




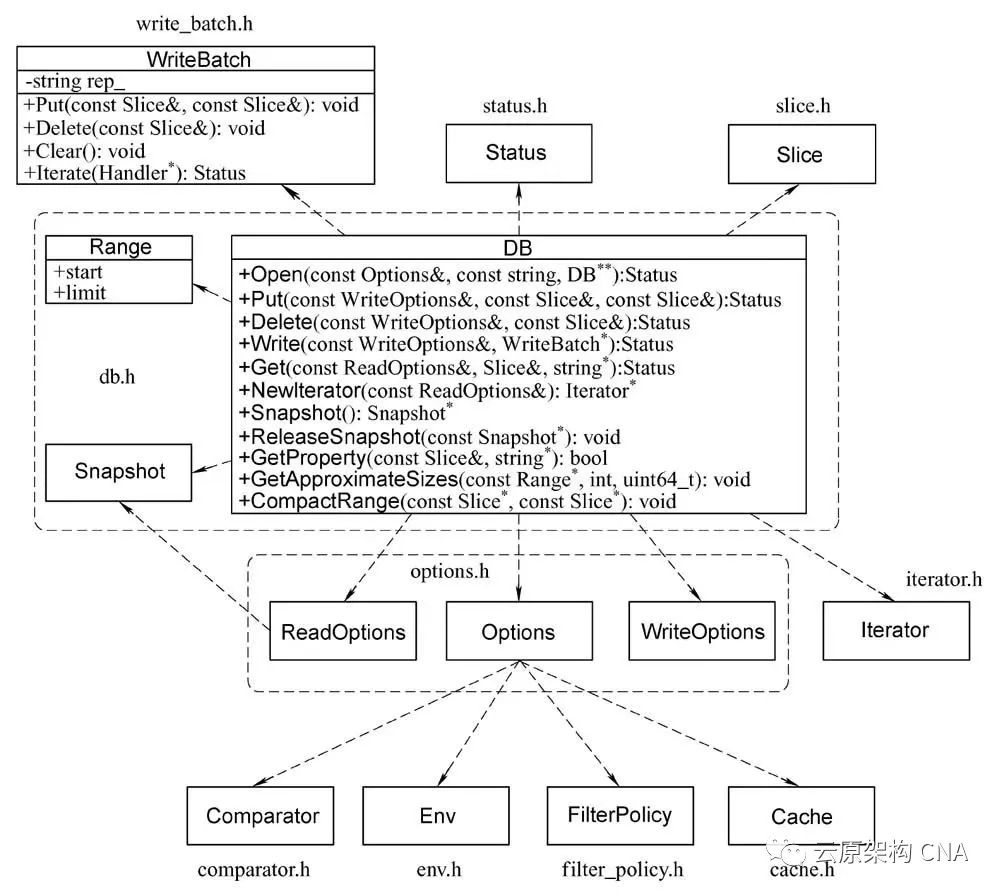
LevelDB 是什么?
LevelDB 就是一种为分布式而生的键-值数据库(一个C++语言编写的库)。键-值数据库主要用于存取、管理关联性的数组。关联性数组又称映射、字典,是一种抽象的数据结构,其数据对象为一个个的 key-value 数据对,且在整个数据库中每个key均是唯一的。某些应用中,写数据比读数据更加频繁,对数据写的速度要求也越来越高。社区的公认读均是有方法可以优化并提速的,写数据的场景就持续在不断的思考如何提速。
2006年,Google 发表了一篇论文—— Bigtable: A Distributed Storage System for StructuredData。这篇论文公布了Bigtable的具体实现方法(包括基本原理与技术架构),从而揭开了 Bigtable 的技术面纱。Bigtable 虽然也有行、列、表的概念,但不同于传统的关系数据库,从本质上讲,它是一个稀疏的、分布式的、持久化的、多维的排序键-值映射。LevelDB 可看作 Bigtable 的简化版或单机版。
特性
LevelDB是一个C++语言编写的高效键-值嵌入式数据库。
优点:key 与 value 采用字符串形式,且长度没有限制;数据能持久化存储,同时也能将数据缓存到内存,实现快速读取;基于 key 按序存放数据,并且 key 的排序比较函数可以根据用户需求进行定制;支持简易的操作接口API,如Put、Get、Delete,并支持批量写入;可以针对数据创建数据内存快照;支持前向、后向的迭代器;采用 Google 的 Snappy 压缩算法对数据进行压缩,以减少存储空间;基本不依赖其他第三方模块,可非常容易地移植到 Windows、Linux、UNIX、Android、iOS。
缺点:不是传统的关系数据库,不支持 SQL 查询与索引;只支持单进程,不支持多进程;不支持多种数据类型;不支持客户端-服务器的访问模式。用户在应用时,需要自己进行网络服务的封装。读者可以综合 LevelDB 的优缺点,有针对性地评估其是否适用于实际开发的项目/产品,并对最终是否使用进行决定。
存储系统
LevelDB 是单机版或简化版的 Bigtable,继承了 Bigtable 的相关概念与架构设计,也具有持久化、按键值顺序存储的特点。
Bigtable 有两个核心的组件:
master server:一个集群中只有唯一一个,用于管理 tablet server,将tablet 分配到 tablet server中。
tablet server:一个集群中存在许多个,主要受 master server 的管理与支配。tablet server 中有许多的 tablet。一般而言,每一个 tablet server具有10~1000个 tablet。tablet server 可以根据当前集群的负载,进行动态添加或删除 tablet。其主要由三部分构成:Log、MemTable、SSTable 文件。SSTable(Sorted String Table),是一种按键排序的、存储字符串形式键-值对的文件,可实现海量键-值对的高效存储。而 MemTable 则是这种键-值对在内存中的存储方式,当 MemTable 的使用空间达到某一个阈值时,则会将该部分内存中对应的数据导出到磁盘,并生成一个新的 SSTable 文件。
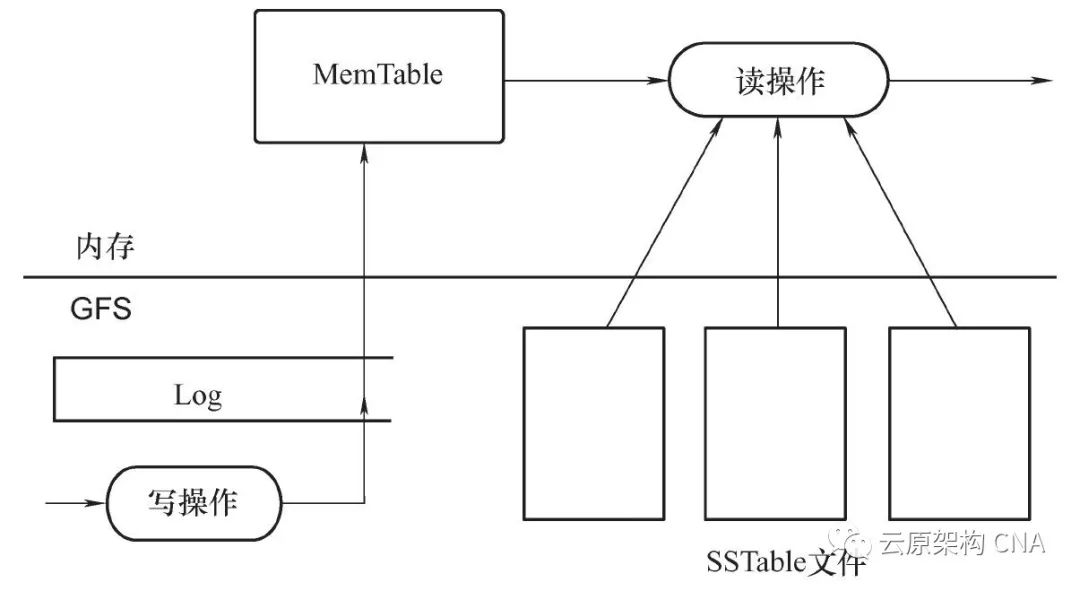
LevelDB 的基本结构与 tablet server 基本一致,只不过 LevelDB 是将数据存储在磁盘,而 tablet server 是将数据存储在 GFS 中。LevelDB 是基于LSM树(Log-Strucrued Merge Tree,日志结构合并树)进行存储。LSM 树是实现 levelDB 的核心。关于 LSM 树的具体介绍,读者可以参考O’ Neil所发表的The log-structuredmerge-tree(LSM-tree)这篇论文。
多版本管理与Compaction原理
LevelDB 中的 Level 代表层级,有0~6 共 7 个层级,每个层级都由一定数量的 SSTable 文件组成。其中,高层级文件是由低层级的一个文件与高层级中与该文件有键重叠的所有文件使用归并排序算法生成,该过程称为Compaction。LevelDB通过Compaction将冷数据逐层下移,并且在Compaction 过程中重复写入的键只会保留一个最终值,已经删除的键不再写入,因此可以减少磁盘空间占用。由于 Compaction 涉及大量的磁盘I/O操作,比较耗时,因此需要通过后台的一个独立线程执行该过程。
LevelDB 中 Level 0 的 SSTable 文件是由 MemTable 生成,每当 Level 0 的文件个数大于等于 4 时会触发一次 Compaction,并生成 Level 1的文件。而从Level 1 到 Level 5,当每个层级所有文件的大小之和超出该层允许的最大值时,也会触发一次 Compaction。其中 Level 1 允许的最大大小为10MB,Level 2 为 100MB,Level3 为 1000MB(即 1GB),Level4 为 10GB,Level5为 100GB,Level6 为 1TB。需要注意的是,Level 0的单个文件中的键是有序的,但在 Level 0 中的所有文件可能会出现键重叠的情况。而从 Level 1 到Level 6,不只单个文件中的键是有序的,每个层级中的所有文件也不会有键重叠。
当进行Compaction操作时,为了不影响 LevelDB 中键-值对的读取和写入,会使用一个单独的线程来执行。执行过程如下:首先选定本次Compaction 操作需要参与的文件,然后使用归并排序将所有参与文件中的数据排序后输出到新的文件之中,最后将该次变更情况记录到 Manifest 文件并且生成新的版本代表此次 Compaction 操作之后的各层级情况。
衍生系统
RocksDB(基于 LevelDB 开发的,并保留、继承了 LevelDB 原有的基本功能,也是一个嵌入式的键-值数据存储库) 和 LevelDB 一样,仍旧只是一个C++语言编写的库,而非一个分布式数据库,但是它作为存储引擎广泛应用到了多种主流的分布式数据库中,例如Cassandra、MongoDB、SSDB、TiDB。
RocksDB 设计之初,正值 SSD 硬盘兴起。然而在当时,无论是传统的关系数据库如MySQL,还是分布式数据库如 HDFS、HBase,均没有充分发挥 SSD 硬盘的数据读写性能。因而 Facebook 当时的目标就是开发一款针对SSD硬盘的数据存储产品,从而有了后面的 RocksDB。RocksDB 采用嵌入式的库模式,充分发挥了SSD的性能。
RocksDB 兼容 LevelDB 原有的API,但在开发设计过程中,针对性地对LevelDB 进行了一系列的优化与完善。具体主要体现在以下几个方面。
针对 SSD硬盘进行优化,支持更多的 IOPS(I/O Operation per Second),并改进数据压缩,减少数据写入,尽可能延长 SSD 的使用寿命。
针对多 CPU、多核环境进行优化,从而提升整体性能。一般而言,商用的服务器均采用多核的 CPU,RocksDB 不仅支持多线程合并、多线程内存表的插入,同时采用 MVCC,并将数据库的只读与读写操作分开,减少了锁的使用,从而更适合、进行高并发操作。
增加了一系列 LevelDB 不具备的功能,如数据合并、多种压缩算法、按范围查询,以及一些管理统计维护工具。
使用了一个插件式的架构,这使得它能够通过简单的扩展适用于各种不同的场景。插件式架构主要体现在以下几个方面。
不同的压缩模块插件:例如 Snappy、Zlib、BZip等(LevelDB只使用Snappy)。
Compaction 过滤器:一个应用能够定义自己的 Compaction 过滤器,从而可以在 Compaction 操作时处理键。例如,可以定义一个过滤器处理键过期,从而使 RocksDB 有了类似过期时间的概念。
MemTable 插件:LevelDB 中的 MemTable 是一个SkipList,适用于写入和范围扫描,但并不是所有场景都同时需要良好的写入和范围扫描功能,此时用 SkipList 就有点大材小用了。因此 RocksDB 的 MemTable 定义为一个插件式结构,可以是 SkipList,也可以是一个数组,还可以是一个前缀哈希表(以字符串前缀进行哈希,哈希之后寻找桶,桶内的数据可以是一个B树)。因为数组是无序的,所以大批量写入比使用SkipList 具有更好的性能,但不适用于范围查找,并且当内存中的数组需要生成为 SSTable 时,需要进行再排序后写入Level 0。前缀哈希表适用于读取、写入和在同一前缀下的范围查找。因此可以根据场景使用不同的 MemTable。
SSTable插件:SSTable也可以自定义格式,使之更适用于SSD的读取和写入。
Compaction 操作方面的优化,主要有以下几个方面。
线程池:可以定义一个线程池进行 Level 0~Level 5的 Compaction 操作,另一个线程池进行将 MemTable 生成为 SSTable 的操作。如果Level 0~Level 5 的 Compaction 操作没有重叠的文件,可以并行操作,以加快 Compaction 操作的执行。
多个 Immutable MemTable:当 MemTable 写满之后,会将其赋值给一个 ImmutableMemTable,然后由后台线程生成一个 SSTable。但如果此时有大量的写入,MemTable 会迅速再次写满,此时如果 Immutable MemTable 还未执行完 Compaction 操作就会阻塞写入。因此 RocksDB使用一个队列将 Immutable MemTable 放入,依次由后台线程处理,实现同时存在多个 Immutable MemTable。以此优化写入,避免写放大,当使用慢速存储时也能够加大写吞吐量。
此文章没有过多的实践,自己玩与使用此组件也过去很多年了,主要是整理最近阅读 《精通LevelDB》(廖环宇,张仕华) 之后的一些摘录与整理。
