




内容说明
内容以天池地表建筑物识别比赛为具体实践案例,配套撰写了相应的学习教程。
天池学习赛:https://tianchi.aliyun.com/competition/entrance/531872/introduction
教程Github:https://github.com/datawhalechina/team-learning-cv

47页PDF版本领取方式见文末,本文为文字版本的内容,干货较多建议收藏。
贡献者
随机排名,不分先后
闫永强、安晟、宋志龙、王程伟、袁明坤、路建飞、Huijun、阿水
Task1 学习目录
1.1 赛题背景
本次新人赛是Datawhale与天池联合发起的零基础入门系列赛事 —— 零基础入门语义分割之地表建筑物识别。
赛题以计算机视觉为背景,要求选手使用给定的航拍图像训练模型并完成地表建筑物识别任务。为更好的引导大家入门,我们为本赛题定制了学习方案和学习任务,具体包括语义分割的模型和具体的应用案例。在具体任务中我们将讲解具体工具和使用和完成任务的过程。
通过对本方案的完整学习,可以帮助掌握语义分割基本技能。同时我们也将提供专属的视频直播学习通道。
1.2 任务安排
Task1:赛题理解与baseline(3天)
学习主题:理解赛题内容解题流程 学习内容:赛题理解、数据读取、比赛baseline构建 学习成果:比赛baseline提交
Task2:数据扩增方法(3天)
学习主题:语义分割任务中数据扩增方法 学习内容:掌握语义分割任务中数据扩增方法的细节和使用 学习成果:数据扩增方法的实践
Task3:网络模型结构发展(3天)
学习主题:掌握语义分割模型的发展脉络 学习内容:FCN、Unet、DeepLab、SegNet、PSPNet 学习成果:多种网络模型的搭建
Task4:评价函数与损失函数(3天)
学习主题:语义分割模型各种评价函数与损失函数 学习内容:Dice、IoU、BCE、Focal Loss、Lovász-Softmax 学习成果:评价/损失函数的实践
Task5:模型训练与验证(3天)
学习主题:数据划分方法 学习内容:三种数据划分方法、模型调参过程 学习成果:数据划分具体操作
Task6:分割模型模型集成(3天)
学习主题:语义分割模型集成方法 学习内容:LookaHead、SnapShot、SWA、TTA 学习成果:模型集成思路
1.3 赛制说明
本次赛事分为两个阶段,分别为正式赛及长期赛。
正式赛
正式赛赛制选手报名成功后,选手下载数据,可以本地或天池PAI平台完成模型训练,并在测试集上进行提交。
长期赛
在正式赛后,本场比赛将长期开放,报名和参赛无时间限制。每天每位参赛选手可提交3次完成初赛打分;排行榜每小时更新,按照评测指标得分从高到低排序;排行榜将选择历史最优成绩进行展示;
1.4 赛题数据
数据说明
赛题数据来源(Inria Aerial Image Labeling),并进行拆分处理。数据集报名后可见并可下载。赛题数据为航拍图,需要参赛选手识别图片中的地表建筑具体像素位置。
评价函数
赛题使用Dice coefficient来衡量选手结果与真实标签的差异性,Dice coefficient可以按像素差异性来比较结果的差异性。Dice coefficient的具体计算方式如下:
其中是预测结果,为真实标签的结果。当与完全相同时Dice coefficient为1,排行榜使用所有测试集图片的平均Dice coefficient来衡量,分数值越大越好。
Task2 赛题理解
本章将对语义分割赛题进行赛题背景讲解,对赛题数据读取进行说明,并给出解题思路。
2.1 学习目标
理解赛题背景和赛题数据 完成赛题报名和数据下载,理解赛题的解题思路
2.2 赛题数据
遥感技术已成为获取地表覆盖信息最为行之有效的手段,遥感技术已经成功应用于地表覆盖检测、植被面积检测和建筑物检测任务。本赛题使用航拍数据,需要参赛选手完成地表建筑物识别,将地表航拍图像素划分为有建筑物和无建筑物两类。
赛题数据来源(Inria Aerial Image Labeling),并进行拆分处理。数据集报名后可见并可下载。赛题数据为航拍图,需要参赛选手识别图片中的地表建筑具体像素位置。
2.3 数据标签
赛题为语义分割任务,因此具体的标签为图像像素类别。在赛题数据中像素属于2类(无建筑物和有建筑物),因此标签为有建筑物的像素。赛题原始图片为jpg格式,标签为RLE编码的字符串。

RLE全称(run-length encoding),翻译为游程编码或行程长度编码,对连续的黑、白像素数以不同的码字进行编码。RLE是一种简单的非破坏性资料压缩法,经常用在在语义分割比赛中对标签进行编码。
RLE与图片之间的转换如下:
import numpy as np
import pandas as pd
import cv2
# 将图片编码为rle格式
def rle_encode(im):
'''
im: numpy array, 1 - mask, 0 - background
Returns run length as string formated
'''
pixels = im.flatten(order = 'F')
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return ' '.join(str(x) for x in runs)
# 将rle格式进行解码为图片
def rle_decode(mask_rle, shape=(512, 512)):
'''
mask_rle: run-length as string formated (start length)
shape: (height,width) of array to return
Returns numpy array, 1 - mask, 0 - background
'''
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
img[lo:hi] = 1
return img.reshape(shape, order='F')
2.4 评价指标
赛题使用Dice coefficient来衡量选手结果与真实标签的差异性,Dice coefficient可以按像素差异性来比较结果的差异性。Dice coefficient的具体计算方式如下:
其中是预测结果,为真实标签的结果。当与完全相同时Dice coefficient为1,排行榜使用所有测试集图片的平均Dice coefficient来衡量,分数值越大越好。
读取数据
| FileName | Size | 含义 |
|---|---|---|
| test_a.zip | 314.49MB | 测试集A榜图片 |
| test_a_samplesubmit.csv | 46.39KB | 测试集A榜提交样例 |
| train.zip | 3.68GB | 训练集图片 |
| train_mask.csv.zip | 97.52MB | 训练集图片标注 |
具体数据读取案例:
import pandas as pd
import cv2
train_mask = pd.read_csv('train_mask.csv', sep='\t', names=['name', 'mask'])
# 读取第一张图,并将对于的rle解码为mask矩阵
img = cv2.imread('train/'+ train_mask['name'].iloc[0])
mask = rle_decode(train_mask['mask'].iloc[0])
print(rle_encode(mask) == train_mask['mask'].iloc[0])
# 结果为True
2.5 解题思路
由于本次赛题是一个典型的语义分割任务,因此可以直接使用语义分割的模型来完成:
步骤1:使用FCN模型模型跑通具体模型训练过程,并对结果进行预测提交; 步骤2:在现有基础上加入数据扩增方法,并划分验证集以监督模型精度; 步骤3:使用更加强大模型结构(如Unet和PSPNet)或尺寸更大的输入完成训练; 步骤4:训练多个模型完成模型集成操作;
2.6 本章小结
本章主要对赛题背景和主要任务进行讲解,并多对赛题数据和标注读取方式进行介绍,最后列举了赛题解题思路。
2.7 课后作业
理解RLE编码过程,并完成赛题数据读取并可视化; 统计所有图片整图中没有任何建筑物像素占所有训练集图片的比例; 统计所有图片中建筑物像素占所有像素的比例; 统计所有图片中建筑物区域平均区域大小;
Task3 数据扩增
本章对语义分割任务中常见的数据扩增方法进行介绍,并使用OpenCV和albumentations两个库完成具体的数据扩增操作。
3.1 学习目标
理解基础的数据扩增方法 学习OpenCV和albumentations完成数据扩增 Pytorch完成赛题读取
3.2 常见的数据扩增方法
数据扩增是一种有效的正则化方法,可以防止模型过拟合,在深度学习模型的训练过程中应用广泛。数据扩增的目的是增加数据集中样本的数据量,同时也可以有效增加样本的语义空间。
需注意:
不同的数据,拥有不同的数据扩增方法; 数据扩增方法需要考虑合理性,不要随意使用; 数据扩增方法需要与具体任何相结合,同时要考虑到标签的变化;
对于图像分类,数据扩增方法可以分为两类:
标签不变的数据扩增方法:数据变换之后图像类别不变; 标签变化的数据扩增方法:数据变换之后图像类别变化;
而对于语义分割而言,常规的数据扩增方法都会改变图像的标签。如水平翻转、垂直翻转、旋转90%、旋转和随机裁剪,这些常见的数据扩增方法都会改变图像的标签,即会导致地标建筑物的像素发生改变。
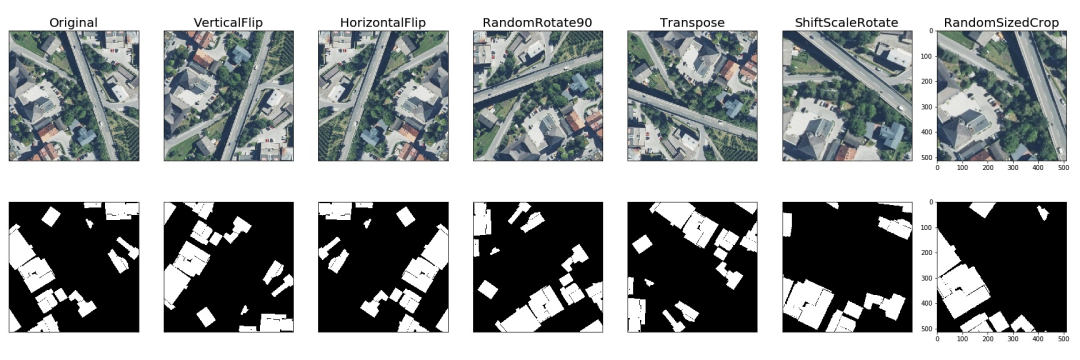
3.3 OpenCV数据扩增
OpenCV是计算机视觉必备的库,可以很方便的完成数据读取、图像变化、边缘检测和模式识别等任务。为了加深各位对数据可做的影响,这里首先介绍OpenCV完成数据扩增的操作。

# 首先读取原始图片
img = cv2.imread(train_mask['name'].iloc[0])
mask = rle_decode(train_mask['mask'].iloc[0])
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.imshow(img)
plt.subplot(1, 2, 2)
plt.imshow(mask)

# 垂直翻转
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.imshow(cv2.flip(img, 0))
plt.subplot(1, 2, 2)
plt.imshow(cv2.flip(mask, 0))

# 水平翻转
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.imshow(cv2.flip(img, 1))
plt.subplot(1, 2, 2)
plt.imshow(cv2.flip(mask, 1))

# 随机裁剪
x, y = np.random.randint(0, 256), np.random.randint(0, 256)
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.imshow(img[x:x+256, y:y+256])
plt.subplot(1, 2, 2)
plt.imshow(mask[x:x+256, y:y+256])

3.4 albumentations数据扩增
albumentations是基于OpenCV的快速训练数据增强库,拥有非常简单且强大的可以用于多种任务(分割、检测)的接口,易于定制且添加其他框架非常方便。
albumentations也是计算机视觉数据竞赛中最常用的库:
GitHub:https://github.com/albumentations-team/albumentations 示例:https://github.com/albumentations-team/albumentations_examples
与OpenCV相比albumentations具有以下优点:
albumentations支持的操作更多,使用更加方便; albumentations可以与深度学习框架(Keras或Pytorch)配合使用; albumentations支持各种任务(图像分流)的数据扩增操作
albumentations它可以对数据集进行逐像素的转换,如模糊、下采样、高斯造点、高斯模糊、动态模糊、RGB转换、随机雾化等;也可以进行空间转换(同时也会对目标进行转换),如裁剪、翻转、随机裁剪等。
import albumentations as A
# 水平翻转
augments = A.HorizontalFlip(p=1)(image=img, mask=mask)
img_aug, mask_aug = augments['image'], augments['mask']
# 随机裁剪
augments = A.RandomCrop(p=1, height=256, width=256)(image=img, mask=mask)
img_aug, mask_aug = augments['image'], augments['mask']
# 旋转
augments = A.ShiftScaleRotate(p=1)(image=img, mask=mask)
img_aug, mask_aug = augments['image'], augments['mask']
albumentations还可以组合多个数据扩增操作得到更加复杂的数据扩增操作:
trfm = A.Compose([
A.Resize(256, 256),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.RandomRotate90(),
])
augments = trfm(image=img, mask=mask)
img_aug, mask_aug = augments['image'], augments['mask']
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.imshow(augments['image'])
plt.subplot(1, 2, 2)
plt.imshow(augments['mask'])

3.5 Pytorch数据读取
由于本次赛题我们使用Pytorch框架讲解具体的解决方案,接下来将是解决赛题的第一步使用Pytorch读取赛题数据。在Pytorch中数据是通过Dataset进行封装,并通过DataLoder进行并行读取。所以我们只需要重载一下数据读取的逻辑就可以完成数据的读取。
Dataset:数据集,对数据进行读取并进行数据扩增; DataLoder:数据读取器,对Dataset进行封装并进行批量读取;
定义Dataset:
import torch.utils.data as D
class TianChiDataset(D.Dataset):
def __init__(self, paths, rles, transform):
self.paths = paths
self.rles = rles
self.transform = transform
self.len = len(paths)
def __getitem__(self, index):
img = cv2.imread(self.paths[index])
mask = rle_decode(self.rles[index])
augments = self.transform(image=img, mask=mask)
return self.as_tensor(augments['image']), augments['mask'][None]
def __len__(self):
return self.len
实例化Dataset:
trfm = A.Compose([
A.Resize(IMAGE_SIZE, IMAGE_SIZE),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.RandomRotate90(),
])
dataset = TianChiDataset(
train_mask['name'].values,
train_mask['mask'].fillna('').values,
trfm
)
实例化DataLoder,批大小为10:
loader = D.DataLoader(
dataset, batch_size=10, shuffle=True, num_workers=0)
3.6 本章小结
本章对数据扩增方法进行简单介绍,并介绍并完成OpenCV数据扩增、albumentations数据扩增和Pytorch读取赛题数据的具体操作。
3.7 课后作业
使用OpenCV完成图像加噪数据扩增; 使用OpenCV完成图像旋转数据扩增; 使用albumentations其他的的操作完成扩增操作; 使用Pytorch完成赛题数据读取;
Task4 语义分割模型发展
语义分割(全像素语义分割)作为经典的计算机视觉任务(图像分类,物体识别检测,语义分割)。其结合了图像分类、目标检测和图像分割,通过一定的方法将图像分割成具有一定语义含义的区域块,并识别出每个区域块的语义类别,实现从底层到高层的语义推理过程,最终得到一幅具有逐像素语义标注的分割图像。
本章主要讲解的是语义分割网络模型的发展:FCN 、SegNet、Unet、DeepLab、RefineNet、PSPNet、GAN语义分割。
4.1 学习目标
掌握语义分割模型的原理和训练过程; 掌握语义分割模型的发展脉络; 掌握语义分割模型的使用;
4.2 FCN
FCN原理及网络结构
FCN首先将一幅RGB图像输入到卷积神经网络后,经过多次卷积以及池化过程得到一系列的特征图,然后利用反卷积层对最后一个卷积层得到的特征图进行上采样,使得上采样后特征图与原图像的大小一样,从而实现对特征图上的每个像素值进行预测的同时保留其在原图像中的空间位置信息,最后对上采样特征图进行逐像素分类,逐个像素计算softmax分类损失。
主要特点:
不含全连接层(FC)的全卷积(Fully Conv)网络。从而可适应任意尺寸输入。 引入增大数据尺寸的反卷积(Deconv)层。能够输出精细的结果。 结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
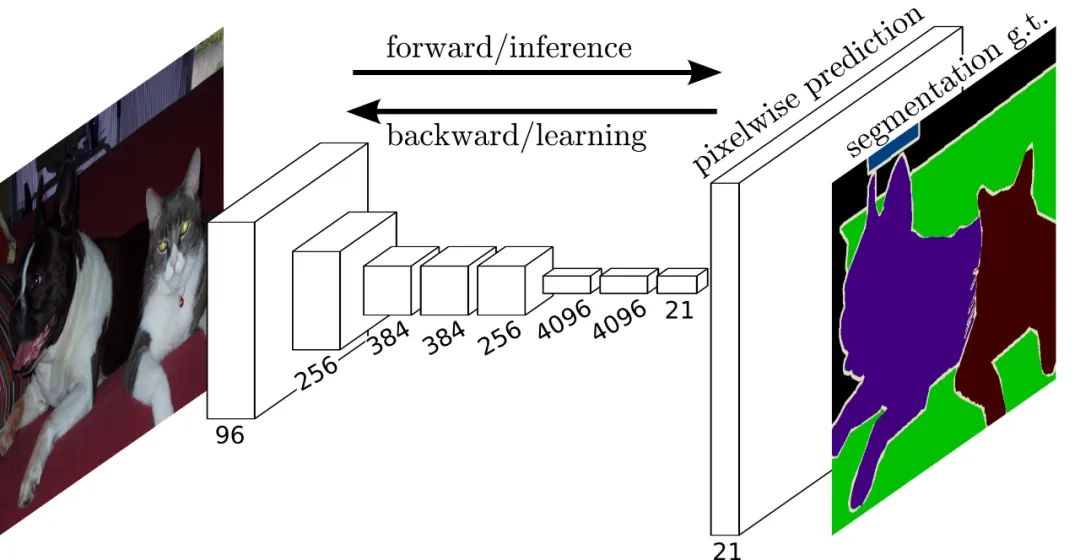
网络结构详解图:输入可为任意尺寸图像彩色图像;输出与输入尺寸相同,深度为20类目标+背景=21,这里的类别与数据集类别保持一致。
反卷积(Deconvolutional)
unsamplingd的操作可以看成是反卷积(Deconvolutional),卷积运算的参数和CNN的参数一样是在训练FCN模型的过程中通过bp算法学习得到。
普通的池化会缩小图片的尺寸,比如VGG16经过5次池化后图片被缩小了32倍。为了得到和原图等大小的分割图,我们需要上采样、反卷积。
反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和反向传播,只用颠倒卷积的前后向传播即可。如下图所示:
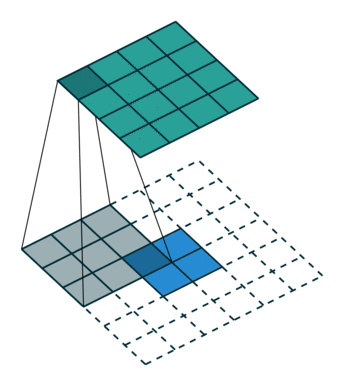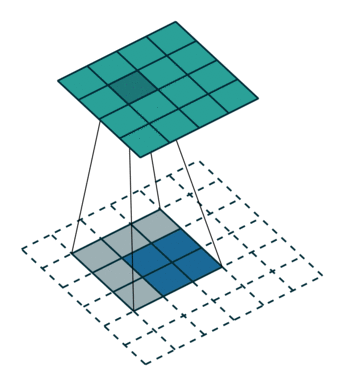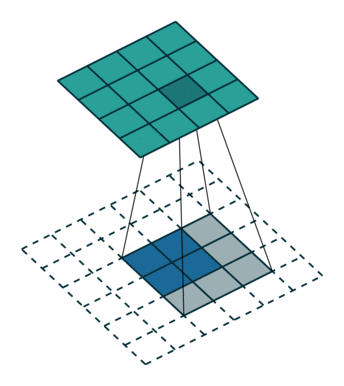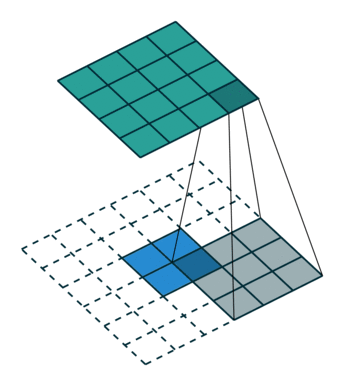
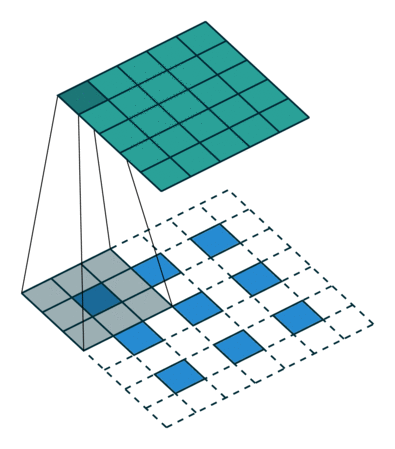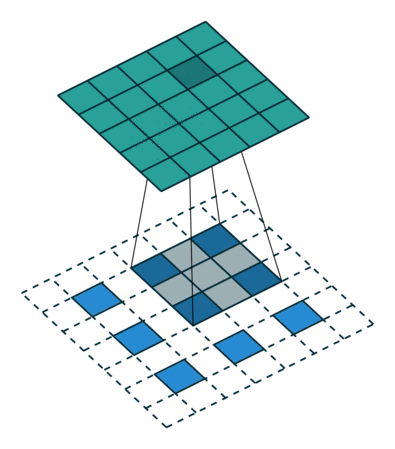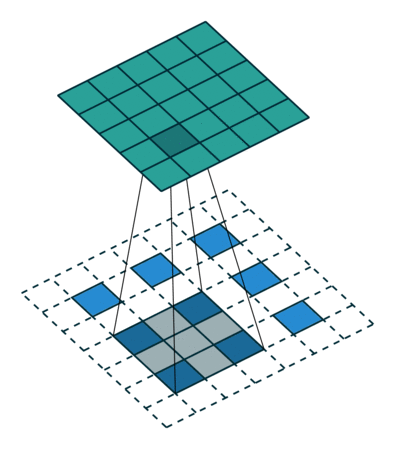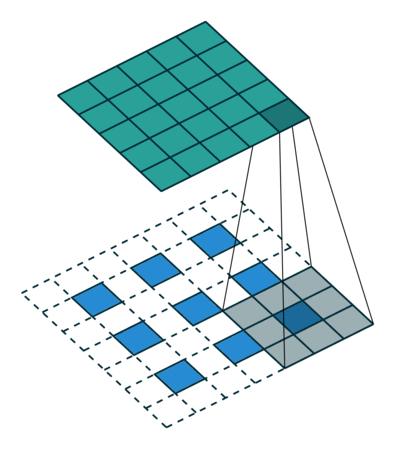
跳跃结构
经过全卷积后的结果进行反卷积,基本上就能实现语义分割了,但是得到的结果通常是比较粗糙的。
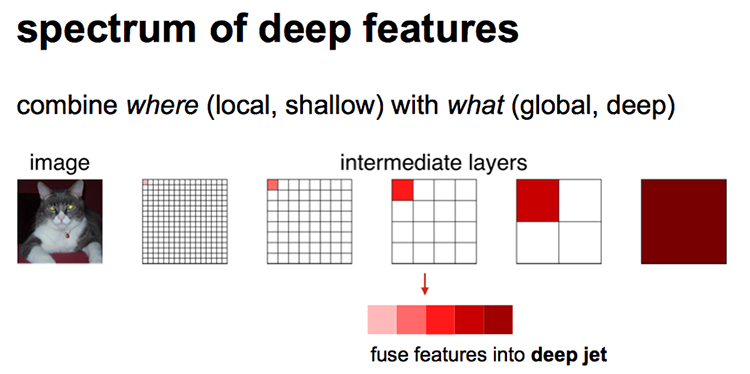
如上图所示,对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时图像不再叫featureMap而是叫heatMap。
现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行upsampling操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征。因此在这里向前迭代,把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节(相当于一个插值过程),最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
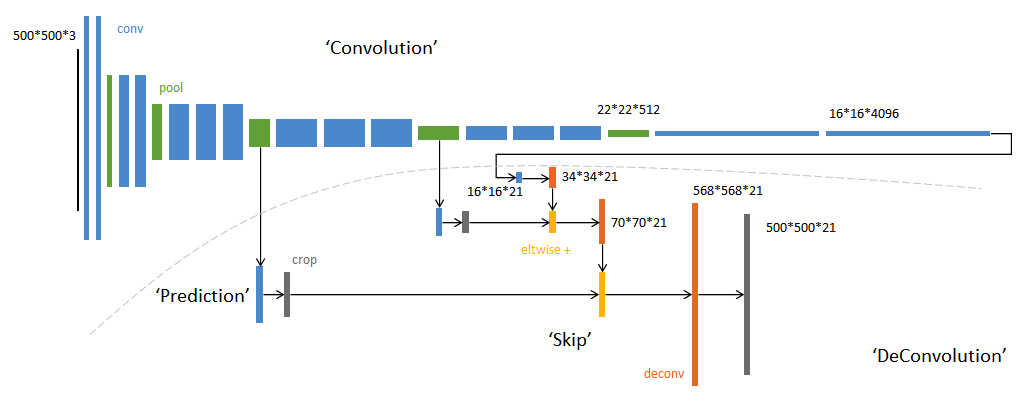
具体来说,就是将不同池化层的结果进行上采样,然后结合这些结果来优化输出,分为FCN-32s,FCN-16s,FCN-8s三种,第一行对应FCN-32s,第二行对应FCN-16s,第三行对应FCN-8s。具体结构如下:
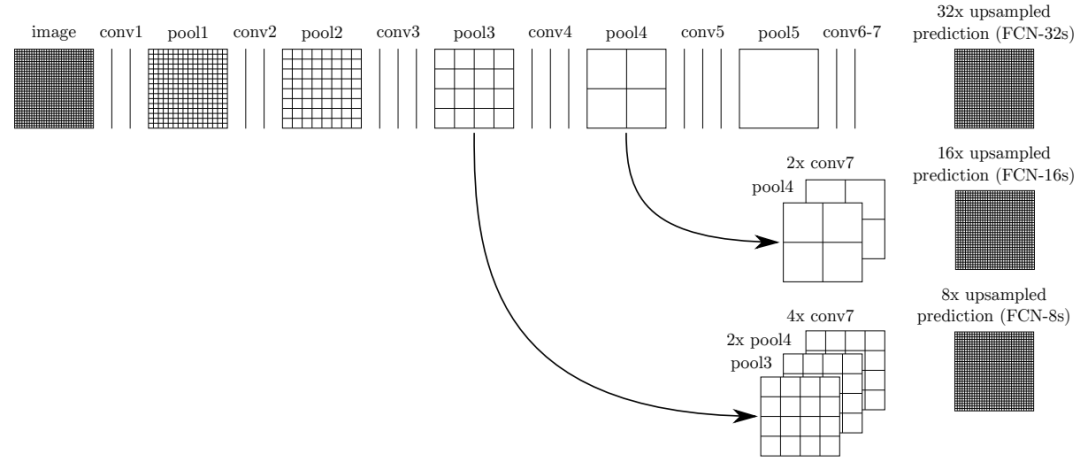
图中,image是原图像,conv1,conv2..,conv5为卷积操作,pool1,pool2,..pool5为pool操作(pool就是使得图片变为原图的1/2),注意con6-7是最后的卷积层,最右边一列是upsample后的end to end结果。必须说明的是图中nx是指对应的特征图上采样n倍(即变大n倍),并不是指有n个特征图,如32x upsampled 中的32x是图像只变大32倍,不是有32个上采样图像,又如2x conv7是指conv7的特征图变大2倍。
(1)FCN-32s过程
只需要留意第一行,网络里面有5个pool,所以conv7的特征图是原始图像1/32,可以发现最左边image的是32x32(假设以倍数计),同时我们知道在FCN中的卷积是不会改变图像大小(或者只有少量像素的减少,特征图大小基本不会小很多)。看到pool1是16x16,pool2是8x8,pool3是4x4,pool4是2x2,pool5是1x1,所以conv7对应特征图大小为1x1,然后再经过32x upsampled prediction 图片变回32x32。FCN作者在这里增加一个卷积层,卷积后的大小为输入图像的32(2^5)倍,我们简单假设这个卷积核大小也为32,这样就是需要通过反馈训练32x32个权重变量即可让图像实现end to end,完成了一个32s的upsample。FCN作者称做后卷积,他也提及可以称为反卷积。事实上在源码中卷积核的大小为64,同时没有偏置bias。还有一点就是FCN论文中最后结果都是21×*,这里的21是指FCN使用的数据集分类,总共有21类。
(2)FCN-16s过程
现在我们把1,2两行一起看,忽略32x upsampled prediction,说明FCN-16s的upsample过程。FCN作者在conv7先进行一个2x conv7操作,其实这里也只是增加1个卷积层,这次卷积后特征图的大小为conv7的2倍,可以从pool5与2x conv7中看出来。此时2x conv7与pool4的大小是一样的,FCN作者提出对pool4与2x conv7进行一个fuse操作(事实上就是将pool4与2x conv7相加,另一篇博客说是拼接,个人认为是拼接)。fuse结果进行16x upsampled prediction,与FCN-32s一样,也是增加一个卷积层,卷积后的大小为输入图像的16(2^4)倍。我们知道pool4的大小是2x2,放大16倍,就是32x32,这样最后图像大小也变为原来的大小,至此完成了一个16s的upsample。现在我们可以知道,FCN中的upsample实际是通过增加卷积层,通过bp反馈的训练方法训练卷积层达到end to end,这时卷积层的作用可以看作是pool的逆过程。
(3)FCN-8s过程
这是我们看第1行与第3行,忽略32x upsampled prediction。conv7经过一次4x upsample,即使用一个卷积层,特征图输出大小为conv7的4倍,所得4x conv7的大小为4x4。然后pool4需要一次2x upsample,变成2x pool4,大小也为4x4。再把4x conv7,2x pool4与pool3进行fuse,得到求和后的特征图。最后增加一个卷积层,使得输出图片大小为pool3的8倍,也就是8x upsampled prediction的过程,得到一个end to end的图像。实验表明FCN-8s优于FCN-16s,FCN-32s。我们可以发现,如果继续仿照FCN作者的步骤,我们可以对pool2,pool1实现同样的方法,可以有FCN-4s,FCN-2s,最后得到end to end的输出。这里作者给出了明确的结论,超过FCN-8s之后,结果并不能继续优化。
结合上述的FCN的全卷积与upsample,在upsample最后加上softmax,就可以对不同类别的大小概率进行估计,实现end to end。最后输出的图是一个概率估计,对应像素点的值越大,其像素为该类的结果也越大。FCN的核心贡献在于提出使用卷积层通过学习让图片实现end to end分类。
事实上,FCN有一些短处,例如使用了较浅层的特征,因为fuse操作会加上较上层的pool特征值,导致高维特征不能很好得以使用,同时也因为使用较上层的pool特征值,导致FCN对图像大小变化有所要求,如果测试集的图像远大于或小于训练集的图像,FCN的效果就会变差。
训练过程
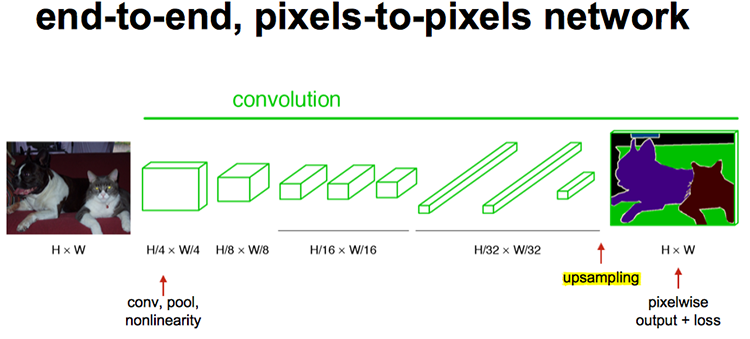
FCN训练过程分为四个阶段:
第1阶段
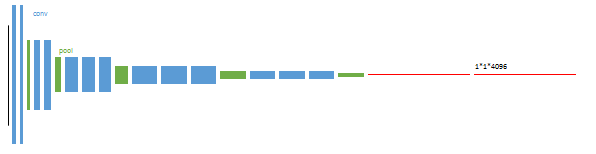
以经典的分类网络为初始化,最后两级是全连接(红色),参数舍弃不用。
第2阶段
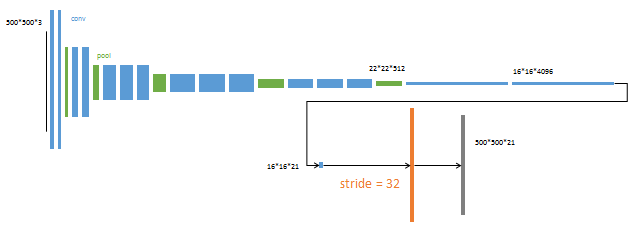
从特征图(16x16x4096)预测分割小图( 16x16x21),之后直接升采样为大图。反卷积(橙色)的步长为32,这个网络称为FCN-32s。
第3阶段
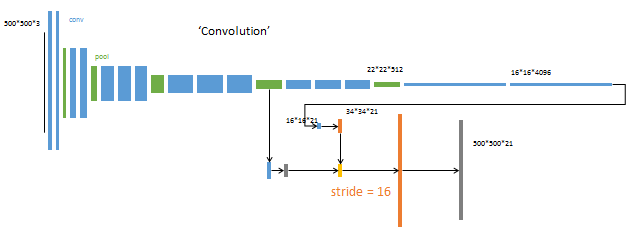
升采样分为两次完成(橙色×2)。在第二次升采样前,把第4个pooling层(绿色)的预测结果(蓝色)融合进来。使用跳级结构提升精确性。第二次反卷积步长为16,这个网络称为FCN-16s。
第4阶段
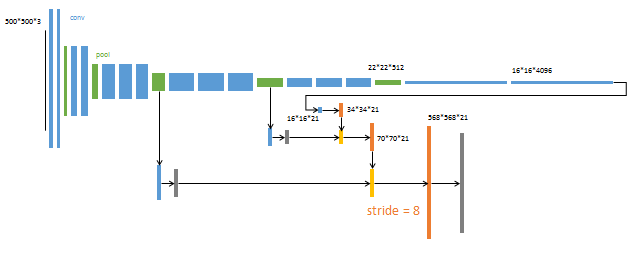
升采样分为三次完成(橙色×3)。进一步融合了第3个pooling层的预测结果。第三次反卷积步长为8,记为FCN-8s。这一阶段使用单GPU训练约需1天。
较浅层的预测结果包含了更多细节信息。比较2,3,4阶段可以看出,跳级结构利用浅层信息辅助逐步升采样,有更精细的结果。
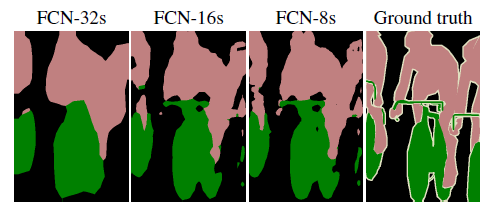
FCN原理参考连接:
https://blog.csdn.net/qinghuaci666/article/details/80863032 https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
4.3 SegNet
Segnet是用于进行像素级别图像分割的全卷积网络,分割的核心组件是一个encoder 网络,及其相对应的decoder网络,后接一个象素级别的分类网络。
encoder网络:其结构与VGG16网络的前13层卷积层的结构相似。decoder网络:作用是将由encoder的到的低分辨率的feature maps 进行映射得到与输入图像featuremap相同的分辨率进而进行像素级别的分类。
Segnet的亮点:decoder进行上采样的方式,直接利用与之对应的encoder阶段中进行max-pooling时的polling index 进行非线性上采样,这样做的好处是上采样阶段就不需要进行学习。上采样后得到的feature maps 是非常稀疏的,因此,需要进一步选择合适的卷积核进行卷积得到dense featuremaps 。
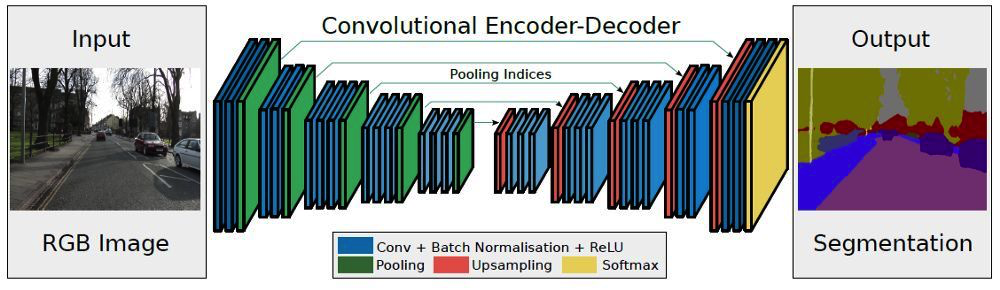
SegNet的思路和FCN十分相似,只是Encoder,Decoder(Unsampling)使用的技术不一样。SegNet的编码器部分使用的是VGG16的前13层卷积网络,每个编码器层都对应一个解码器层,最终解码器的输出被送入soft-max分类器以独立的为每个像素产生类别概率。
左边是卷积提取特征,通过pooling增大感受野,同时图片变小,该过程称为Encoder,右边是反卷积(在这里反卷积与卷积没有区别)与unsampling,通过反卷积使得图像分类后特征得以重现,upsampling还原到原图想尺寸,该过程称为Decoder,最后通过Softmax,输出不同分类的最大值,得到最终分割图。
Encoder编码器
在编码器处,执行卷积和最大池化。 VGG-16有13个卷积层。(不用全连接的层) 在进行2×2最大池化时,存储相应的最大池化索引(位置)。
Decoder解码器
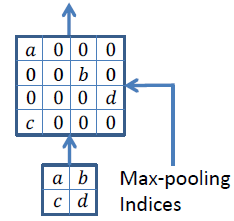
使用最大池化的索引进行上采样
在解码器处,执行上采样和卷积。最后,每个像素送到softmax分类器。 在上采样期间,如上所示,调用相应编码器层处的最大池化索引以进行上采样。 最后,使用K类softmax分类器来预测每个像素的类别。
4.4 Unet
U-net对称语义分割模型,该网络模型主要由一个收缩路径和一个对称扩张路径组成,收缩路径用来获得上下文信息,对称扩张路径用来精确定位分割边界。U-net使用图像切块进行训练,所以训练数据量远远大于训练图像的数量,这使得网络在少量样本的情况下也能获得不变性和鲁棒性。
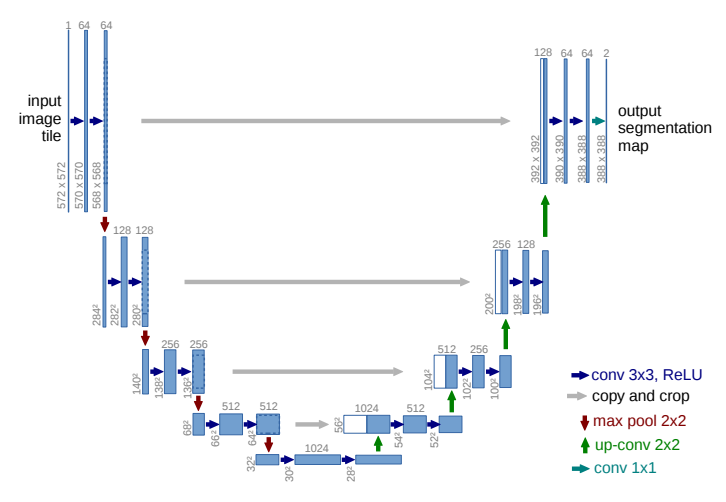
Encoder:左半部分,由两个3x3的卷积层(RELU)+2x2的max pooling层(stride=2)反复组成,每经过一次下采样,通道数翻倍;
Decoder:右半部分,由一个2x2的上采样卷积层(RELU)+Concatenation(crop对应的Encoder层的输出feature map然后与Decoder层的上采样结果相加)+2个3x3的卷积层(RELU)反复构成;
最后一层通过一个1x1卷积将通道数变成期望的类别数。
4.5 DeepLab
基于全卷积对称语义分割模型得到的分割结果比较粗糙,忽略了像素与像素之间的空间一致性关系。于是Google提出了一种新的扩张卷积语义分割模型,考虑了像素与像素之间的空间一致性关系,可以在不增加数量的情况下增加感受野。
Deeplabv1是由深度卷积网路和概率图模型级联而成的语义分割模型,由于深度卷积网路在重复最大池化和下采样的过程中会丢失很多的细节信息,所以采用扩张卷积算法增加感受野以获得更多上下文信息。考虑到深度卷积网路在图像标记任务中的空间不敏感性限制了它的定位精度,采用了完全连接条件随机场(Conditional Random Field, CRF)来提高模型捕获细节的能力。 Deeplabv2予以分割模型增加了ASPP(Atrous spatial pyramid pooling)结构,利用多个不同采样率的扩张卷积提取特征,再将特征融合以捕获不同大小的上下文信息。 Deeplabv3语义分割模型,在ASPP中加入了全局平均池化,同时在平行扩张卷积后添加批量归一化,有效地捕获了全局语义信息。 DeepLabV3+语义分割模型在Deeplabv3的基础上增加了编-解码模块和Xception主干网路,增加编解码模块主要是为了恢复原始的像素信息,使得分割的细节信息能够更好的保留,同时编码丰富的上下文信息。增加Xception主干网络是为了采用深度卷积进一步提高算法的精度和速度。在inception结构中,先对输入进行11卷积,之后将通道分组,分别使用不同的33卷积提取特征,最后将各组结果串联在一起作为输出。
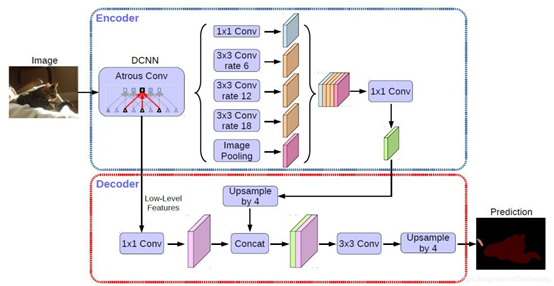
主要特点:
在多尺度上为分割对象进行带洞空间金字塔池化(ASPP) 通过使用DCNNs(空洞卷积)提升了目标边界的定位 降低了由DCNN的不变性导致的定位准确率
4.6 RefineNet
RefineNet采用了通过细化中间激活映射并分层地将其链接到结合多尺度激活,同时防止锐度损失。网络由独立的RefineNet模块组成,每个模块对应于ResNet。
每个RefineNet模块由三个主要模块组成,即剩余卷积单元(RCU),多分辨率融合(MRF)和链剩余池(CRP)。RCU块由一个自适应块组成卷积集,微调预训练的ResNet权重对于分割问题。MRF层融合不同的激活物使用卷积上采样层来创建更高的分辨率地图。最后,在CRP层池中使用多种大小的内核用于从较大的图像区域捕获背景上下文。
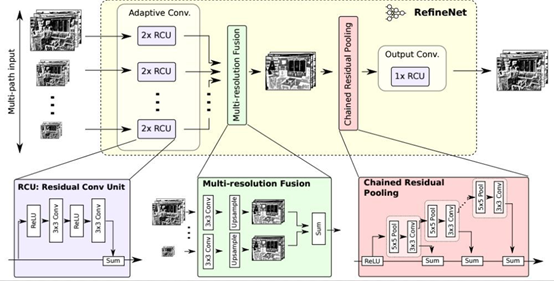
主要特点:
提出一种多路径refinement网络,称为RefineNet。这种网络可以使用各个层级的features,使得语义分割更为精准。 RefineNet中所有部分都利用resdiual connections (identity mappings),使得梯度更容易短向或者长向前传,使端对端的训练变得更加容易和高效。 提出了一种叫做chained residual pooling的模块,它可以从一个大的图像区域捕捉背景上下文信息。
3.7 PSPNet
深度卷积神经网络的每一层特征对语义分割都有影响,如何将高层特征的语义信息与底层识别的边界与轮廓信息结合起来是一个具有挑战性的问题。
金字塔场景稀疏网络语义分割模型(Pyramid Scene Parsing Network,PSP)首先结合预训练网络 ResNet和扩张网络来提取图像的特征,得到原图像 1/8 大小的特征图,然后,采用金字塔池化模块将特征图同时通过四个并行的池化层得到四个不同大小的输出,将四个不同大小的输出分别进行上采样,还原到原特征图大小,最后与之前的特征图进行连接后经过卷积层得到最后的预测分割图像。
PSPNet为像素级场景解析提供了有效的全局上下文先验 金字塔池化模块可以收集具有层级的信息,比全局池化更有代表性 在计算量方面,我们的PSPNet并没有比原来的空洞卷积FCN网络有很大的增加 在端到端学习中,全局金字塔池化模块和局部FCN特征可以被同时训练
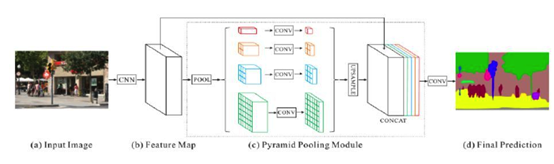
主要特点:
金字塔场景解析网络是建立在FCN之上的基于像素级分类网络。将大小不同的内核集中在一起激活地图的不同区域创建空间池金字塔。 特性映射来自网络被转换成不同分辨率的激活,并经过多尺度处理池层,稍后向上采样并与原始层连接进行分割的feature map。 学习的过程利用辅助分类器进一步优化了像ResNet这样的深度网络。不同类型的池模块侧重于激活的不同区域地图。
4.8 基于全卷积的GAN语义分割模型
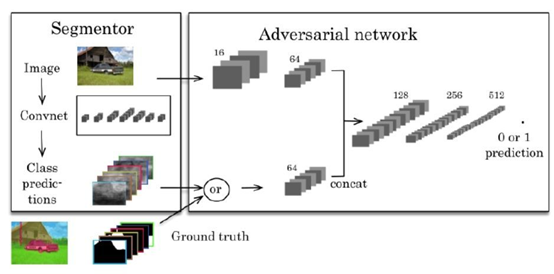
生成对抗网络模型(Generative Adversarial Nets,GAN)同时训练生成器 G 和判别器 D,判别器用来预测给定样本是来自于真实数据还是来自于生成模型。
利用对抗训练方法训练语义分割模型,将传统的多类交叉熵损失与对抗网络相结合,首先对对抗网络进行预训练,然后使用对抗性损失来微调分割网络,如下图所示。左边的分割网络将 RGB 图像作为输入,并产生每个像素的类别预测。右边的对抗网络将标签图作为输入并生成类标签(1 代表真实标注,0 代表合成标签)。
参考链接:https://cloud.tencent.com/developer/article/1589733
4.9 具体调用
对于常见的语义分割模型,推荐可以直接使用segmentation_models_pytorch库完成:
import segmentation_models_pytorch as smp
model = smp.Unet(
encoder_name="resnet34", # choose encoder, e.g. mobilenet_v2 or efficientnet-b7
encoder_weights="imagenet", # use `imagenet` pre-trained weights for encoder initialization
in_channels=1, # model input channels (1 for gray-scale images, 3 for RGB, etc.)
classes=3, # model output channels (number of classes in your dataset)
)
4.10 本章小结
本章对常见的语义分割网络模型进行介绍,并使用segmentation_models_pytorch完成具体调用。
4.11 课后作业
理解语义分割模型构造过程,特别是最终概率值的输出; 理解FCN的网络模型结构和训练过程;
Task5 评价函数与损失函数
本章主要介绍语义分割的评价函数和各类损失函数。
5.1 学习目标
掌握常见的评价函数和损失函数Dice、IoU、BCE、Focal Loss、Lovász-Softmax; 掌握评价/损失函数的实践;
5.2 TP TN FP FN
在讲解语义分割中常用的评价函数和损失函数之前,先补充一**TP(真正例 true positive) TN(真反例 true negative) FP(假正例 false positive) FN(假反例 false negative)**的知识。在分类问题中,我们经常看到上述的表述方式,以二分类为例,我们可以将所有的样本预测结果分成TP、TN、 FP、FN四类,并且每一类含有的样本数量之和为总样本数量,即TP+FP+FN+TN=总样本数量。其混淆矩阵如下:
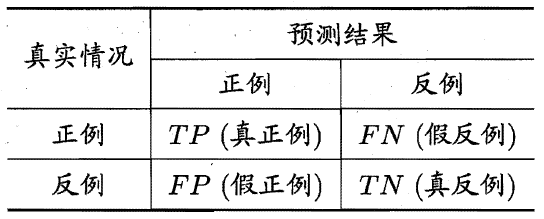
上述的概念都是通过以预测结果的视角定义的,可以依据下面方式理解:
预测结果中的正例 → 在实际中是正例 → 的所有样本被称为真正例(TP)<预测正确>
预测结果中的正例 → 在实际中是反例 → 的所有样本被称为假正例(FP)<预测错误>
预测结果中的反例 → 在实际中是正例 → 的所有样本被称为假反例(FN)<预测错误>
预测结果中的反例 → 在实际中是反例 → 的所有样本被称为真反例(TN)<预测正确>
这里就不得不提及精确率(precision)和召回率(recall):
代表了预测的正例中真正的正例所占比例;代表了真正的正例中被正确预测出来的比例。
转移到语义分割任务中来,我们可以将语义分割看作是对每一个图像像素的的分类问题。根据混淆矩阵中的定义,我们亦可以将特定像素所属的集合或区域划分成TP、TN、 FP、FN四类。

以上面的图片为例,图中左子图中的人物区域(黄色像素集合)是我们真实标注的前景信息(target),其他区域(紫色像素集合)为背景信息。当经过预测之后,我们会得到的一张预测结果,图中右子图中的黄色像素为预测的前景(prediction),紫色像素为预测的背景区域。此时,我们便能够将预测结果分成4个部分:
预测结果中的黄色无线区域 → 真实的前景 → 的所有像素集合被称为真正例(TP)<预测正确>
预测结果中的蓝色斜线区域 → 真实的背景 → 的所有像素集合被称为假正例(FP)<预测错误>
预测结果中的红色斜线区域 → 真实的前景 → 的所有像素集合被称为假反例(FN)<预测错误>
预测结果中的白色斜线区域 → 真实的背景 → 的所有像素集合被称为真反例(TN)<预测正确>
5.3 Dice评价指标
Dice系数
Dice系数(Dice coefficient)是常见的评价分割效果的方法之一,同样也可以改写成损失函数用来度量prediction和target之间的距离。Dice系数定义如下:
式中:表示真实前景(target),表示预测前景(prediction)。Dice系数取值范围为,其中值为1时代表预测与真实完全一致。仔细观察,Dice系数与分类评价指标中的F1 score很相似:
所以,Dice系数不仅在直观上体现了target与prediction的相似程度,同时其本质上还隐含了精确率和召回率两个重要指标。
计算Dice时,将近似为prediction与target对应元素相乘再相加的结果。 和的计算直接进行简单的元素求和(也有一些做法是取平方求和),如下示例:
Dice Loss
Dice Loss是在V-net模型中被提出应用的,是通过Dice系数转变而来,其实为了能够实现最小化的损失函数,以方便模型训练,以的形式作为损失函数:
在一些场合还可以添加上Laplace smoothing减少过拟合:
代码实现
import numpy as np
def dice(output, target):
'''计算Dice系数'''
smooth = 1e-6 # 避免0为除数
intersection = (output * target).sum()
return (2. * intersection + smooth) / (output.sum() + target.sum() + smooth)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = dice(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.5714286326530524
5.4 IoU评价指标
IoU(intersection over union)指标就是常说的交并比,不仅在语义分割评价中经常被使用,在目标检测中也是常用的评价指标。顾名思义,交并比就是指target与prediction两者之间交集与并集的比值:
仍然以人物前景分割为例,如下图,其IoU的计算就是使用。

代码实现
def iou_score(output, target):
'''计算IoU指标'''
intersection = np.logical_and(target, output)
union = np.logical_or(target, output)
return np.sum(intersection) / np.sum(union)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = iou_score(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.4
5.5 BCE损失函数
BCE损失函数(Binary Cross-Entropy Loss)是交叉熵损失函数(Cross-Entropy Loss)的一种特例,BCE Loss只应用在二分类任务中。针对分类问题,单样本的交叉熵损失为:
式中,,其中是非0即1的数字,代表了是否属于第类,为真实值;代表属于第i类的概率,为预测值。可以看出,交叉熵损失考虑了多类别情况,针对每一种类别都求了损失。针对二分类问题,上述公式可以改写为:
式中,为真实值,非1即0;为所属此类的概率值,为预测值。这个公式也就是BCE损失函数,即二分类任务时的交叉熵损失。值得强调的是,公式中的为概率分布形式,因此在使用BCE损失前,都应该将预测出来的结果转变成概率值,一般为sigmoid激活之后的输出。
代码实现
在pytorch中,官方已经给出了BCE损失函数的API,免去了自己编写函数的痛苦:
torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean')参数:weight(Tensor)- 为每一批量下的loss添加一个权重,很少使用 size_average(bool)- 弃用中 reduce(bool)- 弃用中 reduction(str) - 'none' | 'mean' | 'sum':为代替上面的size_average和reduce而生。——为mean时返回的该批量样本loss的平均值;为sum时,返回的该批量样本loss之和
同时,pytorch还提供了已经结合了Sigmoid函数的BCE损失:torch.nn.BCEWithLogitsLoss()
,相当于免去了实现进行Sigmoid激活的操作。
import torch
import torch.nn as nn
bce = nn.BCELoss()
bce_sig = nn.BCEWithLogitsLoss()
input = torch.randn(5, 1, requires_grad=True)
target = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(input)
loss_bce = bce(pre, target)
loss_bce_sig = bce_sig(input, target)
# ------------------------
input = tensor([[-0.2296],
[-0.6389],
[-0.2405],
[ 1.3451],
[ 0.7580]], requires_grad=True)
output = tensor([[1.],
[0.],
[0.],
[1.],
[1.]])
pre = tensor([[0.4428],
[0.3455],
[0.4402],
[0.7933],
[0.6809]], grad_fn=<SigmoidBackward>)
print(loss_bce)
tensor(0.4869, grad_fn=<BinaryCrossEntropyBackward>)
print(loss_bce_sig)
tensor(0.4869, grad_fn=<BinaryCrossEntropyWithLogitsBackward>)
5.6 Focal Loss
Focal loss最初是出现在目标检测领域,主要是为了解决正负样本比例失调的问题。那么对于分割任务来说,如果存在数据不均衡的情况,也可以借用focal loss来进行缓解。Focal loss函数公式如下所示:
仔细观察就不难发现,它其实是BCE扩展而来,对比BCE其实就多了个
为什么多了这个就能缓解正负样本不均衡的问题呢?见下图:
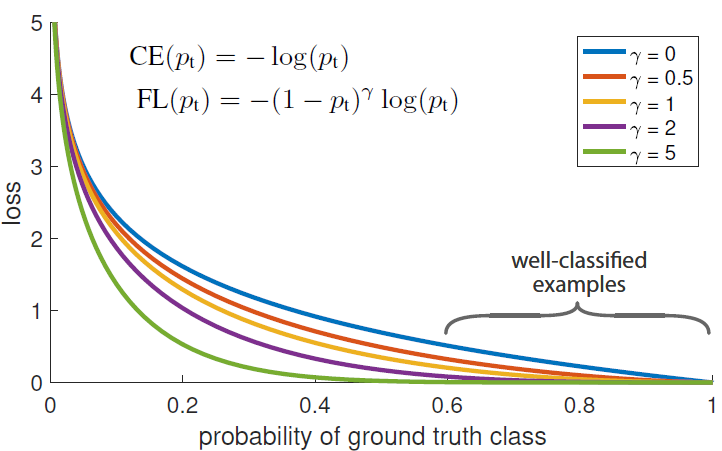
简单来说:解决样本不平衡问题,解决样本难易问题。
也就是说,当数据不均衡时,可以根据比例设置合适的,这个很好理解,为了能够使得正负样本得到的损失能够均衡,因此对loss前面加上一定的权重,其中负样本数量多,因此占用的权重可以设置的小一点;正样本数量少,就对正样本产生的损失的权重设的高一点。
那γ具体怎么起作用呢?以图中曲线为例,假设类别为1,当模型预测结果为1的概率比较大时,我们认为模型预测的比较准确,也就是说这个样本比较简单。而对于比较简单的样本,我们希望提供的loss小一些而让模型主要学习难一些的样本,也就是则loss接近于0,既不用再特别学习;当分类错误时,则loss正常产生,继续学习。对比图中蓝色和绿色曲线,可以看到,γ值越大,当模型预测结果比较准确的时候能提供更小的loss,符合我们为简单样本降低loss的预期。
代码实现:
import torch.nn as nn
import torch
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits # 如果BEC带logits则损失函数在计算BECloss之前会自动计算softmax/sigmoid将其映射到[0,1]
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduce=False)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduce=False)
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
# ------------------------
FL1 = FocalLoss(logits=False)
FL2 = FocalLoss(logits=True)
inputs = torch.randn(5, 1, requires_grad=True)
targets = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(inputs)
f_loss_1 = FL1(pre, targets)
f_loss_2 = FL2(inputs, targets)
# ------------------------
print('inputs:', inputs)
inputs: tensor([[-1.3521],
[ 0.4975],
[-1.0178],
[-0.3859],
[-0.2923]], requires_grad=True)
print('targets:', targets)
targets: tensor([[1.],
[1.],
[0.],
[1.],
[1.]])
print('pre:', pre)
pre: tensor([[0.2055],
[0.6219],
[0.2655],
[0.4047],
[0.4274]], grad_fn=<SigmoidBackward>)
print('f_loss_1:', f_loss_1)
f_loss_1: tensor(0.3375, grad_fn=<MeanBackward0>)
print('f_loss_2', f_loss_2)
f_loss_2 tensor(0.3375, grad_fn=<MeanBackward0>)
5.7 Lovász-Softmax
IoU是评价分割模型分割结果质量的重要指标,因此很自然想到能否用(即Jaccard loss)来做损失函数,但是它是一个离散的loss,不能直接求导,所以无法直接用来作为损失函数。为了克服这个离散的问题,可以采用lLovász extension将离散的Jaccard loss 变得连续,从而可以直接求导,使得其作为分割网络的loss function。Lovász-Softmax相比于交叉熵函数具有更好的效果。
论文地址:https://arxiv.org/abs/1705.08790
首先明确定义,在语义分割任务中,给定真实像素标签向量和预测像素标签,则所属类别的IoU(也称为Jaccard index)如下,其取值范围为,并规定:
则Jaccard loss为:
针对类别,所有未被正确预测的像素集合定义为:
则可将Jaccard loss改写为关于的子模集合函数(submodular set functions):
方便理解,此处可以把理解成如图像mask展开成离散一维向量的形式。
Lovász extension可以求解子模最小化问题,并且子模的Lovász extension是凸函数,可以高效实现最小化。在论文中作者对(集合函数)和(集合函数的Lovász extension)进行了定义,为不涉及过多概念以方便理解,此处不再过多讨论。我们可以将理解为一个线性插值函数,可以将这种离散向量连续化,主要是为了方便后续反向传播、求梯度等等。因此我们可以通过这个线性插值函数得到的Lovász extension。
在具有个类别的语义分割任务中,我们使用Softmax函数将模型的输出映射到概率分布形式,类似传统交叉熵损失函数所进行的操作:
式中,表示了像素所属类别的概率。通过上式可以构建每个像素产生的误差:
可知,对于一张图像中所有像素则误差向量为,则可以建立关于的代理损失函数:
当我们考虑整个数据集是,一般会使用mIoU进行度量,因此我们对上述损失也进行平均化处理,则定义的Lovász-Softmax损失函数为:
代码实现
论文作者已经给出了Lovász-Softmax实现代码,并且有pytorch和tensorflow两种版本,并提供了使用demo。此处将针对多分类任务的Lovász-Softmax源码进行展示。
Lovász-Softmax实现链接:https://github.com/bermanmaxim/LovaszSoftmax
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
try:
from itertools import ifilterfalse
except ImportError: # py3k
from itertools import filterfalse as ifilterfalse
# --------------------------- MULTICLASS LOSSES ---------------------------
def lovasz_softmax(probas, labels, classes='present', per_image=False, ignore=None):
"""
Multi-class Lovasz-Softmax loss
probas: [B, C, H, W] Variable, class probabilities at each prediction (between 0 and 1).
Interpreted as binary (sigmoid) output with outputs of size [B, H, W].
labels: [B, H, W] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
per_image: compute the loss per image instead of per batch
ignore: void class labels
"""
if per_image:
loss = mean(lovasz_softmax_flat(*flatten_probas(prob.unsqueeze(0), lab.unsqueeze(0), ignore), classes=classes)
for prob, lab in zip(probas, labels))
else:
loss = lovasz_softmax_flat(*flatten_probas(probas, labels, ignore), classes=classes)
return loss
def lovasz_softmax_flat(probas, labels, classes='present'):
"""
Multi-class Lovasz-Softmax loss
probas: [P, C] Variable, class probabilities at each prediction (between 0 and 1)
labels: [P] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
"""
if probas.numel() == 0:
# only void pixels, the gradients should be 0
return probas * 0.
C = probas.size(1)
losses = []
class_to_sum = list(range(C)) if classes in ['all', 'present'] else classes
for c in class_to_sum:
fg = (labels == c).float() # foreground for class c
if (classes is 'present' and fg.sum() == 0):
continue
if C == 1:
if len(classes) > 1:
raise ValueError('Sigmoid output possible only with 1 class')
class_pred = probas[:, 0]
else:
class_pred = probas[:, c]
errors = (Variable(fg) - class_pred).abs()
errors_sorted, perm = torch.sort(errors, 0, descending=True)
perm = perm.data
fg_sorted = fg[perm]
losses.append(torch.dot(errors_sorted, Variable(lovasz_grad(fg_sorted))))
return mean(losses)
def flatten_probas(probas, labels, ignore=None):
"""
Flattens predictions in the batch
"""
if probas.dim() == 3:
# assumes output of a sigmoid layer
B, H, W = probas.size()
probas = probas.view(B, 1, H, W)
B, C, H, W = probas.size()
probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, C
labels = labels.view(-1)
if ignore is None:
return probas, labels
valid = (labels != ignore)
vprobas = probas[valid.nonzero().squeeze()]
vlabels = labels[valid]
return vprobas, vlabels
def xloss(logits, labels, ignore=None):
"""
Cross entropy loss
"""
return F.cross_entropy(logits, Variable(labels), ignore_index=255)
# --------------------------- HELPER FUNCTIONS ---------------------------
def isnan(x):
return x != x
def mean(l, ignore_nan=False, empty=0):
"""
nanmean compatible with generators.
"""
l = iter(l)
if ignore_nan:
l = ifilterfalse(isnan, l)
try:
n = 1
acc = next(l)
except StopIteration:
if empty == 'raise':
raise ValueError('Empty mean')
return empty
for n, v in enumerate(l, 2):
acc += v
if n == 1:
return acc
return acc / n
5.8 参考链接
https://blog.csdn.net/lingzhou33/article/details/87901365 https://blog.csdn.net/Biyoner/article/details/84728417 https://www.jianshu.com/p/0998e6560288 https://pytorch.org/docs/stable/nn.html#loss-functions https://sudeepraja.github.io/Submodular/
5.9 本章小结
本章对各类评价指标进行介绍,并进行具体代码实践。
5.10 课后作业
理解各类评价函数的原理; 对比各类损失函数原理,并进行具体实践;
Task6 模型训练与验证
一个成熟合格的深度学习训练流程至少具备以下功能:
在训练集上进行训练,并在验证集上进行验证; 模型可以保存最优的权重,并读取权重; 记录下训练集和验证集的精度,便于调参。
为此本章将从构建验证集、模型训练和验证、模型保存与加载和模型调参几个部分讲解,在部分小节中将会结合Pytorch代码进行讲解。
6.1 学习目标
理解验证集的作用,并使用训练集和验证集完成训练 学会使用Pytorch环境下的模型读取和加载,并了解调参流程
6.2 构造验证集
在机器学习模型(特别是深度学习模型)的训练过程中,模型是非常容易过拟合的。深度学习模型在不断的训练过程中训练误差会逐渐降低,但测试误差的走势则不一定。
在模型的训练过程中,模型只能利用训练数据来进行训练,模型并不能接触到测试集上的样本。因此模型如果将训练集学的过好,模型就会记住训练样本的细节,导致模型在测试集的泛化效果较差,这种现象称为过拟合(Overfitting)。与过拟合相对应的是欠拟合(Underfitting),即模型在训练集上的拟合效果较差。
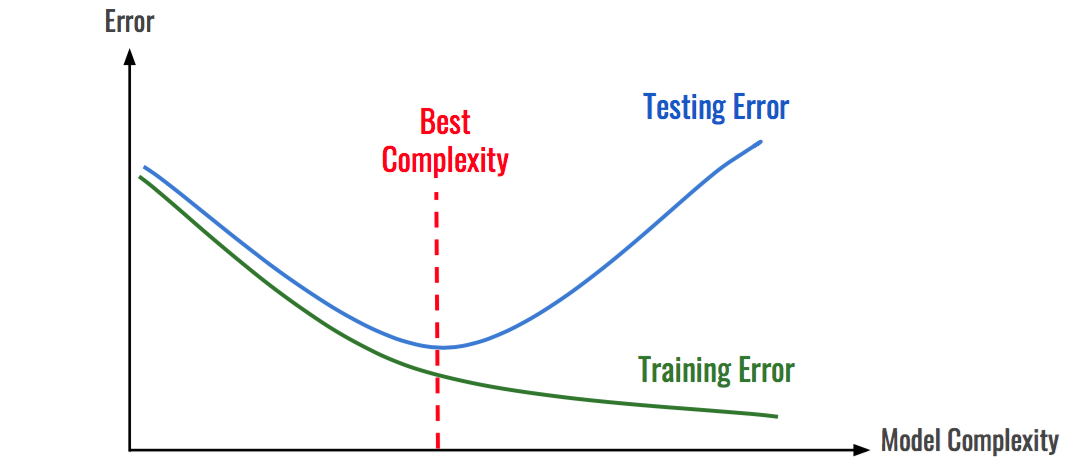
如图所示:随着模型复杂度和模型训练轮数的增加,CNN模型在训练集上的误差会降低,但在测试集上的误差会逐渐降低,然后逐渐升高,而我们为了追求的是模型在测试集上的精度越高越好。
导致模型过拟合的情况有很多种原因,其中最为常见的情况是模型复杂度(Model Complexity )太高,导致模型学习到了训练数据的方方面面,学习到了一些细枝末节的规律。
解决上述问题最好的解决方法:构建一个与测试集尽可能分布一致的样本集(可称为验证集),在训练过程中不断验证模型在验证集上的精度,并以此控制模型的训练。
在给定赛题后,赛题方会给定训练集和测试集两部分数据。参赛者需要在训练集上面构建模型,并在测试集上面验证模型的泛化能力。因此参赛者可以通过提交模型对测试集的预测结果,来验证自己模型的泛化能力。同时参赛方也会限制一些提交的次数限制,以此避免参赛选手“刷分”。
在一般情况下,参赛选手也可以自己在本地划分出一个验证集出来,进行本地验证。训练集、验证集和测试集分别有不同的作用:
训练集(Train Set):模型用于训练和调整模型参数; 验证集(Validation Set):用来验证模型精度和调整模型超参数; 测试集(Test Set):验证模型的泛化能力。
因为训练集和验证集是分开的,所以模型在验证集上面的精度在一定程度上可以反映模型的泛化能力。在划分验证集的时候,需要注意验证集的分布应该与测试集尽量保持一致,不然模型在验证集上的精度就失去了指导意义。
既然验证集这么重要,那么如何划分本地验证集呢。在一些比赛中,赛题方会给定验证集;如果赛题方没有给定验证集,那么参赛选手就需要从训练集中拆分一部分得到验证集。验证集的划分有如下几种方式:
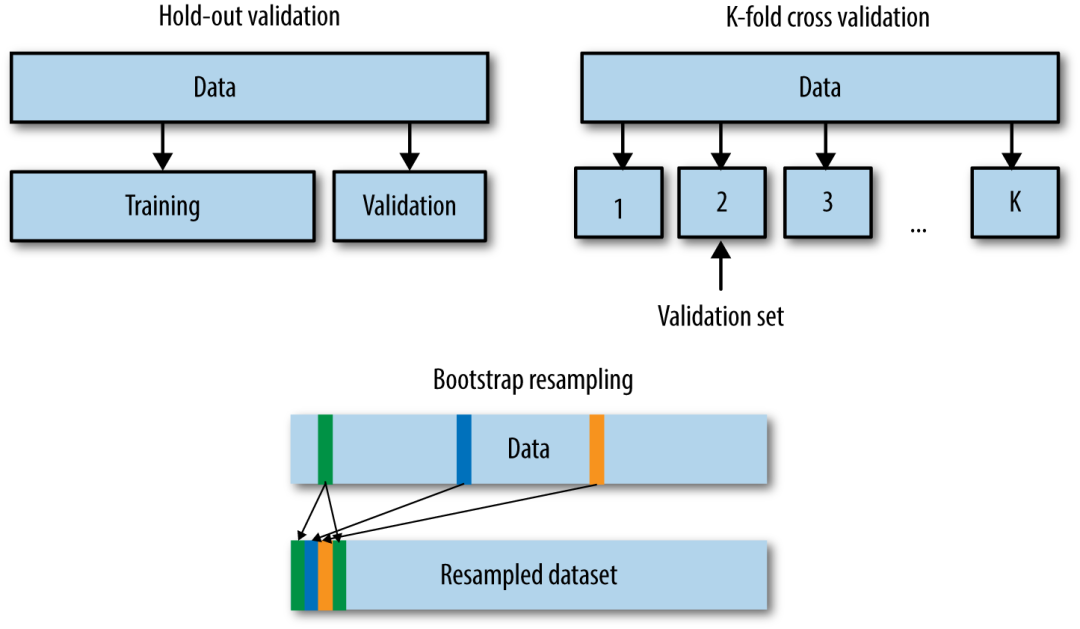
留出法(Hold-Out)
直接将训练集划分成两部分,新的训练集和验证集。这种划分方式的优点是最为直接简单;缺点是只得到了一份验证集,有可能导致模型在验证集上过拟合。留出法应用场景是数据量比较大的情况。
交叉验证法(Cross Validation,CV)
将训练集划分成K份,将其中的K-1份作为训练集,剩余的1份作为验证集,循环K训练。这种划分方式是所有的训练集都是验证集,最终模型验证精度是K份平均得到。这种方式的优点是验证集精度比较可靠,训练K次可以得到K个有多样性差异的模型;CV验证的缺点是需要训练K次,不适合数据量很大的情况。
自助采样法(BootStrap)
通过有放回的采样方式得到新的训练集和验证集,每次的训练集和验证集都是有区别的。这种划分方式一般适用于数据量较小的情况。
在本次赛题中已经划分为验证集,因此选手可以直接使用训练集进行训练,并使用验证集进行验证精度(当然你也可以合并训练集和验证集,自行划分验证集)。
当然这些划分方法是从数据划分方式的角度来讲的,在现有的数据比赛中一般采用的划分方法是留出法和交叉验证法。如果数据量比较大,留出法还是比较合适的。当然任何的验证集的划分得到的验证集都是要保证训练集-验证集-测试集的分布是一致的,所以如果不管划分何种的划分方式都是需要注意的。
这里的分布一般指的是与标签相关的统计分布,比如在分类任务中“分布”指的是标签的类别分布,训练集-验证集-测试集的类别分布情况应该大体一致;如果标签是带有时序信息,则验证集和测试集的时间间隔应该保持一致。
6.3 模型训练与验证
在本节我们目标使用Pytorch来完成CNN的训练和验证过程,CNN网络结构与之前的章节中保持一致。我们需要完成的逻辑结构如下:
构造训练集和验证集; 每轮进行训练和验证,并根据最优验证集精度保存模型。
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=10,
shuffle=True,
num_workers=10,
)
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=10,
shuffle=False,
num_workers=10,
)
model = Model1()
criterion = nn.CrossEntropyLoss(size_average=False)
optimizer = torch.optim.Adam(model.parameters(), 0.001)
best_loss = 1000.0
for epoch in range(20):
print('Epoch: ', epoch)
train(train_loader, model, criterion, optimizer, epoch)
val_loss = validate(val_loader, model, criterion)
# 记录下验证集精度
if val_loss < best_loss:
best_loss = val_loss
torch.save(model.state_dict(), './model.pt')
其中每个Epoch的训练代码如下:
def train(train_loader, model, criterion, optimizer, epoch):
# 切换模型为训练模式
model.train()
for i, (input, target) in enumerate(train_loader):
# 正向传播
# 计算损失
# 反向传播
pass
其中每个Epoch的验证代码如下:
def validate(val_loader, model, criterion):
# 切换模型为预测模型
model.eval()
val_loss = []
# 不记录模型梯度信息
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
# 正向传播
# 计算损失
pass
6.4 模型保存与加载
在Pytorch中模型的保存和加载非常简单,比较常见的做法是保存和加载模型参数:torch.save(model_object.state_dict(), 'model.pt')
model.load_state_dict(torch.load(' model.pt'))
6.5 模型调参流程
深度学习原理少但实践性非常强,基本上很多的模型的验证只能通过训练来完成。同时深度学习有众多的网络结构和超参数,因此需要反复尝试。训练深度学习模型需要GPU的硬件支持,也需要较多的训练时间,如何有效的训练深度学习模型逐渐成为了一门学问。
深度学习有众多的训练技巧,比较推荐的阅读链接有:
http://lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html http://karpathy.github.io/2019/04/25/recipe/
本节挑选了常见的一些技巧来讲解,并针对本次赛题进行具体分析。与传统的机器学习模型不同,深度学习模型的精度与模型的复杂度、数据量、正则化、数据扩增等因素直接相关。所以当深度学习模型处于不同的阶段(欠拟合、过拟合和完美拟合)的情况下,大家可以知道可以什么角度来继续优化模型。
在参加本次比赛的过程中,我建议大家以如下逻辑完成:
初步构建简单的CNN模型,不用特别复杂,跑通训练、验证和预测的流程; 简单CNN模型的损失会比较大,尝试增加模型复杂度,并观察验证集精度; 在增加模型复杂度的同时增加数据扩增方法,直至验证集精度不变。
6.6 本章小节
本章以深度学习模型的训练和验证为基础,讲解了验证集划分方法、模型训练与验证、模型保存和加载以及模型调参流程。
需要注意的是模型复杂度是相对的,并不一定模型越复杂越好。在有限设备和有限时间下,需要选择能够快速迭代训练的模型。
6.7 课后作业
掌握模型训练&模型调参过程; 掌握数据划分方法和具体实践;
Task7 模型集成
在上一章我们学习了如何构建验证集,如何训练和验证。本章作为本次赛题学习的最后一章,将会讲解如何使用集成学习提高预测精度。
本章讲解的知识点包括:集成学习方法、深度学习中的集成学习和结果后处理思路。
7.1 学习目标
学习集成学习方法以及交叉验证情况下的模型集成 学会使用深度学习模型的集成学习
7.2 集成学习方法
在机器学习中的集成学习可以在一定程度上提高预测精度,常见的集成学习方法有Stacking、Bagging和Boosting,同时这些集成学习方法与具体验证集划分联系紧密。
由于深度学习模型一般需要较长的训练周期,如果硬件设备不允许建议选取留出法,如果需要追求精度可以使用交叉验证的方法。
下面假设构建了10折交叉验证,训练得到10个语义分割模型。
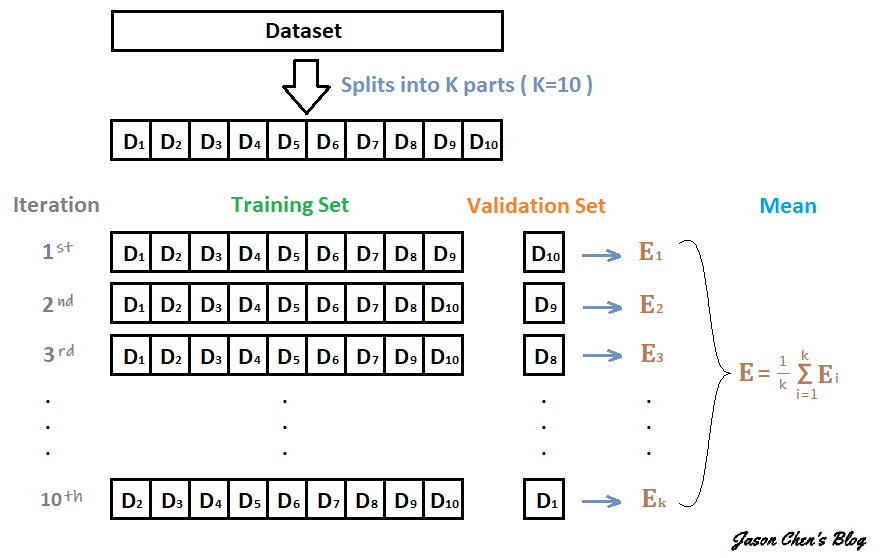
那么在10个CNN模型可以使用如下方式进行集成:
对预测的结果的概率值进行平均,然后解码为具体字符; 对预测的字符进行投票,得到最终字符;
7.3 深度学习中的集成学习
此外在深度学习中本身还有一些集成学习思路的做法,值得借鉴学习:
Dropout
Dropout可以作为训练深度神经网络的一种技巧。在每个训练批次中,通过随机让一部分的节点停止工作。同时在预测的过程中让所有的节点都其作用。
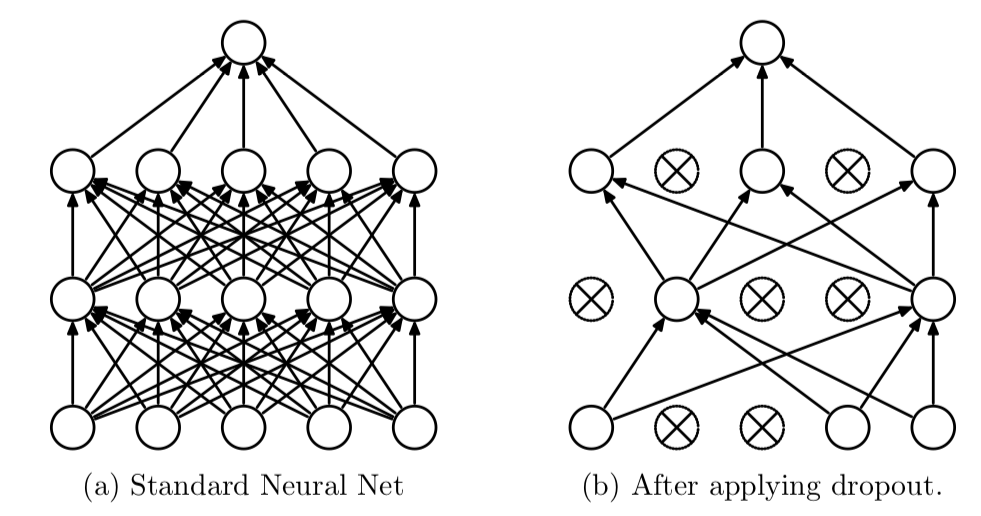
Dropout经常出现在在先有的CNN网络中,可以有效的缓解模型过拟合的情况,也可以在预测时增加模型的精度。
TTA
测试集数据扩增(Test Time Augmentation,简称TTA)也是常用的集成学习技巧,数据扩增不仅可以在训练时候用,而且可以同样在预测时候进行数据扩增,对同一个样本预测三次,然后对三次结果进行平均。
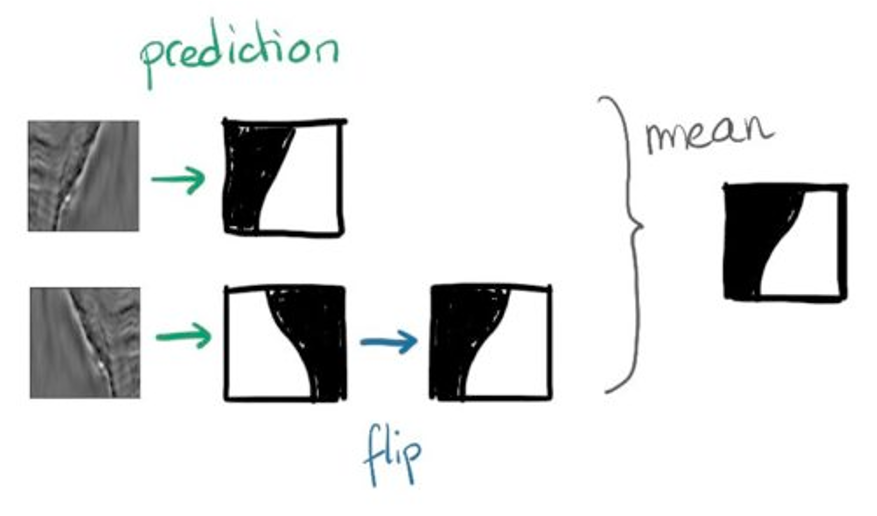
for idx, name in enumerate(tqdm_notebook(glob.glob('./test_mask/*.png')[:])):
image = cv2.imread(name)
image = trfm(image)
with torch.no_grad():
image = image.to(DEVICE)[None]
score1 = model(image).cpu().numpy()
score2 = model(torch.flip(image, [0, 3]))
score2 = torch.flip(score2, [3, 0]).cpu().numpy()
score3 = model(torch.flip(image, [0, 2]))
score3 = torch.flip(score3, [2, 0]).cpu().numpy()
score = (score1 + score2 + score3) / 3.0
score_sigmoid = score[0].argmax(0) + 1
Snapshot
本章的开头已经提到,假设我们训练了10个CNN则可以将多个模型的预测结果进行平均。但是加入只训练了一个CNN模型,如何做模型集成呢?
在论文Snapshot Ensembles中,作者提出使用cyclical learning rate进行训练模型,并保存精度比较好的一些checkopint,最后将多个checkpoint进行模型集成。
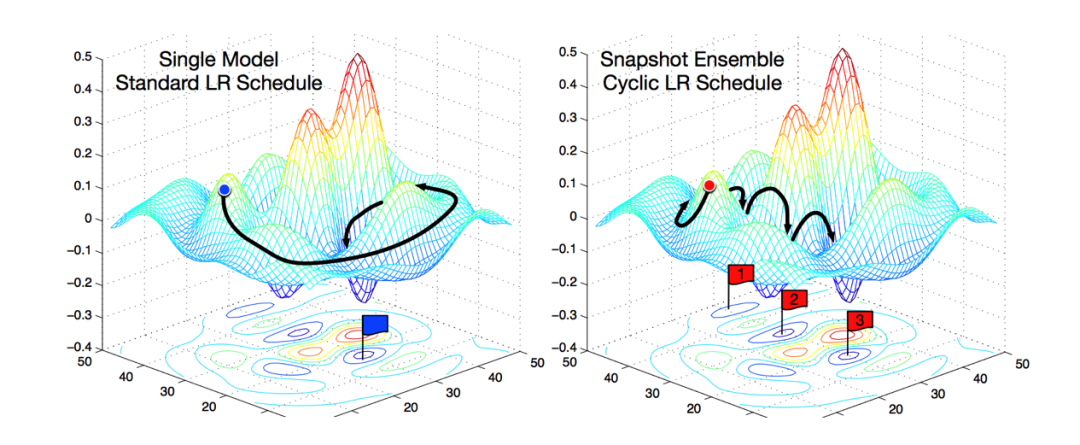
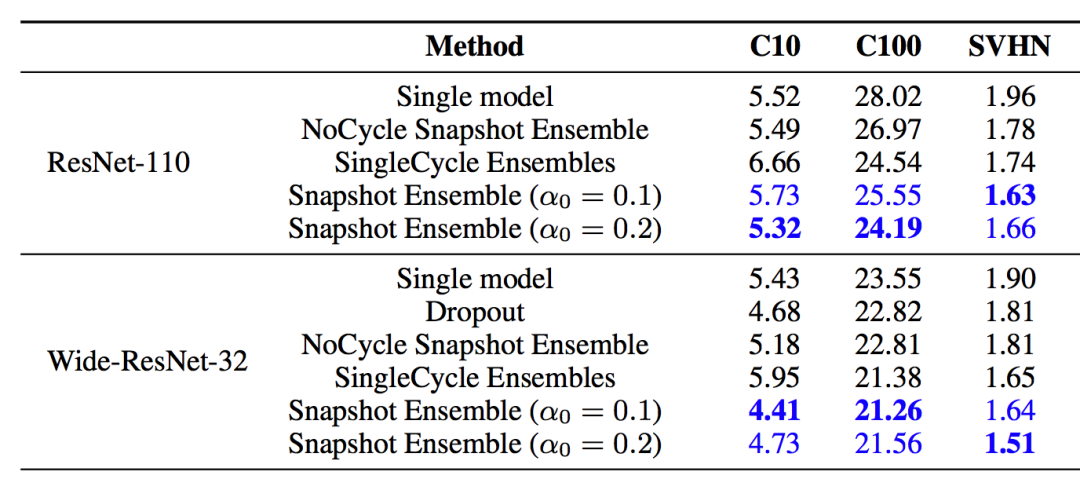
由于在cyclical learning rate中学习率的变化有周期性变大和减少的行为,因此CNN模型很有可能在跳出局部最优进入另一个局部最优。在Snapshot论文中作者通过使用表明,此种方法可以在一定程度上提高模型精度,但需要更长的训练时间。
7.4 本章小节
在本章中我们讲解了深度学习模型做集成学习的各种方法,并以此次赛题为例讲解了部分代码。以下几点需要同学们注意
集成学习只能在一定程度上提高精度,并需要耗费较大的训练时间,因此建议先使用提高单个模型的精度,再考虑集成学习过程; 具体的集成学习方法需要与验证集划分方法结合,Dropout和TTA在所有场景有可以起作用。
7.5 课后作业
使用交叉验证训练模型,得到多个模型权重; 学习Snapshot和TTA的具体用法;
资料领取

领取47页语义分割PDF
关注上面公众号,回复「语义分割」领取
