




背景
上一篇文章写了MySQL多云多活的方案,里面开头介绍了我们整个多云多活的背景,具体信息可以跳转到多云多活方案之MySQL,大概要点就是我们的业务分单元化部分和不能单元化部分,那么如解决其中一个单元的高可用问题和不能单元化服务的高可用问题,关于讨论mongodb的方案之前,我们还是给出几个前提条件或者说是设计原则:
支持多云,单个云故障短时间(分钟级别)服务可恢复;
多云的多个机房通过专线打通;
是需要多活的,两个region和两个云都有流量,经验告诉我们灾备的方案在关键时刻99%的情况下是无法正常接管的。
方案
方案一
集群采用两地三中心的部署架构,以GZone这个单元为例,北京分别启用A云和B云的一个机房,保定启用B云的一个机房,三个机房组成一个集群
写操作写到主机房,读操作根据业务场景选择读取方式:readPreference=primary|primaryPreferred|secondary|secondaryPreferred|nearest,每种读取方式的场景如下:
primary:只从主节点上读取数据;
primaryPreferred:读取将被重定向至主服务器;如果主节点不可用,那么读取将被重定向至某个从节点上;
secondary:读取将被重定向至从节点。如果没有从节点,读取就会产生异常;
secondaryPreferred:读取将被重定向至从节点上;如果没有从节点,那么读取将被重定向至主节点上;
nearest:从最近的节点读取数据,不论它是主服务器还是从节点,该选项通过网络延迟决定使用哪个节点服务器。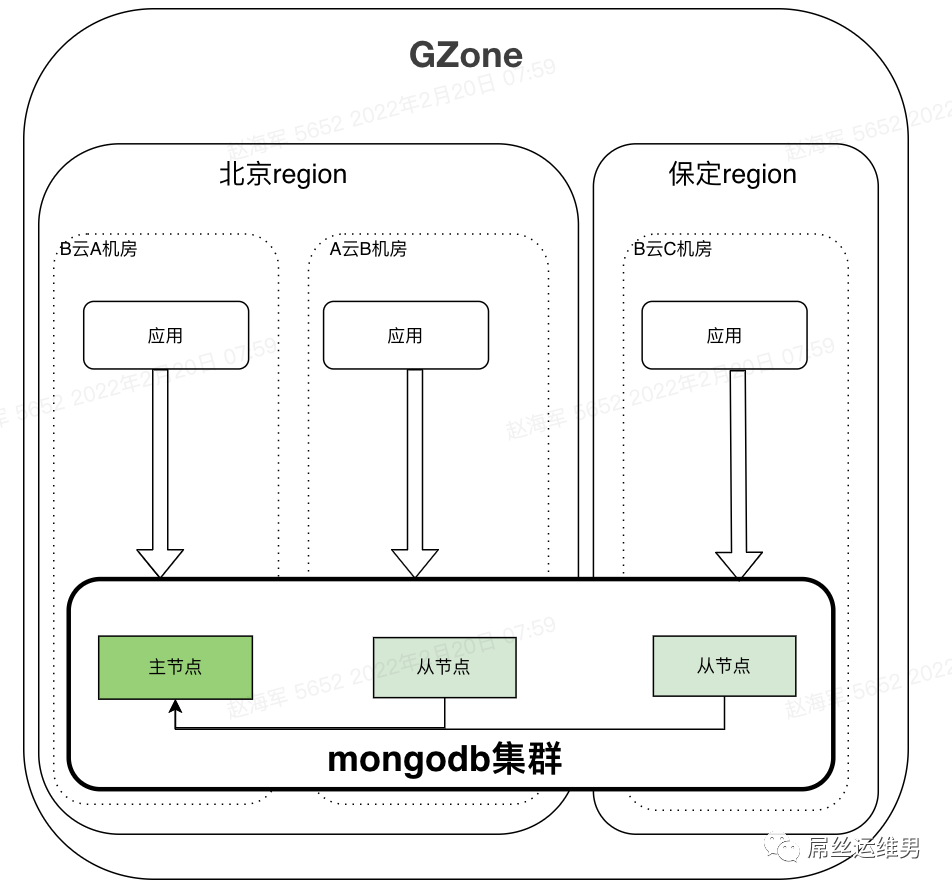
这个方案无法解决北京这个region A云和B云同时故障的场景,因为这种故障场景出现的概率比较小,我们暂且忽略这种情况
方案二
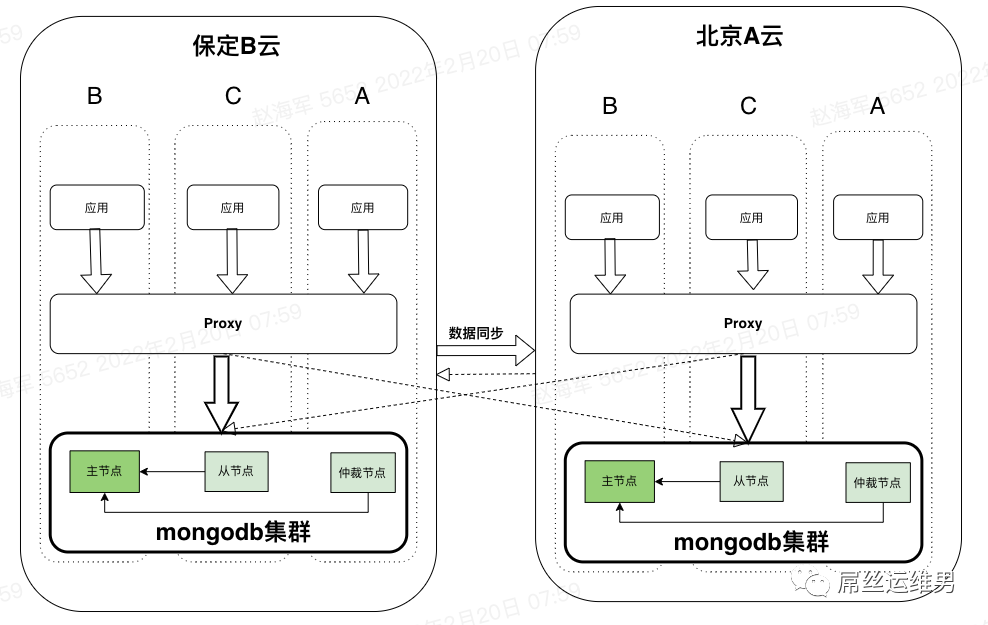
B云的保定region部署独立集群,region内部使用3AZ部署架构;A云的北京region也部署独立集群,两个集群通过DTS做数据同步;
需要开发一个Proxy,实现夸集群的写入路由,让写入操作都写主集群;
当主集群故障,需要一套fail-over机制,做主备集群的切换,这个切换流程和MySQL的方案里面的切换流程大同小异,这里就不详细描述了。
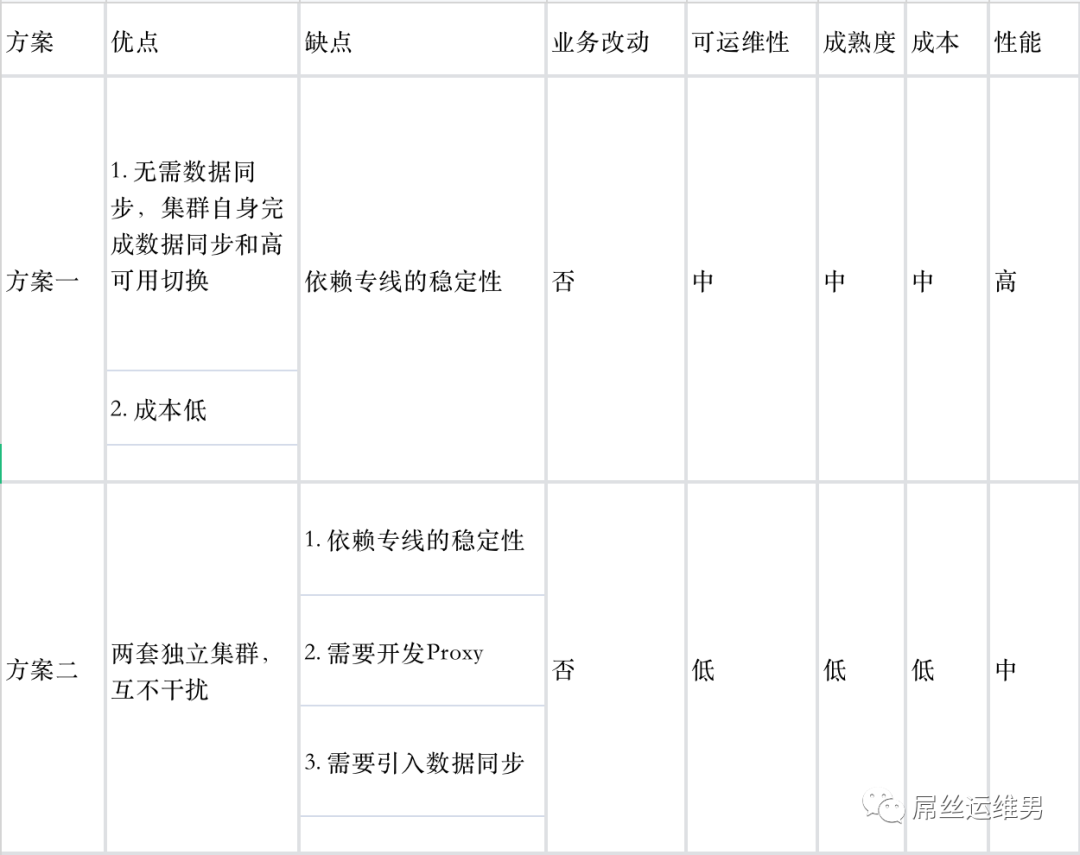
方案对比
总结
综合考虑,我们计划采用方案一,关于这个方案大家有建议欢迎一起讨论交流;
这是一个两到三年的工程,目前各个板块都缺人,大家有想法一起来搞的找我内推,数据库这块我们重点招三个方向的人:DBA、管控平台的开发、中间件的开发,欢迎大家自荐或推荐。
部分岗位的JD:理想汽车内推岗位JD
