功),404(Not Found,没有发现文件、查询或URl),304( Not Modified,客户端已经执行了GET,但文件未变化 ),302(Found,在其他地址发现了请求数据).
DoS和DDos攻击都是破坏网络服务的方式,使得受害主机或网络无法及时接收并处理外界请求。表现在大流量、ip洪流访问主机,造成资源浪费,从而导致主机瘫痪。从IIS日志中分析DoS和DDoS攻击,一般表现在某ip出现频率较高。
syslog常被成为系统日志或系统记录。系统日志消息中有标准格式的消息(称为系统日志消息、系统错误消息或简单系统消息),也有从调试命令输出的消息。每个syslog消息中都包含一个严重级别和一个特性。
很多网络设备都支持syslog,其中包括路由器、交换机、应用服务器、防火墙和其他网络设备。
SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。具体来说,它是利用现有应用程序,将(恶意)的SQL命令注入到后台数据库引擎执行的能力,它可以通过在Web表单中输入(恶意)SQL语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行SQL语句。
Apache_error_log模型
第一步:在logstash成功将apache错误日志导入elasticsearch后,我们在setting中创建索引模式,index name or pattern 与elasticsearch中索引名字需填写一致,点击create。
第二步,在kibana的discover标签中左侧选择目标索引,同时选择合适的时间过滤器,就可以看到数据。
第三步,进入visualize标签中,做出apache错误日志计,apache错误日志中clientip排名靠前的前5位,apache错误日志中errormsg排名靠前的前5位。把它们分别起个名字保存起来。
第四步,在dashboard面板上添加这几个可视化图形,调整位置,可设置黑色主题,起个名字保存起来。
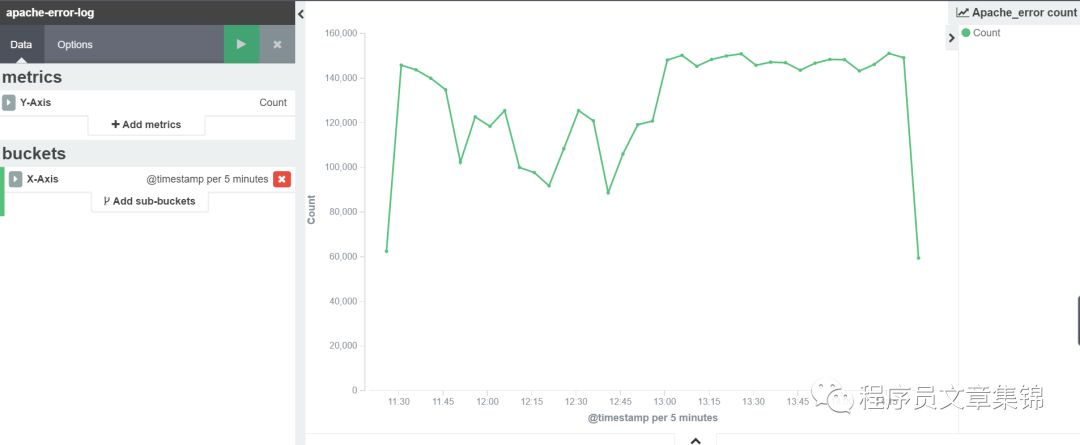
Apache错误日志计数
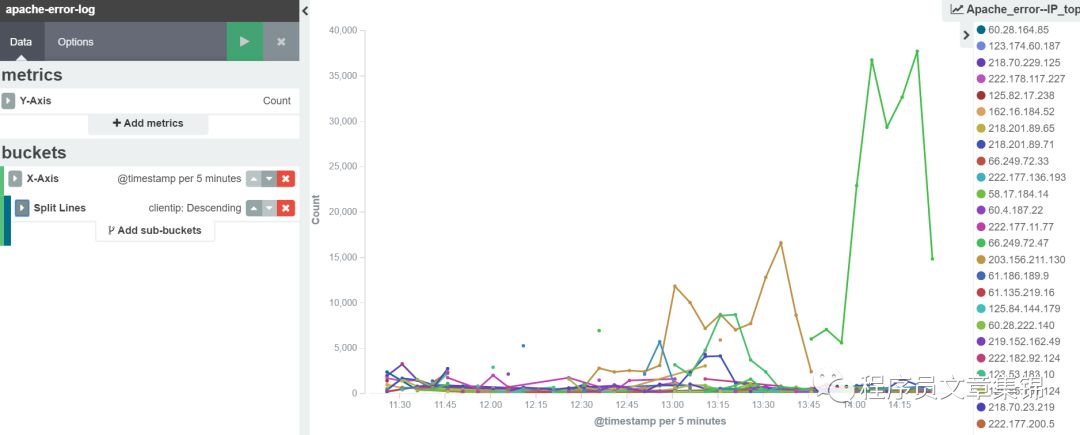
Apache错误日志的clientip前20
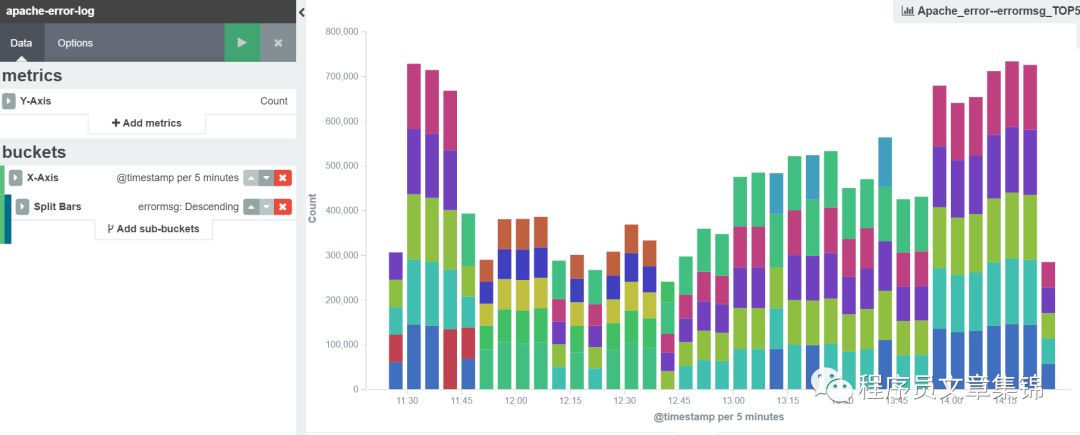
Apache错误日志的errormsg前20
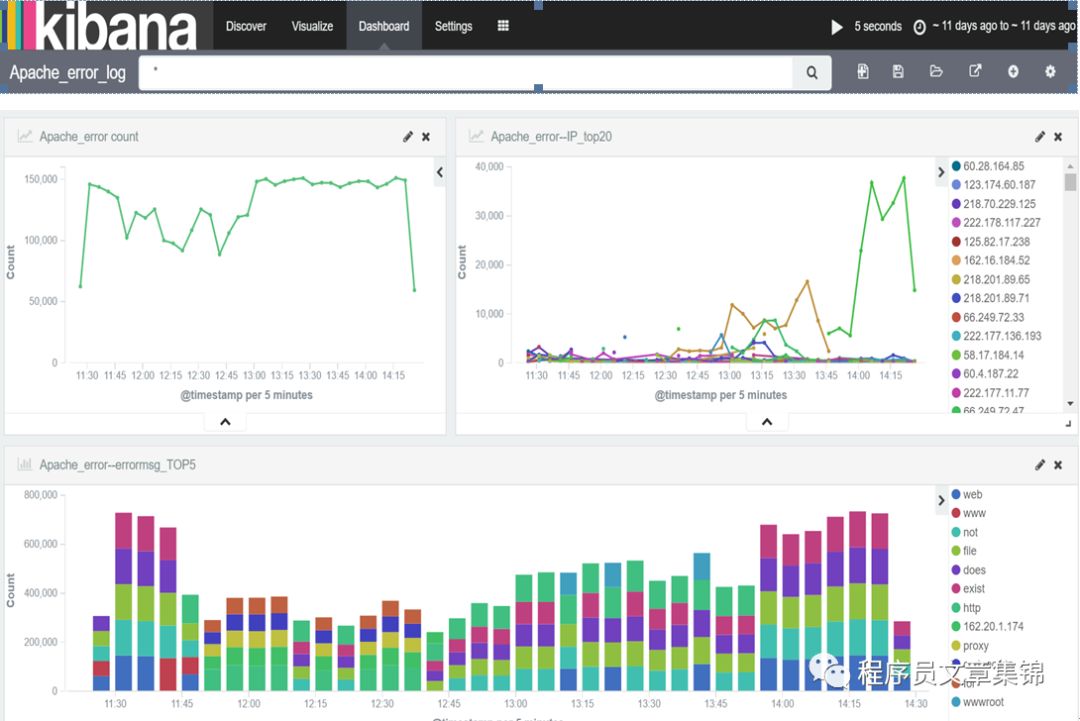
Apache错误日志模型
IIS日志分析DoS攻击模型
第一步:在logstash成功将iis日志导入elasticsearch后,我们在setting中创建索引模式,index name or pattern 与elasticsearch中索引名字需填写一致,点击create。
第二步,在kibana的discover标签中左侧选择目标索引,同时选择合适的时间过滤器,就可以看到数据。将其放大以合适的度量显示。
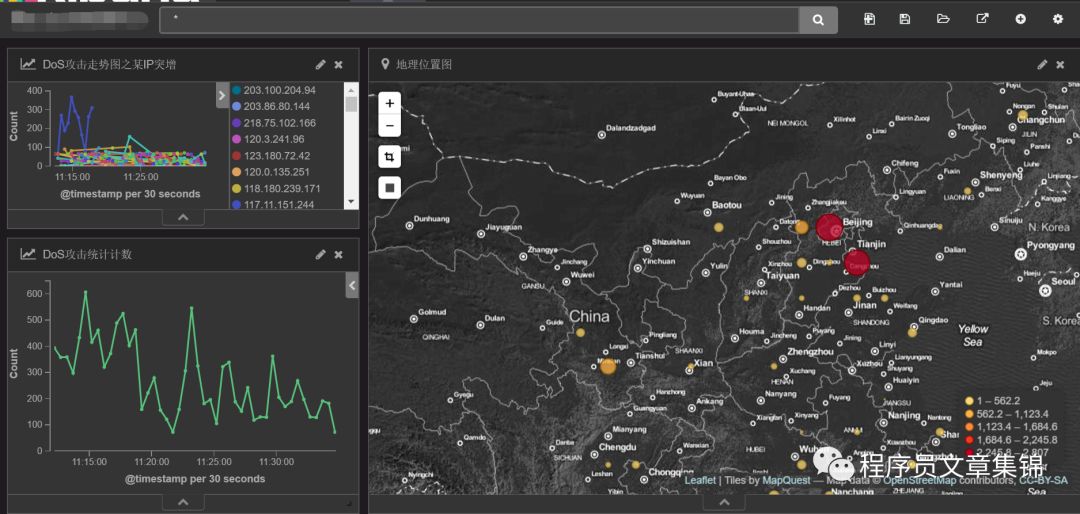
第三步,进入visualize标签中,做出iis 日志计数图;iis日志中clientip排名靠前的前5位,可以从图中某ip突增,可能存在DoS攻击;iis日志中ip的地理位置。把它们分别起个名字保存起来。
第四步,在dashboard面板上添加这几个可视化图形,调整位置,可设置黑色主题,起个名字保存起来。
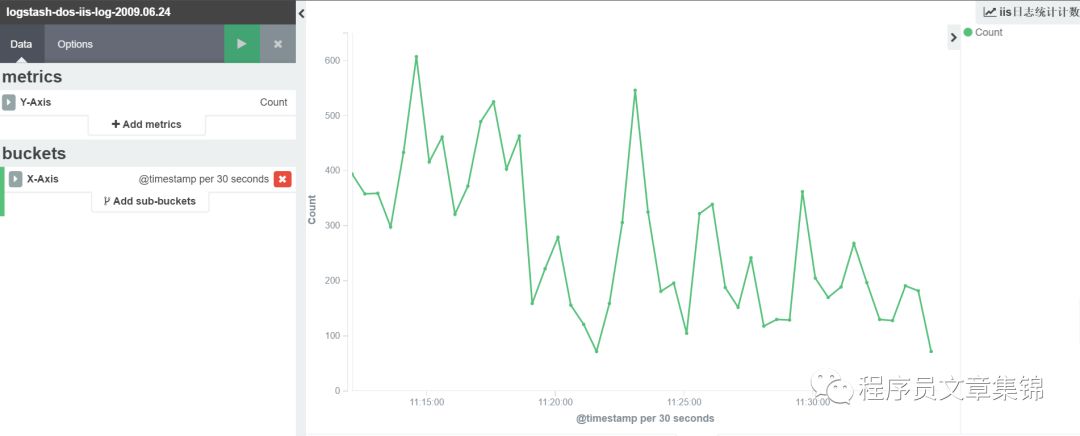
iis日志计数
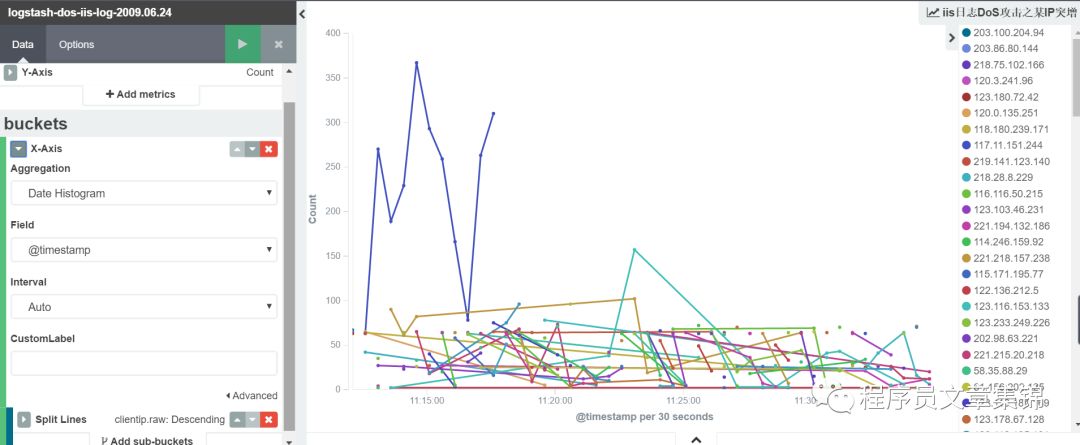
iis日志DoS攻击之某ip突增
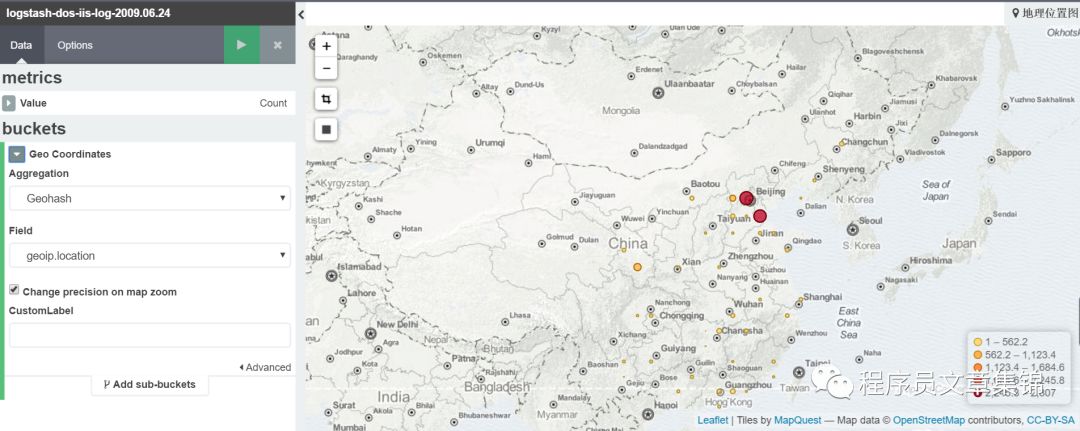
地理位置图
iis日志分析DoS攻击模型
linux系统syslog日志实时监控模型
第一步:在logstash成功将linux的syslog日志导入elasticsearch后(放在后台启动),我们在setting中创建索引模式,index name or pattern 与elasticsearch中索引名字需填写一致,点击create。
第二步,在kibana的discover标签中左侧选择目标索引,同时选择合适的时间过滤器,就可以看到数据。将其放大以合适的度量显示。
第三步,进入visualize标签中,做出linux的syslog计数。
linux的syslog日志中message severity(信息严重级别)和message facility(设备信息)经常被用来反映syslog日志信息。如表1和表2所示为目前syslog使用5424协议中severity和facility的对应关系。由此可作图,通过filters将severity和facility在图中显示出来,把它们分别起个名字保存起来。
Numerical code | Facility |
0 | kernel messages |
1 | user-level messages |
2 | mail system |
3 | system daemons |
4 | security/authorization messages |
5 | messages generated internally by syslogd |
6 | line printer subsystem |
7 | network news subsystem |
8 | UUCP subsystem |
9 | clock daemon |
10 | security/authorization messages |
11 | FTP daemon |
12 | NTP subsystem |
13 | log audit |
14 | log alert |
15 | clock daemon (note 2) |
16 | local use 0 (local0) |
17 | local use 1 (local1) |
18 | local use 2 (local2) |
19 | local use 3 (local3) |
20 | local use 4 (local4) |
21 | local use 5 (local5) |
22 | local use 6 (local6) |
23 | local use 7 (local7) |
表1 linux的Syslog的Message Facilities
Numerical code | Severity |
0 | Emergency: system is unusable |
1 | Alert: action must be taken immediately |
2 | Critical: critical conditions |
3 | Error: error conditions |
4 | Warning: warning conditions |
5 | Notice: normal but significant condition |
6 | Informational: informational messages |
表2 linux的Syslog的Message Severities
第四步,在dashboard面板上添加这几个可视化图形,调整位置,可设置黑色主题,起个名字保存起来。
第五步设置自动刷新,设置相对时间,20min到现在,每隔5秒钟自动刷新一次。即可实时监控linux的syslog日志。
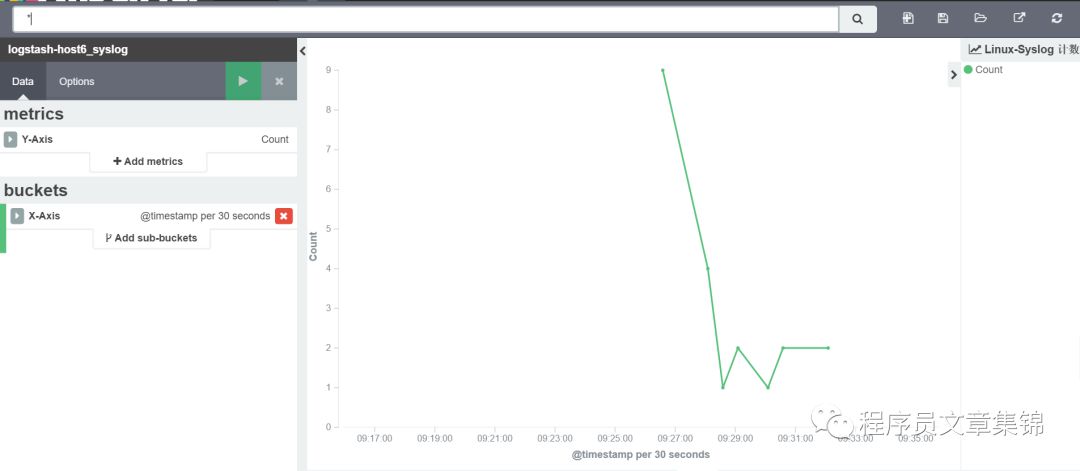
inux的syslog日志计数
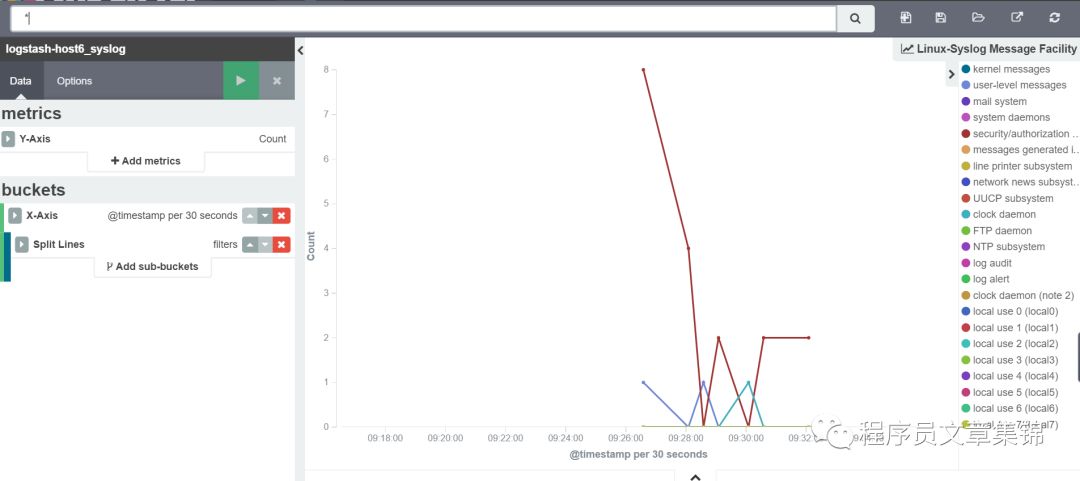
inux的syslog日志的message Facility
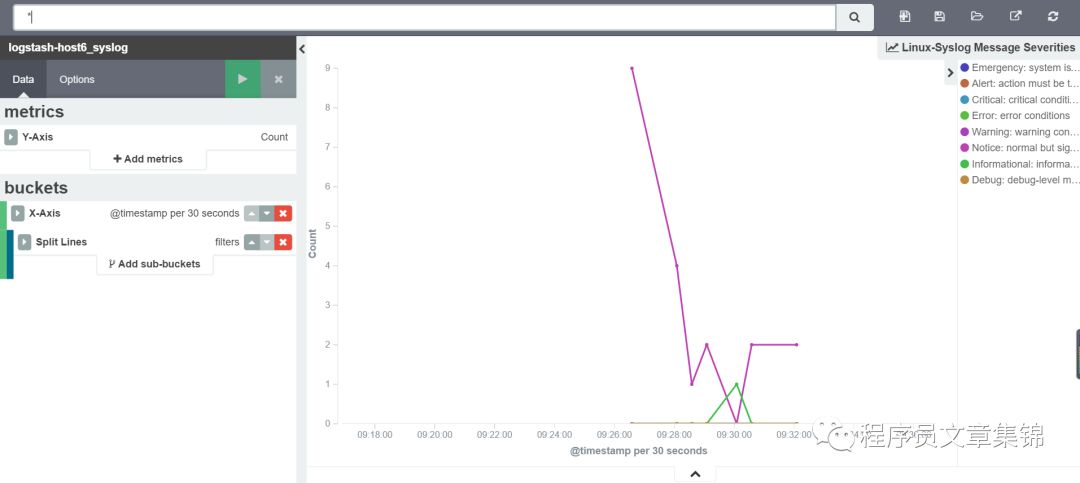
linux的syslog日志的Message Severities
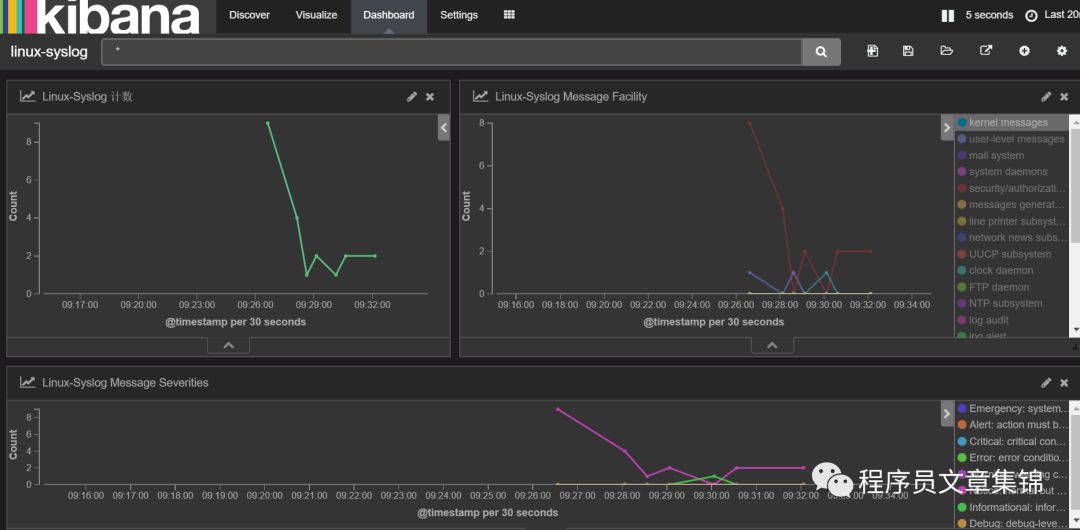
linux的syslog日志实时监控模型

