




并行查询直接读取磁盘数据,不写入缓存,而直接交给调用进程。直接读取磁盘时,一次读取 多个数据块,并采用了多数据块读的参数设置。因此,只有那些多数据块读的操作会并并行化。
而对并行操作的代价估算,就是以串行操作代价为基础,考虑并行度(Degree Of Parallel,
DOP),估算出完成并行查询的代价。其中,并行度由以下几个设置控制:
o 由提示(PARALLEL)或 PARALLEL 子句指定的并行度;
o 由会话级别系统参数(parallel_max_servers、parallel_min_servers、parallel_min_percent 等) 指定的并行度限制;
o 创建(CREATE)或修改(ALTER)表、索引时指定的并行度;
提示:生产者/消费者模式下,每个并行处理由一对进(线)程,因此,并行度不能超过最大并行 进程设置的 1/2。
6.6.1 IO 代价计算
无论是 IO 代价模型还是 CPU 代价模型,对并行操作的 IO 代价估算都是一样的:由串行 IO 代价除以并行度(DOP)。
IOCOST[Parallel] = IOCOST[Serial] / DOP
在并行模式下,对象的存储段被划分为多个范围,每个并行服务进程读取一个范围内的数据块。因此,每个范围的尾部都可能有少量数据块未达到一次多数据块读可以读取的数量,因而会导致并 行读的总 IO 次数会大于串行读模式下的额 IO 次数。相应的,IOCOST[Serial]需要乘以系数进行调整。在目前版本(10g、11g)中,我们观察到该系数为 10/9。
IOCOST[Parallel] = IOCOST[Serial]*10/9/DOP
此外,还有一个参数(_optimizer_percent_parallel,PPCT,默认为 101)用于控制优化器在估算时,采用并行度代价估算的比例。考虑到该参数,并行操作的 IO 代价公式调整为:
IOCOST[Parallel] = GREATEST(0,1-PPCT)IOCOST[Serial] + PPCTIOCOST[Serial]*10/9/DOP
示例:
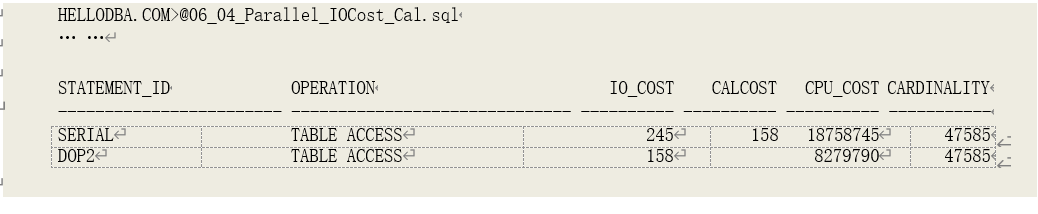
上述例子中,串行执行时,IO 代价为 245;在并行执行时,DOP 为 2、MBRC 为 8,并对 80%代价做并行代价估算,计算得到 IO 代价为 158。
o 系统 IO 吞吐量限制
对于每一个操作系统而言,它的 IO 带宽都是由限制,这也决定了 Oracle 的 IO 的最大吞吐量
(Maximum Throughout)。相应的,在负载模式下收集系统统计数据时,也会收集到这一数据
(MAXTHR,单位为 Bytes/Sec)。而这一统计数据也就决定全表扫描的最小代价:
IOCOST[Min 1] = IOCOST[FTS] / (MAXTHR*2/OPTBLK)
在并行执行中,每个并行服务进程同样会受到最大 IO 吞吐量的限制。在负载模式下收集系统统计数据时,也会收集到并行进程的最大吞吐量统计数据(SLAVETHR,单位为 B/S)。这一数据也限制了并行进程的最小代价:
IOCOST[Min 2] = IOCOST[FTS] / (SLAVETHR*2/OPTBLK * DOP)
提示:一组并行服务由消费者和生产者两个进程组成,因此这里需要乘以 2。
优化器最终会取 IOCOST[Parallel]、IOCOST[Min 1]和 IOCOST[Min 2]三者中的最大值作为估算的代价值。
示例:
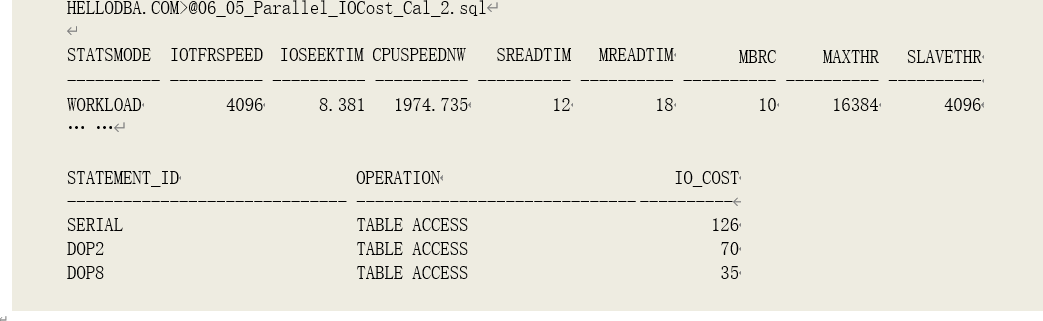
在上例中,表 T_OBJECTS 的数据块数(#BLKS)为 830;系统统计数据中,MBRC 为 10,
MREADTIM 为 18,SREADTIM 为 12。未作取整时的全表扫描代价为: IOCOST[FTS] = #BLKS / MBRC * MREADTIM / SREADTIM
= 830/10*18/12
= 124.5
根据系统参数调整后,估算出串行方式下的 IO 代价为:
IOCOST[Serial] = CEIL(IOCOST[FTS]) + 1
= CEIL(124.5) + 1
= 126
由并行查询的最大 IO 吞吐量限制计算出的代价为:
IOCOST[Min 1] = ROUND(IOCOST[FTS] / (MAXTHR2/OPTBLK))
= ROUND(124.5/(163842/8192) * 10/9)
= 35
o 当 DOP = 2 时,由并行度计算出的代价为:
IOCOST[Parallel] = GREATEST(0,1-PPCT)IOCOST[Serial] + PPCTIOCOST[Serial]10/9/DOP =
ROUND(12610/9/2) = 70
由并行进程最大 IO 吞吐量限制计算出的代价为:
IOCOST[Min 2] = ROUND(IOCOST[FTS] / (SLAVETHR2/OPTBLK * DOP)) =
ROUND(124.5/(40962/8192*2)*10/9) = 69
优化选择三者中的最大值,即 70(IOCOST[Parallel])。
o 当 DOP = 8 时,由并行度计算出的代价为:
IOCOST[Parallel] = GREATEST(0,1-PPCT)IOCOST[Serial] + PPCTIOCOST[Serial]10/9/DOP = ROUND(12610/9/8) = 18
由并行进程最大 IO 吞吐量限制计算出的代价为:
IOCOST[Min 2] = ROUND(IOCOST[FTS] / (SLAVETHR2/OPTBLK * DOP)) =
ROUND(124.5/(40962/8192*8)*10/9) = 17
优化选择三者中的最大值,即 35(IOCOST[Min 1])。

表 T_OBJECTS 的总数据记录数(ALLROWS)为 47585,并且由之前示例的计算过程中知道,过滤条件 object_name like 'T%'的选择率为 0.006759601,过滤处理指令数(FLTCYCLES)为 100,从而得到串行总指令数:
#CPUCYCLES[Serial] = 47585130 + 47585220 + ROUND(475850.006759601)520 + 47585100
= 47585130 + 47585220 + 322520 + 47585*100
= 12880150
考虑并行度,得到并行执行的 CPU 总指令数:
#CPUCYCLES[Parallel] = ROUND(1288015010/9/2) = 7155639
6.7 单数据块读操作代价计算
在执行计划的操作中,索引范围扫描(Index Range Scan)、索引唯一扫描(Index Unique
Scan)、索引完全扫描(Index Full Scan)以及由 ROWID 访问表(Table Access By Rowid)等操作是属于单数据块读操作。我们以对普通(BTree)索引的范围扫描和由索引 ROWID 访问表为例,分别分析在 IO 代价模型和 CPU 代价模型中,其代价估算过程。
6.7.1 IO 代价计算
在 IO 代价模型和 CPU 代价模型中,单数据块读的 IO 代价计算方式都是一致的。由于索引范围扫描中仅有单数据块读,不存在多数据块读(即#MRDS=0),因此其代价估算公式为:
IOCOST = SRDCOST = #SRDS
在进一步分析代价计算公式之前,我们需要先简单了解通过索引读取数据的步骤:
由访问条件(Access Predication)从索引树上,由根节点开始,通过访问条件与键值(key) 的匹配,找到叶子数据块;
从叶子数据块上找到符合访问条件的索引记录;
o 如果存在谓词条件存在对索引字段的过滤条件,则由过滤条件过滤掉不匹配的记录;
如果父操作仅需要获取索引上的字段(包括 ROWID),则返回相应字段;
如果父操作还需要获取索引以外的字段,则返回 ROWID,父操作由 ROWID 从表中获取相应记录和字段;
如果还存在其他字段的过滤条件,则根据过滤条件对数据集进行过滤
提示:根据对操作获得的数据集的影响不同,查询语句中的谓词条件分为两类:一类是在读取物理 数据时,使 Oracle 仅访问符合条件的数据,称为访问条件;另外一类是在 Oracle 读取到了数据集以后,再对数据集进行过滤,抛弃(Throw Out)不符合条件的数据,称为过滤条件。
索引范围扫描
由上述过程可知,对索引本身的访问,单数据块读的数量由枝节点数据块读取数(Read Branch
Blocks,RBBLKS)和叶子节点数据块读取数(Read Leaf Blocks,RLBLKS)决定,即:
#SRDS = RBBLKS + RLBLKS
我们逐一找出影响索引范围扫描的 IO 代价估算的因素。
o 索引树的枝节点层数(Branch Level,BLVL)
在 B*Tree 结构中,每个叶子节点都存储了指向上一叶子节点和下一叶子节点的地址,也就是说, 所有叶子节点本身就构成了一个按照索引记录顺序排列的双向链表。因此,根据访问条件获取索引 记录,只需要找到第一个符合条件的记录即可。而在对索引树的枝节点(包括根节点)的访问匹配 时,可以由访问条件找到指向子节点的键值记录。综合上述因素,对于多层树的访问,每一层的枝 节点都会且仅会读取一个数据块。也即是说,索引树的枝节点层数成为了索引访问的 IO 代价的决
定因素之一,它也是索引统计数据之一。枝节点数据块读取数就等于索引树的枝节点层数。
RBBLKS = BLVL
提示:对于索引范围扫描,存在一种特殊情况,当枝节点层数为 1 时(即仅有根节点,没有枝节点存在),且索引中所有字段在访问条件中都为等于匹配(AllEqRange),优化器会将估算出的代价值减 1。
o 叶子数据块数(Leaf Blocks,LBLKS)和访问条件选择率(Access Selectivity,INDACCSEL) 由访问条件定位到第一个叶子节点后,Oracle 再由访问条件从叶子节点的双向链表中获取符合
条件的叶子节点数据块。最终读取的叶子节点数据块的数量则由叶子节点总数和访问条件选择率共
同决定,而叶子数据块数也是索引统计数据之一。对索引访问条件的选择率计算,也就是对条件中 字段匹配选择率的计算。计算方法可以参见全表扫描代价计算章节中的字段选择率的计算。
RLBLKS = CEIL(LBLKS*INDACCSEL)
o 优化器索引代价调节比(OPTICA)
由单数据块读读入缓存的数据块会被放置在缓存链表中的前列,使得他们不容易很快被置换出去。在 OLTP 系统中,通过索引访问数据是系统中数据的主要访问方式。当缓存空间足够时,我们会更希望这些数据能尽量久的存在缓存当中,使得后续访问能命中缓存。为了调整索引访问被优化 器所采纳的几率,Oracle 提供了一个参数(优化器索引代价调节比,optimizer_index_cost_adj,
OPTICA)用于对计算得到的代价进行加权。它的数值为百分比数值,范围为 1~1000,默认值是
100,即不做调节。
综上,可以得到索引访问的 IO 代价计算公式:
IOCOST = ROUND((BLVL + CEIL(LBLKSINDACCSEL)) * OPTICA/100)
o 缓存数据块和缓存命中率
启用了缓存统计数据(_optimizer_cache_stats 设置为 TRUE)后,叶子数据块 IO 代价值由叶子数据块缓存命中率(CACHEHIT)调整 IO 代价。
RLBLKS = CEIL(LBLKSINDACCSEL*CACHEHIT)
当统计数据中存在缓存数据块数(CACHEDBLK)时,缓存命中率由其计算得出:
CACHEHIT = (LBLKS-CACHEDBLK)/LBLKS
引入缓存统计数据后的 IO 代价计算公式为:
IOCOST = ROUND((BLVL -1 + CEIL(LBLKSINDACCSELCACHEHIT)) * OPTICA/100)
而当启用了缓存统计数据后,如果对应表上存在缓存统计数据,而索引上不存在缓存统计数据, 优化器会将计算所得的叶子数据块 IO 代价值减 10(结果小于 0 则取 0),枝节点 IO 代价部分会减1:
IOCOST = ROUND((BLVL -1 + CEIL(LBLKSINDACCSEL) - 10) * OPTICA/100)
o 示例
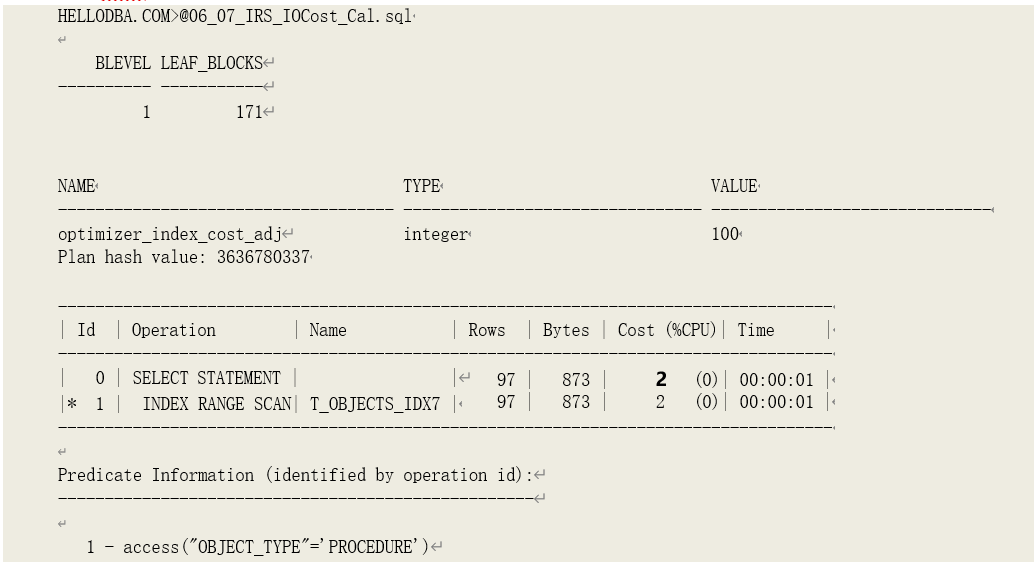
上例中,索引 T_OBJECTS_IDX7 的 BTree 高度为 1,叶子数据块数为 171,索引代价调节比为
100。根据字段匹配的选择率计算方法,计算得到访问条件 object_type = 'PROCEDURE’的选择率为
0.002023。由代价计算公式计算得到索引范围扫描的代价为:
IOCOST = ROUND((BLVL + CEIL(LBLKSINDACCSEL)) * OPTICA/100)
= ROUND((1 +CEIL(1710.002023))*100/100)
= 2
索引唯一扫描
对索引唯一扫描(Index Unique Scan)进行代价估算时,优化器会认为索引的根节点是被缓存
在内存中的。并且,根据唯一索引本身的特点,该操作会读取并只会读取一个叶子节点和一条记录。有了这两个前提,索引唯一扫描的代价估算公式实际上也是索引范围扫描代价公式的衍生。
考虑到根节点被缓存,因此要减 1,再加上 1 个叶子节点。
IOCOST = BLVL - 1 + 1
= BLVL
其中,BLVL 为索引树的高度。
由索引 ROWID 访问表
如果查询还需要获取索引字段以外的字段数据,则对索引的访问就会获取索引记录中的 ROWID, 再由 ROWID 访问表。我们下面逐一列出影响索引范围扫描的 IO 代价估算的因素。
o 索引过滤条件选择率(Index Filter Selectivity,INDFLTSEL)
在由访问条件读取到了索引数据记录后,如果还存在索引上的过滤条件,则需要已经过滤条件 将不符合要求的数据丢弃掉,最终得到的索引记录上的 ROWID 就是用于访问表的 ROWID。过滤条件选择率的计算,是在访问条件选择率的基础上,再结合过滤字段选择率进一步得到的。
o 簇集因子(Clustering Factor,CLUF)
通过访问条件从索引上获取的索引记录大部分都是连续的。而通过索引记录上的 ROWID 去读取表的数据块时,是按照索引记录逐个访问表的数据块。当连续的多个 ROWID 都指向同一个表数
据块时(即它们是簇集的),这个数据块就只需要读取一次以获取这些 ROWID 所指向的数据记录; 如果下一个 ROWID 指向了另外一个数据块时,无论这个数据块是否在之前被读取过,都会产生一
次逻辑读(Logical Read)。
在索引的统计数据中,存在一个这样的数据,它代表了连续的索引记录上的 ROWID 所指向的表数据块的簇集性。这个统计数据就是簇集因子(Clustering Factor)。而簇集因子也就是决定通过索引 ROWID 访问表的 IO 代价的决定因素之一。
“由索引 ROWID 访问表”这一操作是索引访问操作的父操作,它的代价中还包含了其子操作的代价。此外,索引代价条件比对其同样其作用。因此,它的 IO 代价计算公式为:
IOCOST = ROUND((BLVL + CEIL(LBLKSINDACCSEL) + CEIL(CLUFINDFLTSEL)) * OPTICA/100)
o 缓存数据块和缓存命中率
当启用了缓存统计数据后,则访问表的 IO 代价值取表的数据块数,而不是通过簇集因子和索引过滤选择率计算得出。
IOCOST = ROUND((BLVL + CEIL(LBLKSINDACCSEL) + ROUND(#BLKSCACHEHIT)) * OPTICA/100)
当统计数据中存在缓存数据块数(CACHEDBLK)时,缓存命中率由其计算得出:
CACHEHIT = (LBLKS-CACHEDBLK)/LBLKS
o 示例

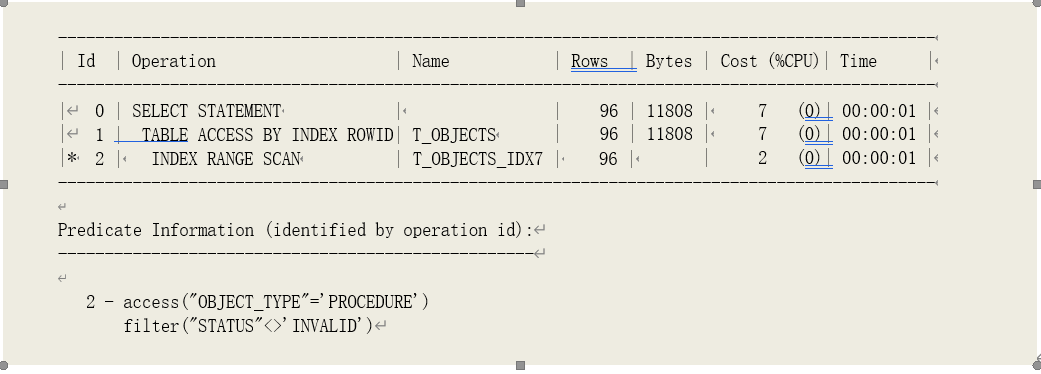
上例中,索引 T_OBJECTS_IDX7 的 BTree 高度为 1,叶子数据块数为 171,索引簇集因子为
2044,索引代价调节比为 100。根据字段匹配的选择率计算方法,计算得到访问条件 object_type =
'PROCEDURE’的选择率为 0.002023,过滤条件 STATUS<>'INVALID’的选择率为 0.992883。由代价计算公式计算得到索引范围扫描的代价为:
IOCOST = ROUND((BLVL + CEIL(LBLKSINDACCSEL) + CEIL(CLUFINDFLTSEL)) * OPTICA/100)
= ROUND((1 +CEIL(1710.002023)+CEIL(20440.0020230.992883))*100/100)
= 7
6.7.2 CPU 代价计算
我们以索引范围扫描和由索引 ROWID 访问表这两个操作为例,分析单数据块读的 CPU 代价计算。
索引范围扫描
索引范围扫描的处理过程包含四个部分:从磁盘读取数据块到内存;请求进程从内存获取数据块;从叶子数据块上获取索引记录;依据过滤条件对字段数据进行匹配、以过滤数据。相应的,其
CPU 总指令数计算公式为:
#CPUCYCLES = DISKBLK*(RDCYCLES+RBCYCLES) + CACHEBLKRBCYCLES + INDACCROWSGICYCLES
- INDACCROWS*PICYCLES
其中,
o DISKBLK 为从磁盘读取的数据块数,即单数据块读的次数;
DISKBLK = #SRDS
o RDCYCLES 为从磁盘读取一个数据块的 CPU 总指令数,和多数据块读中的计算相同
RDCYCLES = (0.32OPTBLKSIZE + 3650)
o RBCYCLES 为从内存读取一个数据块的 CPU 总指令数,和多数据块读中的计算相同
RBCYCLES = 850
o CACHEBLK 为缓存数据块数,由缓存统计数据计算得出
CACHEBLK = DISKBLKCACHEHIT = #SRDS*CACHEHIT
o INDACCROWS 为由访问条件获取到的索引记录数;
INDACCROWS = INDROWS * INDACCSEL
其中,INDROWS 为索引的总索引记录数,是一个统计数据;
o GICYCLES 为从叶子数据块中读取一条索引记录的 CPU 指令数;
GICYCLES = 200
o PICYCLES 为由过滤条件过滤一条索引记录的 CPU 指令数;
对于单个字读匹配过滤条件的 CPU 指令数,和多数据块读计算过程中给出的数值一致, 与字段的数据类型相关;
对于多个字读匹配复合过滤条件的 CPU 指令数计算,按照以下公式计算
表 6-10 关系表达式的 CPU 指令数

其中,字段 a 在索引中的位置比字段 b 靠前,且 a 未在访问条件中出现过。
代入以上计算公式和数值,索引范围扫描的 CPU 总指令数的计算公式如下,
#CPUCYCLES = ROUND(#SRDS*(0.32OPTBLKSIZE + 3650 + 850)) + ROUND(#SRDSCACHEHIT*850)
- CEIL(INDROWS*INDACCSEL)200 + ROUND(INDROWSINDACCSEL)*PICYCLES
如果考虑索引代价调节比,则公式可以进一步写为:
#CPUCYCLES = ROUND(ROUND(#SRDS*(0.32OPTBLKSIZE + 3650 + 850)) + ROUND(#SRDSCACHEHIT850) + CEIL(INDROWSINDACCSEL)200 + ROUND(INDROWSINDACCSEL)PICYCLES)OPTICA/100)
索引唯一扫描
根据索引唯一扫描的特点,只会读取到 1 条索引记录。同样,还要考虑 1 个索引块被缓存:
#CPUCYCLES = ROUND(ROUND((BLVL - 1 + 1)(0.32OPTBLKSIZE + 3650 + 850)) + (1850) + 1200))
由索引 ROWID 访问表
由索引 ROWID 访问表的处理过程包含四个部分:从磁盘读取数据块到内存;请求进程从内存获取数据块;从数据块上获取数据记录;从数据记录上获取字段;依据过滤条件对字段数据进行匹 配、以过滤数据。相应的,其 CPU 总指令数计算公式为:
#CPUCYCLES = DISKBLK*(RDCYCLES+RBCYCLES) + CACHEBLKRBCYCLES +
TABACCROWSGRCYCLES + TABACCROWSCOLNUMSGCCYCLES + TABACCROWS*FLTCYCLES
其中,
o DISKBLK 为从磁盘读取的表数据块数,即单数据块读的次数;
DISKBLK = #SRDS[Access Table]
o RDCYCLES 为从磁盘读取一个数据块的 CPU 总指令数,和多数据块读中的计算相同
RDCYCLES = (0.32OPTBLKSIZE + 3650)
o RBCYCLES 为从内存读取一个数据块的 CPU 总指令数,和多数据块读中的计算相同
RBCYCLES = 850
o CACHEBLK 为缓存数据块数,由缓存统计数据计算得出
CACHEBLK = DISKBLKCACHEHIT = #SRDS[Access Table]CACHEHIT
o TABACCROWS 为从表上读取的记录数,由于一个索引及的 ROWID 对应一条表记录,该值也就是对访问索引得到记录数再由索引过滤条件过滤后的索引记录数;
TABACCROWS = INDROWSINDFLTSEL
o GRCYCLES 为从表数据块上读取一条数据记录的 CPU 指令数,和多数据块读中的计算相同;
GRCYCLES = 130
o COLNUMS 为获取的字段数,由索引字段位置最大值(MAXINDCPOS)、选择字段位置最大值(MAXSELCPOS)和谓词条件字段位置最大值(MAXFLTCPOS)共同决定,取他们三者之间的最大值;
COLNUMS = GREATEST(MAXINDCPOS, MAXSELCPOS, MAXFLTCPOS)
o GCCYCLES 为获取一个字段的 CPU 指令数,和多数据块读中的计算相同;
GCCYCLES = 20
o FLTCYCLES 为一个或多个复合条件过滤一条记录的 CPU 指令数,与全表扫描中的计算相同
代入以上计算公式和数值,由索引 ROWID 访问表的 CPU 总指令数的计算公式如下,
#CPUCYCLES = ROUND(#SRDS*(0.32OPTBLKSIZE + 3650 + 850)) + ROUND(#SRDSCACHEHIT*850)
- CEIL(INDROWS*INDFLTSEL)130 + CEIL(INDROWSINDFLTSEL)*GREATEST(MAXINDCPOS,
MAXSELCPOS, MAXFLTCPOS)20 + CEIL(INDROWSINDFLTSEL)*FLTCYCLES
如果考虑索引代价调节比,则公式可以进一步写为:
#CPUCYCLES = ROUND(ROUND(#SRDS*(0.32OPTBLKSIZE + 3650 + 850)) + ROUND(#SRDSCACHEHIT850) + CEIL(INDROWSINDFLTSEL)130 + CEIL(INDROWSINDFLTSEL)GREATEST(MAXINDCPOS, MAXSELCPOS, MAXFLTCPOS)20 + CEIL(INDROWSINDFLTSELFLTCYCLES))*OPTICA/100)
