




点击上方👆蓝字关注我们!

本文是字节跳动数据平台开发套件团队在 Flink Forward Asia 2021: Flink Forward 峰会上的演讲,着重分享了字节跳动数据湖技术上的选型思考和探索实践。
字节跳动数据集成的现状
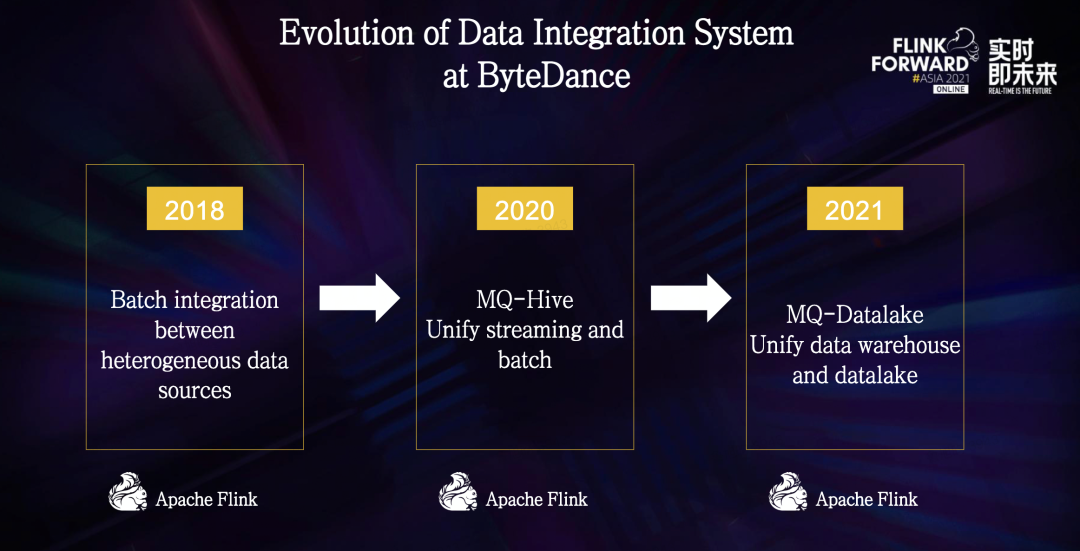
批式集成模式基于 Flink Batch 模式打造,将数据以批的形式在不同系统中传输,目前支持了 20 多种不同数据源类型。 流式集成模式主要是从 MQ 将数据导入到 Hive 和 HDFS,任务的稳定性和实时性都受到了用户广泛的认可。 增量模式即 CDC 模式,用于支持通过数据库变更日志 Binlog,将数据变更同步到外部组件的数据库。 这种模式目前支持 5 种数据源,虽然数据源不多,但是任务数量非常庞大,其中包含了很多核心链路,例如各个业务线的计费、结算等,对数据准确性要求非常高。 在 CDC 链路的整体链路比较长。首先,首次导入为批式导入,我们通过 Flink Batch 模式直连 MySQL 库拉取全量数据写入到 Hive,增量 Binlog 数据通过流式任务导入到 HDFS。 由于 Hive 不支持更新操作,我们依旧使用了一条基于 Spark 的批处理链路,通过 T-1 增量合并的方式,将前一天的 Hive 表和新增的 Binlog 进行合并从而产出当天的 Hive 表。
首先,这条基于 Spark 的离线链路资源消耗严重,每次产出新数据都会涉及到一次全量数据 Shuffle 以及一份全量数据落盘,中间所消耗的储存以及计算资源都比较严重。 同时,随着字节跳动业务的快速发展,近实时分析的需求也越来越多。 最后,整条链路流程太长,涉及到 Spark 和 Flink 两个计算引擎,以及 3 个不同的任务类型,用户使用成本和学习成本都比较高,并且带来了不小的运维成本。

关于数据湖技术选型的思考
Iceberg:核心抽象对接新的计算引擎的成本比较低,并且提供先进的查询优化功能和完全的 schema 变更。 Hudi:更注重于高效率的 Upsert 和近实时更新,提供了 Merge On Read 文件格式,以及便于搭建增量 ETL 管道的增量查询功能。
哪个框架可以更好的支持我们 CDC 数据处理的核心诉求? 哪个框架可以更快速补齐另一个框架的功能,从而成长为一个通用并且成熟的数据湖框架?
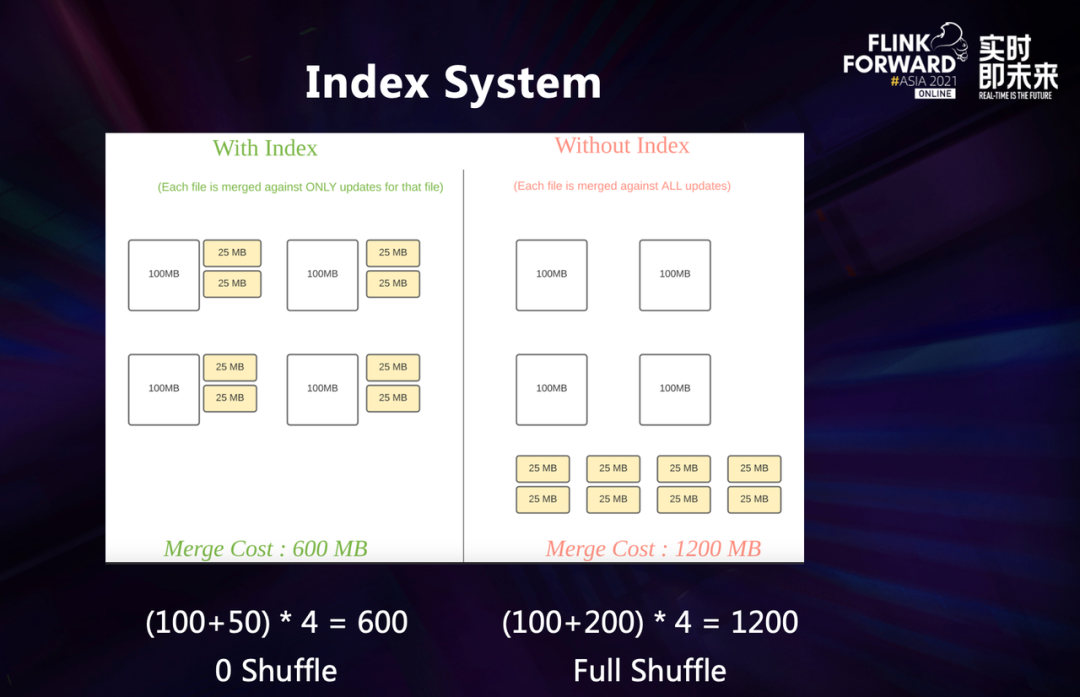
create_time的时间戳,底表的分布也是按照这个时间戳进行分区,最近几小时或者几天的数据会有比较频繁的更新,但是更老的数据则不会有太多的变化。
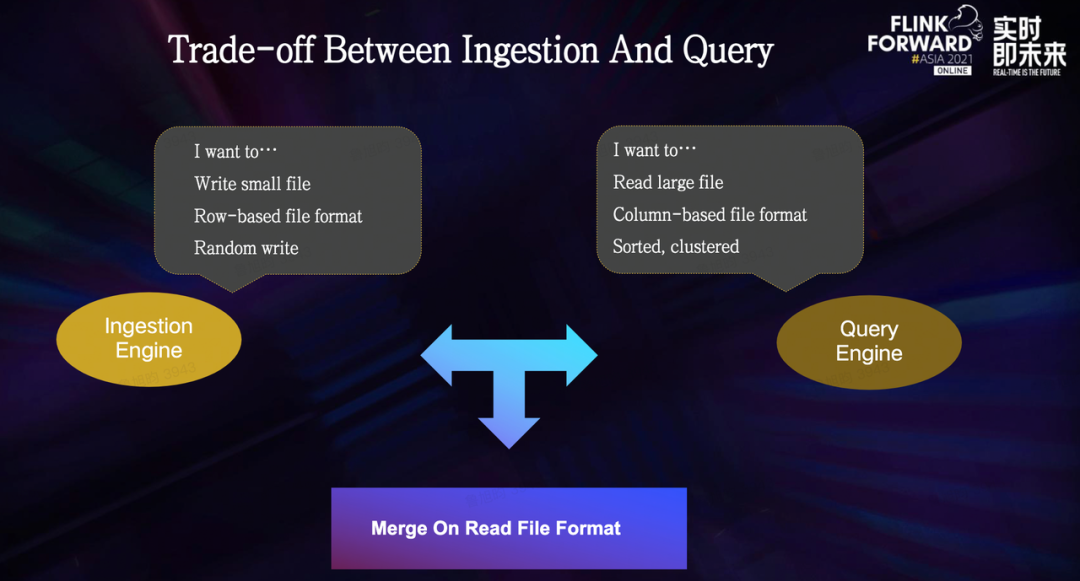
写入引擎更倾向于写小文件,以行存的数据格式写入,尽可能避免在写入过程中有过多的计算包袱,最好是来一条写一条。 查询引擎则更倾向于读大文件,以列存的文件格式储存数据,比如说 parquet 和 orc,数据以某种规则严格分布,比如根据某个常用字段进行排序,从而做到可以在查询的时候,跳过扫描无用的数据,来减少计算开销。
结语

文章转载自火山引擎开发者社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
