




一、背景介绍
二、BERT使用框架
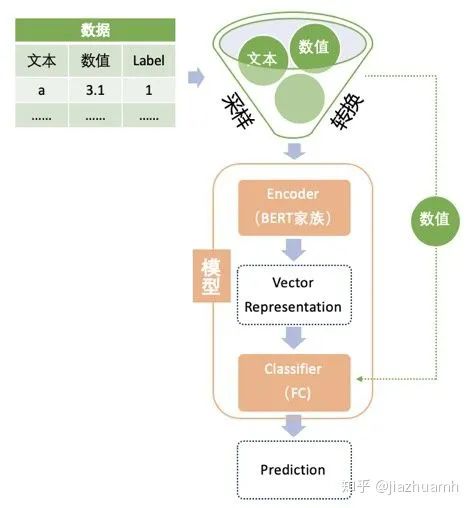 绿色的数据部分,主要包括对数据进行采样,转换成 BERT 输入的格式。NLP 类比赛中的数据大致可分为文本数据和非文本数据,文本数据为主,一般以句子、段落或篇章的形式存在;非文本数据是指数值变量或分类变量,这类变量的处理方法与传统挖掘类比赛一样,因为不是重点,不需要太复杂的处理或转换,并且一般只是作为补充信息被整合到 BERT 模型中,我们不妨称它们为 meta 特征。
绿色的数据部分,主要包括对数据进行采样,转换成 BERT 输入的格式。NLP 类比赛中的数据大致可分为文本数据和非文本数据,文本数据为主,一般以句子、段落或篇章的形式存在;非文本数据是指数值变量或分类变量,这类变量的处理方法与传统挖掘类比赛一样,因为不是重点,不需要太复杂的处理或转换,并且一般只是作为补充信息被整合到 BERT 模型中,我们不妨称它们为 meta 特征。2.1 Encoder
Bert
Bert-WWM
Roberta
相比原生 Bert 的16G训练数据,RoBerta 训练数据量达到了161G; 去除了 NSP 任务,研究表明 NSP 任务太过简单,不仅不能提升反倒有损模型性能; MLM 换成 Dynamic Masking LM; 更大的 Batch size 以及其他超参数的调优;
XLNet
Bert 的 MLM 在预训练时有 MASK 标签,但在使用时却没有,导致训练和使用时出现不一致;并且 MLM 不属于 Autoregressive LM,不能做生成类任务。XLNet 采用 PML(Permutation Language Model) 避免了 MASK 标签的使用,且属于 Autoregressive LM,可以做生成任务。 Bert 使用的 Transformer 结构对文本的长度有限制,为更好地处理长文本,XLNet 采用升级版的 Transformer-XL。
Albert
对 Vocabulary Embedding 进行矩阵分解,将原来的矩阵 V x E
分解成两个矩阵V x H
和H x E
(H << E
)。跨层参数共享,每层的 attention map 有相似的pattern,可以考虑共享。
2.2 数据转换
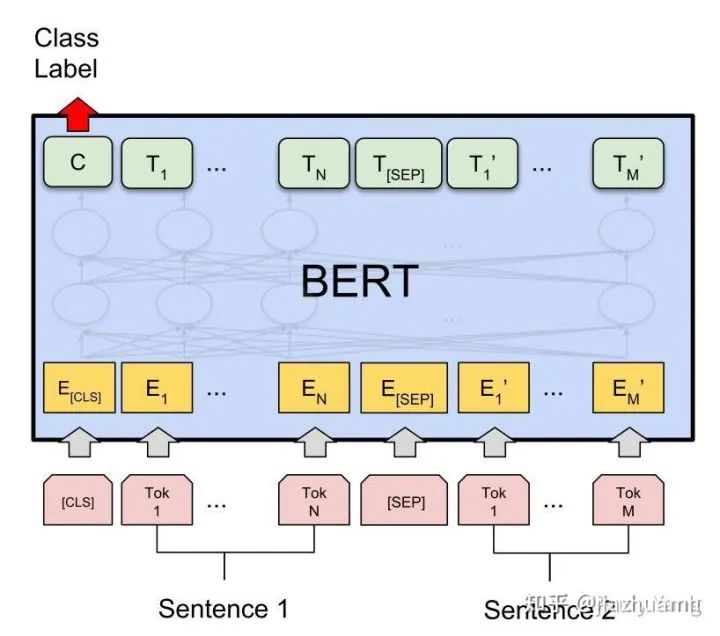
tokens : [CLS] Sentence 1 [SEP] Sentence 2 [SEP]
input_ids : 101 3322 102 9987 102
segment_ids: 0 0 0 1 1
文本特征
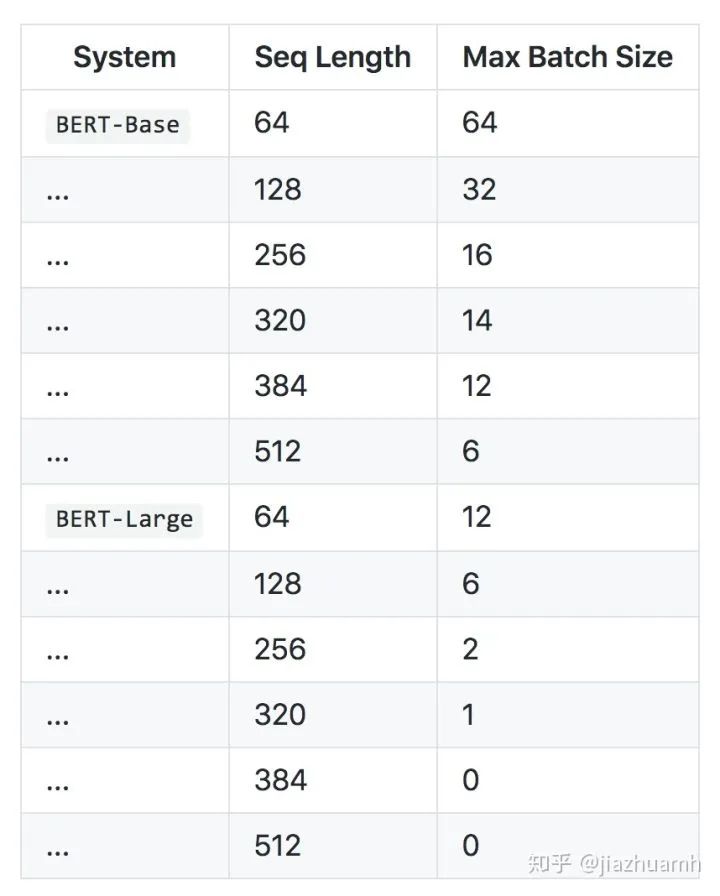
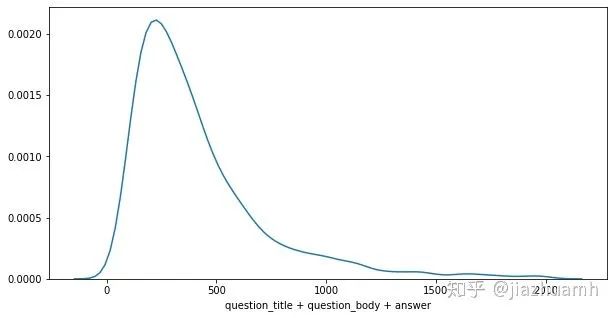
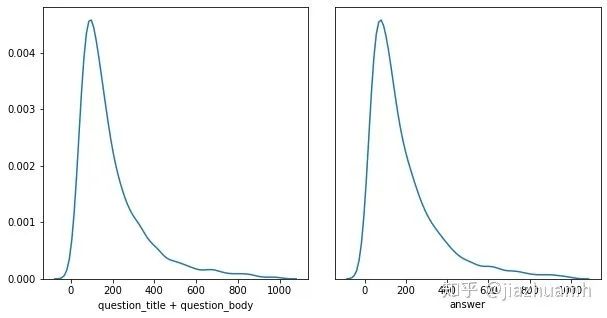
使用 question_title + question_body + answer
的方式,则有75%左右的样本满足512的长度限制,另外25%需要做truncate处理;使用 question_title + question_body
和answer
分开编码的方式,则有92%左右的样本满足512的长度限制,不过这时候需要使用两个 Bert;
pre-truncate post-truncate middle-truncate (head + tail)
meta 特征
在 Bert 输入端,通过添加 special tokens
[CAT=CULTURE]和
[CAT=SCIENCE]加入到文本中:
tokens : [CLS] [CAT=CULTURE] question [SEP] answer [SEP]
input_ids : 101 1 3322 102 9987 102
segment_ids: 0 0 0 0 1 1
在 Bert 输出端,直接做 embedding
emb = nn.Embedding(10, 32) # 初始化一个 Embedding 层
meta_vector = emb(cat) # 将类别编码成 vector
logits = torch.cat([txt_vector, meta_vector], dim=-1) # 文本向量和类别向量融合
2.3 Vector Representation
取最后一层所有 token 对应的向量做融合; 取所有层的第一个 token 对应的向量做融合; 取最后四层的所有 token 对应的向量,加权重(可学习)融合;
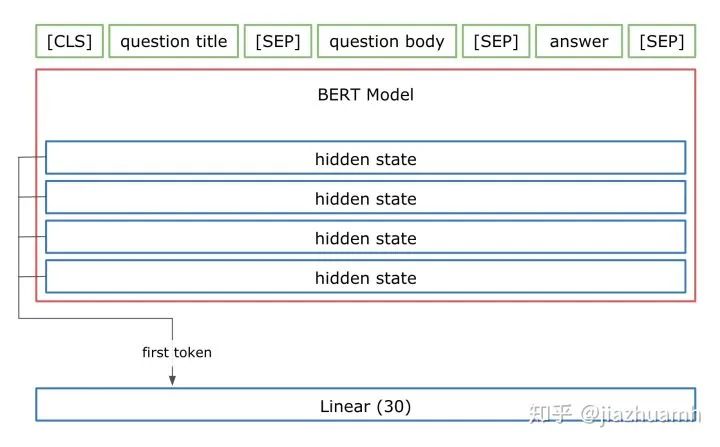
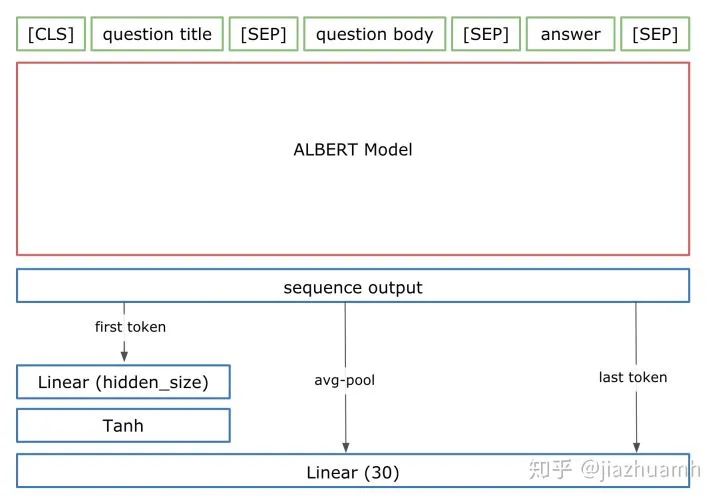

2.4 Classifier
Multi-Sample Dropout
dropouts = nn.ModuleList([
nn.Dropout(0.5) for _ in range(5)
])
for j, dropout in enumerate(dropouts):
if j == 0:
logit = self.fc(dropout(h))
else:
logit += self.fc(dropout(h))
辅助任务
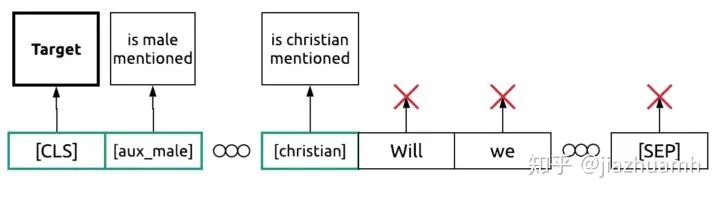
Target是比赛要预测的目标,
is male mentioned、
is christian mentioned等是一些辅助目标,通过这些辅助目标提供的监督信号,也可以对模型的训练和最终效果提供帮助。
2.5 采样
预训练语言模型
文本扩增
Hard negative sampling
Pseudo-labeling
1. 训练集上训练得到 model1;
2. 使用 model1 在测试集上做预测得到有伪标签的测试集;
3. 使用训练集+带伪标签的测试集训练得最终模型 model2;
2.6 Ensemble
SWA
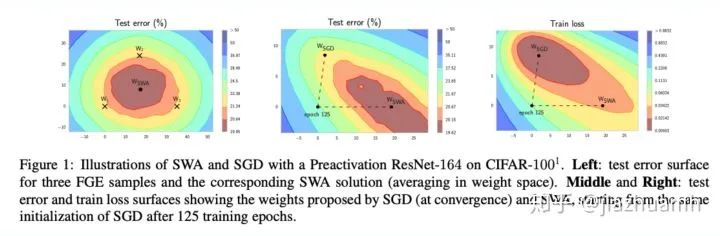
Checkpoint / Seed / Fold average
三、 结束语
说是总结,其实更像是收集了一堆 tricks,至于有没有效,可能真的要试了才知道。突然想到有位 kaggle 大佬分享比赛经验时写道:
During our search of the solution space ...
打 NLP 比赛确实更像是搜索解空间,不断寻找下一个更优解,直到比赛结束。这样看来,快速撸出一个 baseline,建立可靠的 local validation 系统,然后不断尝试并验证新想法,收获好成绩似乎也有迹可循。希望这篇总结能提供一个狭窄的“解空间”,帮助大家在下一个比赛中搜索到更优解。
最后,祝大家在打怪升级过程中收获知识与快乐,Happly Kaggling!
点击查看更多竞赛资讯

让我知道你在看
文章转载自Coggle数据科学,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
