






分享嘉宾:黄俊深 PingCAP
编辑整理:林冬莲 易仓科技
出品平台:DataFunTalk
导读:本文将从TiDB的架构出发,为大家介绍如何在TiDB之上构建一个实时应用。主要包括以下三部分内容:
目前行业使用数据库的现状
对“HTAP”架构设计理念与设计思路的思考
浅谈TiDB使用场景
近几年来,越来越多的用户期待对数据的分析和访问做到更加实时,但传统的数据库,比如MySQL,扩展性存在一定的瓶颈。很多用户在遇到瓶颈后,可能会转向NoSQL,NoSQL能提供高频率的点查,但是NoSQL的系统缺乏复杂分析的能力。比如想像传统数据库那样使用二级索引来做一些查询,对全局做一些过滤,全局的聚合分析,在NoSQL上做会比较困难,可能要写很多业务代码,需要在业务层面上去解决,在业务场景比较固定的情况下,通过投入研发力量来实现、支持业务的统计需求。传统的大数据技术,比如Hadoop、Spark这种方案,在实时和高并发存取上有一定的缺陷,在实时数据更新方面做得不是很好。
这就造成了现在数据库中的场景,用户往往需要使用多个产品来拼凑成一个完整的解决方案。这样系统之间的数据同步又成为一个问题。可能需要通过像Kafka这样的数据管道来做数据同步,把整个数据链路串联起来。这样的情况下,整个系统数据的实时性和新鲜度就丢失了。另外还会带来一个问题,就是Spark、Hadoop这种生态跟传统运维的技术栈很不一样,整个集群的运维精力投入也是比较高的。
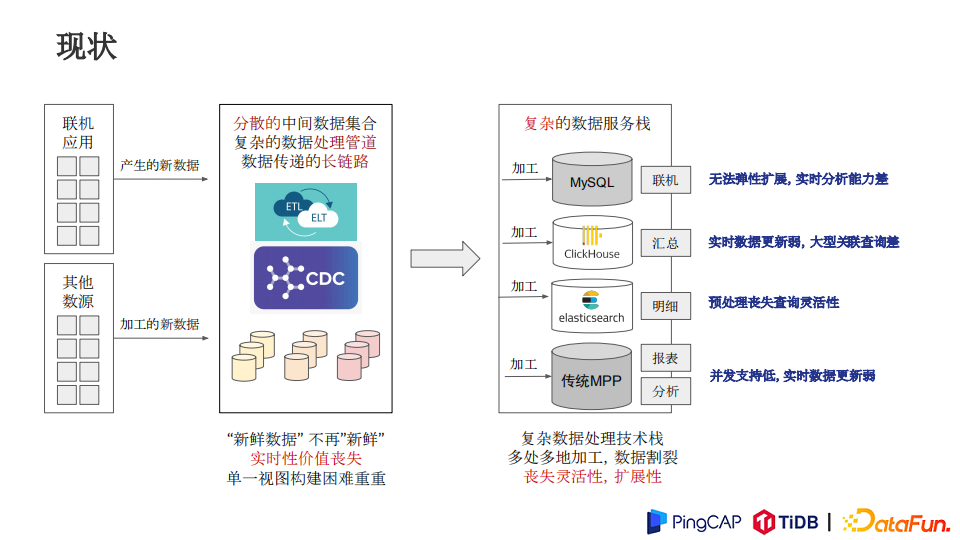
这是现在比较经典的解决方法,中间是比较分散的数据管道,前端连接的应用和其他数据源通过数据管道来汇总到后面不同数据的服务栈。比较在MySQL上面做的一些Sharding的方案,来做一个联机查询,来保证高并发的数据存取和事务的一致性。这样系统的弹性扩展能力比较差,同时实时分析的能力也比较差。数据的查询汇总可能会使用像ClickHouse这样的OLAP数据库,OLAP数据库的实时更新相对比较弱一些,在处理大型关联查询的时候能力会有点欠缺。也有会通过ElaticSearch来做一些明细数据的存储,ElaticSearch会对数据做一些预处理,会丧失查询的灵活性。在做一些跨表查询的话可能会不太方便。也会有人选择把数据落到传统的MPP,MPP并发支持比较低,实时数据更新比较弱。
这整套解决方案带来了两个问题,数据通过整套链路,实时性价值丧失,数据的新鲜度有一定丢失,比如说按天或按小时来做入库;另外一点是整个系统数据栈服务比较复杂的,整体快速迭代的灵活性较差,运维复杂度高。
下面是TiDB整体的架构
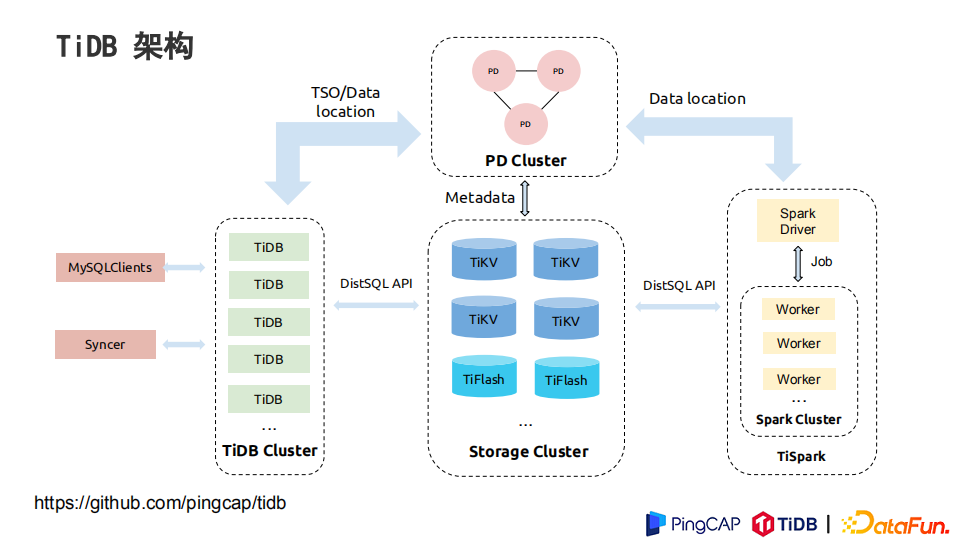
TiKV和TiFlash是存储的节点,TiKV是行存,TiFlash是列存,可以通过TiSpark连接大数据的生态。PD集群负责数据元信息,数据分片情况的存储,数据以Range分片的形式存储和进行热点的调度。
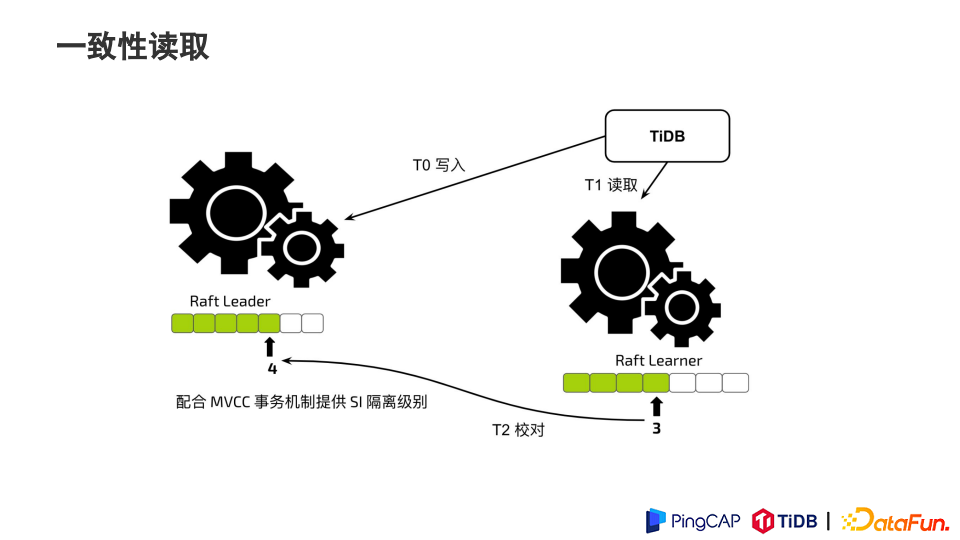
为了做到资源分离,TiDB采用行式、列式分别存储,而不是相同的文件格式存储。通过行存支持OLTP以及索引这样一些高并发的查询,通过列存支持BI类的查询。通过行列存储的节点资源分离,来确保Workload的隔离。因为TP的负载很多情况下是一个延迟非常敏感的负载。在进行AP分析的时候不想TP的延迟对吞吐量造成影响。同时,TiKV和TiFlash行列之间通过Raft协议进行复制,配合MVCC兼顾数据的一致性和新鲜度。
传统的列存在进行数据写入的时候,需要将数据拆散成不同的列,造成文件系统的负担比较大。针对这种情况,学术界和工业界有很多思考和实践,其中比较成熟的设计是DeltaMain的设计,以一种对写入比较友好的方式先将数据写入Delta区域,在Delta区域达到一定的量之后,跟列存的Main区域做一个合并,重新生成一份列存的数据。这样可以支持高速的更新写入,数据读取的时候性能也不会受到太大影响。
今年发布的TiDB5.0实现了MPP引擎,测下来MPP数据库的性能超出传统数据库性能两到三倍。
接下来我们回顾一下TiDB HTAP整个演进的思路和后面的一些思考。
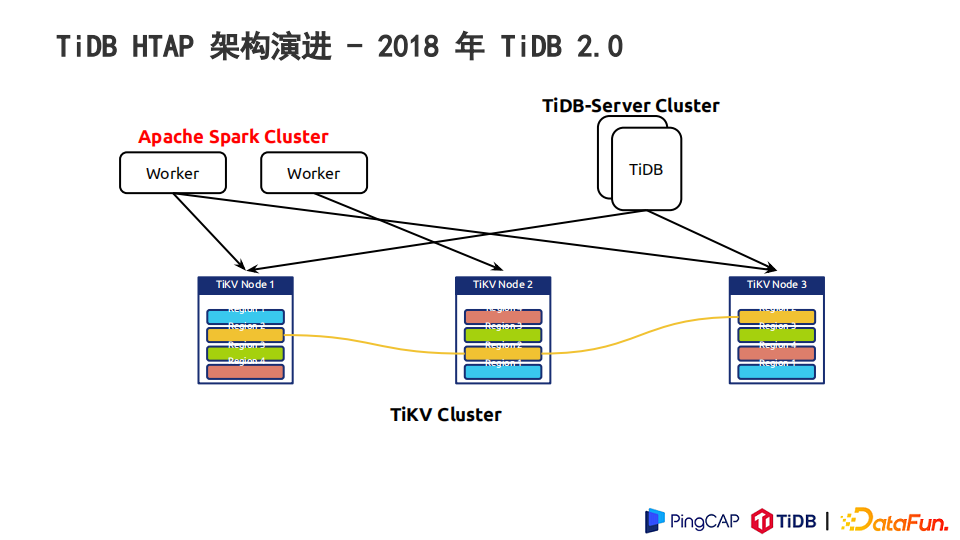
我们在2018年的时候推出了TiSpark的组件。TiSpark重写了Spark下面一些执行计划的逻辑,让它在TiKV的节点上像TiDB一样,可以拿到一些表的信息,能正确地理解和解码行的信息以及在上面做一些计算。这样一方面可以借助TiSpark引擎提升TiDB在AP方面的性能。另外TiSpark可以提供跟现有大数据生态更好的对接方式。比如可以在平时的业务上,通过TiDB、MySQL这样的一个接口来承载,后面通过TiSpark来访问到TiDB的一些数据,比如做一些汇总统计,入库到Hadoop或其他大数据生态集群里面。
这个架构下,TiSpark的查询还是会打到TiKV的存储节点上,TiSpark和TiDB都是对TiKV的节点做直接访问。通常AP查询又会比较重,消耗的资源较多,这样在做AP查询分析的时候会造成TP方的影响,比如延迟上升、吞吐量下降。这些在较严肃的TP场景下是不可接受的。
同时,TiKV里面的数据是按行的形式来存储,行的形式对AP的负载不友好,因为它在做分析型查询的时候会引入大量不必要的IO。
经过两年的迭代,我们推出了TiFlash,作为TiDB系统中的一个列存插件。
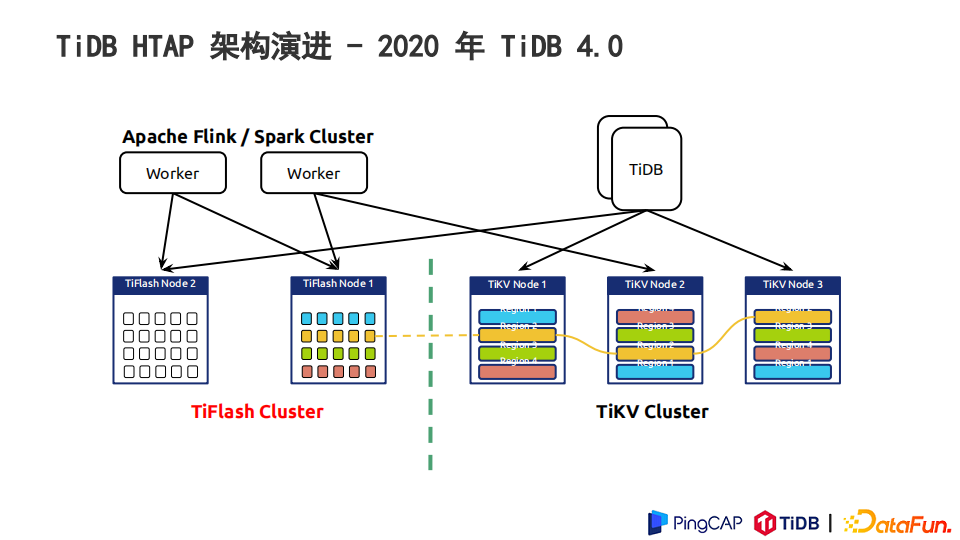
整体还是通过TiKV的形式来承载TP的写入,数据按照Range来进行分片,形成一个个的Region。当用户给表创建TiFlash副本后,相应的Region通过Raft协议,以Learner角色来加入到RaftGroup 中,与TiKV中的数据保持同步。
有了TiFlash之后,TiSpark可以把分析的负载发到TiFlash的节点上。因为TiFlash节点上数据是以列存的方式存储的,在执行AP负载的时候,能够裁剪不必要的IO。结合在AP场景下一些内置的粗糙索引对数据进行过滤,相对TiKV来说,在TiFlash的列存数据更好地适应AP场景。
另外可以通过与MySQL高度兼容的SQL语法,通过TiDB一个统一的入口,同时访问到TiFlash或TiKV。有些情况下TiDB这边执行优化器可能会同时用到TiFlash和TiKV,这样也是能做到的。这样的架构下,也可以通过TiDB中一些变量控制,做到TP负载和AP负载完全隔离,互相不会影响。
列存带来了在AP分析下比行存更好的性能,但是也存在一些问题。在一些很重的多表关联查询下,承载最终关联计算的节点可能还是TiSpark节点或单个TiDB节点。它们可以把数据以及一些过滤,聚合操作下发到TiFlash节点或TiKV节点,但是最终数据整个关联、汇总计算在TiDB这边会形成一个单点,这样多表关联查询情况下会形成一些瓶颈。
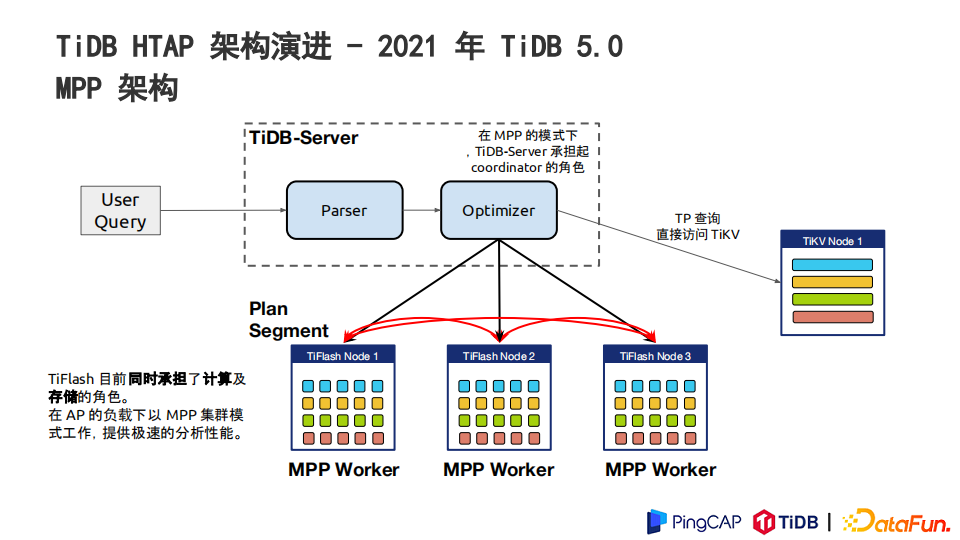
2021年TiDB5.0引入了MPP架构,主要解决之前整个计算需要把数据捞到TiDB做单点汇聚。在这个架构下,TiFlash节点之间做数据的Shuffle操作,能让TiFlash同时承担一部分计算和存储的功能。TiDB5.0下,TiFlash节点之间组成一个MPP的集群,MPP集群让TiFlash节点能更好地承担节点间数据的Shuffle,Shuffle之后能更好地在MPP节点间做并行的分析查询。在大型的多表关联的分析场景下能达到更好的性能。
在MPP模式下,TiDBServer承担起了coordinator的角色,它会承担起用户的SQL语句的解析,还有生成整个执行计划。优化器也会判断这个查询适合走到TiKV,还是更适合通过MPP的形式把这个语句发到TiFlash集群上去执行。后端的引擎选择,对用户的查询能做到透明。
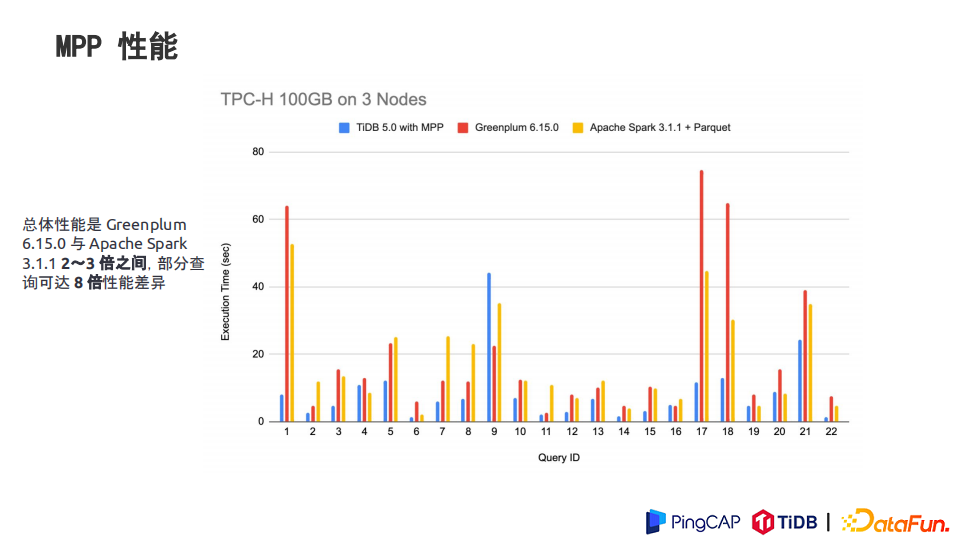
MPP 架构下,计算可被多节点分担以充分利用分布式计算的性能优势。
性能提升:5.0 TiFlash双节点比4.0 TiFlash双节点:SQL1 - SQL6 SQL执行时间平均降低:46.91%;Q5,查询耗时从3.40s 降低到 0.67s,下降80.29%;Q6,查询耗时从118.00s 降低到 6.10s,下降 92.17%;6 个SQL 查询,5.0 对比 4.0 总耗时从 88.26s 下降到 12.68s。
1. TiDB HTAP场景
(1) TP + AP
以行存支撑 TP 类业务,满足高并发读写:透明扩展,完整的 SQL、事务支持,强一致性;
以列存支持分析类业务,满足中低并发 BI 分析:高性能,行列一致性同步,确保数据新鲜度。
(2) Streaming 和 CDC 接入
在线 Schema 变更
支持增删改的存储支持
同时支持索引查询和批量查询
2. 实时大屏和BI
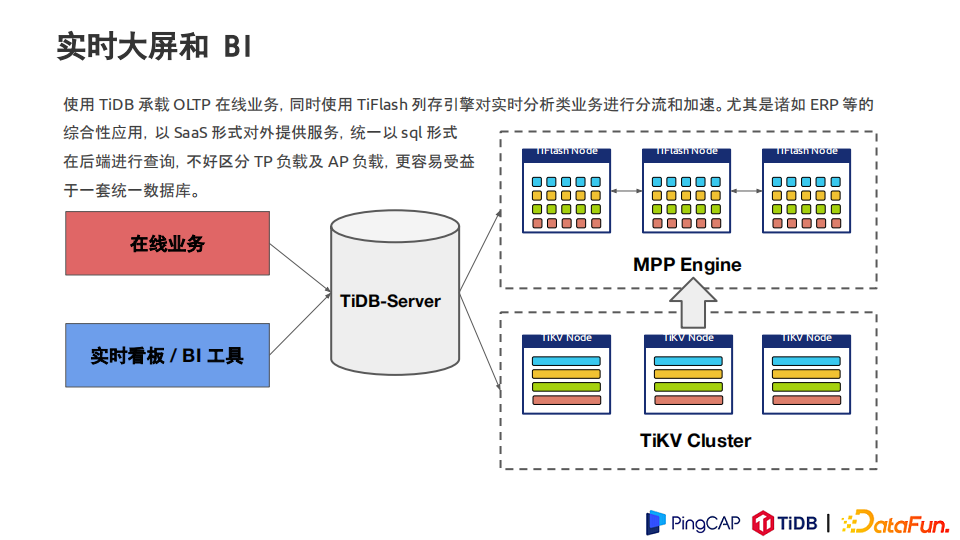
使用 TiDB 承载 OLTP 在线业务,同时使用 TiFlash 列存及MPP引擎对实时分析类业务进行分流和加速。尤其是诸如 ERP 等的综合性应用,它们以 SaaS 形式对外提供服务,统一以 sql 形式在后端进行查询。查询时不好区分 TP 负载及 AP 负载,更容易受益于一套统一数据库。
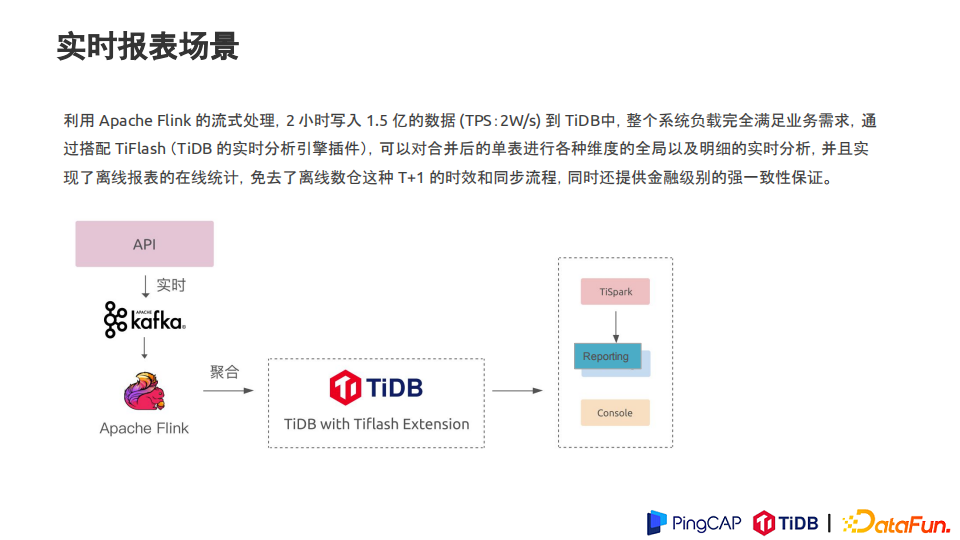
3. 实时报表
利用 Apache Flink 的流式处理,2 小时写入 1.5 亿数据 (TPS:2W/s) 到 TiDB中,整个系统负载完全满足业务需求,通过搭配 TiFlash,可以对合并后的单表进行各种维度的全局以及明细的实时分析,并且实现了报表的在线统计,免去了离线数仓这种T+1 的时效和同步流程,同时还提供金融级别的强一致性保证。
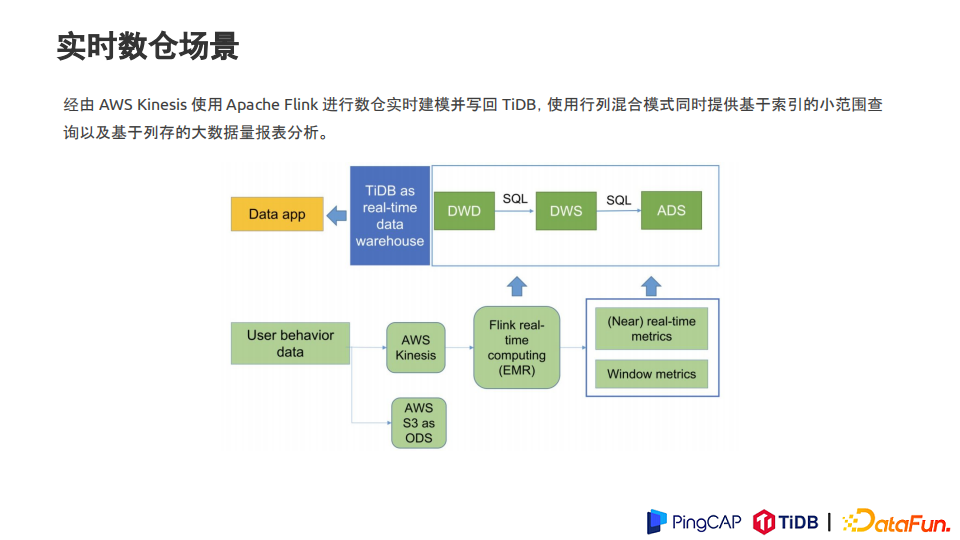
4. 实时数仓
经由 AWS Kinesis 使用 Apache Flink 进行数仓实时建模并写回 TiDB,使用行列混合模式同时提供基于索引的小范围查询,以及基于列存的大数据量报表分析。
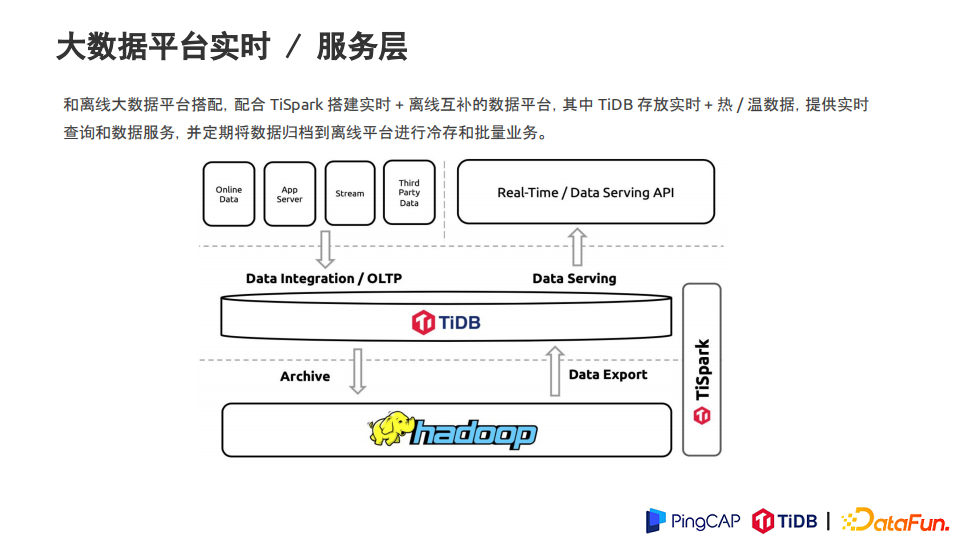
5. 大数据平台实时 / 服务层
和离线大数据平台搭配,配合 TiSpark 搭建实时 + 离线互补的数据平台,其中 TiDB 存放实时 + 热 / 温数据,提供实时查询和数据服务,并定期将数据归档到离线平台进行冷存和批量业务。
TiDB为用户提供了一站式OLTP、OLAP、HTAP解决方案,有着广泛的企业级应用场景,适合高可用、强一致性要求较高、数据规模较大的各种应用场景。
Q:TiFlash和TiKV都需要存储,所以TiDB的数据需要存两份吗?还有除了learner抄写外,还有额外的副本机制吗?
A: 我先回答一下第二个问题。副本是在TiKV这边做三副本,TP侧通过Raft协议来提供高可用,AP侧通过建立两个learner副本来实现高可用。对于列存是否造成额外的存储,这个问题可以这样去看。假如说提前有一个比较大量的数据,你把它存在TP的系统里面,TP的形式是一个行存的,行存天然对AP的操作是不友好的。你可以在TP上做一些AP的分析,但是会导致整个查询性能比较低、TP的负载受影响会比较大。在这种前提下想要解决这个问题,通常的做法是通过一些数据管道,将数据同步到MPP的数据库,然后在MPP的数据库上做一些AP类的查询。这种情况下你原来已经有行存的副本,就是跟原来的服务是一样的。中间还要搭建一些比如像Kafka这样的数据管道,然后在MPP那边还要做一些查询。另外为了AP的高可用,需要在MPP那边创建一些副本。TiDB这个体系中间数据同步的管道,是利用Raft协议来消除了。TiFlash列存副本,可以对应到单独部署的MPP集群,提供更好的AP查询服务,同时也能够做到跟TP的业务隔离,让AP的业务不会受到TP的影响。我觉得应该以这样的角度来理解副本的开销。所以TiFlash和TiKV是分离的两份存储。
Q:刚才提到说TiDB 5.0,我们看到它的OLAP能力相比之前有非常大的提升,大家肯定也想尽快地用起来,那现在这个TiDB 5.0我们可以获得吗?
A:TiDB整个技术,整个场景都是开源的,在我们的官网上有一个tiup工具(https://tiup.io),这个工具可以很简单部署起一个集群。如果使用上遇到问题,可以到asktug.com的社区上去提问,上面有我们的一些支持工程师来做解答。
Q:从4.0到5.0是可以做到透明升级吗?还是要做一些数据库搬迁?
A:是可以做到数据原地升级。如果之前已经部署了TiDB 4.0、3.0的集群,可以利用tiup工具来做一个原地的升级。升级之后通过开启一些变量以及SQL语句,可以马上给表创建TiFlash一个副本,然后利用MPP引擎进行计算。
Q:TiDB扩容的原理是什么,扩容的时候怎么操作?
A:我们所有数据都是以Range分片的形式,每个分片是一个Region,比如扩容一个TiKV节点或一个TiFlash节点,那么它其实就是把一些Region迁移到新的节点。在这种情况下整个集群的查询和更新可以由其它一些副本来承载,只是其中的一个副本搬到新的节点上。搬迁完之后再升级为Raft leader角色来对外提供读写服务。整个搬迁的工作是由PD来做调度,这样就可以做到平滑地升级。
Q:TiKV和TiFlash分别是几个副本?
A:因为TiKV自己要做一个高可用的Raft Group,所以生产环境需要三副本,这也是所有强一致性协议推荐的最小配置。TiFlash作为一个抄写的角色。假如线上AP业务这边挂了也没关系,而且资源比较紧张的情况,也就是说整个AP的高可用不是十分重要的话,TiFlash这边可以建单副本。一般为了TiFlash的AP高可用,可以在TiFlash也建两副本。这样的话假如有一个TiFlash节点宕机了,TiDB会感知到这个TiFlash节点宕机,然后把请求路由到另一个TiFlash节点上提供AP的服务。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

活动推荐:
2月27日,我们将邀请来自亚马逊云科技、贝壳、腾讯音乐的三位嘉宾,就MLOPS相关主题进行分享,感兴趣的小伙伴欢迎识别海报二维码免费报名!

关于我们:
🧐分享、点赞、在看,给个3连击呗!👇
