




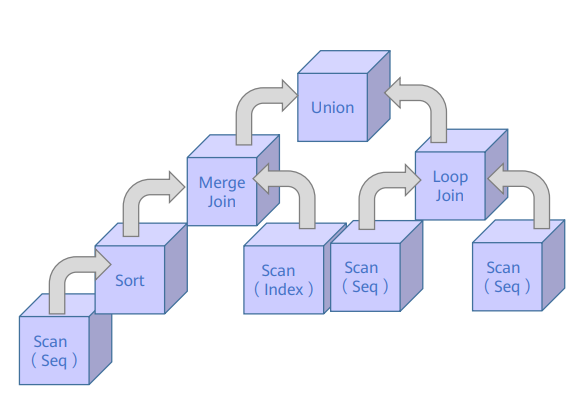
关系数据库本身是对关系集合Relation的运算操作,执行引擎作为运算的控制 逻辑主要是围绕着关系运算来实现的,算子可以分成以下几类:
1. 扫描算子(Scan Plan Node) 扫描节点负责从底层数据来源抽取数据,数据来源可能是来自文件系统, 也可能来自网络。一般而言扫描节点都位于执行树的叶子节点,作为执 行的数据输入来源,典型代表SeqScan、IndexScan、SubQueryScan 关键特征:输入数据、叶子节点、表达式过滤
2. 控制算子(Control Plan Node) 控制算子一般不映射代数运算符,是为了执行器完成一些特殊的流程引 入的算子,例如Limit、RecursiveUnion、Union 关键特征:用于控制数据流程
3. 物化算子(Materialize Plan Node) 物化算子一般指算法要求,在做算子逻辑处理的时候,要求把下层的数 据进行缓存处理,因为对于下层算子返回的数据量不可提前预知,因此 需要在算法上考虑数据无法全部放置到内存的情况,例如Agg、Sort 关键特征:需要扫描所有数据之后才返回
4. 连接算子(Join Plan Node)
这类算子是为了应对数据库中最常见的关联操作,根据处理算法和数据
输入源的不同分成MergeJoin,SortJoin,HashJoin。
关键特征:多个输入
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
