




EDA介绍
Exploratory Data Analysis
是数据科学领取理解和分析数据的方法,通过不断的收集、分析和假设验证,以取得对数据的深入理解。
本文将使用的Automobile Dataset
来进行EDA过程,并试图给介绍EDA的具体步骤。
什么是EDA? 为什么做EDA? 如何做EDA?
什么是EDA?
EDA用于从数据中获取规律,使用一些统计值和可视化技术在数据中找到不同的模式、关系和异常情况。
深入理解数据 发现数据的内部结构 分析数据集中重要变量 识别数据中的异常值和异常 验证数据假设
为什么做EDA?
在比赛中所有选手给定的介绍和数据相同的情况下,从EDA发现的信息越多,对我们建模就更加有帮助。
特征如何选择 特征如何编码 数据如何划分
如何做EDA?
首先我们读取Automobile Dataset
:
https://www.kaggle.com/toramky/automobile-dataset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
auto=pd.read_csv('Automobile dataset.data')
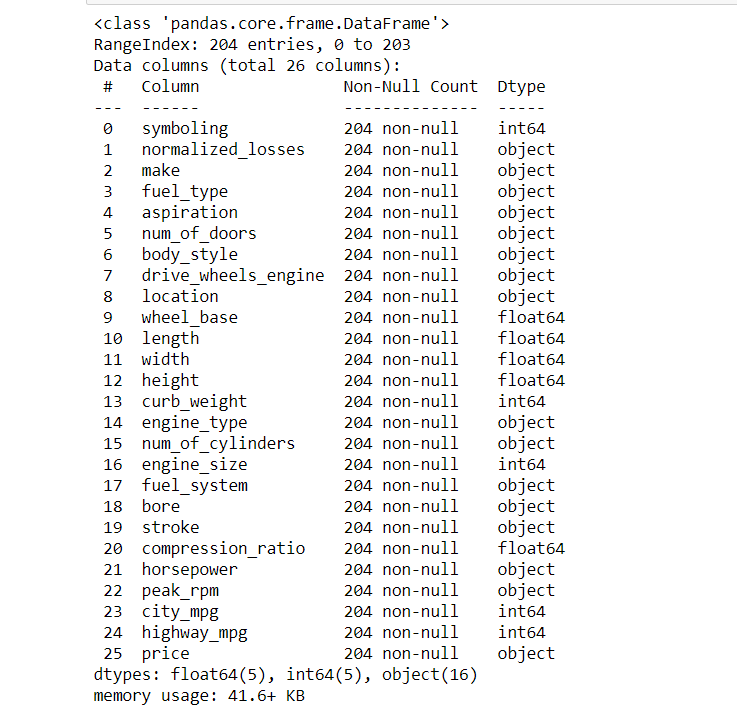
查看每列的类型:
auto.info()
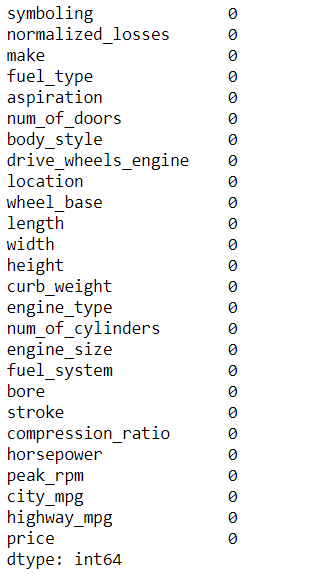
接下来可以检查下每列的缺失值情况:
auto.isnull().sum()
由于原始数据缺失值可能使用?
代替,所以这里我们看不出具体缺失值的情况。此外数据集里面有一些字段应该是数值类型,但编码为类别信息了。
接下来我们查看下每列的取值空间:
for col in auto.columns:
print('{} : {}'.format(col,auto[col].unique()))
对?
进行替换,然后统计缺失值:
for col in auto.columns:
auto[col].replace({'?':np.nan},inplace=True)
auto.isnull().sum()
接下来对缺失值出现情况进行可视化:
sns.heatmap(auto.isnull(),cbar=False,cmap='viridis')
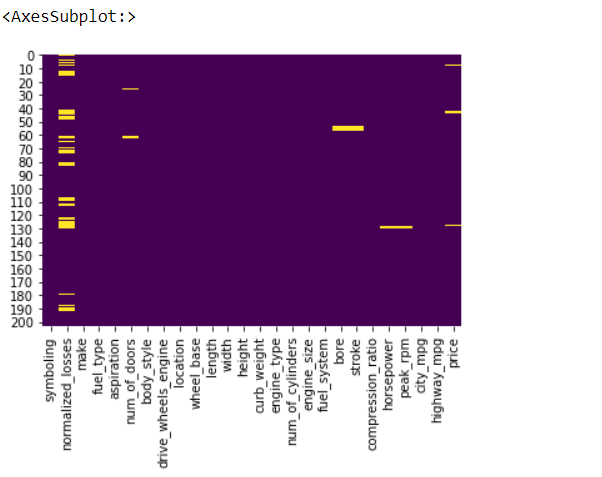
我们发现较多缺失值出现在normalized_losses
列,但我们不能直接删除,可能这一列包含重要信息。
接下来对列进行相关性分析:
plt.figure(figsize=(10,10))
sns.heatmap(auto.corr(),cbar=True,annot=True,cmap='Blues')
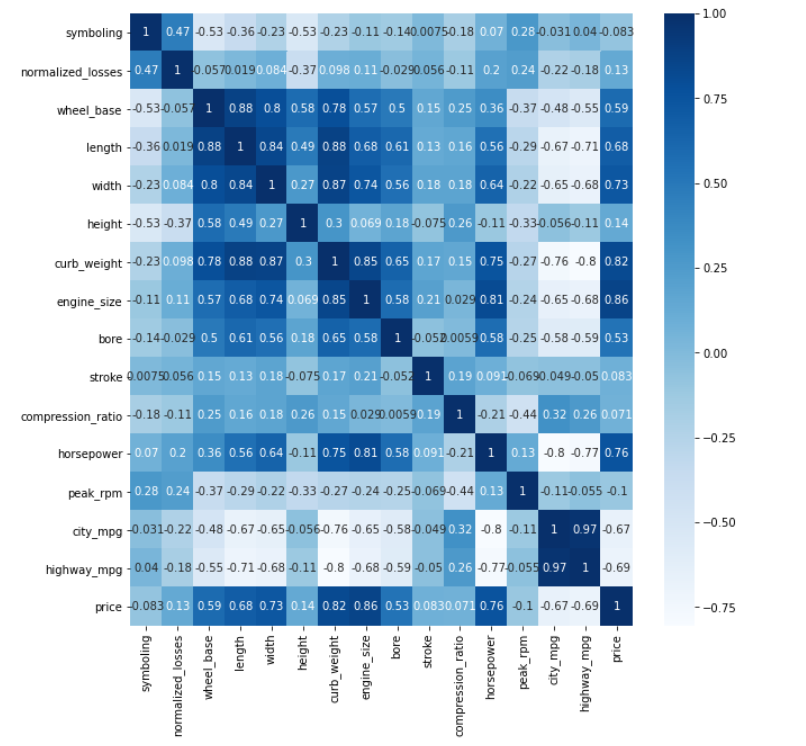
我们可以发现较多变量之间是存在强相关的,接下来我们可以对强相关的列进行分析,如horsepower和price:
plt.figure(figsize=(10,10))
plt.scatter(x='horsepower',y='price',data=auto)
plt.xlabel('Horsepower')
plt.ylabel('Price')
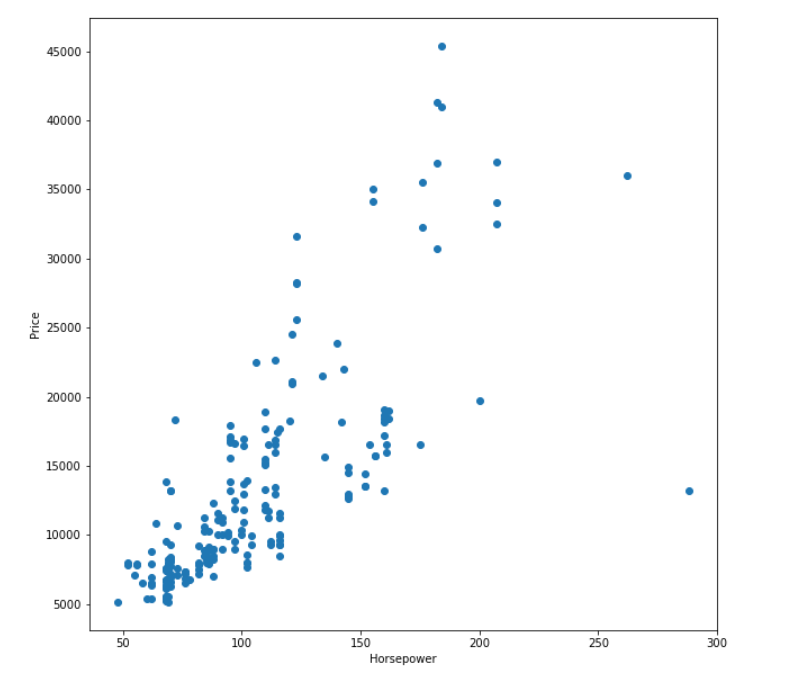
类似的,我们还可以对其他强相关列进行类似分析,通过分析可以得到:
两个变量如何相互影响。 变量的笛卡尔积对标签是否有影响。 两个变量是否存在交叉的可能。


文章转载自Coggle数据科学,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
