





文章转载自公众号:DB印象
一、场景引入
现网环境中,我们有时候可能会遇到业务同学来电说:执行了一个误操作,或者说业务程序里头有bug,导致表数据混乱了、改错了.........(省略N种情况)。
比如,业务可能执行了一条简单的update操作:
update tab_aken set col_a = 'test' where col_id=666;
结果发现,其实业务真正想执行的是:
update tab_aken set col_a = 'test' where col_id=888;
此为改错数据,即表数据和实际业务逻辑不相符。
比如在一个银行存款和借记卡系统,Aken这个账号的余额实际上只有10元,但因为逻辑上的误操作,将余额update到了10w元。
这种问题一旦出现,通常影响较大且不太好处理,一般的同学可能都比较慌张,虽然问题属于业务逻辑层面,通常应该由业务层面去修复,但旁边的同学如运维侧,也不妨可以通过自己的技能,去帮助业务的将问题解决。
二、解决方法
遇到这种问题,我们该怎么修复呢?
这个时候,一刀切的利用备份来回退就非常不合适了。
因为如果在一个实时在线交易系统里面,除非业务停服,备份恢复则只能做到基于时间点T的部分恢复,即恢复到出现逻辑错误之前的时刻T,但会丢失时间点T后面的在线数据。
而丢失数据的恢复,对一个核心系统来说往往是无法接受的。
备份恢复,无论是物理备份恢复还是逻辑备份恢复,本质上都是物理恢复,通常用于故障恢复,而不是用于逻辑上的回退。
因此,物理恢复往往无法解决逻辑上的数据混乱问题。
业务数据逻辑混乱具体指什么问题呢?
我们来看一个现网的案例:
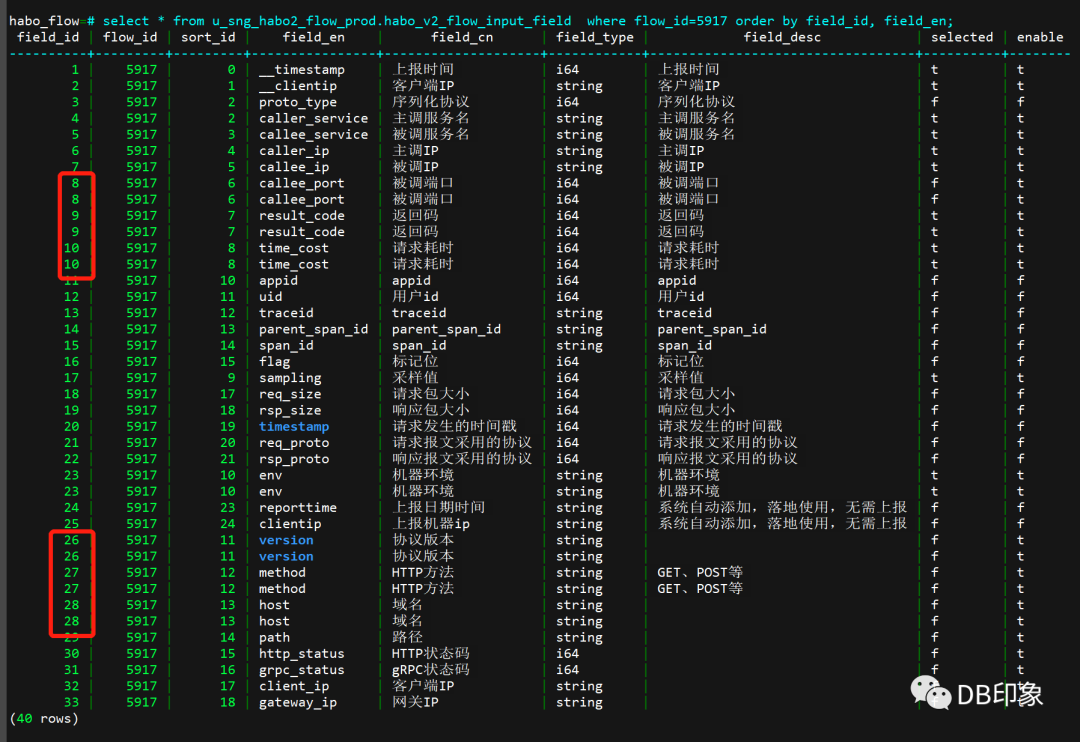
上面截图中,由于程序bug或其他误操作原因,导致了多条重复field_Id的出现,即出现了重复数据。
而业务实际情况是要求一个field_Id对应一条数据(如唯一性约束),因此,这里只需要保留其中一条数据即可满足业务逻辑需求。
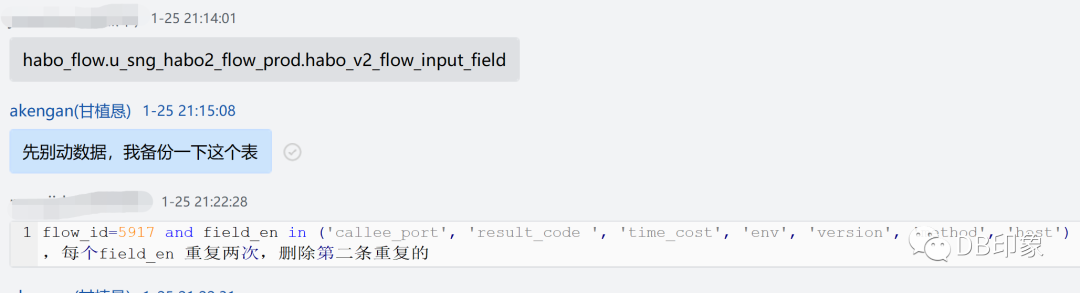
插个题外话,这种数据修复操作,记得一定要养成先备份的习惯:
如果表不是特别大,可以使用复制表的方法进行备份:
1.先like源表创建表结构:
habo_flow=# create table u_sng_habo2_flow_prod.habo_v2_flow_input_field_bak_0125
(like u_sng_habo2_flow_prod.habo_v2_flow_input_field
INCLUDING INDEXES INCLUDING COMMENTS including constraints including defaults);
CREATE TABLE
habo_flow=#
2.接着将源表数据inset到临时备份表:
habo_flow=# insert into u_sng_habo2_flow_prod.habo_v2_flow_input_field_bak_0125
select * from u_sng_habo2_flow_prod.habo_v2_flow_input_field;
INSERT 0 23980
注意:
生产环境不建议直接使用下面这种方式进行备份或拉取数据,而应该拆分成上面的方式。
create table A as select * from B
好了,我们回到数据修复的问题。
根据业务对需求逻辑的介绍,我们只需要删除重复行其中一条数即可,常规的方法可能是这样:
delete from u_sng_habo2_flow_prod.habo_v2_flow_input_field
where
field_id=8 and flow_id=5917 and xxx=yyy and ... limit N;
或者如下:
with del_tmp
as (select field_id from u_sng_habo2_flow_prod.habo_v2_flow_input_field where field_id =8
delete from u_sng_habo2_flow_prod.habo_v2_flow_input_field
where field_id in (select * from del_tmp);
可是,仔细的同学可能已经发现,上面每个field_id重复的两条数据是完全相同的,即所有的字段值都相同。
这种情况下,当数据库不支持delete/update limit语法的时候(当前pg-14版本未支持此种语法) ,依靠下面这样delete就不好删除了
delete from tab_xxx where colxxx=yyy
因为这样表中对应的数据会全部被delete:
habo_flow=# with del_tmp as (select field_id from u_sng_habo2_flow_prod.habo_v2_flow_input_field_bak_0125_02 where field_id =8 limit 1)
delete from u_sng_habo2_flow_prod.habo_v2_flow_input_field_bak_0125_02 where field_id in (select * from del_tmp);
DELETE 2
也许,你会说,上表每条id重复的只有2条数据,总共6条重复数据,我们先将对应数据全部delete删除,然后再insert其中一条进来就好。
方法如下:
delete from u_sng_habo2_flow_prod.habo_v2_flow_input_field_bak_0125_02 where field_id =8;
insert into u_sng_habo2_flow_prod.habo_v2_flow_input_field(field_id,flow_id,sort_id,field_en,field_cn,field_type,field_desc,selected,enable)
values(8,5917,0,'_timestamp',xxx(略)........,'t','t');
是的,这样做确实可以修复数据。
但是,现网中有时候我们可能不会这么幸运。
假如这是一个上亿数据量的表,比如现网一个表中的数据量可能高达几十亿,然后我们假设其中重复数据有6000w,那么,我们是不是要写几千万条insert语句,然后将字段值一个一个写进来呢?
很显然,这样做的时间成本很大,间接的,意味着对业务影响也更大。

既然有些场景直接使用delete然后insert不合适,那我们又用什么具体的方法呢?
介绍之前,我们先来认识一下什么叫ctid scan。在PostgreSQL中,通过执行计划,有时候我们可以看到如下的数据检索方式:
Tid Scan on tab_xxx (cost=0.00..1.11 rows=1 width=6) (actual time=0.000..0.000 rows=1 loops=99)
TID Cond: (ctid = tab_xxx .ctid)
即通过ctid来扫描表数据。那么什么是ctid呢?
ctid表示的是表中当前行存储在DB数据块中的具体位置,具体表示如下:
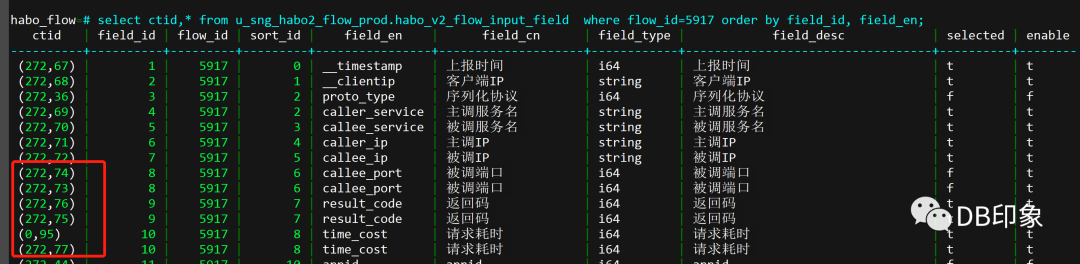
上面的ctid=(272,74),表示的是当前行存储在第272个数据块中的第74条记录,即表数据的物理行号,这个行号在表内是唯一的。
typedef struct XactLockTableWaitInfo
57 {
58 XLTW_Oper oper;
59 Relation rel;
60 ItemPointer ctid;
61 } XactLockTableWaitInfo;
typedef struct ItemPointerData
37 {
38 BlockIdData ip_blkid; --数据块ID,使用uint16表示
39 OffsetNumber ip_posid; --位置ID,使用uint16表示
40 }
所以,即使表中field_id=8的两条数据,我们看到的ctid也是不一样的,根据ctid,执行引擎可以直接根据物理行号直接读取到对应的数据行。
那么,有了ctid,当我们要清洗一个没有唯一性约束的重复数据的时候,就有了更比上面delete insert更加高效的方法。
具体如下:
with del_tmp as (select ctid from u_sng_habo2_flow_prod.habo_v2_flow_input_field where field_id =8 limit 1)
delete from u_sng_habo2_flow_prod.habo_v2_flow_input_field where ctid = any (array(select ctid from del_tmp));
这个SQL之所以这样写,主要逻辑思路是先将目标数据存放到中间临时表del_tmp,然后在主查询中通过历遍del_tmp中的数据行进行删除。
具体效果如下:
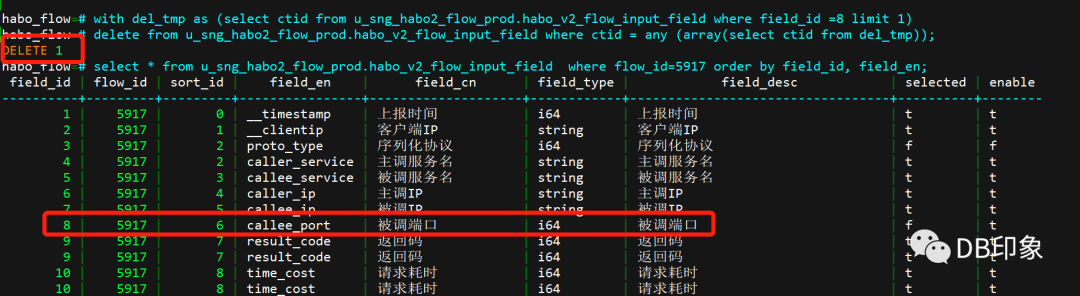
用这个方法,我们就可以避免编写繁琐的insert语句,并且用这种方法,大表清洗的速度也是极速的,通过唯一的物理行号去获取一条记录,也是检索数据最快的方式。
三、总结
通过这个例子,我们不难发现,如果我们对DB的特性和原理越了解,我们解决问题的思路及方法可能就越越广越多越好,我们看待一个数据库,不应只把它当做一个简单的存储组件,而应充分挖掘它在具体的场景里面能给业务所带来的好处。
最后,关于如何清洗重复数据,本案例用到PostgreSQL通用特性如下:
1.表的临时备份
create table tab_bak (like tab_source);
insert into tab_bak select * from tab_source;
2.过渡逻辑中间数据-CTE语法
with del_tmp as (select ctid from u_sng_habo2_flow_prod.habo_v2_flow_input_field where field_id =8 limit 1)
3.物理数据定位-利用ctid将重复数据清洗掉
delete from tab_xxxx where ctid = any (array(select ctid from del_tmp);
通过with和ctid,我们可以在这里的基础上,还可以结合更加复杂的场景,实现更加复杂的逻辑功能,有兴趣的同学可以自行了解探索。





新闻|Babelfish使PostgreSQL直接兼容SQL Server应用程序
中国PostgreSQL分会入选工信部重点领域人才能力评价机构

更多新闻资讯,行业动态,技术热点,请关注中国PostgreSQL分会官方网站
https://www.postgresqlchina.com
中国PostgreSQL分会生态产品
https://www.pgfans.cn
中国PostgreSQL分会资源下载站
https://www.postgreshub.cn


点击此处阅读原文
↓↓↓
