




autovacuum是mogdb一个线程,称之为清理进程,分为AutoVacLauncher和AutoVacWorker。
为什么需要autovacuum线程,因为在mogdb的表里面存在大量的dead_tuple记录,可以通过试图pg_stat_all_tables,比如:
autovacuum的原理
sbtest=# select * from pg_stat_all_tables where relname like ‘sbtest1’;
-[ RECORD 1 ]-----±-----------------------------
relid | 16392
schemaname | public
relname | sbtest1
seq_scan | 2
seq_tup_read | 100000
idx_scan | 223447
idx_tup_fetch | 10906244
n_tup_ins | 113112
n_tup_upd | 26410
n_tup_del | 13112
n_tup_hot_upd | 11775
n_live_tup | 100000
n_dead_tup | 374
last_vacuum | 2022-02-16 14:55:56.88311+08
last_autovacuum | 2022-02-16 14:55:56.88311+08
last_analyze | 2022-02-16 14:56:02.1043+08
last_autoanalyze | 2022-02-16 14:56:02.1043+08
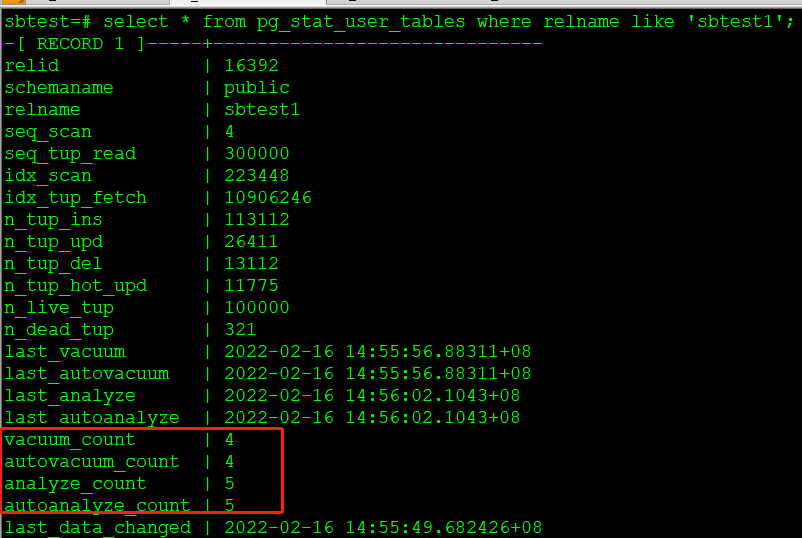
vacuum_count | 4
autovacuum_count | 4
analyze_count | 5
autoanalyze_count | 5
last_data_changed | 2022-02-16 14:55:49.682426+08
这些dead_tuple并不会立即删除,释放磁盘的空间,而是在删除的时候是一个逻辑删除,就是打上一个删除标记,而数据的可见性通过xmin来进行判断,有这么多的dead_tuple,有什么坏处呢,浪费磁盘空间,有很多死的元组,造成表膨胀,可以通过vacuum full命令来缩小表所占用的数据页,同时还存在select扫描大量无用的数据页,浪费io资源,增加select的查询时间,同时对statcollect收集统计信息,制定最小代价的查询路径计划有影响。那这样有什么好处呢,好处是数据的当前版本和历史版本不会发生冲突,同时就是在这种机制下面使用MVCC的话,读和写是不会阻塞的,从这边的描述不难看出,这个机制对读和写有好处,同时也有上面所说不好之处,需要进行清理,清理这个动作,是一个密集型io操作,是非常浪费cpu和内存资源的,所以autovacuum在使用的时候也是需要设置参数的,是autovacuum能够进行小步快跑的原则进行,所涉及的参数有:
参数释义
vacuum_cost_page_hit = 1 读取已在共享缓冲区中且不需要磁盘读取的页的成本
vacuum_cost_page_miss = 10 获取不在共享缓冲区中的页的成本
vacuum_cost_page_dirty = 20 为了从页/块中删除死元组,写操作的开销
autovacuum = on 开启autovacuum
log_autovacuum_min_duration = 10000 进行autovacuum超过指定的时间会在日志中记录
autovacuum_max_workers = 3 autovacuum的线程数目,可以根据实际情况调整
autovacuum_naptime = 1min autovacumm周期性的运行时间间隔
autovacuum_vacuum_threshold = 50
autovacuum_analyze_threshold = 50
autovacuum_vacuum_scale_factor = 0.01
autovacuum_analyze_scale_factor = 0.01
autovacuum_freeze_max_age = 200000000
autovacuum_vacuum_cost_delay = 20ms autovacuum被重新唤醒的时间间隔,配合
autovacuum_max_workers和 vacuum_cost_limit
autovacuum_vacuum_cost_limit = -1
vacuum_cost_limit = 200 设置autovacuum扫描的总成本
设置autovacuum的关注点
所以在设置的autovacuum的时候需要参照数据库的实际情况,同时也需要兼顾参数,可以参考这个顺序去设置的autovacuum。
autovacuum_max_workers,vacuum_cost_limit ,autovacuum_vacuum_cost_delay ,
顺序为vacuum_cost_limit–>autovacuum_vacuum_cost_delay -->autovacuum_max_workers
autovacuum清理逻辑
至于autovacuum是在共享缓冲区里面是如何清理的。
AutoVacLauncher和AutoVacWorker,当autovacuum参数打开后,AutoVacLauncher线
程会由Postmaster线程启动,并且会不断地将数据库需要做vacuum的对象信息保存在共享
内存中,当表上被删除或更新的记录数超过设定的阈值( 表中(update,delte记录) >=
autovacuum_vacuum_scale_factor* reltuples(表上记录数) +
autovacuum_vacuum_threshold ) 时,调用AutoVacWorker线程对这个表的存储空间执
行回收清理工作。
当需要发起数据库vacuum的时候,AutoVacLauncher线程会在共享内存
设置相应的flag,然后发送信号给Postmaster线程,postmaster线程收到信号后,就知
道需要启动一个AutoVacWorker子线程连接共享内存,AutoVacWorker子线程将从共享内
存获取待清理的任务信息,并执行对象的清理回收工作。
示例,观察autovacuum的次数变化
参数设置
autovacuum_vacuum_threshold = 50
autovacuum_analyze_threshold = 50
autovacuum_vacuum_scale_factor = 0.01
autovacuum_analyze_scale_factor = 0.01
查询pg_stat_user_tables,观察autovacuum_count
更新表的记录
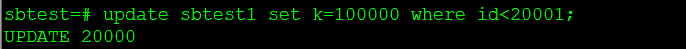
再次查询pg_stat_user_tables,观察autovacuum_count
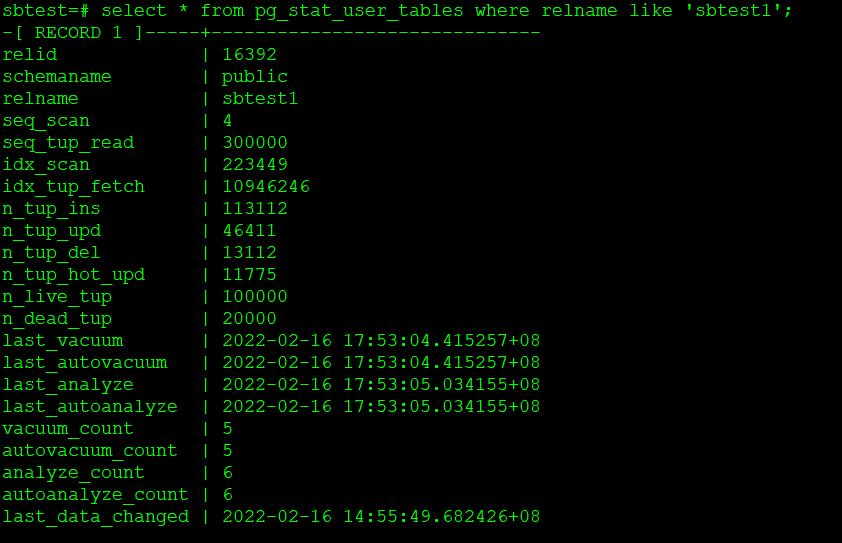
可以看到autovacuum_count已经有5变化为6,说明autvacuum根据阈值条件自动执行。
