




赛题名称:科大讯飞线下商店销量预测挑战赛
赛题报名链接:https://challenge.xfyun.cn/topic/info?type=offline-store-sales-forecast&ch=dw-sq-1
赛题介绍
赛事背景
企业运营效率的提高主要依托于两个要素:销售预测的精度和供应链的反应速度。销售预测精度高,即便供应链反应速度不快,也能够实现库存与资金的高周转;采购管理、补货管理、销售管理等的基础便是销售预测。
销量预测是个非常经典的时序预测问题,通过一段时间内销售数据,预测未来商品的销量,对商品进行合理的分配和调度,解决供货上的不足或者堆积等问题。
赛事任务
给定商店销量历史相关数据和时间等信息,预测商店对应商品的周销量。
赛题数据
赛题数据由训练集和测试集组成,为了保证比赛的公平性,将每周日期进行脱敏,用0-33进行标识,即0为数据集第一周,33为数据集最后一周,其中33为测试集数据。数据集由字段shop_id(店铺id)、 item_id(商品id)、week(周标识)、item_price(商品价格)、item_category_id(商品品类id)、weekly_sales(周销量)组成。
赛题baseline思路
很明显的时间序列预测问题,那么关键点是序列的相关性、周期性、趋势性和随机性,如果能够把握这几点,那么一定能够获得不错的分数。
作为baseline,将使用lightgbm模型,进行五折交叉验证,同时会构建历史平移特征作为我们的base特征。
baseline
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import KFold
import lightgbm as lgb
import warnings
warnings.filterwarnings('ignore')
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
sample_submit = pd.read_csv('sample_submit.csv')
df = pd.concat([train, test], axis=0, ignore_index=True)
def lag_feature_adv(df, lags, col):
'''
历史N周平移特征
'''
tmp = df[['week','shop_id','item_id',col]]
for i in lags:
shifted = tmp.copy()
shifted.columns = ['week','shop_id','item_id', col+'_lag_'+str(i)+'_adv']
shifted['week'] += i
df = pd.merge(df, shifted, on=['week','shop_id','item_id'], how='left')
df[col+'_lag_'+str(i)+'_adv'] = df[col+'_lag_'+str(i)+'_adv']
return df
df = lag_feature_adv(df, [1, 2, 3], 'weekly_sales')
x_train = df[df.week < 33].drop(['weekly_sales'], axis=1)
y_train = df[df.week < 33]['weekly_sales']
x_test = df[df.week == 33].drop(['weekly_sales'], axis=1)
def cv_model(clf, train_x, train_y, test_x, clf_name='lgb'):
folds = 5
seed = 1024
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
train = np.zeros(train_x.shape[0])
test = np.zeros(test_x.shape[0])
categorical_feature = ['shop_id','item_id','item_category_id']
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt',
'objective': 'mse',
'metric': 'mse',
'min_child_weight': 5,
'num_leaves': 2 ** 7,
'lambda_l2': 10,
'feature_fraction': 0.9,
'bagging_fraction': 0.9,
'bagging_freq': 4,
'learning_rate': 0.05,
'seed': 1024,
'n_jobs':-1,
'silent': True,
'verbose': -1,
}
model = clf.train(params, train_matrix, 5000, valid_sets=[train_matrix, valid_matrix],
categorical_feature = categorical_feature,
verbose_eval=500,early_stopping_rounds=200)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
train[valid_index] = val_pred
test += test_pred / kf.n_splits
cv_scores.append(mean_squared_error(val_y, val_pred))
print(cv_scores)
print("%s_scotrainre_list:" % clf_name, cv_scores)
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
print("%s_score_std:" % clf_name, np.std(cv_scores))
return train, test
lgb_train, lgb_test = cv_model(lgb, x_train, y_train, x_test)
sample_submit['weekly_sales'] = lgb_test
sample_submit['weekly_sales'] = sample_submit['weekly_sales'].apply(lambda x:x if x>0 else 0).values
sample_submit.to_csv('baseline_result.csv', index=False)
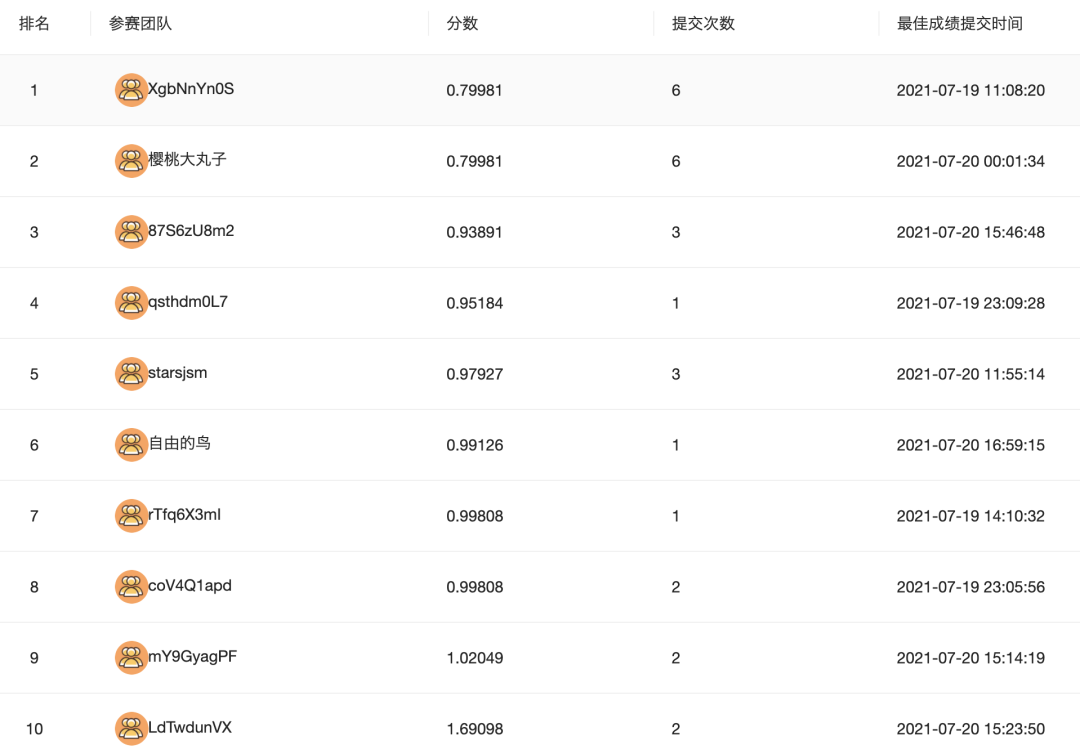
结果提交后线上mse能到0.99808,听说参数调整后能到0.9左右。
更多干货获取
Kaggle竞赛讲义:公众号回复 讲义
获取推荐系统知识卡片:公众号回复 推荐系统
获取数据科学速查表(传统CTR、深度学习CTR、Graph Embedding、多任务学习):公众号回复 速查表
获取历届腾讯广告算法大赛答辩PPT:公众号回复 腾讯赛
获取KDD Cup历史比赛合集:公众号回复 KDD2020
获取


文章转载自Coggle数据科学,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
