




官方文档:https://www.percona.com/doc/percona-toolkit/2.2/pt-archiver.html
Percona Toolkit是一组高级命令行工具的集合。我们可以用它来执行各种MYSQL的任务。
安装Percona Toolkit
建议从官方软件仓库安装Percona软件:
1.配置Percona repositories
基于rpm的发行版,例如Red Hat Enterprise Linux或CentOS,可以使用yum包管理器安装percona-release。
sudo yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
PS:在CentOS 8中,使用yum时也许出现如下错误:
Error: Failed to download metadata for repo 'appstream': Cannot prepare internal mirrorlist: No URLs in mirrorlist
原因是:在2022年1月31日,CentOS团队从官方镜像中移除了CentOS 8的所有包,并将它们转移到了https://vault.centos.org
怎么解决?
我们可以更新/etc/yum.repos.d/下的repos,使用vault.centos.org替换mirror.centos.org
# sudo sed -i -e "s|mirrorlist=|#mirrorlist=|g" /etc/yum.repos.d/CentOS-*
# sudo sed -i -e "s|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g" /etc/yum.repos.d/CentOS-*
2.使用相应的包管理器安装Percona Toolkit
For RHEL or CentOS:
sudo yum install percona-toolkit
pt-archiver
pt-archiver是用作归档的工具。该工具的目标是降低从表中剔除旧数据的影响,这对高负载的OLTP应用十分重要。
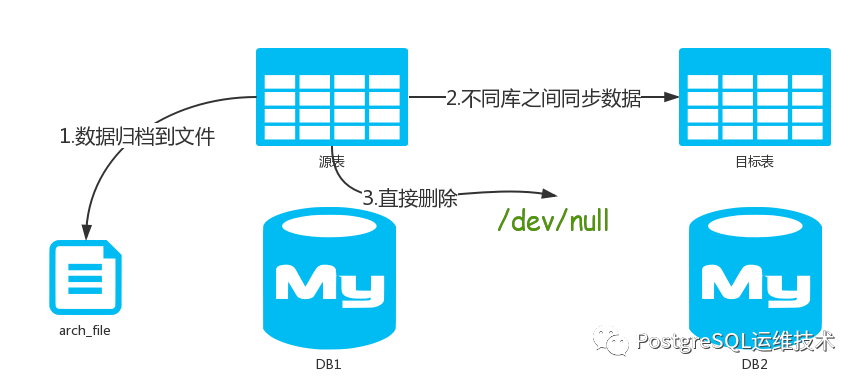
其主要用法包括三类:
将历史数据直接删除 将历史数据归档到文件 在不同库表之间同步数据(可以是同服务器也可以是不同服务器,并且不用数据落盘)
语法
pt-archiver [OPTIONS] --source DSN --where WHERE
创建测试数据
创建表
CREATE TABLE `user_test` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`login_name` VARCHAR(30) NOT NULL COMMENT '登录账号',
`email` VARCHAR(50) DEFAULT '' COMMENT '用户邮箱',
`phonenumber` VARCHAR(11) DEFAULT '' COMMENT '手机号码',
`sex` CHAR(1) DEFAULT '0' COMMENT '用户性别(0男 1女 2未知)',
`password` VARCHAR(50) DEFAULT '' COMMENT '密码',
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='测试';
使用函数,批量插入1000000条数据。
DELIMITER $$
DROP FUNCTION IF EXISTS `bulk_insert_fun`$$
CREATE FUNCTION `bulk_insert_fun`() RETURNS INT(11)
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
-- 插入语句
INSERT INTO user_test(`login_name`,`email`,`phonenumber`,`sex`,`password`)
VALUES(CONCAT('用户',i),CONCAT(FLOOR(RAND()*((999999-111111)+111111)),'@qq.com'),
CONCAT('135',FLOOR(RAND()*((99999999- 11111111)+11111111))), FLOOR(RAND()*2),UUID());
SET i = i+1;
END WHILE;
RETURN i;
END$$
DELIMITER ;
示例1:将历史数据直接删除
删除id<100000的记录
pt-archiver --source h=xxx.xx.xx.xx,P=3306,u=root,p=123456,D=test,t=user_test \
--purge \
--where "id<200000" \
--primary-key-only \
--no-check-charset \
--bulk-delete \
--limit=1000 \
--why-quit \
--progress=100000 \
--sentinel=/tmp/pt-test
参数解释:
1:--source :指定要归档表的信息,兼容DSN选项。
DSN语法是key=value[,key=value...],可选的参数有:
KEY COPY MEANING
=== ==== =============================================
A yes Default character set
D yes Database that contains the table
F yes Only read default options from the given file
L yes Explicitly enable LOAD DATA LOCAL INFILE
P yes Port number to use for connection
S yes Socket file to use for connection
a no Database to USE when executing queries
b no If true, disable binlog with SQL_LOG_BIN
h yes Connect to host
i yes Index to use
m no Plugin module name
p yes Password to use when connecting
t yes Table to archive from/to
u yes User for login if not current user
2: --purge:直接清除数据而不是归档; 允许省略--file和--dest。如果只想清除数据,可以考虑使用--primary-key-only指定仅限表的主键列。这样可以防止从服务器获取所有列。
3: --primary-key-only:查询仅限主键列。用于指定具有主键列的--columns的快捷方式,它可以避免获取整行。
4: --[no]check-charset:不检查字符集,禁用此检查可能会导致文本被错误地从一个字符集转换为另一个字符集。进行字符集转换时,禁用此检查可能有用。此例中,我们是直接清除数据,所以可以禁用字符集检查。
5: --bulk-delete:批量删除source上的旧数据。
6: --limit: 每次取n行数据给pt-archive处理。
7: --why-quit:除非行耗尽,否则打印退出原因。
8: --progress: 每处理n行输出一次处理信息。
示例2:将历史数据导出到文件
将user_test表归档到文件
pt-archiver --source h=xxx.xx.xx.xx,P=3306,u=root,p=123456,D=test,t=user_test \
--file=/tmp/%Y-%m-%d-%D.%t \
--where="1=1" \
--no-check-charset \
--no-delete \
--no-safe-auto-increment \
--progress=1000 \
--statistics
参数解释:
1: --no-delete:不要删除归档的行(如果需要删除源表数据,--no-delete改为--purge)。
2: --[no]safe-auto-increment: 不以最大AUTO_INCREMENT值归档行。默认值是YES。添加一个额外的where子句,以防止pt-archiver在对单列AUTO_INCERMENT值进行升序时删除最新的行。这可以防止在服务器重启时重用AUTO_INCREMENT值。
3: --statistics:结束的时候给出统计信息:开始的时间点,结束的时间点,查询的行数,归档的行数,删除的行数,以及各个阶段消耗的总的时间和比例,便于以此进行优化。
4: --file:要归档到的文件。
file输出文件的参数。
%d Day of the month, numeric (01..31)
%H Hour (00..23)
%i Minutes, numeric (00..59)
%m Month, numeric (01..12)
%s Seconds (00..59)
%Y Year, numeric, four digits
%D Database name
%t Table name
示例3:在不同库表之间同步数据。
将user_test表的数据同步到同服务器同库下的user_test_his表
pt-archiver --source h=xxx.xx.xx.xx,P=3306,u=root,p=123456,D=test,t=user_test \
--where "id<300000" \
--dest t=user_test_his \
--purge \
--charset=utf8mb4 \
--limit=1000 \
--sleep=1 \
--nosafe-auto-increment \
--noversion-check \
--why-quit \
--progress=10000 \
--sentinel=/tmp/pt-test
参数解释:
1: --dest:指定要归档到的表,兼容DSN选项。
它使用与--source相同的参数格式。大多数缺失值默认为与--source相同的值,因此不必重复--source和--dest中相同的选项。
2: --charset:设置默认字符集。
3: --sentinel:优雅地退出操作。指定的文件的存在将导致pt-archiver停止存档并退出。默认值为/tmp/pt-archiver-sentinel。
4: --sleep: 指定SELECT语句之间的休眠时间。
pt-archiver的使用规则
源表必须有主键。 参数至少需要指定--dest,--file,--purge其中的一个。 --ignore和--replace互斥。 --txn-size和--commit-each互斥 --low-priority-insert和--delayed-insert互斥。 --share-lock和--for-update互斥。 --analyze和--optimize互斥。 --no-ascend和--no-delete互斥。
说明:--ignore和--replace参数:归档冲突时是跳过还是覆盖。
最后
pt-archiver毕竟是操作生产数据,使用起来得慎重些,投入生产之前得多在测试环境进行测试,根据实际情况进行参数的调整优化。
参考文档:https://www.percona.com/doc/percona-toolkit/2.2/pt-archiver.html https://www.fordba.com/percona-toolkitpt-archiver.html
