




前几天在朋友圈问了大家关于MongoDB的数据储存结构,小摩托同学提出可以加个索引,然后我加完测试了一下,这里跟大家说下结果
1. 数据结构
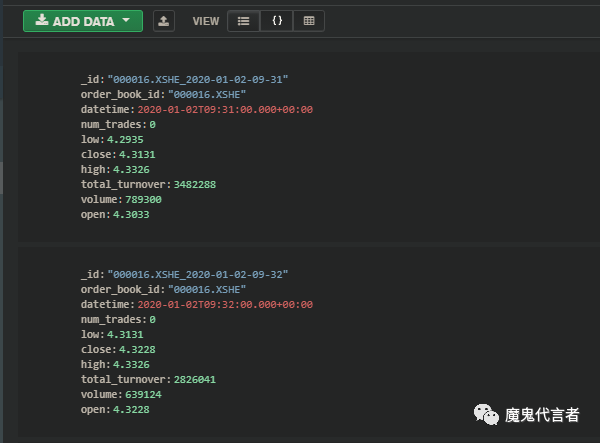
我的数据是这样储存的,_id 我这么设置首先它有唯一性,由于是分钟数据,所以我想以后查询起来都用 "-" 比较方便,但其实这无所谓,大家并不真的用_id来查东西
时间被存储为ISO格式,你用datetime传到MongoDB中,它就会直接给你这么转化,所以还比较方便
其实还可以增加几行,把时间拆成year, month, date,也许方便以后索引
还可以把股票代码单独拆出来,后面的.XSHE我现在看有点多余
2. 索引
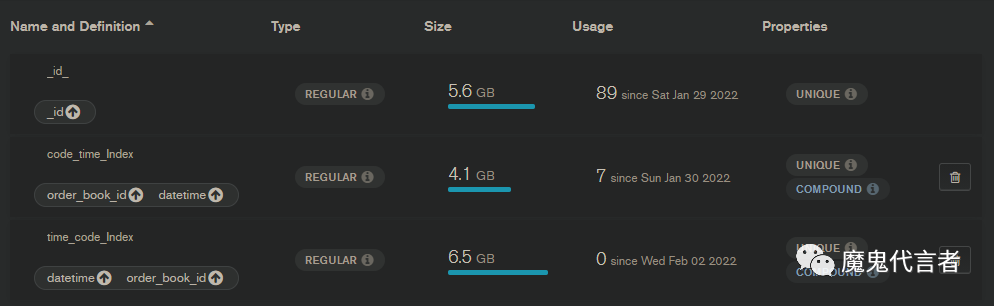
这里有三个索引
_id_:这个是默认的,我就不说了
code_time_Index: 这个是我加的唯一复合索引,后面的unique表示它具有唯一性,coumpound表示它是复合的。
这里会先用股票代码code做索引,然后再用datetime作为二级索引
time_code_Index:这也是我加的唯一复合索引,只不过区别是时间在上面,而股票代码code是二级索引
我测试了一下3型索引,用起来没啥问题
{'explainVersion': '1','queryPlanner': {'namespace': '***.CS_Data','indexFilterSet': False,'parsedQuery': {'$and': [{'datetime': {'$lt': datetime.datetime(2022, 1, 6, 0, 0)}},{'datetime': {'$gt': datetime.datetime(2022, 1, 3, 0, 0)}}]},'maxIndexedOrSolutionsReached': False,'maxIndexedAndSolutionsReached': False,'maxScansToExplodeReached': False,'winningPlan': {'stage': 'FETCH','inputStage': {'stage': 'IXSCAN','keyPattern': {'datetime': 1, 'order_book_id': 1},'indexName': 'time_code_Index','isMultiKey': False,'multiKeyPaths': {'datetime': [], 'order_book_id': []},'isUnique': True,'isSparse': False,'isPartial': False,'indexVersion': 2,'direction': 'forward','indexBounds': {'datetime': ['(new Date(1641168000000), new Date(1641427200000))'],'order_book_id': ['[MinKey, MaxKey]']}}},'rejectedPlans': []},'executionStats': {'executionSuccess': True,'nReturned': 1231440,'executionTimeMillis': 4441,'totalKeysExamined': 1231440,'totalDocsExamined': 1231440,'executionStages': {'stage': 'FETCH','nReturned': 1231440,'executionTimeMillisEstimate': 1003,'works': 1231441,'advanced': 1231440,'needTime': 0,'needYield': 0,'saveState': 1244,'restoreState': 1244,'isEOF': 1,'docsExamined': 1231440,'alreadyHasObj': 0,'inputStage': {'stage': 'IXSCAN','nReturned': 1231440,'executionTimeMillisEstimate': 171,'works': 1231441,'advanced': 1231440,'needTime': 0,'needYield': 0,'saveState': 1244,'restoreState': 1244,'isEOF': 1,'keyPattern': {'datetime': 1, 'order_book_id': 1},'indexName': 'time_code_Index','isMultiKey': False,'multiKeyPaths': {'datetime': [], 'order_book_id': []},'isUnique': True,'isSparse': False,'isPartial': False,'indexVersion': 2,'direction': 'forward','indexBounds': {'datetime': ['(new Date(1641168000000), new Date(1641427200000))'],'order_book_id': ['[MinKey, MaxKey]']},'keysExamined': 1231440,'seeks': 1,'dupsTested': 0,'dupsDropped': 0}},'allPlansExecution': []},'command': {'find': 'CS_Data','filter': {'datetime': {'$gt': datetime.datetime(2022, 1, 3, 0, 0),'$lt': datetime.datetime(2022, 1, 6, 0, 0)}},'$db': 'MinutesData'},'serverInfo': {'host': 'LAPTOP-***','port': ****,'version': '5.0.5','gitVersion': 'd65fd89df3fc039b5c55933c0f71d647a54510ae'},'serverParameters': {'internalQueryFacetBufferSizeBytes': 104857600,'internalQueryFacetMaxOutputDocSizeBytes': 104857600,'internalLookupStageIntermediateDocumentMaxSizeBytes': 104857600,'internalDocumentSourceGroupMaxMemoryBytes': 104857600,'internalQueryMaxBlockingSortMemoryUsageBytes': 104857600,'internalQueryProhibitBlockingMergeOnMongoS': 0,'internalQueryMaxAddToSetBytes': 104857600,'internalDocumentSourceSetWindowFieldsMaxMemoryBytes': 104857600},'ok': 1.0}
这里是索引使用数据
IXSCAN 表示的确用到了索引,一共查询了1231440个数据
耗时:171毫秒
查询时间上来说我觉得挺好的,如果不加索引直接查,我等了五分钟没出东西就关掉了,所以索引必须要加的
这里跟SQL数据库就不太一样,MongoDB必须要建立索引,才能根据你建立的索引进行查询,然后有时候如果查询的方式不一样,如果没用到你建立的索引,它就会一条条的读下去,对于全市场分钟数据的数据库来说,这个耗时想来就很恐怖。
3. 为什么用MongoDB
3.1. 之前面了个私募,他们在用MongoDB,然后当时他们不太会用,所以要找个会用的,碰巧我当时也不会用,那就没办法了,所以既然大家都在用,那么跟进下没啥问题
3.2. mysql太慢了,性能差
3.3. 芒果DB有免费版也有企业版,社区版对我们这种散修来说比较友好,部署在本地也没啥要收费的东西
3.4 有人建议用dolphineDB,ddb确实好用,有推送,有计算功能,但是这玩意太贵了,而且我总觉得外国人做的精致一些,芒果DB界面就挺好看的,感觉他们花了很多时间来维护
3.5 也有人建议用Influx,这个我看了下,有时间序列的结构,但是是部署在linux上的,而且没有界面。我觉得建立起来就很废力(我并不熟悉linux,勉强用吧),所以就不想搞了,而且看起来这东西也要花钱
4. 索引的其他方案
4.1 其实可以不用唯一性标识,直接给时间打上索引,也许也会好一点
5. 问题
5.1 一个索引4个G,另一个5G... 索引占空间挺大的, 我的数据一共才13G,索引有16.1G,所以到头来索引比数据还大,具体怎么加索引大家要衡量一下
