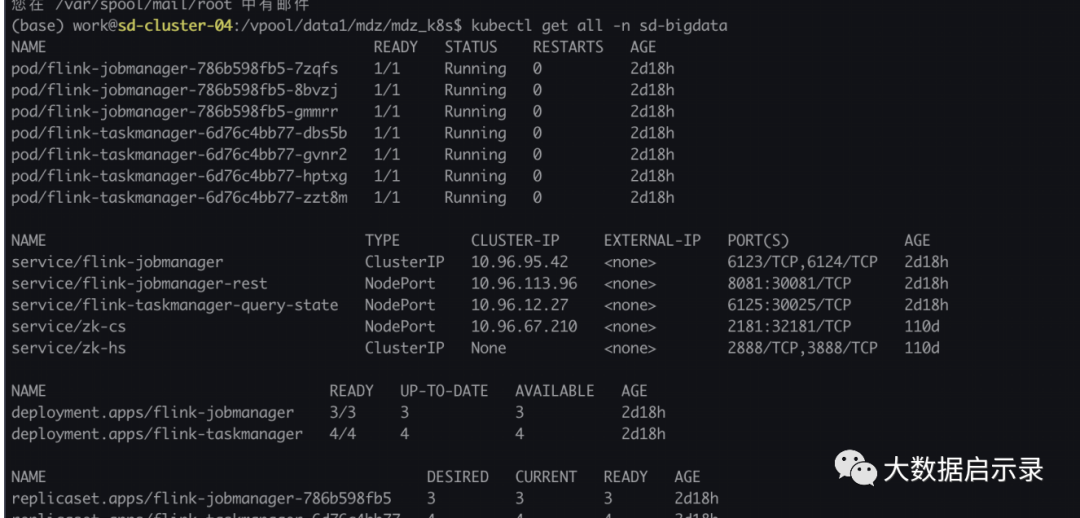
本⽂档共分为打包镜像和k8s 部署两部分。

镜像打包

1: 编辑镜像,本部分集成了hdfs 相关配置:
下载hadoop 依赖压缩包
mwget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz
解压hadoop 压缩包
解压后进⼊到etc/hadoop/⽬录下并替换掉core-site.xml,hdfs-site.xml,yarnsite.xml,mapred-site.xml⽂件。
若有需要,可以在lib 包下添加相应jar包,完成后打包成.tar.gz⽂件。
下载其它安装包,需在Dockerfile同级⽬录下:如
编辑Dockerfile⽂件:
################################################################################ Licensed to the Apache Software Foundation (ASF) under one# or more contributor license agreements. See the NOTICE file# distributed with this work for additional information# regarding copyright ownership. The ASF licenses this file# to you under the Apache License, Version 2.0 (the# "License"); you may not use this file except in compliance# with the License. You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.###############################################################################FROM centos:7# Install dependenciesRUN set -ex; \yum -y install wget; \cd /etc/yum.repos.d/; \mv CentOS-Base.repo CentOS-Base.repo.bak; \wget http://mirrors.aliyun.com/repo/Centos-7.repo; \yum clean all; \yum makecache; \yum -y update; \yum install -y bzip2 gettext make autogen autoconf net-tools gcc-c++ telnet;# Prepare environmentENV FLINK_HOME=/opt/flinkENV PATH=$FLINK_HOME/bin:$PATHRUN set -ex; \mkdir $FLINK_HOME;RUN groupadd --system --gid=9999 flink && \useradd --system --home-dir $FLINK_HOME --uid=9999 --gid=flink flink# Install gosuCOPY ./gosu.tgz /opt/gosu/gosu.tgzRUN set -ex; \cd /opt/gosu; \tar -xf /opt/gosu/gosu.tgz --strip-components=1 \&& /opt/gosu/gosu.install.sh \&& rm -fr /opt/gosu# Install jemalloc-5.2.1.tar.gzCOPY ./jemalloc-5.2.1.tar.gz /opt/jemolloc/jemalloc-5.2.1.tar.gzRUN set -ex; \cd /opt/jemolloc; \tar -xf /opt/jemolloc/jemalloc-5.2.1.tar.gz --strip-components=1 \&& ./configure --prefix=/usr/lib/x86_64-linux-gnu \&& make \&& make install# Install jdk-8RUN set -ex; \mkdir /usr/java;ENV JAVA_HOME=/usr/java/ENV PATH=$JAVA_HOME/bin:$PATHCOPY ./jdk1.8.0_181-cloudera.tgz /tmp/jdk.tgzRUN set -ex; \cd /usr/java; \tar -xf /tmp/jdk.tgz --strip-components=1; \rm /tmp/jdk.tgz; \\chown -R flink:flink .;# Install FlinkWORKDIR $FLINK_HOMECOPY ./flink-1.13.1_dz.tar.gz flink.tgz // 此处对应的flink-1.13.1_dz.tar.gz 需要安装包名字⼀致RUN set -ex; \tar -xf flink.tgz --strip-components=1; \rm flink.tgz; \\chown -R flink:flink .;# Prepare environmentENV HADOOP_HOME=/opt/hadoopENV PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHCOPY hadoop-2.8.3.tar.gz hadoop-2.8.3.tgzRUN set -ex; \tar -xf hadoop-2.8.3.tgz --strip-components=1; \rm hadoop-2.8.3.tgz; \chown -R flink:flink .;# add hadoop conf or jarCOPY flink-shaded-hadoop-2-uber-2.8.3-10.0.jar /opt/flink/libCOPY hadoop-client-2.8.3.jar /opt/flink/libCOPY hadoop-common-2.8.3.jar /opt/flink/libCOPY hadoop-hdfs-2.8.3.jar /opt/flink/libCOPY hadoop-mapreduce-client-common-2.8.3.jar /opt/flink/libCOPY hadoop-mapreduce-client-core-2.8.3.jar /opt/flink/libCOPY hadoop-mapreduce-client-jobclient-2.8.3.jar /opt/flink/lib# Configure containerCOPY docker-entrypoint.sh /#ENTRYPOINT ["/docker-entrypoint.sh"]#CMD /docker-entrypoint.sh jobmanagerEXPOSE 6123 8081
打包镜像:
docker build -t 镜像名:版本号 . 如:flink_k8s:v1.13 .docker iamges (查看镜像)docker run -it flink_k8s:v1.13 (运⾏⼀个容器)docker exec -u 0 -it 容器名 /bin/bash 以root权限...
推送/拉取镜像
docker login 仓库地址 登陆镜像仓库docker tag 镜像名:版本号 仓库地址/namespace/镜像名:版本号 打tagdocker push 镜像地址/namespace/镜像名:版本号 推送镜像docker pull 仓库地址/namespace/镜像名:版本号 (拉取镜像)docker logout 镜像地址 登出镜像仓库
flink on k8s JM HA yaml配置
配置⽬录结构如下:
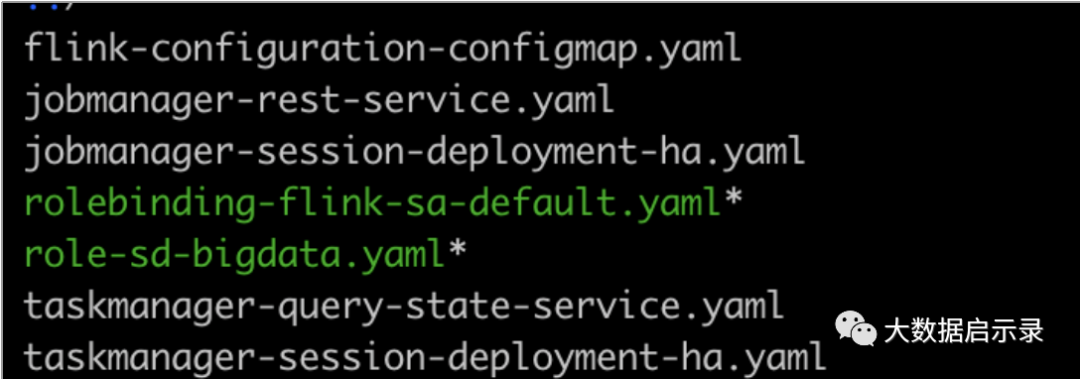
1:对于 JobManager 和 TaskManager 运⾏过程中需要的⼀些配置⽂件,如:flink-conf.yaml、hdfssite.xml、core-site.xml,log4j-console.properties....,可以通过flink-configuration-configmap.yaml⽂件将它们定义为 ConfigMap 来实现配置的传递和读取。如果使⽤默认配置,这⼀步则不需要。模版如下:
apiVersion: v1kind: ConfigMapmetadata:name: flink-confignamespace: sd-bigdatalabels:app: flinkdata: //挂载了两个配置⽂件(flink-conf.yaml,log4j-console.properties)flink-conf.yaml: |+jobmanager.rpc.address: flink-jobmanagertaskmanager.numberOfTaskSlots: 2blob.server.port: 6124jobmanager.rpc.port: 6123taskmanager.rpc.port: 6122queryable-state.proxy.ports: 6125jobmanager.memory.process.size: 1600mtaskmanager.memory.process.size: 20480mtaskmanager.numberOfTaskSlots: 18parallelism.default: 1classloader.resolve-order: parent-first# classloader.resolve-order: 当加载⽤户代码类时,Flink使⽤child-first的# ClassLoader还是parent-first ClassLoader。可以是parent-first 或 child-first中的⼀个# 值。(默认:child-first)---->建议使⽤parent-first。## ha 相关配置参数kubernetes.cluster-id: sdai-cluster-test# 不⽀持_,*,.等符号,建议使⽤-high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory# hdfs ⽬录high-availability.storageDir: hdfs://sd-cluster-03:8020/flink/recoveryrestart-strategy: fixed-delayrestart-strategy.fixed-delay.attempts: 10# chekpoin 相关参数state.backend: filesystem# hdfs checkpointstate.checkpoints.dir: hdfs://sd-cluster-03:8020/data/flink/checkpointslog4j-console.properties: |+# This affects logging for both user code and FlinkrootLogger.level = INFOrootLogger.appenderRef.console.ref = ConsoleAppenderrootLogger.appenderRef.rolling.ref = RollingFileAppender# Uncomment this if you want to _only_ change Flink's logging#logger.flink.name = org.apache.flink#logger.flink.level = INFO# The following lines keep the log level of common libraries/connectors on# log level INFO. The root logger does not override this. You have to manually# change the log levels here.logger.akka.name = akkalogger.akka.level = INFOlogger.kafka.name= org.apache.kafkalogger.kafka.level = INFOlogger.hadoop.name = org.apache.hadooplogger.hadoop.level = INFOlogger.zookeeper.name = org.apache.zookeeperlogger.zookeeper.level = INFO# Log all infos to the consoleappender.console.name = ConsoleAppenderappender.console.type = CONSOLEappender.console.layout.type = PatternLayoutappender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n# Log all infos in the given rolling fileappender.rolling.name = RollingFileAppenderappender.rolling.type = RollingFileappender.rolling.append = falseappender.rolling.fileName = ${sys:log.file}appender.rolling.filePattern = ${sys:log.file}.%iappender.rolling.layout.type = PatternLayoutappender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%nappender.rolling.policies.type = Policiesappender.rolling.policies.size.type = SizeBasedTriggeringPolicyappender.rolling.policies.size.size=100MBappender.rolling.strategy.type = DefaultRolloverStrategyappender.rolling.strategy.max = 10# Suppress the irrelevant (wrong) warnings from the Netty channel handlerlogger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipelinelogger.netty.level = OFF
2:jobmanager-rest-service.yaml. 可选服务,将 jobmanager rest 端⼝公开为公共 Kubernetes 节点的端⼝。
apiVersion: v1kind: Servicemetadata:name: flink-jobmanager-restnamespace: sd-bigdataspec:type: NodePortports:- name: restport: 8081targetPort: 8081nodePort: 30081 # web ui访问端⼝selector:app: flinkcomponent: jobmanager---apiVersion: v1kind: Servicemetadata:name: flink-jobmanagernamespace: sd-bigdataspec:ports:- name: rpcport: 6123- name: blob-serverport: 6124selector:app: flinkcomponent: jobmanager
3:jobmanager-session-deployment-ha.yaml
apiVersion: apps/v1kind: Deploymentmetadata:name: flink-jobmanagernamespace: sd-bigdataspec:replicas: 3 # Set the value to greater than 1 to start standby JobManagers,建议设为奇数个selector:matchLabels:app: flinkcomponent: jobmanagertemplate:metadata:labels:app: flinkcomponent: jobmanagerspec:hostAliases:- ip: "47.92.212.xx" # kafka ip 地址hostnames:- "sd-kafka001"- "kafka001"- ip: "39.99.227.xx"hostnames:- "sd-kafka002"- "kafka002"- ip: "39.99.158.xx"hostnames:- "sd-kafka003"- "kafka003"- ip: "192.168.1.xx" # hdfs ip 地址hostnames:- "sd-cluster-03"- ip: "192.168.1.xx"hostnames:- "sd-cluster-04"- ip: "192.168.1.xx"hostnames:- "sd-cluster-05"containers:- name: jobmanager # 容器名(角色名)# image: registry-jf.sensedeal.wiki:9443/big-data/hdfs_flink:v8image: registry-jf.sensedeal.wiki:9443/big-data/flink_k8s:v1.40 # 镜像名env:- name: POD_IPvalueFrom:fieldRef:apiVersion: v1fieldPath: status.podIP# The following args overwrite the value of jobmanager.rpc.address configured in the configuration config map to POD_IP.args: ["jobmanager", "$(POD_IP)"] # 这两⾏不能省略# args: ["jobmanager"]command: ["/docker-entrypoint.sh"]ports:- containerPort: 6123name: rpc- containerPort: 6124name: blob-server- containerPort: 8081name: webuilivenessProbe:tcpSocket:port: 6123initialDelaySeconds: 30periodSeconds: 60volumeMounts:- name: flink-config-volumemountPath: /opt/flink/confsecurityContext:runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessaryserviceAccountName: flink-service-account # Service account which has the permissions to create, edit, delete ConfigMapsvolumes:- name: flink-config-volumeconfigMap:name: flink-configitems:- key: flink-conf.yamlpath: flink-conf.yaml- key: log4j-console.propertiespath: log4j-console.properties
注意:serviceAccountName 必须具有相关权限。
3:Taskmanager-query-state-service.yaml 可选服务,公开 TaskManager 端⼝以作为公共Kubernetes 节点的端⼝访问可查询状态
如果您为其创建 NodePort 服务,则可以访问 TaskManager 的可查询状态:
1. 运⾏为pod kubectl create -f taskmanager-query-state-service.yaml 创建 NodePort 服务 taskmanager 的例⼦ taskmanager-query-state-service.yaml 可以在附录中找到。
2. 运⾏ kubectl get svc flink-taskmanager-query-state 以获取 <node-port> 此服务的。然后你可以创建QueryableStateClient(, 来提交状态查询。
taskmanager-query-state-service.yaml
apiVersion: v1kind: Servicemetadata:name: flink-taskmanager-query-statenamespace: sd-bigdataspec:type: NodePortports:- name: query-stateport: 6125targetPort: 6125nodePort: 30025selector:app: flinkcomponent: taskmanager
taskmanager-session-deployment-ha.yaml
apiVersion: apps/v1kind: Deploymentmetadata:name: flink-taskmanagernamespace: sd-bigdataspec:replicas: 4selector:matchLabels:app: flinkcomponent: taskmanagertemplate:metadata:labels:app: flinkcomponent: taskmanagerspec:hostAliases:- ip: "47.92.212.xx"hostnames:- "sd-kafka001"- "kafka001"- ip: "39.99.227.xx"hostnames:- "sd-kafka002"- "kafka002"- ip: "39.99.158.xx"hostnames:- "sd-kafka003"- "kafka003"- ip: "192.168.1.xx"hostnames:- "sd-cluster-03"- ip: "192.168.1.xx"hostnames:- "sd-cluster-04"- ip: "192.168.1.xx"hostnames:- "sd-cluster-05"containers:- name: taskmanager# image: registry-jf.sensedeal.wiki:9443/big-data/hdfs_flink:v8image: registry-jf.sensedeal.wiki:9443/big-data/flink_k8s:v1.40args: ["taskmanager"]command: ["/docker-entrypoint.sh"]ports:- containerPort: 6122name: rpc- containerPort: 6125name: query-statelivenessProbe:tcpSocket:port: 6122initialDelaySeconds: 30periodSeconds: 60volumeMounts:- name: flink-config-volumemountPath: /opt/flink/conf/securityContext:runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessaryserviceAccountName: flink-service-account //必须配置volumes:- name: flink-config-volumeconfigMap:name: flink-configitems:- key: flink-conf.yamlpath: flink-conf.yaml- key: log4j-console.propertiespath: log4j-console.properties
此外,您必须使⽤有权创建、编辑、删除 ConfigMap 的服务帐户启动 JobManager 和 TaskManagerpod。有关更多信息,有关更多信息,请参阅如何为 Pod 配置服务帐户。
当启⽤ High-Availability 时,Flink 将使⽤⾃⼰的 HA-services 进⾏服务发现。因此,JobManager pod应该以其 IP 地址⽽不是 Kubernetes 服务作为其 jobmanager.rpc.address .
4:serviceAccountName 需要运维配置:
role-sd-bigdata.yaml
apiVersion: rbac.authorization.k8s.io/v1kind: Rolemetadata:name: flink-sanamespace: defaultrules:- apiGroups:- '*'resources:- '*'verbs:- "*"
rolebinding-flink-sa-default.yaml
apiVersion: rbac.authorization.k8s.io/v1kind: RoleBindingmetadata:name: flink-sa-defaultnamespace: defaultroleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: flink-sasubjects:- kind: ServiceAccountname: flink-service-accountnamespace: sd-bigdata
5:启动服务:
切换为具有执⾏权限的⽤户后执⾏以下命令:
启动
kubectl apply -f flink-configuration-configmap.yaml -n namespacekubectl apply -f jobmanager-rest-service.yaml -n namespacekubectl apply -f jobmanager-session-deployment-ha.yaml -n namespacekubectl apply -f taskmanager-query-state-service.yaml -n namespacekubectl apply -f taskmanager-session-deployment-ha.yaml -n namespace
删除:
kubectl delete -f flink-configuration-configmap.yaml -n namespacekubectl delete -f jobmanager-rest-service.yaml -n namespacekubectl delete -f jobmanager-session-deployment-ha.yaml -n namespacekubectl delete -f taskmanager-query-state-service.yaml -n namespacekubectl delete -f taskmanager-session-deployment-ha.yaml -n namespace
查看:
kubectl get pods -n namespace
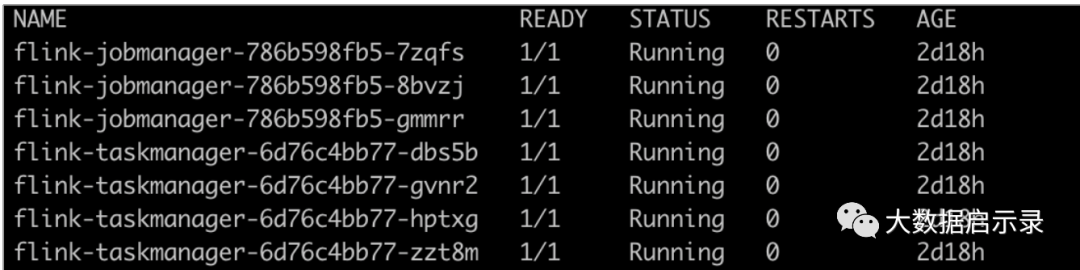
kubectl get svc -n namespace

kubectl get all -n namespace