






双向图模型
双向图模拟是在2012年VLDB论文《Capturing Topology in Graph PatternMatching》[1]中提出的,是对之前存在的图模拟(GraphSimulation)问题的进一步改进,在 RDF 数据集上,其定义如下:
双向图模拟:给定两个图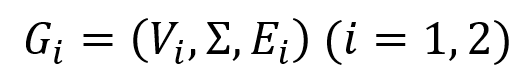 其中
其中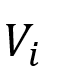 为点集合,Σ 为边标签集合,
为点集合,Σ 为边标签集合,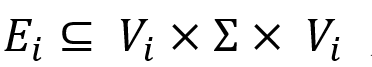 为带标签的边集合,且 (v,a,w) 表示从点 v 到点w 标签为 a 的边。定义二元关系
为带标签的边集合,且 (v,a,w) 表示从点 v 到点w 标签为 a 的边。定义二元关系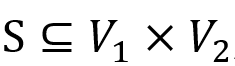 , 则 S 为
, 则 S 为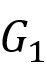 和
和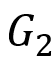 之间的双向图模拟,当且仅当对于所有
之间的双向图模拟,当且仅当对于所有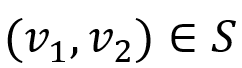 :
:
1. 若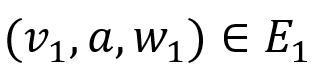 , 则存在
, 则存在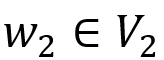 使得
使得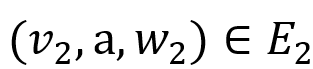 , 且
, 且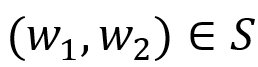 。
。
2. 若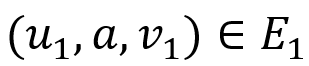 , 则存在
, 则存在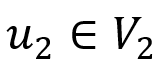 使得
使得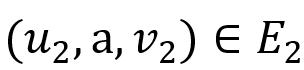 , 且
, 且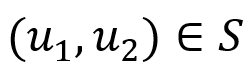 。
。
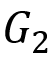 双向模拟
双向模拟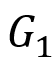 。简单来说,我们要求中每一个参与模拟的点都保留了模式图中相应点的前驱和后继语义。相比子图同态或者同构,双向模拟允许模式图中的点到数据图中的点为一对多映射,也就是说,我们最终得到的是中每一个点v在中的模拟点集合
。简单来说,我们要求中每一个参与模拟的点都保留了模式图中相应点的前驱和后继语义。相比子图同态或者同构,双向模拟允许模式图中的点到数据图中的点为一对多映射,也就是说,我们最终得到的是中每一个点v在中的模拟点集合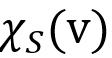 ,其中可能包含多个不同的点。此外我们只要求保留前驱和后继的语义关系,但不要求保留的拓扑结构,这使得双向图模拟得到的中的模拟点集合是子图同态或者同构能够得到的匹配点集合的超集。例如下图,p4 在双向图模拟的语义下可以作为 v 或者 w 的模拟点,但是在子图同态或者同构中则不能作为匹配。
,其中可能包含多个不同的点。此外我们只要求保留前驱和后继的语义关系,但不要求保留的拓扑结构,这使得双向图模拟得到的中的模拟点集合是子图同态或者同构能够得到的匹配点集合的超集。例如下图,p4 在双向图模拟的语义下可以作为 v 或者 w 的模拟点,但是在子图同态或者同构中则不能作为匹配。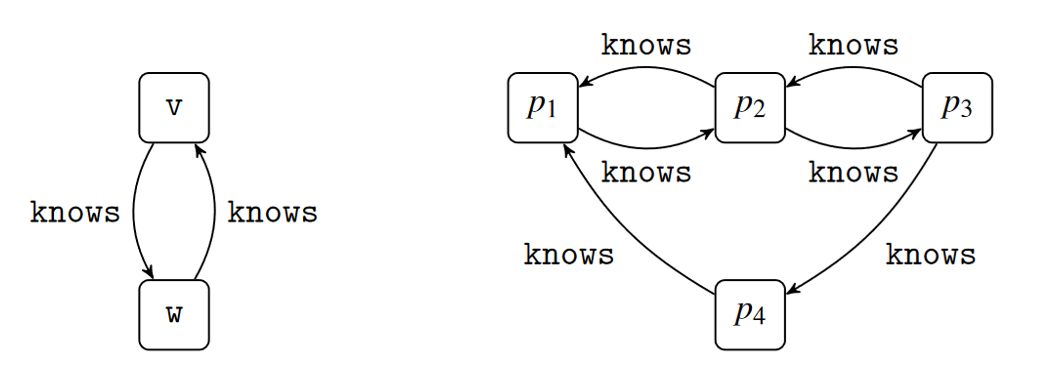
双向图模拟算法
本文提出了基于不等式系统(SOI,System ofinequalities)的求解双向图模拟的算法。该算法基于以下观察:
给定两个图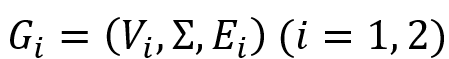 ,
,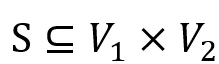 二元关系, 若 S 为和之间的双向图模拟,且
二元关系, 若 S 为和之间的双向图模拟,且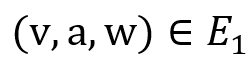 ,则
,则
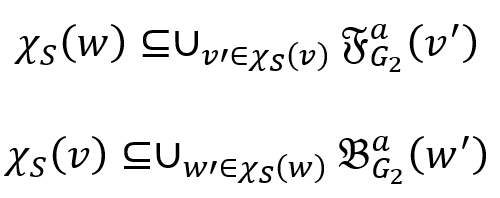
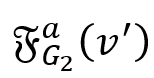 表示 v’ 的一跳后继集合,
表示 v’ 的一跳后继集合,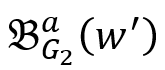 表示 w’ 的一跳前驱集合。也就是说,v 的模拟点一定在w 的模拟点的前驱集合中,而 w 的模拟点一定在 v 的模拟点的后继集合中。根据双向图模拟的定义不难得出该结论。
表示 w’ 的一跳前驱集合。也就是说,v 的模拟点一定在w 的模拟点的前驱集合中,而 w 的模拟点一定在 v 的模拟点的后继集合中。根据双向图模拟的定义不难得出该结论。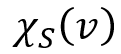 表示为一个
表示为一个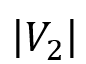 维的 bit向量,其中第 i 个 bit 为 1,则表示中的第 i 个点在 v 的模拟点集合
维的 bit向量,其中第 i 个 bit 为 1,则表示中的第 i 个点在 v 的模拟点集合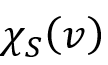 中。对于
中。对于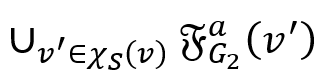 和
和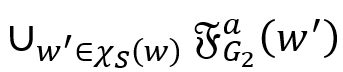 ,则表示为向量与矩阵相乘。本文用
,则表示为向量与矩阵相乘。本文用 分别表示一个图 G 在边标签 a 上的前向和后向邻接矩阵。在
分别表示一个图 G 在边标签 a 上的前向和后向邻接矩阵。在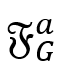 的第 i 行第 j 列为 1,则表示图中存在边
的第 i 行第 j 列为 1,则表示图中存在边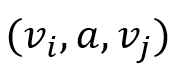 。在
。在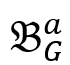 的第 i 行第 j 列为 1,则表示图中存在边,则:
的第 i 行第 j 列为 1,则表示图中存在边,则: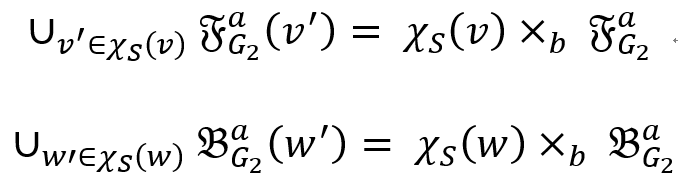
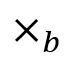 表示bit矩阵乘法。因此,上述观察可以转换为不等式:
表示bit矩阵乘法。因此,上述观察可以转换为不等式: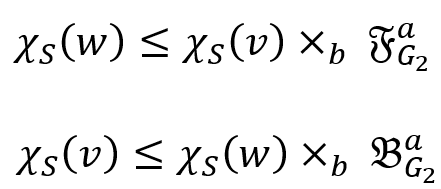

求解表示模式图和数据图之间的双向模拟关系 S 的SOI 的方法如下:
1. 我们初始化二元关系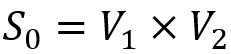 ,即每一个变量都为一个全 1 的bit 向量,并将所有不等式设置为不稳定。
,即每一个变量都为一个全 1 的bit 向量,并将所有不等式设置为不稳定。
2. 用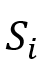 表示当前关系,如果存在一个不稳定的不等式
表示当前关系,如果存在一个不稳定的不等式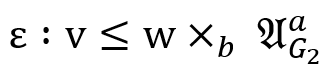 (
( 表示
表示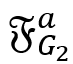 或者
或者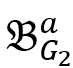 ),则检查该不等式是否满足,如果满足,则将其设为稳定并继续。如果不满足,则令
),则检查该不等式是否满足,如果满足,则将其设为稳定并继续。如果不满足,则令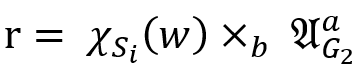 , 更新到
, 更新到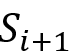 :
:
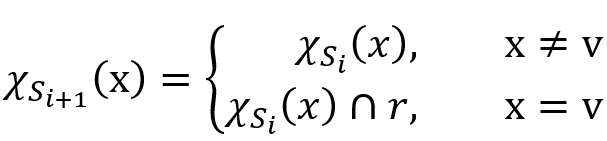
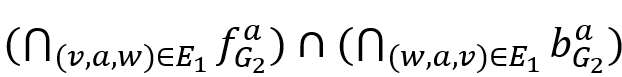
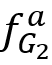 表示中所有标签为 a 的边的源点的集合,而
表示中所有标签为 a 的边的源点的集合,而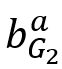 表示中所有标签为 a 的边的目的点的集合。
表示中所有标签为 a 的边的目的点的集合。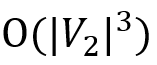 。
。在SPARQL查询中应用双向图模拟
BGP:对于符合基础图模式的 SPARQL 查询,我们可以将其直接转换为一个模式图,由于SPARQL查询结果一定是双向图模拟结果的子集,因此我们可以先用双向图模拟的方法进行剪枝,在得到的结果集合中再进行 SPARQL查询。
UNION:一些 SPARQL 查询中会包含 UNION 语句,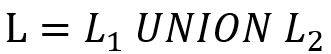 表示对
表示对 两个 SPARQL 查询取并集。对于这种情况,我们只需要将分别转换为模式图并进行双向图模拟,将得到的结果集取并集,L 的查询结果集合便包含在该并集中,我们可以在其中进行进一步查询。
两个 SPARQL 查询取并集。对于这种情况,我们只需要将分别转换为模式图并进行双向图模拟,将得到的结果集取并集,L 的查询结果集合便包含在该并集中,我们可以在其中进行进一步查询。
AND: 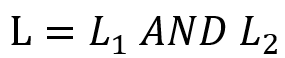 表示对两个 SPARQL 查询在公共变量上取交集。对于该语句,我们需要将转换出的 SOI 聚合起来。若
表示对两个 SPARQL 查询在公共变量上取交集。对于该语句,我们需要将转换出的 SOI 聚合起来。若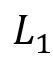 产生的 SOI 为
产生的 SOI 为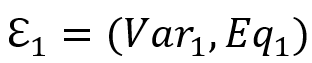 ,
,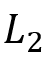 产生的 SOI 为
产生的 SOI 为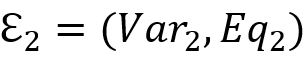 , 则求解
, 则求解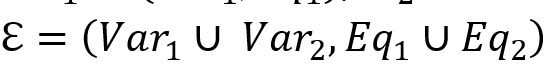 得到的结果集中便包含了 L 的解,可以在其中进行进一步的查询。
得到的结果集中便包含了 L 的解,可以在其中进行进一步的查询。
OPTIONAL:OPTIONAL 语句略为复杂,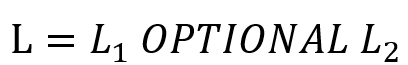 表示
表示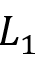 必需满足,而
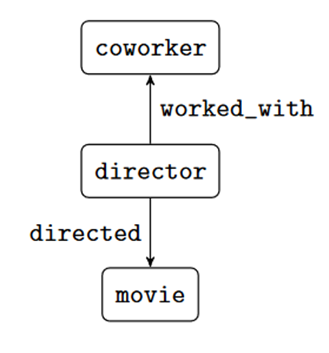
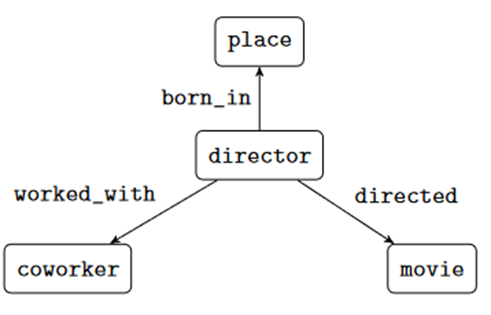
必需满足,而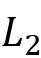 则以满足的变量为基础进行进一步搜索,若存在则在结果中报告。例如下列 SPARQL 意为 “找到执导过至少一部电影的导演,如果该导演有合作者,则也找出来”。
则以满足的变量为基础进行进一步搜索,若存在则在结果中报告。例如下列 SPARQL 意为 “找到执导过至少一部电影的导演,如果该导演有合作者,则也找出来”。
 产生的 SOI 为
产生的 SOI 为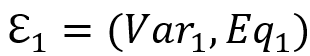 , 产生的 SOI 为
, 产生的 SOI 为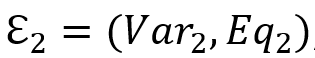 , 我们定义函数mand(),表示变量必需满足的出现,例如上图示表示变量必需满足的出现,例如上图示例中,”?director directed ?movie” 中的 ?director 便为必需满足的出现。”?director workded_with ?coworker” 中的 ?director则不是。更具体的来说: AND )=mand()∩ mand(). OPTIONAL )=mand()
, 我们定义函数mand(),表示变量必需满足的出现,例如上图示表示变量必需满足的出现,例如上图示例中,”?director directed ?movie” 中的 ?director 便为必需满足的出现。”?director workded_with ?coworker” 中的 ?director则不是。更具体的来说: AND )=mand()∩ mand(). OPTIONAL )=mand() 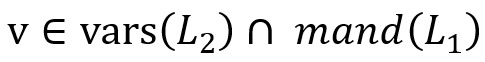 定义重命名函数
定义重命名函数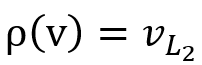 则SOI
则SOI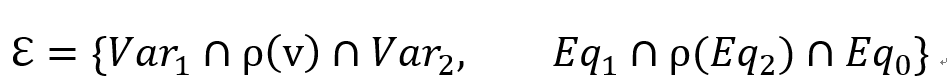 可以应用于
可以应用于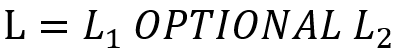 的求解,其中
的求解,其中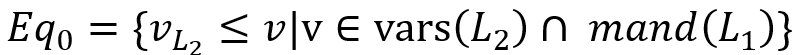 中重命名产生的变量的匹配结果必须是中原变量的匹配结果的子集。ℇ 的求解结果包含了 L 的解。例如,上图中的 SPARQL 语句转换为的 SOI 如下所示:
中重命名产生的变量的匹配结果必须是中原变量的匹配结果的子集。ℇ 的求解结果包含了 L 的解。例如,上图中的 SPARQL 语句转换为的 SOI 如下所示: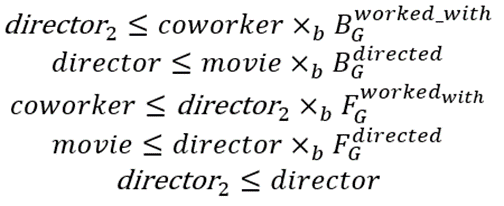
实验结果
实验使用的数据集包括两个:
DBpedia 数据集[2],包含751,603,507 条三元组,216,132,665个点和65430条谓词(边标签)。
LUBM(LehighUniversity Benchmark)数据集[3],包含1,38,692,508条三元组,328,620,750个点和18个谓词(边标签)。
实验使用的查询集则分为三组, 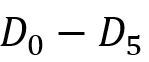 为来自论文[4]的DBpedia查询集,
为来自论文[4]的DBpedia查询集,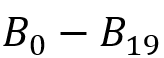 为来自论文[5]的DBpedia查询集,
为来自论文[5]的DBpedia查询集,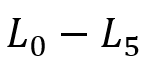 为来自论文[4]的LUBM查询集。
为来自论文[4]的LUBM查询集。
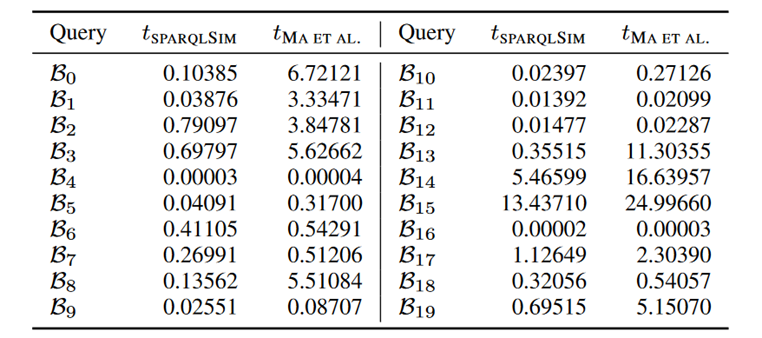
作者首先将本文提出的双向图模拟求解算法和 Ma et al.[1]设计的算法进行了对比,对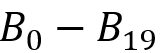 产生的模式图在数据图上的求解时间如下图所示,可以发现该算法在执行速度上相比已有算法具有优势。
产生的模式图在数据图上的求解时间如下图所示,可以发现该算法在执行速度上相比已有算法具有优势。
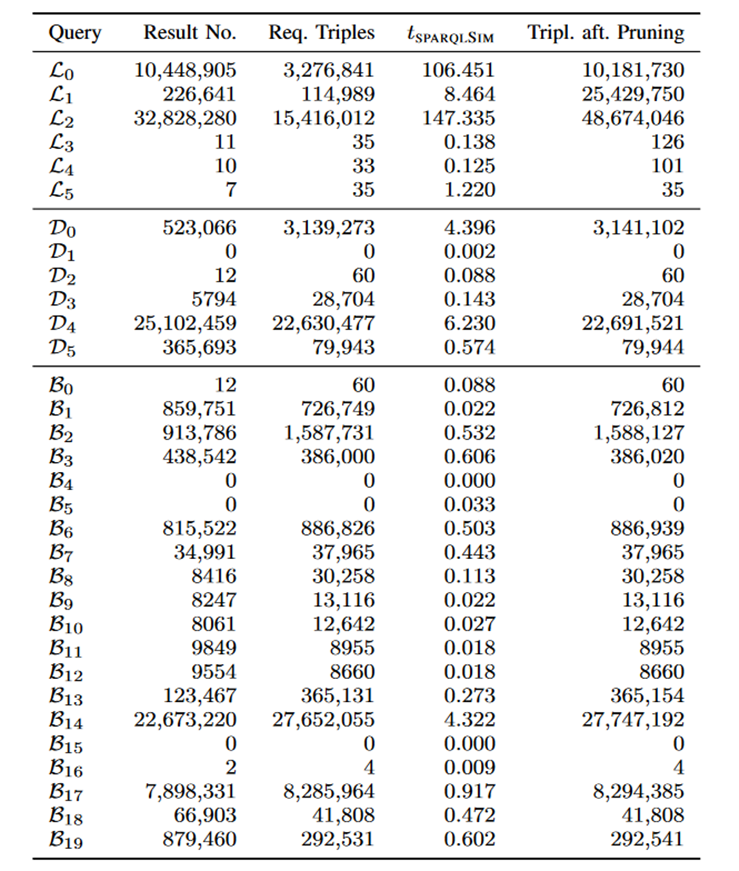
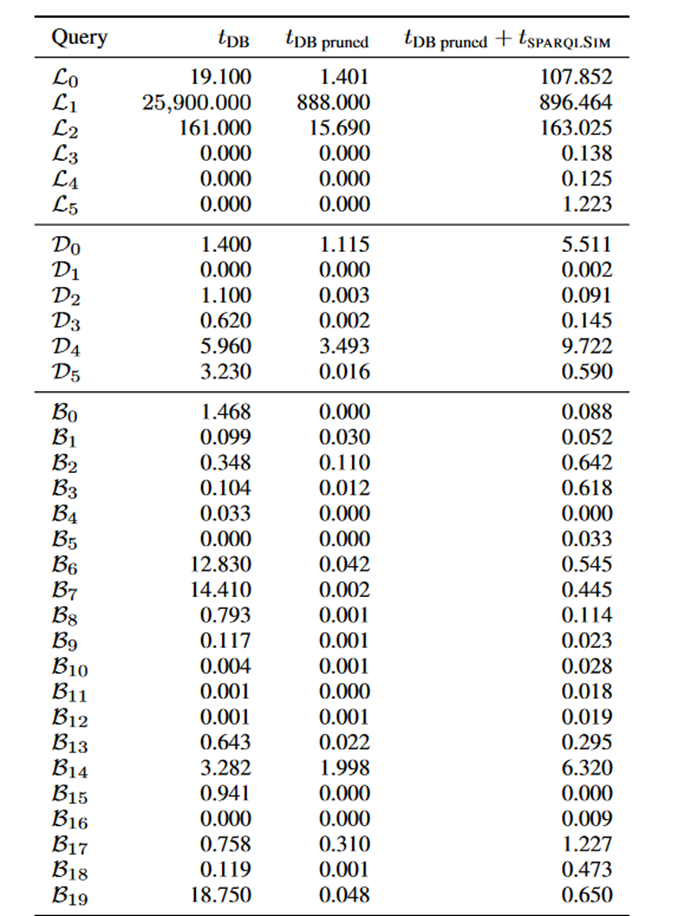
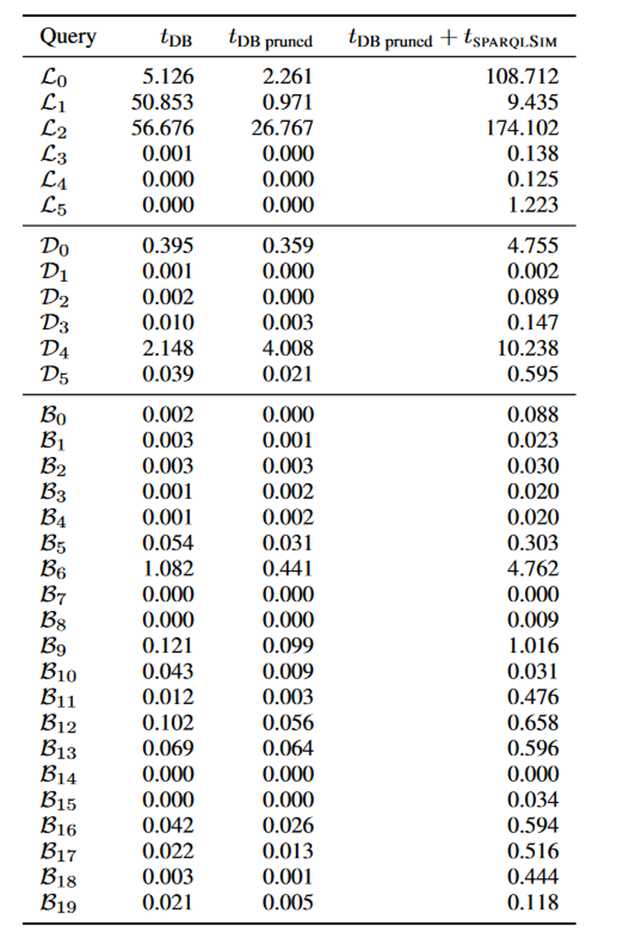
然后,作者对双向图模拟的剪枝效果进行了测试,结果如下图所示。其中第二列表示SPARQL查询结果的数目,第三列为查询结果相关的三元组的数目,第四列为双向图模拟所需的时间,第五列为双向图模拟剪枝后剩余的三元组数目。可以看到,在DBpedia的查询中(,),双向图模拟具有较高的剪枝效果,而在 LUBM的查询()中则较差。这是由于 LUBM数据集的谓词种类少,每一个谓词的筛选能力较低,使得剪枝的效果不强。
总结
参考文献



