




目录
前言
不同的数据库因为数据类型、SQL语句不同,导致异构数据库的迁移一直以来都是比较复杂的操作,DBA一般会借助各种迁移工具来实现迁移,简化迁移操作。南大通用也开发了GMTK迁移工具,经常用于不同事务型数据到GBase 8s的迁移,在GBase 8a集群项目中较少使用迁移工具,本文以一个具体案例说明如何使用迁移工具实现从Oracle迁移到GBase 8a集群。
一、GBase Migration Toolkit 迁移工具介绍
GBase Migration Toolkit (简称GMTK)迁移工具是南大通用提供的一种实现异构数据库进行数据迁移的图形化工具。
目前支持的源数据库有12种:
ACCESS、Oracle、SQL Server2005、DM、DB2、MySQL、ShenTong、GBase8sV8.3、GBase 8t、GBase 8s、PostgreSQL 和 Teradata
目前支持的目标数据库有:GBase 8a 和 GBase 8s
下面来具体介绍使用GMTK迁移工具实现从Oracle迁移到GBase 8a集群的使用方法和注意事项。
二、从Oracle迁移到GBase 8a集群环境准备
1 环境说明:
Oracle 版本 :Oracle 11GR2 (服务器IP:172.16.9.172)
GBase 8a集群版本:9.5.2.39.126761 (3节点服务器IP:172.16.9.162-164)
迁移工具版本:GBaseMigrationToolkit_8.5.23.0_2_winx86_64.zip
2 迁移步骤:
1.使用GMTK迁移表结构
2.使用GMTK迁移数据
注意:其他数据库迁移到GBase 8a集群时,表结构和表数据一定要分开迁移。
3 Oracle 数据准备
在Oracle数据库中,使用hr_main.sql脚本创建HR示例数据库
主要步骤:
- 将 hr_main.sql 脚本文件拷贝到/home/oracle目录下面
- sqlplus 执行 hr_main.sql 脚本文件
- HR数据库中有7张表,查看表名和数据条数
[oracle@ora172:/home/oracle]$ sqlplus / as sysdba @hr_main.sql
SQL> alter user hr identified by "hr";
User altered.
SQL> conn hr/hr
SQL> select table_name from user_tables;
TABLE_NAME
------------------------------
COUNTRIES
JOB_HISTORY
EMPLOYEES
JOBS
DEPARTMENTS
LOCATIONS
REGIONS
7 rows selected.
SQL> select count(*) from EMPLOYEES;
COUNT(*)
----------
107
SQL> exit
hr_main.sql脚本下载链接:
https://pan.baidu.com/s/1MvIVikeu-Eg1bbNX1BIhtg
hr_main.sql具体操作网上资料很多,不清楚的话自行查询即可。
4 GBase 8a集群环境准备
连接到GBase 8a MPP Cluster数据库,只需创建hr数据库,不需要创建目标表。
使用命令如下:
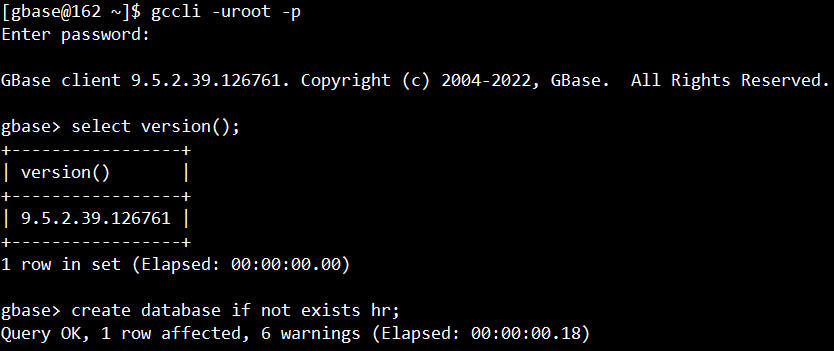
select version();
create database if not exists hr;
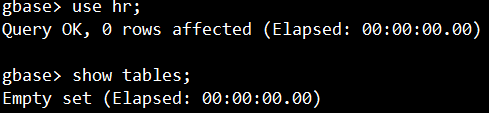
use hr;
show tables;
三、使用GMTK迁移表结构
1.解压迁移工具安装包
在windows电脑上解压缩MTK安装包到一个非中文目录下,解压缩后可直接使用
注意:请不要解压到含中文目录下
2.启动GMTK
双击 Migration.exe ,启动 GMTK工具

3. 新建一个任务
在主界面上单击“新建任务”,进入步骤一,任务名称填写为orato8a,单击“下一步”

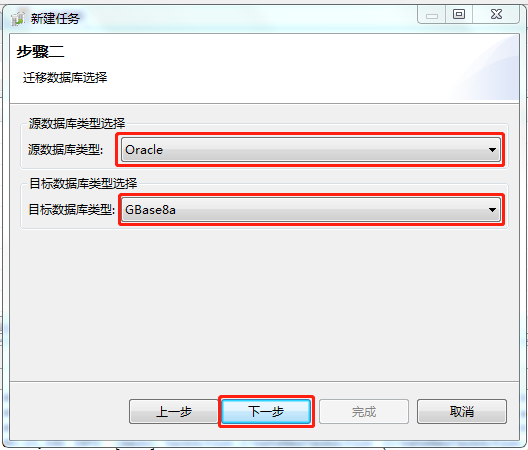
4.迁移数据库选择
进入步骤二,源数据库类型选择“Oracle”,目标数据库类型选择“GBase8a”,单击“下一步”
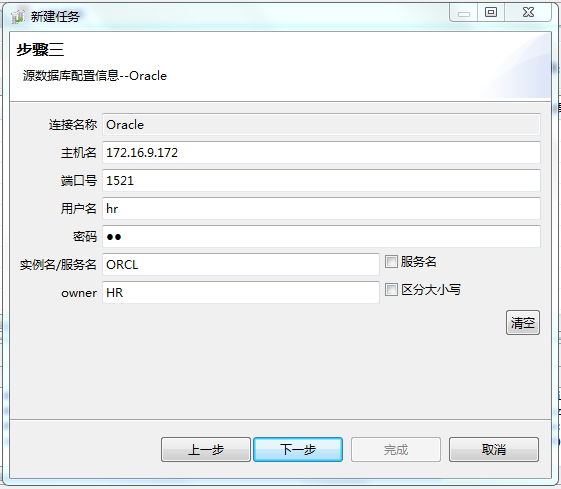
5.填写源数据库配置信息
进入步骤三,填写源数据库Oracle配置信息,主要填写主机名、端口号、用户名、密码、实例名等,配置完毕后,单击“下一步”
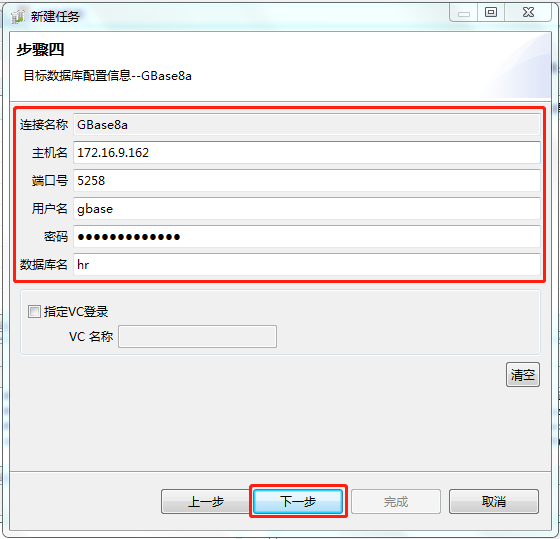
6.填写目标数据库配置信息
进入步骤四,填写目标数据库GBase 8a配置信息,主要填写主机名、端口号、用户名、密码、数据库名等,选择新创建的hr数据库,因为8a集群安装的是兼容VC模式,不用勾选“指定VC登录”选项。
配置完毕,单击“下一步”
7.指定迁移表结构
进入步骤五,选择“迁移表对象”,选择迁移表对象,不要勾选迁移数据,单击“详细设置”按钮,进行表的详细设置。

表的详细设置页面
选择要迁移的表
默认全选所有表,不用修改。如果只迁移个别表,则勾选需要导入的表名即可,不迁移的表不选择即可。
设置表类型
为了更好的适应MPP分布式数据库并行需要,一定要给迁移到8a集群的表设置表的类型,建议设置成复制表、hash分布表(主外键为hash分布列),不建议设置成随机分布表。
设置表类型原则:
对于事实表或增长较快的表,设置为hash分布表(可把主键或外键设置为hash分布列);对于维度表或基本变化不大的小表设置成复制表。
按此原则,把EMPLOYEES 和JOB_HISTORY两个表设置为hash分布表,都以 EMPLOYEE_ID 为hash分布键,其他表为小表设置为复制表。
设置完成如下图
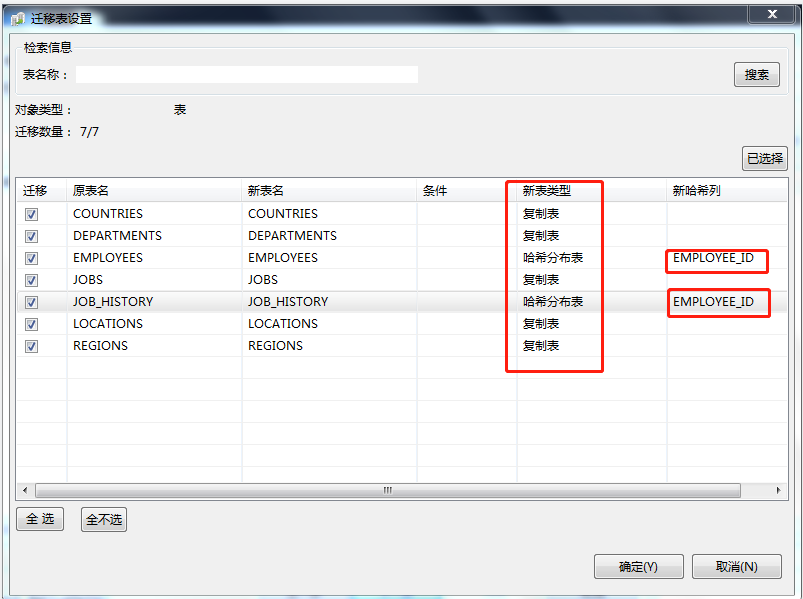
全部表设置完成之后,单击“确定”按钮返回上一步窗口。
注意
-
8a集群是MPP分布式数据库,一般迁移表对象时,先迁移表结构,后迁移数据,不建议同时迁移表结构和数据。
原因在于建表DDL语句要在gcluster和gnode节点都要执行,插入数据的DML语句只在gnode节点执行,所以这两个步骤要分开进行。 -
8a集群是MPP分布式数据库,能创建随机分布表、hash分布表和复制表,从其他数据库迁移,默认的表类型是随机分布表,因为随机分布表性能并不好,所以不推荐设置。
8.指定迁移表结构
单击下一步按钮,进入步骤六,进行“数据类型映射设置”,要注意oracle支持的数据类型跟8a集群支持的数据类型很多不一样,每一种类型要选择合适的8a数据库类型对应,如果选择不合适,可能会导致迁移表失败。
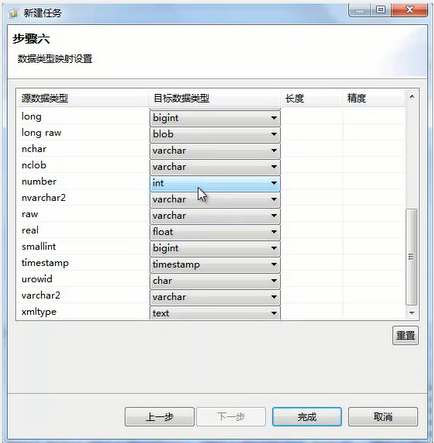
字段类型映射配置建议
oracle的字符类型,例如:char、varchar2、clob等设置成 varchar,尽量不选text
blob对应blob,尽量不选longblob类型
number类型,如果数据为整数,选择int类型;数据为小数,选择double类型
单击“完成”按钮,则任务创建成功。
9.启动任务
任务创建成功后,选择左侧的oracle看到了新建任务名称,双击后,则右侧出现表的迁移任务(未开始)
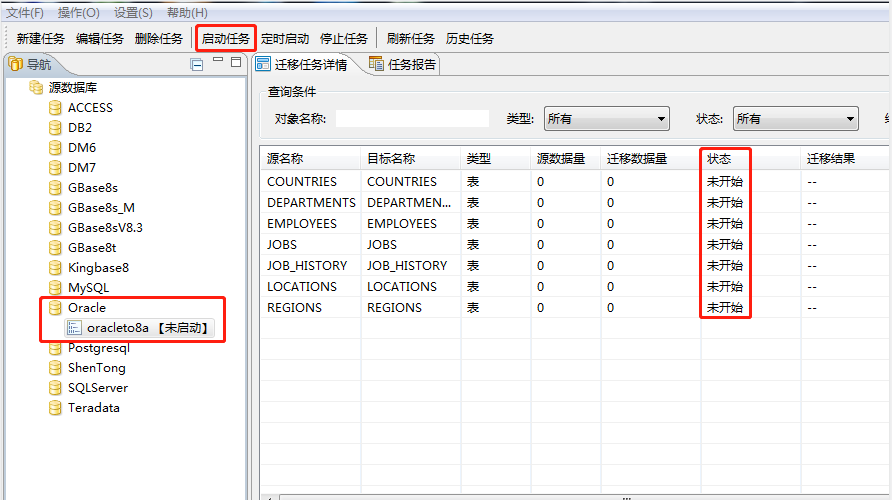
点击【启动任务】开始迁移,直到显示完成,显示表结构迁移成功。
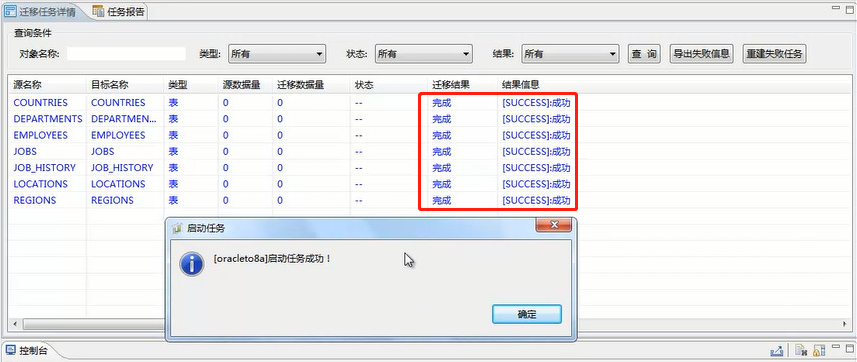
10.到8a集群查看迁移的表
到GBase 8a集群中查看hr数据库中的表是否已存在
[root@162 ~]# su - gbase
上一次登录:三 2月 9 21:06:18 CST 2022pts/0 上
[gbase@162 ~]$ gccli
GBase client 9.5.2.39.126761. Copyright (c) 2004-2022, GBase. All Rights Reserved.
gbase> use hr;
Query OK, 0 rows affected (Elapsed: 00:00:00.00)
gbase> show tables;
+--------------+
| Tables_in_hr |
+--------------+
| countries |
| departments |
| employees |
| job_history |
| jobs |
| locations |
| regions |
+--------------+
7 rows in set (Elapsed: 00:00:00.00)
gbase> show create table employees ;
employees | CREATE TABLE "employees" (
"EMPLOYEE_ID" int(6) DEFAULT NULL,
"FIRST_NAME" varchar(20) DEFAULT NULL,
"LAST_NAME" varchar(25) DEFAULT NULL,
"EMAIL" varchar(25) DEFAULT NULL,
"PHONE_NUMBER" varchar(20) DEFAULT NULL,
"HIRE_DATE" datetime DEFAULT NULL,
"JOB_ID" varchar(10) DEFAULT NULL,
"SALARY" int(8) DEFAULT NULL,
"COMMISSION_PCT" int(2) DEFAULT NULL,
"MANAGER_ID" int(6) DEFAULT NULL,
"DEPARTMENT_ID" int(4) DEFAULT NULL
) ENGINE=EXPRESS DISTRIBUTED BY('employee_id') DEFAULT CHARSET=utf8 TABLESPACE='sys_tablespace'
hr 库下面出现表名称,表示表结构迁移完毕。
注意
如果迁移表结构出现个别表错误,可查询具体出错信息,例如数据类型错误,需要修改任务,改好后再次进行迁移。一般建议在8a中删除hr库,然后新建hr,重新迁移表结构。
四、使用GMTK迁移表数据
跟迁移表结构步骤类似,简单介绍一下迁移数据过程。
1.新建迁移数据任务
新建另一个任务,名称Oracto8a-data,专门迁移表数据。
设置时,之前任务设置过的内容会自动带入,非常方便。
步骤二~步骤4 跟迁移表结构设置相同,步骤五去掉“迁移表结构”,想迁移哪张表就去详细设置中去选表,因为全部表数据进行迁移,可以不进入“详细设置”进行设置了。
数据类型不用再改,单击完成则任务新建成功。
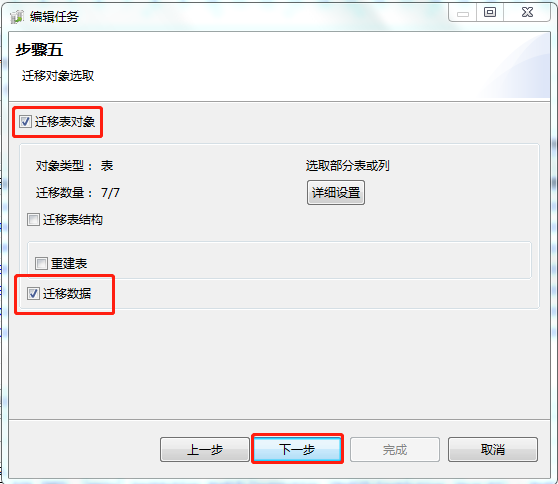
2.启动迁移数据任务
设置完成后,选左侧树中的oracle,显示出未启动的任务名称,单击后,右侧出现表迁移数据任务。
启动迁移数据任务,会显示出迁移数据量,直到全部数据迁移完成。
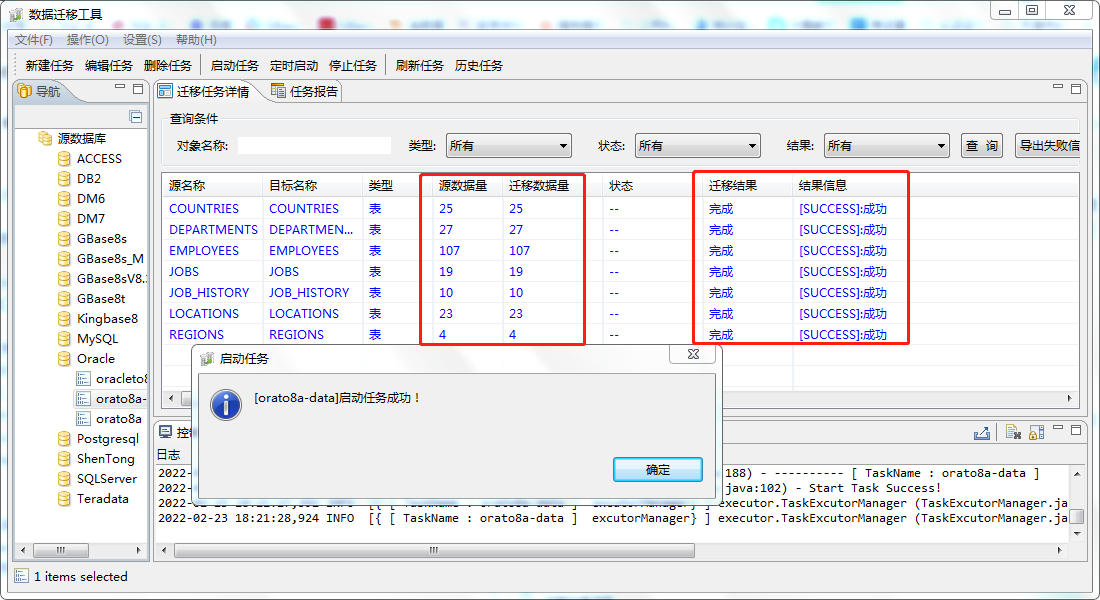
3.在8a集群上可查询到迁移导入hr库的数据

如果表的数据量比较少,直接使用GMTK进行迁移,设置简单,非常方便。
特别说明
在生产环境中,GBase 8a集群处理数据量巨大,往往不使用迁移工具导入数据,原因在于迁移工具使用JDBC标准接口方法GBase 8a集群,入库速度相当于执行insert… values语句,因为是走SQL解析插入数据,性能较慢,对于大数据量(上亿条记录)不推荐使用,大数据量请务必使用load data 语句加载入8a库。
总结
1.GMTK迁移工具较多用于异构事务型数据库间的数据迁移,例如从oracle迁移到GBase 8s数据库,事务型数据库的数据量一般不大,使用迁移工具很方便。
2.在GBase 8a MPP Cluster项目中,可以使用GMTK做数据迁移可行性验证,验证通过后再进行大批量数据的迁移工作。GBase 8a集群往往支撑的数据量巨大,实际生产项目中进行大批量数据的迁移时较少使用GMTK迁移工具,原因是迁移工具通过使用JDBC接口走SQL语句方式导入数据,性能较慢,不满足入库性能,DBA往往使用脚本命令进行迁移。
3.对于小数据量的测试或个人学习8a需要,使用GMTK工具进行数据迁移还是非常方便的。
4.8a集群是MPP分布式数据库,一般进行迁移时,先迁移表结构,后迁移数据,不建议同时迁移表结构和数据。
5.GMTK迁移工具的安装包,未在8a社区找到可公开下载的地址;
目前仅在GBase项目中使用,有需要的话通过GBase销售或官网(www.gbase.cn)进行申请获取。
