




我们在观察SQL执行计划的时候,一般会首先关注COST,COST较大,SQL一般就需要进行关注了。
数据库后台默默执行了大量SQL,我们需要提取COST的SQL进行分析,分析哪些sql可以进行优化。
如果给每个SQL_ID都能生成一个随着时间波动的COST变化图,对了解SQL的性能变动趋势,就一目了然了。
那么,现在开始吧,其实很简单:
1、获取SQL COST变动历史
select * from (
select
a.SNAP_ID,to_char(tt.BEGIN_INTERVAL_TIME,'yyyy-mm-dd hh24:mi:ss') begin_time,a.MODULE,
a.DBID,a.INSTANCE_NUMBER ins_id,a.SQL_ID,a.PLAN_HASH_VALUE,a.OPTIMIZER_COST,nvl(a.CPU_TIME_DELTA,0) cpu_cost,
nvl(a.EXECUTIONS_DELTA,0) execs,nvl(a.ELAPSED_TIME_DELTA,0)/1000000 exec_all_times,
round((elapsed_time_delta/decode(nvl(executions_delta,0),0,1,executions_delta))/1000000,2) avg_time,
a.DISK_READS_DELTA io_get,a.BUFFER_GETS_DELTA dbbuffer_get
from dba_hist_sqlstat a, DBA_HIST_SNAPSHOT tt where a.SNAP_ID=tt.SNAP_ID and a.DBID=tt.DBID and a.OPTIMIZER_COST is not null and OPTIMIZER_COST>10000 order by a.SQL_ID,a.OPTIMIZER_COST desc )
where rownum<=100 ;
这个sql虽然是笔者写的,这个语句可以获取SQL的性能波动历史,可以获取cpu、磁盘读写、数据缓冲区读写次数等,看上去晦涩难懂,来个简答的说下:
select sql_id,a.OPTIMIZER_COST
from dba_hist_sqlstat a
where a.OPTIMIZER_COST is not null and OPTIMIZER_COST>1000 and rownum<=1000 order by OPTIMIZER_COST desc;
dba_hist_sqlstat这个视图可以自行查看官网,很多sql的历史执行信息,都在这里面,awr的很多信息,都来自这个试图,上面的语句就是SQL 执行计划COST>10000的top 1000条数据,然后,将结果输出到到一个文本里,形式如下:
4js707bppkjmv 286 138387247
fbjs6vqydm3xa 277 1719
fbjs6vqydm3xa 284 1719
第一列是sql_id,第二列是snap_id,第三列是cost
2、准备python环境
程序需要使用三个包:
import os #读文件用,自带的,
from pyecharts import Bar #画柱状图用
from pyecharts import Line #画折线图用
pyecharts 不是默认安装的,需要单独安装,如果用PyCharm,可以在file-> settings 安装一下:
3、编写python脚本
一次性把脚本全部贴出来:
#import linecache
# Press Shift+F10 to execute it or replace it with your code.
# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
#import re
# docx import Document
import os
#from docx.oxml.ns import nsdecls
#from docx.oxml import parse_xml
from pyecharts import Bar
from pyecharts import Line
if __name__ == '__main__':
ALL_DATA = []
file = 'D:\\专业知识\\python\\check_abc.log'
f = open(file, 'r', encoding='UTF-8')
lines = f.readlines()
#获取所有sql_id,不重复,用sql_id来获取其他性能数据
number = []
for lss in lines:
m = lss.replace('\n', '')
sql_id=lss.split()[0]
if sql_id not in number:
number.append(sql_id)
ALL_DATA=[]
for j in range(len(number)):
sql_id_w=number[j]
for lss in lines:
lss = lss.replace('\n', '')
sql_id_n = lss.split()[0]
if sql_id_w==sql_id_n:
snap_id = lss.split()[1]
cost = lss.split()[2]
ALL_DATA.append({"snap_id": snap_id, "cost": cost})
#一个sql_id相关数据获取完成,开始画图
show_data = ALL_DATA
snap_id = list(map(lambda ALL_DATA: ALL_DATA["snap_id"], show_data))
cost = list(map(lambda ALL_DATA: int(ALL_DATA["cost"]), show_data))
chart = Bar(f'sql_id:{sql_id_w} cost变化趋势图:') # 需要安装pyechart模块
chart.add("cost变化趋势图", snap_id, cost)
f_out = f'sql_cost_{sql_id_w}.html'
chart.render(f_out)
line = Line("cost变化趋势图", title_top="50%")
line.add("cost变化趋势图", snap_id, cost)
line.show_config()
f_out = f'sql_cost_line_{sql_id_w}.html'
line.render(f_out)
ALL_DATA = []
f.close()
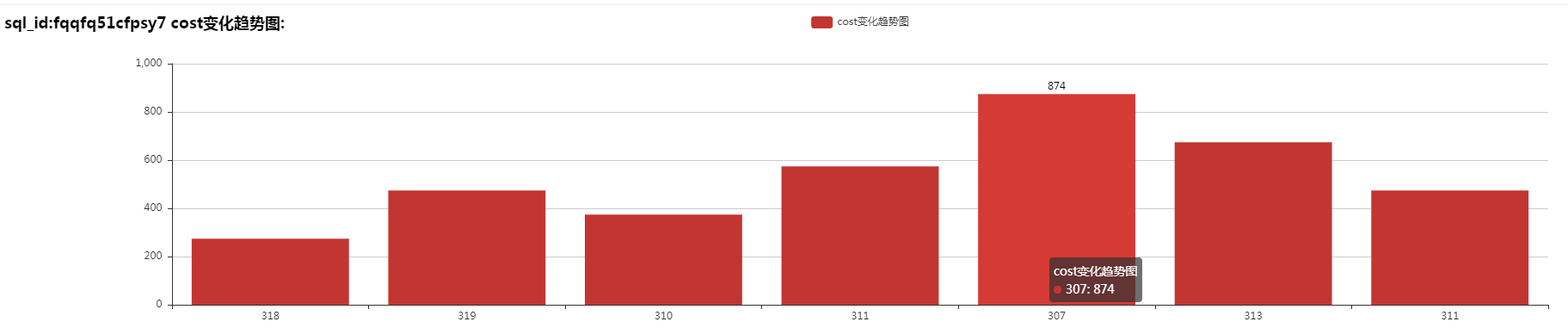
看,就这么几行,效果如下: 柱状图效果
折线图效果:
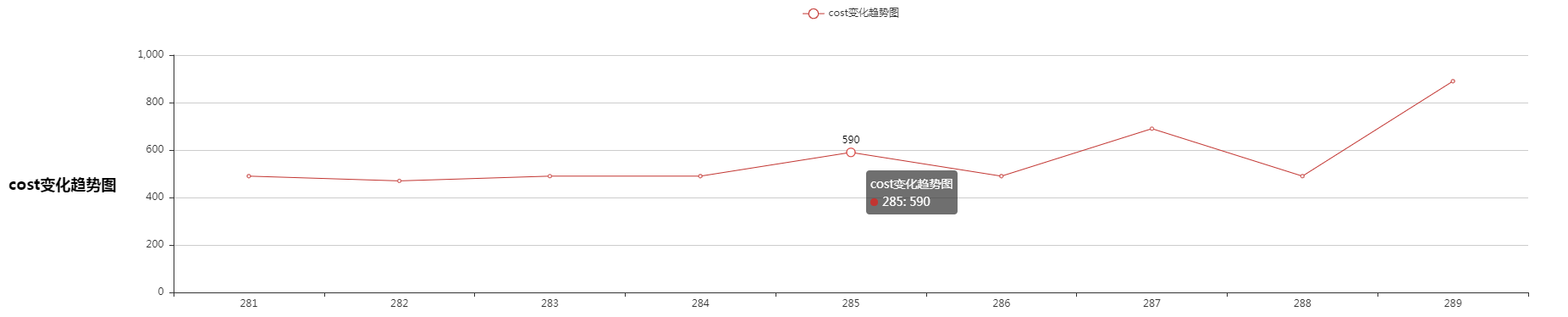
标题是sql_id,横轴是snap id,纵轴是cost,其实snap id可以和时间对应上,就是第一个复杂脚本里写着。
4、主要代码详解
打开文件,逐行读取:
file = 'D:\\专业知识\\python\\check_abc.log'
f = open(file, 'r', encoding='UTF-8')
lines = f.readlines()
然后读取所有sql_id:
for lss in lines:
m = lss.replace('\n', '')
sql_id=lss.split()[0]
if sql_id not in number:
number.append(sql_id)
这样,就从文本中读取了指定的值,并且不重复。number是个list,里面放着所有sql_id。
然后用number值作为外层循环,在逐行读取文本文件,获取某一个sql_id的全部数据:
sql_id_w=number[j] #外层循环SQL_id数据
sql_id_n = lss.split()[0] #内存循环SQL_id数据,发现当前SQL_id对应上的,就加入list里面:
ALL_DATA.append({“snap_id”: snap_id, “cost”: cost})
其实可以做两个list变量,做两个变量,就不用下面的代码了:
snap_id = list(map(lambda ALL_DATA: ALL_DATA["snap_id"], show_data))
cost = list(map(lambda ALL_DATA: int(ALL_DATA["cost"]), show_data))
最后,就是画图及输出了:
chart = Bar(f'sql_id:{sql_id_w} cost变化趋势图:') # title
chart.add("cost变化趋势图", snap_id, cost) #加入纵横轴数据
f_out = f'sql_cost_{sql_id_w}.html' # 文件名
chart.render(f_out) # 输出文件
下面的Line方法相同。还可以把很多图片输出到一个文件里,可以对pyecharts这个模块详细研究。
欢迎大家与红希交流,一个一直在做dba,做过云,中间件,也喜欢python的IT人。
