





简介
由于 FlinkCDC 是把全部数据统一写入一个 Topic 中, 这样显然不利于日后的数据处理。所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表。在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL 等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。这样的配置不适合写在配置文件中,因为这样的话,业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这种可以有两个方案实现
➢ 一种是用 Zookeeper 存储,通过 Watch 感知数据变化;
➢ 另一种是用 mysql 数据库存储,周期性的同步;
➢ 另一种是用 mysql 数据库存储,使用广播流。
这里选择第二种方案,主要是 MySQL 对于配置数据初始化和维护管理,使用 FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接。
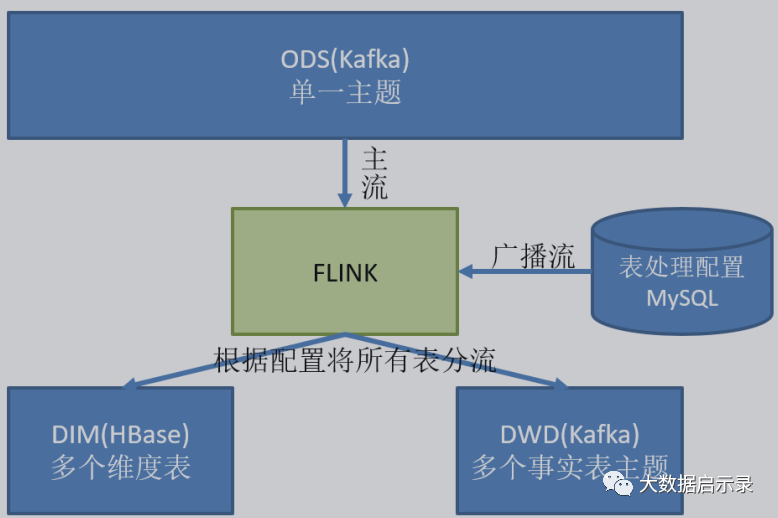
在数据库中创建配置表
CREATE TABLE `table_process` (`source_table` varchar(200) NOT NULL COMMENT '来源表',`operate_type` varchar(200) NOT NULL COMMENT '操作类型 insert,update,delete',`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',PRIMARY KEY (`source_table`,`operate_type`)) ENGINE=InnoDB DEFAULT CHARSET=utf8
创建配置表实体类
import lombok.Data;@Datapublic class TableProcess {//动态分流Sink常量public static final String SINK_TYPE_HBASE = "hbase";public static final String SINK_TYPE_KAFKA = "kafka";public static final String SINK_TYPE_CK = "clickhouse";//来源表String sourceTable;//操作类型 insert,update,deleteString operateType;//输出类型 hbase kafkaString sinkType;//输出表(主题)String sinkTable;//输出字段String sinkColumns;//主键字段String sinkPk;//建表扩展String sinkExtend;}
kafka 相关utils
import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.clients.producer.ProducerConfig;import org.apache.kafka.clients.producer.ProducerRecord;import javax.annotation.Nullable;import java.util.Properties;public class MyKafkaUtil {private static String brokers = "hadoop102:9092,hadoop103:9092,hadoop104:9092";private static String default_topic = "DWD_DEFAULT_TOPIC";public static FlinkKafkaProducer<String> getKafkaProducer(String topic) {return new FlinkKafkaProducer<String>(brokers,topic,new SimpleStringSchema());}public static <T> FlinkKafkaProducer<T> getKafkaProducer(KafkaSerializationSchema<T> kafkaSerializationSchema) {Properties properties = new Properties();properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);return new FlinkKafkaProducer<T>(default_topic,kafkaSerializationSchema,properties,FlinkKafkaProducer.Semantic.EXACTLY_ONCE);}public static FlinkKafkaConsumer<String> getKafkaConsumer(String topic, String groupId) {Properties properties = new Properties();properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);return new FlinkKafkaConsumer<String>(topic,new SimpleStringSchema(),properties);}//拼接Kafka相关属性到DDLpublic static String getKafkaDDL(String topic, String groupId) {return " 'connector' = 'kafka', " +" 'topic' = '" + topic + "'," +" 'properties.bootstrap.servers' = '" + brokers + "', " +" 'properties.group.id' = '" + groupId + "', " +" 'format' = 'json', " +" 'scan.startup.mode' = 'latest-offset' ";}}
处理流程
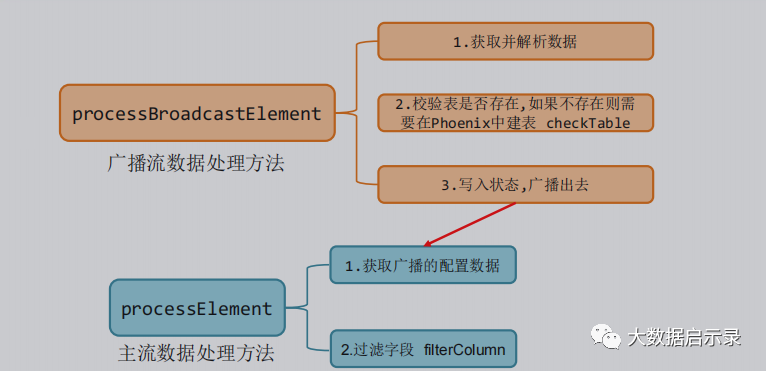
定义TableProcessFunction
import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.JSONObject;import com.atguigu.bean.TableProcess;import com.atguigu.common.GmallConfig;import org.apache.flink.api.common.state.BroadcastState;import org.apache.flink.api.common.state.MapStateDescriptor;import org.apache.flink.api.common.state.ReadOnlyBroadcastState;import org.apache.flink.configuration.Configuration;import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;import org.apache.flink.util.Collector;import org.apache.flink.util.OutputTag;import java.sql.Connection;import java.sql.DriverManager;import java.sql.PreparedStatement;import java.sql.SQLException;import java.util.Arrays;import java.util.List;public class TableProcessFunction extends BroadcastProcessFunction<JSONObject, String, JSONObject> {private OutputTag<JSONObject> objectOutputTag;private MapStateDescriptor<String, TableProcess> mapStateDescriptor;private Connection connection;public TableProcessFunction(OutputTag<JSONObject> objectOutputTag, MapStateDescriptor<String, TableProcess> mapStateDescriptor) {this.objectOutputTag = objectOutputTag;this.mapStateDescriptor = mapStateDescriptor;}@Overridepublic void open(Configuration parameters) throws Exception {Class.forName(GmallConfig.PHOENIX_DRIVER);connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);}//value:{"db":"","tn":"","before":{},"after":{},"type":""}@Overridepublic void processBroadcastElement(String value, Context ctx, Collector<JSONObject> out) throws Exception {//1.获取并解析数据JSONObject jsonObject = JSON.parseObject(value);String data = jsonObject.getString("after");TableProcess tableProcess = JSON.parseObject(data, TableProcess.class);//2.建表if (TableProcess.SINK_TYPE_HBASE.equals(tableProcess.getSinkType())) {checkTable(tableProcess.getSinkTable(),tableProcess.getSinkColumns(),tableProcess.getSinkPk(),tableProcess.getSinkExtend());}//3.写入状态,广播出去BroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(mapStateDescriptor);String key = tableProcess.getSourceTable() + "-" + tableProcess.getOperateType();broadcastState.put(key, tableProcess);}//建表语句 : create table if not exists db.tn(id varchar primary key,tm_name varchar) xxx;private void checkTable(String sinkTable, String sinkColumns, String sinkPk, String sinkExtend) {PreparedStatement preparedStatement = null;try {if (sinkPk == null) {sinkPk = "id";}if (sinkExtend == null) {sinkExtend = "";}StringBuffer createTableSQL = new StringBuffer("create table if not exists ").append(GmallConfig.HBASE_SCHEMA).append(".").append(sinkTable).append("(");String[] fields = sinkColumns.split(",");for (int i = 0; i < fields.length; i++) {String field = fields[i];//判断是否为主键if (sinkPk.equals(field)) {createTableSQL.append(field).append(" varchar primary key ");} else {createTableSQL.append(field).append(" varchar ");}//判断是否为最后一个字段,如果不是,则添加","if (i < fields.length - 1) {createTableSQL.append(",");}}createTableSQL.append(")").append(sinkExtend);//打印建表语句System.out.println(createTableSQL);//预编译SQLpreparedStatement = connection.prepareStatement(createTableSQL.toString());//执行preparedStatement.execute();} catch (SQLException e) {throw new RuntimeException("Phoenix表" + sinkTable + "建表失败!");} finally {if (preparedStatement != null) {try {preparedStatement.close();} catch (SQLException e) {e.printStackTrace();}}}}//value:{"db":"","tn":"","before":{},"after":{},"type":""}@Overridepublic void processElement(JSONObject value, ReadOnlyContext ctx, Collector<JSONObject> out) throws Exception {//1.获取状态数据ReadOnlyBroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(mapStateDescriptor);String key = value.getString("tableName") + "-" + value.getString("type");TableProcess tableProcess = broadcastState.get(key);if (tableProcess != null) {//2.过滤字段JSONObject data = value.getJSONObject("after");filterColumn(data, tableProcess.getSinkColumns());//3.分流//将输出表/主题信息写入Valuevalue.put("sinkTable", tableProcess.getSinkTable());String sinkType = tableProcess.getSinkType();if (TableProcess.SINK_TYPE_KAFKA.equals(sinkType)) {//Kafka数据,写入主流out.collect(value);} else if (TableProcess.SINK_TYPE_HBASE.equals(sinkType)) {//HBase数据,写入侧输出流ctx.output(objectOutputTag, value);}} else {System.out.println("该组合Key:" + key + "不存在!");}}/*** @param data {"id":"11","tm_name":"atguigu","logo_url":"aaa"}* @param sinkColumns id,tm_name* {"id":"11","tm_name":"atguigu"}*/private void filterColumn(JSONObject data, String sinkColumns) {String[] fields = sinkColumns.split(",");List<String> columns = Arrays.asList(fields);// Iterator<Map.Entry<String, Object>> iterator = data.entrySet().iterator();// while (iterator.hasNext()) {// Map.Entry<String, Object> next = iterator.next();// if (!columns.contains(next.getKey())) {// iterator.remove();// }// }data.entrySet().removeIf(next -> !columns.contains(next.getKey()));}}
GmallConfig
定义一个项目中常用的配置常量类 GmallConfig
//Phoenix库名public static final String HBASE_SCHEMA = "GMALL210325_REALTIME";//Phoenix驱动public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver";//Phoenix连接参数public static final String PHOENIX_SERVER = "jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181";//ClickHouse_Urlpublic static final String CLICKHOUSE_URL = "jdbc:clickhouse://hadoop102:8123/default";//ClickHouse_Driverpublic static final String CLICKHOUSE_DRIVER = "ru.yandex.clickhouse.ClickHouseDriver";
BaseDBApp 运行主类
import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.JSONObject;import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;import com.atguigu.app.function.CustomerDeserialization;import com.atguigu.app.function.DimSinkFunction;import com.atguigu.app.function.TableProcessFunction;import com.atguigu.bean.TableProcess;import com.atguigu.utils.MyKafkaUtil;import org.apache.flink.api.common.functions.FilterFunction;import org.apache.flink.api.common.state.MapStateDescriptor;import org.apache.flink.streaming.api.datastream.*;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;import org.apache.flink.util.OutputTag;import org.apache.kafka.clients.producer.ProducerRecord;import javax.annotation.Nullable;//数据流:web/app -> nginx -> SpringBoot -> Mysql -> FlinkApp -> Kafka(ods) -> FlinkApp -> Kafka(dwd)/Phoenix(dim)//程 序:mockDb -> Mysql -> FlinkCDC -> Kafka(ZK) -> BaseDBApp -> Kafka/Phoenix(hbase,zk,hdfs)public class BaseDBApp {public static void main(String[] args) throws Exception {//TODO 1.获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//1.1 设置CK&状态后端//env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall-flink-210325/ck"));//env.enableCheckpointing(5000L);//env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//env.getCheckpointConfig().setCheckpointTimeout(10000L);//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);//env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000);//env.setRestartStrategy(RestartStrategies.fixedDelayRestart());//TODO 2.消费Kafka ods_base_db 主题数据创建流String sourceTopic = "ods_base_db";String groupId = "base_db_app_210325";DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getKafkaConsumer(sourceTopic, groupId));//TODO 3.将每行数据转换为JSON对象并过滤(delete) 主流SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject).filter(new FilterFunction<JSONObject>() {@Overridepublic boolean filter(JSONObject value) throws Exception {//取出数据的操作类型String type = value.getString("type");return !"delete".equals(type);}});//TODO 4.使用FlinkCDC消费配置表并处理成 广播流DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder().hostname("hadoop102").port(3306).username("root").password("000000").databaseList("gmall-210325-realtime").tableList("gmall-210325-realtime.table_process").startupOptions(StartupOptions.initial()).deserializer(new CustomerDeserialization()).build();DataStreamSource<String> tableProcessStrDS = env.addSource(sourceFunction);MapStateDescriptor<String, TableProcess> mapStateDescriptor = new MapStateDescriptor<>("map-state", String.class, TableProcess.class);BroadcastStream<String> broadcastStream = tableProcessStrDS.broadcast(mapStateDescriptor);//TODO 5.连接主流和广播流BroadcastConnectedStream<JSONObject, String> connectedStream = jsonObjDS.connect(broadcastStream);//TODO 6.分流 处理数据 广播流数据,主流数据(根据广播流数据进行处理)OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>("hbase-tag") {};SingleOutputStreamOperator<JSONObject> kafka = connectedStream.process(new TableProcessFunction(hbaseTag, mapStateDescriptor));//TODO 7.提取Kafka流数据和HBase流数据DataStream<JSONObject> hbase = kafka.getSideOutput(hbaseTag);//TODO 8.将Kafka数据写入Kafka主题,将HBase数据写入Phoenix表hbase.addSink(new DimSinkFunction());kafka.addSink(MyKafkaUtil.getKafkaProducer(new KafkaSerializationSchema<JSONObject>() {@Overridepublic ProducerRecord<byte[], byte[]> serialize(JSONObject element, @Nullable Long timestamp) {return new ProducerRecord<byte[], byte[]>(element.getString("sinkTable"),element.getString("after").getBytes());}}));//TODO 9.启动任务env.execute("BaseDBApp");}}
分流sink之保存维度到hbase
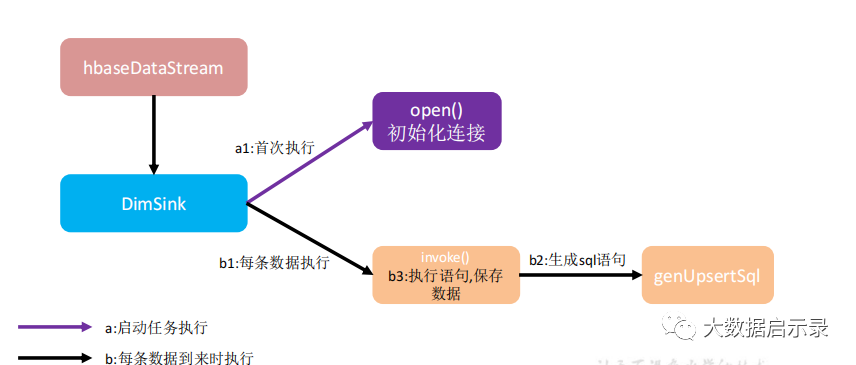
import com.alibaba.fastjson.JSONObject;import com.atguigu.common.GmallConfig;import com.atguigu.utils.DimUtil;import org.apache.commons.lang3.StringUtils;import org.apache.flink.configuration.Configuration;import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;import java.sql.Connection;import java.sql.DriverManager;import java.sql.PreparedStatement;import java.sql.SQLException;import java.util.Collection;import java.util.Set;public class DimSinkFunction extends RichSinkFunction<JSONObject> {private Connection connection;@Overridepublic void open(Configuration parameters) throws Exception {Class.forName(GmallConfig.PHOENIX_DRIVER);connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);connection.setAutoCommit(true);}//value:{"sinkTable":"dim_base_trademark","database":"gmall-210325-flink","before":{"tm_name":"atguigu","id":12},"after":{"tm_name":"Atguigu","id":12},"type":"update","tableName":"base_trademark"}//SQL:upsert into db.tn(id,tm_name) values('...','...')@Overridepublic void invoke(JSONObject value, Context context) throws Exception {PreparedStatement preparedStatement = null;try {//获取SQL语句String sinkTable = value.getString("sinkTable");JSONObject after = value.getJSONObject("after");String upsertSql = genUpsertSql(sinkTable,after);System.out.println(upsertSql);//预编译SQLpreparedStatement = connection.prepareStatement(upsertSql);//判断如果当前数据为更新操作,则先删除Redis中的数据if ("update".equals(value.getString("type"))){DimUtil.delRedisDimInfo(sinkTable.toUpperCase(), after.getString("id"));}//执行插入操作preparedStatement.executeUpdate();} catch (SQLException e) {e.printStackTrace();} finally {if (preparedStatement != null) {preparedStatement.close();}}}//data:{"tm_name":"Atguigu","id":12}//SQL:upsert into db.tn(id,tm_name,aa,bb) values('...','...','...','...')private String genUpsertSql(String sinkTable, JSONObject data) {Set<String> keySet = data.keySet();Collection<Object> values = data.values();//keySet.mkString(","); => "id,tm_name"return "upsert into " + GmallConfig.HBASE_SCHEMA + "." + sinkTable + "(" +StringUtils.join(keySet, ",") + ") values('" +StringUtils.join(values, "','") + "')";}}
文章转载自大数据启示录,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
